クラスターの構成
Note
これらは、従来のクラスター作成 UI の手順であり、正確な履歴の提供のみを目的として含まれています。 すべてのお客様は、更新されたクラスター作成 UI を使用している必要があります。
この記事では、Azure Databricks クラスターを作成および編集するときに使用できる構成オプションについて説明します。 ここでは、UI を使用したクラスターの作成と編集に焦点を当てます。 その他の方法については、Databricks CLI、クラスター API、および Databricks Terraform プロバイダーに関するページを参照してください。
自分のニーズに最も適した構成オプションの組み合わせを決定する方法については、クラスター構成のベスト プラクティスに関するページを参照してください。

クラスター ポリシー
クラスター ポリシーは、一連のルールに基づいてクラスターを構成する機能を制限します。 ポリシー ルールによって、クラスターの作成に使用できる属性または属性値が制限されます。 クラスター ポリシーには、その使用を特定のユーザーとグループに制限する ACL があります。それによって、クラスター作成時に選択できるポリシーが制限されます。
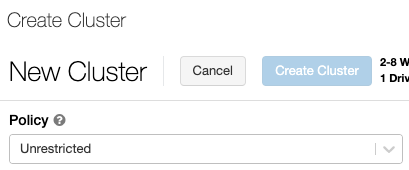
クラスター ポリシーを構成するには、[ポリシー] ドロップダウンからクラスター ポリシーを選択します。
Note
ポリシーがワークスペース内に作成されていない場合、[ポリシー] ドロップダウンは表示されません。
次を持っている場合:
- クラスターの作成アクセス許可 - [無制限] ポリシーを選択し、完全に構成可能なクラスターを作成できます。 [無制限] ポリシーでは、どのクラスター属性または属性値も制限されません。
- クラスターの作成アクセス許可とクラスター ポリシーへのアクセス権の両方 - [無制限] ポリシーとアクセス権を持っているポリシーを選択できます。
- クラスター ポリシーへのアクセス権のみ - アクセス権を持っているポリシーを選択できます。
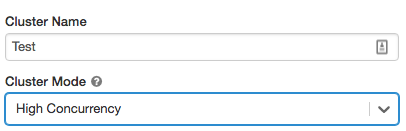
クラスター モード
Note
この記事では、従来のクラスター UI について説明します。 新しいクラスター UI (プレビュー段階) の詳細については、「コンピューティング構成リファレンス」を参照してください。 これには、クラスター アクセスの種類とモードのいくつかの用語の変更が含まれています。 新しいクラスターと従来のクラスターの種類の比較については、「クラスター UI の変更とクラスター アクセス モード」を参照してください。 プレビュー UI で、次の操作を行います。
- 標準モード クラスターは、共有された分離なしアクセス モード クラスターと呼ばれるようになりました。
- テーブル ACL を使用した高コンカレンシーは、共有アクセス モード クラスターと呼ばれるようになりました。
Azure Databricks では、標準、高コンカレンシー、単一ノードという 3 つのクラスター モードがサポートされています。 既定のクラスター モードは標準です。
重要
- ワークスペースが Unity カタログ メタストアに割り当てられている場合、高コンカレンシー クラスターは使用できません。 代わりに、アクセス モードを使って、アクセス制御の整合性を確保し、強力な分離の保証を適用します。 「アクセス モード」も参照してください。
- クラスターの作成後はクラスター モードを変更できません。 別のクラスター モードが必要な場合は、新しいクラスターを作成する必要があります。
クラスター構成には、自動終了設定が含まれています。その "既定値" は、クラスター モードによって異なります。
- 標準と単一ノード クラスターは、既定で 120 分後に自動的に終了します。
- 高コンカレンシー クラスターは、既定で、自動的には終了 "しません"。
標準クラスター
警告
標準モード クラスター (共有された分離なしクラスターとも呼ばれます) は、複数のユーザーが共有でき、ユーザー間で分離することはできません。 テーブル ACL や資格情報パススルーなどの追加のセキュリティ設定なしで高コンカレンシー クラスター モードを使用する場合は、標準モード クラスターと同じ設定が使用されます。 アカウント管理者は、これらの種類のクラスターで Databricks ワークスペース管理者の内部資格情報が自動的に生成されないようにすることができます。 より安全なオプションのために、Databricks では、テーブル ACL を使用した高コンカレンシー クラスターなどの代替手段が推奨されています。
