データ ファイル サイズを制御するように Delta Lake を構成する
Delta Lake には、書き込みや OPTIMIZE 操作のためのターゲット ファイル サイズを手動か自動で構成するオプションがあります。 Azure Databricks は、これらの設定の多くを自動的に調整し、適切なファイル サイズを見つけてテーブルのパフォーマンスを自動的に向上させる機能を有効にします。
Note
Databricks Runtime 13.3 以上での Databricks では、Delta テーブル レイアウトにクラスタリングを使用することを推奨しています。 「Delta テーブルに Liquid Clustering クラスタリングを使用する」を参照してください。
Databricks では、予測最適化を使い、差分テーブルに対して OPTIMIZE と VACUUM を自動的に実行することをお勧めします。 「Delta Lake の予測最適化」を参照してください。
Databricks Runtime 10.4 LTS 以降では、自動圧縮と最適化された書き込みが、MERGE、UPDATE、DELETE の各操作に対して常に有効になっています。 この機能を無効にすることはできません。
特に指定がない限り、この記事のすべての推奨事項は、最新のランタイムを実行している Unity Catalog マネージド テーブルには適用されません。
SQL ウェアハウスまたは Databricks Runtime 11.3 LTS 以上を使用している場合、Unity Catalog マネージド テーブルについては、これらの構成のほとんどを Databricks が自動的に調整します。
ワークロードを Databricks Runtime 10.4 LTS 以前からアップグレードする場合は、「バックグラウンド自動圧縮にアップグレードする」を参照してください。
OPTIMIZE を実行する状況
自動圧縮と最適化された書き込みはそれぞれ小さなファイルの問題を減らしますが、OPTIMIZE の完全な置き換えではありません。 特に 1 TB を超えるテーブルの場合、Databricks では、ファイルをさらに統合するためにスケジュールに基づいて OPTIMIZE を実行することをお勧めします。 Azure Databricks はテーブルで自動的に ZORDER を実行しないため、データの拡張スキップを有効にするには、ZORDER を指定して OPTIMIZE を実行する必要があります。 「Delta Lake に対するデータのスキップ」を参照してください。
Azure Databricks での自動最適化とは
設定 delta.autoOptimize.autoCompact と delta.autoOptimize.optimizeWrite によって制御される機能を記述するために、"自動最適化" という用語が使用される場合があります。 この用語は、各設定を個別に記述することを優先して廃止されました。 「Delta Lake on Azure Databricks の自動圧縮」と「Delta Lake on Azure Databricks の最適化された書き込み」を参照してください。
Delta Lake on Azure Databricks の自動圧縮
自動圧縮では、Delta テーブル パーティション内の小さなファイルを結合して、小さなファイルの問題を自動的に軽減します。 自動圧縮は、テーブルへの書き込みが成功した後に発生し、その書き込みを実行したクラスター上で同期的に実行されます。 自動圧縮は、前に圧縮されていないファイルのみを圧縮します。
Spark 構成spark.databricks.delta.autoCompact.maxFileSize を設定することで、出力ファイル サイズを制御できます。 Databricks では、ワークロードまたはテーブル サイズに基づく自動チューニングを使用することをお勧めします。 「ワークロードに基づいてファイル サイズを自動チューニングする」と「テーブル サイズに基づいてファイル サイズを自動チューニングする」を参照してください。