単一ユーザーにのみ標準クラスターが推奨されます。 標準クラスターでは、Python、SQL、R、Scala で開発されたワークロードを実行できます。
高コンカレンシー クラスター
高コンカレンシー クラスターは、マネージド クラウド リソースです。 高コンカレンシー クラスターの主な利点は、リソース使用率を最大化し、クエリの待機時間を最小限にするための、きめ細かい共有が提供される点です。
高コンカレンシー クラスターでは、SQL、Python、R で開発されたワークロードを実行できます。高コンカレンシー クラスターのパフォーマンスとセキュリティは、別々のプロセスでユーザー コードを実行することによって提供されます。これは、Scala では実行できません。
さらに、テーブルのアクセス制御がサポートされるのは、高コンカレンシー クラスターだけです。
高コンカレンシー クラスターを作成するには、[クラスター モード] を [高コンカレンシー] に設定します。
単一ノード クラスター
単一ノード クラスターにはワーカーがなく、ドライバー ノードで Spark ジョブが実行されます。
これに対し、標準クラスターでは、Spark ジョブを実行するために、ドライバー ノードに加えて "少なくとも 1 つ" の Spark ワーカー ノードが必要です。
単一ノード クラスターを作成するには、[クラスター モード] を [単一ノード] に設定します。

単一ノード クラスターの操作の詳細については、「単一ノードまたはマルチ ノード コンピューティング」を参照してください。
プール
クラスターの起動時間を短縮するには、ドライバーとワーカー ノードを作成するためのアイドル状態のインスタンスが含まれている定義済みプールにクラスターを接続できます。 クラスターは、プール内のインスタンスを使用して作成されます。 要求されたドライバーやワーカー ノードを作成するのに十分なアイドル状態のリソースがプールにない場合、プールは、インスタンス プロバイダーから新しいインスタンスを割り当てることによって拡張します。 接続されたクラスターが終了すると、使用されていたインスタンスはプールに返され、別のクラスターで再利用できます。
ワーカー ノード用のプールを選択したが、ドライバー ノード用を選択しない場合、ドライバー ノードはワーカー ノード構成のプールを継承します。
重要
ドライバー ノード用のプールを選択しようとしたが、ワーカー ノード用を選択しない場合は、エラーが発生し、クラスターは作成されません。 この要件により、ドライバー ノードがワーカー ノードが作成されるのを待機しなければいけない (またはその逆の) 状況が回避されます。
Azure Databricks でのプールの操作の詳細については、「プール構成リファレンス」を参照 してください。
Databricks Runtime
Databricks Runtime は、クラスターで実行されるコア コンポーネントのセットです。 すべての Databricks Runtime には Apache Spark が含まれており、使いやすさ、パフォーマンス、およびセキュリティを向上させるコンポーネントと更新プログラムが追加されています。 詳細は、「Databricks Runtime リリース ノートのバージョンと互換性」を参照してください。
Azure Databricks では、クラスターを作成または編集するときに、[Databricks Runtime のバージョン] ドロップダウンに、複数のランタイムの種類と、それらのランタイムの複数のバージョンが提供されます。
Photon アクセラレーション
Photon は、Databricks Runtime 9.1 LTS 以上を実行しているクラスターで使用できます。
Photon アクセラレーションを有効にするには、[Use Photon Acceleration] (Photon アクセラレーションを使用) チェックボックスをオンにします。
必要に応じて、ワーカーの種類とドライバーの種類ドロップダウンでインスタンスの種類を指定できます。
Databricks では、最適な価格とパフォーマンスを実現するために、次のインスタンスの種類が推奨されています。
- Standard_E4ds_v4
- Standard_E8ds_v4
- Standard_E16ds_v4
Photon アクティビティは Spark UI で表示できます。 次のスクリーンショットは、クエリの詳細 DAG を示しています。 この DAG では Photon に関して 2 つのことが示されています。 1 つ目として、Photon 演算子は "Photon" で始まっています (例: PhotonGroupingAgg)。 2 つ目として、この DAG では、Photon 演算子とステージの色は桃色で、Photon 以外のものは青色です。

Docker イメージ
一部の Databricks Runtime バージョンでは、クラスターを作成するときに Docker イメージを指定できます。 ユース ケース例としては、ライブラリのカスタマイズ、変化しないゴールデン コンテナー環境、および Docker CI/CD 統合があります。
また、Docker イメージを使用して、GPU デバイスを使用するクラスターにカスタム ディープ ラーニング環境を作成することもできます。
手順については、「Databricks コンテナー サービスを使用してコンテナーをカスタマイズする」と「GPU コンピューティング上の Databricks コンテナー サービス」を参照してください。
クラスター ノードの型
クラスターは、1 台のドライバー ノードと 0 台以上のワーカー ノードで構成されます。
ドライバー ノードとワーカー ノードに対して別々のクラウド プロバイダー インスタンスの種類を選択することもできますが、既定では、ドライバー ノードではワーカー ノードと同じインスタンスの種類が使用されます。 インスタンスの種類の異なるファミリは、メモリ集中型やコンピューティング集中型のワークロードなど、異なるユース ケースに適合します。
Note
セキュリティ要件にコンピューティングの分離が含まれている場合は、ワーカー タイプとして Standard_F72s_V2 インスタンスを選択してください。 これらのインスタンスの種類は、物理ホスト全体を消費し、たとえば、米国国防総省影響レベル 5 (IL5) のワークロードなどをサポートするために必要な分離レベルを提供する、分離された仮想マシンを表します。
ドライバー ノード
ドライバー ノードでは、クラスターに接続されているすべてのノートブックの状態情報が保持されます。 また、ドライバー ノードでは SparkContext が保持され、クラスター上のノートブックやライブラリから実行されるコマンドが解釈され、Spark Executor との調整を行う Apache Spark マスターが実行されます。
ドライバー ノードの種類の既定値は、ワーカー ノードの種類と同じです。 Spark ワーカーから多くのデータを collect() し、それらをノートブックで分析することを計画している場合は、より多くのメモリを備えたより大規模なドライバー ノードの種類を選択できます。
ヒント
ドライバー ノードには、接続されているノートブックのすべての状態情報が保持されるため、使用されていないノートブックはドライバー ノードから切断するようにしてください。
ワーカー ノード
Azure Databricks のワーカー ノードでは、クラスターを適切に機能させるために必要な Spark Executor やその他のサービスが実行されます。 Spark を使用してワークロードを分散する場合、すべての分散処理はワーカー ノードで行われます。 Azure Databricks では、ワーカー ノードごとに 1 つの Executor が実行されます。したがって、Executor と "ワーカー" という用語は、Azure Databricks アーキテクチャのコンテキストでは同じ意味で使用されます。
ヒント
Spark ジョブを実行するには、少なくとも 1 台のワーカー ノードが必要です。 クラスター内のワーカーの数が 0 の場合は、Spark 以外のコマンドはドライバー ノードで実行できますが、Spark コマンドは失敗します。
GPU インスタンスの種類
ディープ ラーニングに関連するものなど、ハイ パフォーマンスが要求される、計算が困難なタスクの場合、Azure Databricks ではグラフィックス処理装置 (GPU) によって高速化されたクラスターがサポートされます。 詳細については、GPU 対応コンピューティングに関するページを参照してください。
スポット インスタンス
コストを節約するには、[スポット インスタンス] チェックボックスをオンにして、スポット インスタンス (Azure スポット VM とも呼ばれる) を使用することを選択できます。

最初のインスタンスは常にオンデマンド (ドライバー ノードは常にオンデマンド) であり、後続のインスタンスはスポット インスタンスになります。 使用できないためにスポット インスタンスが強制削除された場合は、強制削除されたインスタンスを置き換えるためにオンデマンド インスタンスがデプロイされます。
クラスターのサイズと自動スケール
Azure Databricks クラスターを作成する際、クラスターに対して固定数のワーカーを指定することも、クラスターに対して最小と最大数のワーカーを指定することもできます。