自動圧縮は、最小限の数の小さなファイルがあるパーティションまたはテーブルに対してのみトリガーされます。 必要に応じて、spark.databricks.delta.autoCompact.minNumFiles を設定して、自動圧縮をトリガーするために必要なファイルの最小数を変更できます。
自動圧縮は、次の設定を使用して、テーブルまたはセッション レベルで有効できます。
- テーブル プロパティ:
delta.autoOptimize.autoCompact - SparkSession の設定:
spark.databricks.delta.autoCompact.enabled
これらの設定は、次のオプションを受け付けます。
| オプション | 動作 |
|---|---|
auto (推奨) |
他の自動チューニング機能を考慮しながら、ターゲット ファイル サイズを調整します。 Databricks Runtime 10.4 LTS 以降が必要です。 |
legacy |
true の別名。 Databricks Runtime 10.4 LTS 以降が必要です。 |
true |
ターゲット ファイル サイズとして 128 MB を使用します。 動的なサイズ設定なし。 |
false |
自動圧縮をオフにします。 セッション レベルで設定して、ワークロードで変更されたすべての Delta テーブルの自動圧縮をオーバーライドできます。 |
重要
Databricks Runtime 9.1 LTS 以下では、他の書き込み処理が DELETE、MERGE、UPDATE、または OPTIMIZE などの操作を同時に実行すると、自動圧縮によって、それらの他のジョブがトランザクションの競合で失敗する可能性があります。 この問題は、Databricks Runtime 10.4 LTS 以降では発生しません。
Delta Lake on Azure Databricks の最適化された書き込み
最適化された書き込みでは、データが書き込まれるときにファイル サイズを改善し、テーブルの後続の読み取りを向上させます。
最適化された書き込みは、各パーティションに書き込まれる小さなファイルの数を減らすため、パーティション テーブルに最も効果的です。 少数の大きなファイルへの書き込みは、多数の小さなファイルへの書き込みよりも効率的ですが、それでも書き込み待機時間が長くなる可能性があります。書き込み前にデータがシャッフルされるためです。
最適化された書き込みのしくみを次の図に示します。
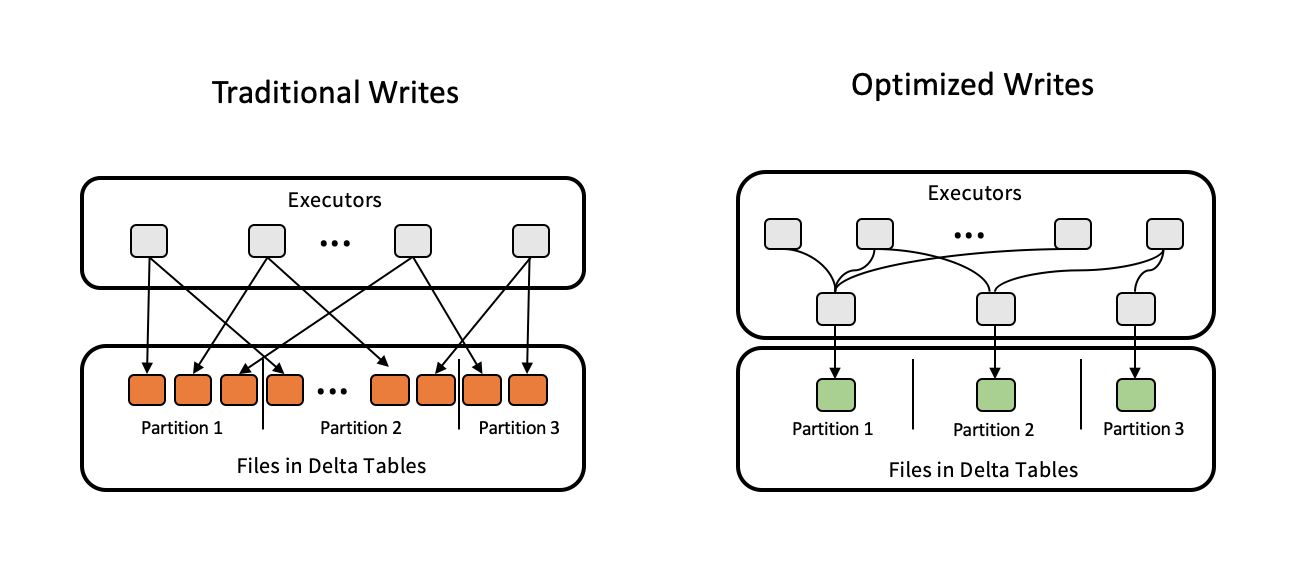
Note
書き込まれたファイルの数を制御するために、データを書き出す直前に coalesce(n) または repartition(n) を実行するコードが使用される場合があります。 最適化された書き込みでは、このパターンを使用する必要がなくなります。
Databricks Runtime 9.1 LTS 以降では、最適化された書き込みが次の操作で既定で有効になっています。
MERGE- サブクエリをともなう
UPDATE - サブクエリをともなう
DELETE
SQL ウェアハウスを使用するときは、CTAS ステートメントと INSERT 操作についても最適化された書き込みが有効になります。 Databricks Runtime 13.3 LTS 以降では、Unity Catalog に登録されているすべての Delta テーブルで、パーティション テーブルの CTAS ステートメントと INSERT 操作に対して最適化された書き込みが有効になっています。
最適化された書き込みは、次の設定を使用して、テーブルまたはセッション レベルで有効できます。
- テーブルの設定:
delta.autoOptimize.optimizeWrite - SparkSession の設定:
spark.databricks.delta.optimizeWrite.enabled
これらの設定は、次のオプションを受け付けます。
| オプション | 動作 |
|---|---|
true |
ターゲット ファイル サイズとして 128 MB を使用します。 |
false |