固定サイズのクラスターを指定すると、Azure Databricks によって、クラスターには指定された数のワーカーが確実に含まれます。 ワーカー数に対して範囲を指定すると、ジョブを実行するために必要な適切な数のワーカーが Databricks によって選択されます。 これは、"自動スケーリング" と呼ばれます。
自動スケーリングを使用すると、Azure Databricks では、ジョブの特性を考慮してワーカーが動的に再割り当てられます。 パイプラインの特定の部分が他の部分よりも計算が困難な場合があります。Databricks では、ジョブのこれらのフェーズ中に自動的にワーカーが追加されます (また、不要になると削除されます)。
自動スケーリングを使用すると、ワークロードに適合するようにクラスターをプロビジョニングする必要がないため、高いクラスター使用率を簡単に実現できます。 これは特に、(1 日の流れの中でデータセットの探索を行うなど、) 時間の経過とともに要件が変化するワークロードに適用されますが、プロビジョニング要件が不明な 1 回限りの短いワークロードにも適用できます。 したがって、自動スケーリングには次の 2 つの利点があります。
- プロビジョニング数が不足している一定サイズのクラスターと比較して、より高速にワークロードを実行できます。
- 自動スケーリングのクラスターでは、静的サイズのクラスターと比較して全体的なコストを削減できます。
クラスターとワークロードの一定サイズに応じて、自動スケーリングを使用すると、これらの利点の一方または両方を同時に得ることができます。 クラスター サイズは、クラウド プロバイダーがインスタンスを終了するときに選択されたワーカーの最小数を下回る場合があります。 この場合は、最小数のワーカーを維持するために、Azure Databricks によって連続的にインスタンスの再プロビジョニングが再試行されます。
注意
自動スケーリングは、spark-submit ジョブには使用できません。
自動スケーリングの動作
- 2 ステップで最小から最大にスケールアップします。
- シャッフル ファイルの状態を確認することで、クラスターがアイドル状態でなくてもスケールダウンできます。
- 現在のノードの割合に基づいてスケールダウンします。
- ジョブ クラスターでは、クラスターの使用率が低い状態が 40 秒間続くとスケールダウンします。
- 汎用クラスターでは、クラスターの使用率が低い状態が 150 秒間続くとスケールダウンします。
spark.databricks.aggressiveWindowDownSSpark 構成プロパティは、クラスターでスケールダウンの決定が行われる頻度を秒単位で指定します。 この値を大きくすると、クラスターでのスケールダウンが遅くなります。 最大値は 600 です。
自動スケーリングを有効にして構成する
Azure Databricks でクラスターのサイズ変更を自動的に行えるようにするには、クラスターの自動スケーリングを有効にし、ワーカーの最小と最大数の範囲を指定します。
自動スケールを有効にします。
汎用クラスター - [クラスターの作成] ページで、[Autopilot オプション] ボックスの [自動スケーリングを有効にする] チェックボックスを選択します。

ジョブ クラスター - [クラスターの構成] ページで、[Autopilot オプション] ボックスの [自動スケーリングを有効にする] チェックボックスを選択します。

最小と最大ワーカー数を構成します。

クラスターが実行されている場合、クラスターの詳細ページに、割り当てられたワーカーの数が表示されます。 割り当てられたワーカーの数をワーカー構成と比較し、必要に応じて調整を行うことができます。
重要
インスタンス プールを使用している場合は、次のようにします。
- 要求されたクラスター サイズが、プール内のアイドル状態のインスタンスの最小数以下になるようにします。 それより大きい場合、クラスターの起動時間はプールを使用しないクラスターと同じになります。
- 最大クラスター サイズが、プールの最大容量以下になるようにします。 それより大きい場合、クラスターの作成は失敗します。
自動スケーリングの例
静的クラスターを自動スケーリング クラスターに再構成すると、Azure Databricks では、即座に最小と最大境界内にクラスターのサイズを変更してから、自動スケーリングを開始します。 例として、次の表では、5 から 10 台のノードの間で自動スケーリングするようにクラスターを再構成した場合に、特定の初期サイズを持つクラスターがどうなるかを示しています。
| 初期サイズ | 再構成後のサイズ |
|---|---|
| 6 | 6 |
| 12 | 10 |
| 3 | 5 |
ローカル ストレージの自動スケール
多くの場合、特定のジョブに必要となるディスク領域を見積もることは困難です。 作成時にクラスターに接続するマネージド ディスクのギガバイト数を見積もらずに済むように、Azure Databricks では、すべての Azure Databricks クラスターでローカル ストレージの自動スケーリングが自動的に有効になります。
ローカル ストレージの自動スケーリングにより、Azure Databricks では、クラスターの Spark ワーカーでの使用可能な空きディスク領域量を監視します。 ワーカーでディスク領域の量が少なくなり始めると、ディスク領域が枯渇する前に、Databricks によって自動的に新しいマネージド ディスクがワーカーに接続されます。 ディスクは、仮想マシン 1 台につき 5 TB の合計ディスク領域制限 (仮想マシンの初期ローカル ストレージを含む) まで接続されます。
仮想マシンにアタッチされたマネージド ディスクは、仮想マシンが Azure に返された場合にのみデタッチされます。 つまり、マネージド ディスクは、実行中のクラスターの一部である限り、仮想マシンから切断されません。 マネージド ディスクの使用量をスケールダウンする場合、Azure Databricks では、クラスター サイズと自動スケールまたは想定外終了を使用して構成されたクラスターでこの機能を使用することが推奨されています。
ローカル ディスク暗号化
重要
この機能はパブリック プレビュー段階にあります。
クラスターの実行に使用するインスタンスの種類によっては、ローカルに接続されたディスクがある場合があります。 Azure Databricks は、これらのローカルに接続されたディスクにシャッフル データやエフェメラル データを格納できます。 クラスターのローカル ディスクに一時的に格納されるシャッフル データを含め、すべてのストレージの種類で、保存データが確実に暗号化されるようにするには、ローカル ディスクの暗号化を有効にできます。
重要
ローカル ボリュームとの間の暗号化されたデータの読み取りと書き込みによるパフォーマンスへの影響により、ワークロードの実行速度が低下する可能性があります。
ローカル ディスク暗号化が有効になっている場合、Azure Databricks によって各クラスター ノードに固有の暗号化キーがローカルで生成されます。これは、ローカル ディスクに格納されているすべてのデータを暗号化するために使用されます。 このキーのスコープは各クラスター ノードに対してローカルであり、クラスター ノード自体と共に破棄されます。 有効期間中、キーは暗号化と暗号化解除のためにメモリ内に存在し、ディスク上に暗号化されて格納されます。
ローカル ディスク暗号化を有効にするには、Clusters API を使用する必要があります。 クラスターの作成または編集中に、次を設定します。
{
"enable_local_disk_encryption": true
}
これらの API を呼び出す方法の例については、Clusters API に関するページを参照してください。
ローカル ディスク暗号化を有効にするクラスター作成呼び出しの例を次に示します。
{
"cluster_name": "my-cluster",
"spark_version": "7.3.x-scala2.12",
"node_type_id": "Standard_D3_v2",
"enable_local_disk_encryption": true,
"spark_conf": {
"spark.speculation": true
},
"num_workers": 25
}
[セキュリティ モード]
ワークスペースが Unity カタログに割り当てられている場合、高コンカレンシー クラスター モードではなくセキュリティ モードを使用して、アクセス制御の整合性を確保し、強力な分離保証を適用します。 高コンカレンシー クラスター モードは、Unity カタログでは使用できません。
[詳細オプション] で、次のクラスター セキュリティ モードから選択します:
- [なし]: 分離なし。 ワークスペースローカル テーブルのアクセス制御または資格情報のパススルーを適用しません。 Unity Catalog のデータにはアクセスできません。