最適化された書き込みをオフにします。 セッション レベルで設定して、ワークロードで変更されたすべての Delta テーブルの自動圧縮をオーバーライドできます。 |
ターゲット ファイル サイズを設定する
Delta テーブル内のファイルのサイズを調整する場合は、テーブルのプロパティdelta.targetFileSize を目的のサイズに設定します。 このプロパティを設定すると、すべてのデータ レイアウト最適化操作で、指定されたサイズのファイルを生成するためのベストエフォートの試みが行われます。 ここの例には最適化または Z オーダー、自動圧縮、および最適化された書き込みが含まれています。
注意
Unity Catalog マネージド テーブルと SQL ウェアハウスまたは Databricks Runtime 11.3 LTS 以上を使用するときは、OPTIMIZE コマンドのみが targetFileSize 設定を考慮します。
| テーブルのプロパティ |
|---|
| delta.targetFileSize 型: サイズ (バイト以上の単位)。 ターゲット ファイルのサイズ。 たとえば、 104857600 (バイト) または 100mb。既定値: なし |
既存のテーブルでは、SQL コマンド ALTER TABLE SET TBL PROPERTIES を使用して、プロパティを設定および設定解除できます。 また、これらのプロパティは、Spark セッション構成を使用して、新しいテーブルの作成時にも自動的に設定できます。 詳細については、「Delta テーブル プロパティのリファレンス」を参照してください。
ワークロードに基づいてファイル サイズを自動チューニングする
Databricks では、Databricks Runtime、Unity Catalog、またはその他の最適化に関係なく、多くの MERGE または DML 操作の対象であるすべてのテーブルに対してテーブル プロパティ delta.tuneFileSizesForRewrites を true に設定することをお勧めします。 true に設定すると、テーブルのターゲット ファイル サイズがはるかに低いしきい値に設定され、書き込み集中型の操作が高速化されます。
明示的に設定されていない場合、Azure Databricks は Delta テーブルに対する直近の 10 回の操作のうち 9 回が MERGE 操作であるかどうかを自動的に検出し、このテーブル プロパティを true に設定します。 この動作を回避するために、このプロパティを false に明示的に設定する必要があります。
| テーブルのプロパティ |
|---|
| delta.tuneFileSizesForRewrites 次のコマンドを入力します: Booleanデータ レイアウトの最適化のためにファイル サイズを調整するかどうか。 既定値: なし |
既存のテーブルでは、SQL コマンド ALTER TABLE SET TBL PROPERTIES を使用して、プロパティを設定および設定解除できます。 また、これらのプロパティは、Spark セッション構成を使用して、新しいテーブルの作成時にも自動的に設定できます。 詳細については、「Delta テーブル プロパティのリファレンス」を参照してください。
テーブル サイズに基づいてファイル サイズを自動チューニングする
手動による調整の必要性を最小限に抑えるために、Azure Databricks では、テーブルのサイズに基づいて Delta テーブルのファイル サイズを自動的に調整します。 Azure Databricks では、小さなテーブルには小さなファイル サイズを使用し、大きなテーブルには大きなファイル サイズを使用して、テーブル内のファイルの数が増えすぎないようにします。 特定のターゲット サイズを使用して、または頻繁に書き換えられるワークロードに基づいて調整したテーブルは、Azure Databricks によって自動調整されません。