- [単一ユーザー]: 1 人のユーザー (既定では、クラスターを作成したユーザー) のみが使用できます。 他のユーザーをクラスターにアタッチすることはできません。 [単一ユーザー] セキュリティ モードでクラスターからビューにアクセスすると、ユーザーのアクセス許可を使用してビューが実行されます。 単一ユーザー クラスターでは、Python、Scala、R を使用するワークロードがサポートされています。Init スクリプト、ライブラリのインストール、DBFS のマウントは単一ユーザー クラスターでサポートされています。 自動ジョブでは、単一ユーザー クラスターを使用する必要があります。
- [ユーザーの分離]: 複数のユーザーで共有できます。 SQL ワークロードのみがサポートされています。 クラスターのユーザー間に厳密な分離を適用するために、ライブラリのインストール、init スクリプト、DBFS のマウントは無効になっています。
- [テーブル ACL のみ (レガシ)]: ワークスペースローカルのテーブルのアクセス制御を適用しますが、Unity Catalog のデータにアクセスすることはできません。
- [パススルーのみ (レガシ)]: ワークスペースローカルの資格情報のパススルーを適用しますが、Unity Catalog のデータにはアクセスできません。
Unity Catalog のワークロードでサポートされるセキュリティ モードは、[単一ユーザー] と [ユーザーの分離] のみです。
詳細については、「アクセス モード」を参照してください。
Spark の構成
Spark ジョブを微調整するには、クラスター構成にカスタム Spark 構成プロパティを指定できます。
クラスター構成ページで、[詳細オプション] トグルをクリックします。
[Spark] タブをクリックします。
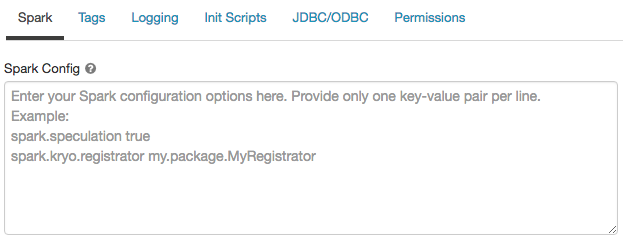
Spark 構成で、構成プロパティを 1 行につき 1 つのキーと値のペアとして入力します。
Cluster API を使用してクラスターを構成する場合は、クラスターの新規作成 API またはクラスター構成の更新 API の spark_conf フィールドに Spark プロパティを設定します。
Databricks では、グローバル init スクリプトの使用は推奨されません。
すべてのクラスターに対して Spark プロパティを設定するには、グローバル init スクリプトを作成します。
dbutils.fs.put("dbfs:/databricks/init/set_spark_params.sh","""
|#!/bin/bash
|
|cat << 'EOF' > /databricks/driver/conf/00-custom-spark-driver-defaults.conf
|[driver] {
| "spark.sql.sources.partitionOverwriteMode" = "DYNAMIC"
|}
|EOF
""".stripMargin, true)
シークレットから Spark 構成プロパティを取得する
Databricks では、パスワードなどの機密情報は、プレーンテキストではなくシークレットに格納することをお勧めしています。 Spark 構成でシークレットを参照するには、次の構文を使用します。
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
たとえば、password という Spark 構成プロパティを、secrets/acme_app/password に格納されているシークレットの値に設定するには、次のようにします。
spark.password {{secrets/acme-app/password}}
詳細については、「Spark の構成プロパティまたは環境変数のシークレットを参照する構文」を参照してください。
環境変数
クラスターで実行されている init スクリプトからアクセスできる環境変数を設定できます。 Databricks には、init スクリプトで使用できる定義済みの環境変数も用意されています。 これらの定義済みの環境変数をオーバーライドすることはできません。
クラスター構成ページで、[詳細オプション] トグルをクリックします。
[Spark] タブをクリックします。
[環境変数] フィールドに環境変数を設定します。
![[環境変数] フィールド](../../_static/images/clusters/environment-variables.png)
クラスターの新規作成 API またはクラスター構成の更新 API の spark_env_vars フィールドを使用して環境変数を設定することもできます。
クラスター タグ