ターゲット ファイル サイズは、Delta テーブルの現在のサイズに基づきます。 2.56 TB 未満のテーブルの場合、自動調整後のターゲット ファイル サイズは 256 MB です。 サイズが 2.56 TB から 10 TB のテーブルの場合、ターゲット サイズは 256 MB から 1 GB に直線的に拡大します。 10 TB を超えるテーブルの場合、ターゲット ファイル サイズは 1 GB です。
注意
テーブルのターゲット ファイル サイズが拡大した場合、既存のファイルは OPTIMIZE コマンドによって大きなファイルに再最適化されません。 したがって、1 つの大きなテーブルに常に、ターゲット サイズより小さなファイルが複数含まれる可能性があります。 これらの小さなファイルも大きなファイルに最適化する必要がある場合は、delta.targetFileSize テーブル プロパティを使用してテーブルに対して固定したターゲット ファイル サイズを構成できます。
テーブルが増分書き込みされる場合、ターゲット ファイル サイズとファイル数は、テーブルのサイズに基づいて、ほぼ次のようになります。 このテーブル内のファイル数は 1 つの例です。 実際の結果は、多くの要因によって異なります。
| テーブルのサイズ | ターゲット ファイル サイズ | テーブル内のファイルのおおよその数 |
|---|---|---|
| 10 GB | 256 MB | 40 |
| 1 TB (テラバイト) | 256 MB | 4096 |
| 2.56 TB | 256 MB | 10240 |
| 3 TB | 307 MB | 12108 |
| 5 TB | 512 MB | 17339 |
| 7 TB | 716 MB | 20784 |
| 10 TB | 1 GB | 24437 |
| 20 TB | 1 GB | 34437 |
| 50 TB | 1 GB | 64437 |
| 100 TB | 1 GB | 114437 |
データ ファイルに書き込まれる行を制限する
場合によっては、ナロー (ロング) データのテーブルでは、特定のデータ ファイル内の行数が Parquet 形式のサポート制限を超えるというエラーが発生する可能性があります。 このエラーを回避するために、SQL セッション構成 spark.sql.files.maxRecordsPerFile を使用して、 Delta Lake テーブルの 1 つのファイルに書き込むレコードの最大数を指定できます。 0 または負の値の値を指定すると、制限がないことを示します。
Databricks Runtime 11.3 LTS 以降では、DataFrame API を使用して Delta Lake テーブルに書き込むときに、DataFrameWriter オプション maxRecordsPerFile を使用することもできます。 maxRecordsPerFile が指定されると、SQL セッション構成 spark.sql.files.maxRecordsPerFile の値は無視されます。
注意
Databricks では、前述のエラーを回避する必要がない限り、このオプションの使用はお勧めしません。 それでも、ナロー度合いが非常に高いデータを含む一部の Unity Catalog マネージド テーブルでこの設定が必要になる場合があります。
バックグラウンド自動圧縮にアップグレードする
バックグラウンド自動圧縮は、Databricks Runtime 11.3 LTS 以降の Unity Catalog マネージド テーブルで利用できます。 レガシ ワークロードまたはテーブルを移行する場合は、次の手順を実行します。
- クラスターまたはノートブックの構成設定から Spark 構成
spark.databricks.delta.autoCompact.enabledを削除します。 - テーブルごとに、
ALTER TABLE <table_name> UNSET TBLPROPERTIES (delta.autoOptimize.autoCompact)を実行してレガシ自動圧縮設定を削除します。
これらのレガシ構成を削除すると、すべての Unity Catalog マネージド テーブルに対してバックグラウンド自動圧縮が自動的にトリガーされることが確認できます。