クラスター タグを使用すると、組織内のさまざまなグループが使用するクラウド リソースのコストを簡単に監視できます。 クラスターを作成するときに、キーと値のペアとしてタグを指定できます。これらのタグは、Azure Databricks によって VM やディスク ボリュームなどのクラウド リソース、および DBU 使用状況レポートに適用されます。
プールから起動されたクラスターの場合、カスタム クラスター タグは DBU 使用状況レポートにのみ適用され、クラウド リソースには伝播しません。
プールおよびクラスター タグを組み合わせて使用する方法の詳細については、「タグを使用した使用状況の監視」をご覧ください。
便宜上、Azure Databricks では各クラスターに次の 4 つの既定タグが適用されます: Vendor、Creator、ClusterName、および ClusterId。
さらに、ジョブ クラスターでは、Azure Databricks によって次の 2 つの既定のタグが適用されます: RunName と JobId。
Databricks SQL によって使用されるリソースでは、Azure Databricks によって既定のタグ SqlWarehouseId も適用されます。
警告
キー Name を持つカスタム タグをクラスターに割り当てないでください。 すべてのクラスターにはタグ Name があり、この値は Azure Databricks によって設定されます。 キー Name に関連付けられている値を変更すると、Azure Databricks でそのクラスターを追跡できなくなります。 その結果、アイドル状態になってもクラスターが終了されない可能性があり、使用コストが引き続き発生することになります。
カスタム タグは、クラスターの作成時に追加できます。 クラスター タグを構成するには、次のようにします。
クラスター構成ページで、[詳細オプション] トグルをクリックします。
ページの下部にある [タグ] タブをクリックします。
![[タグ] タブ](../../_static/images/clusters/tags.png)
カスタム タグごとにキーと値のペアを追加します。 最大 43 個のカスタム タグを追加できます。
クラスターへの SSH アクセス
セキュリティ上の理由から、Azure Databricks では、SSH ポートは既定で閉じられています。 Spark クラスターへの SSH アクセスを有効にする場合は、Azure Databricks のサポートにお問い合わせください。
Note
SSH は、ワークスペースが独自の Azure 仮想ネットワークにデプロイされている場合にのみ有効にできます。
クラスター ログの配信
クラスターを作成するときに、Spark ドライバー ノード、ワーカー ノード、およびイベントのログを配信する場所を指定できます。 ログは、選択された宛先に 5 分ごとに配信されます。 クラスターが終了すると、終了するまでに生成されたすべてのログが配信されることが Azure Databricks によって保証されています。
ログの宛先は、クラスター ID によって異なります。 指定された宛先が dbfs:/cluster-log-delivery の場合、0630-191345-leap375 のクラスター ログは dbfs:/cluster-log-delivery/0630-191345-leap375 に配信されます。
ログの配信場所を構成するには、次のようにします。
クラスター構成ページで、[詳細オプション] トグルをクリックします。
[ログ] タブをクリックします。
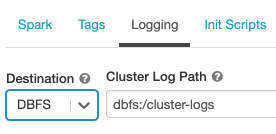
送信先の種類を選択します。
クラスター ログのパスを入力します。
注意
この機能は、REST API でも使用できます。 Clusters API に関するページを参照してください。
init スクリプト
クラスター ノードの初期化 (init) スクリプトは、Spark ドライバーまたはワーカー JVM が起動する "前"、各クラスター ノードの起動時に実行されるシェル スクリプトです。 init スクリプトを使用すると、Databricks ランタイムに含まれていないパッケージとライブラリのインストール、JVM システム クラスパスの変更、JVM で使用されるシステム プロパティと環境変数の設定、または Spark 構成パラメーターの変更などの構成タスクを実行できます。
init スクリプトをクラスターに接続するには、[詳細オプション] セクションを展開し、[init スクリプト] タブをクリックします。
詳細な手順については、「init スクリプトとは」を参照してください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示