Azure Databricks 上のファイルを操作する
Azure Databricks では、次の場所にあるファイルを操作するための複数のユーティリティと API が提供されます。
- Unity Catalog ボリューム
- ワークスペース ファイル
- クラウド オブジェクト ストレージ
- DBFS マウントと DBFS ルート
- クラスターのドライバー ノードにアタッチされたエフェメラル ストレージ
この記事では、次のツールについて、これらの場所にあるファイルを操作する例を紹介します。
- Apache Spark
- Spark SQL と Databricks SQL
- Databricks ファイル システム ユーティリティ (
dbutils.fsまたは%fs) - Databricks CLI
- Databricks REST API
- Bash シェル コマンド (
%sh) %pipを使用したノートブック スコープのライブラリのインストール- Pandas
- OSS Python ファイル管理と処理ユーティリティ
重要
データへの FUSE アクセスが必要なファイル操作では、URI を使用してクラウド オブジェクト ストレージに直接アクセスできません。 Databricks では、Unity Catalog ボリュームを使用して、FUSE に対するこれらの場所へのアクセスを構成することをお勧めします。
Scala は、シングル ユーザー アクセス モードで構成されたコンピューティングまたは Unity Catalog を使用しないクラスター上の Unity Catalog ボリュームまたはワークスペース ファイル用の FUSE をサポートしません。 Scala は、Unity Catalog と共有アクセス モードで構成されたコンピューティング上で Unity Catalog ボリュームとワークスペース ファイル用の FUSE をサポートします。
データにアクセスするために URI スキームを指定する必要はありますか?
Azure Databricks のデータ アクセス パスは、次のいずれかの標準に従います。
URI スタイル パスには URI スキームが含まれます。 Databricks ネイティブ データ アクセス ソリューションでは、URI スキームはほとんどのユース ケースで省略可能です。 クラウド オブジェクト ストレージのデータに直接アクセスする場合は、ストレージの種類に応じて適切な URI スキームを指定する必要があります。
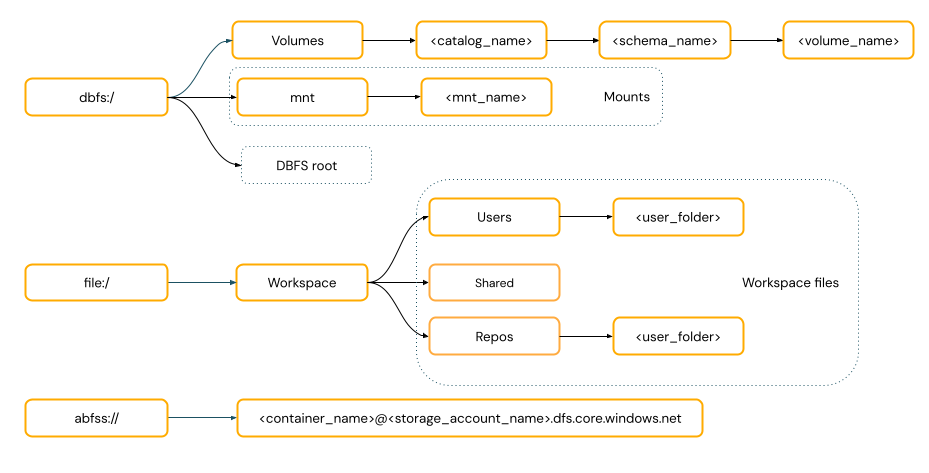
POSIX スタイル パスは、ドライバー ルート (
/) に相対するデータ アクセスを提供します。 POSIX スタイル パスではスキームは必要ありません。 Unity Catalog ボリュームまたは DBFS マウントを使用して、クラウド オブジェクト ストレージのデータに POSIX スタイルでアクセスできます。 多くの ML フレームワークやその他の OSS Python モジュールでは FUSE が必須で、POSIX スタイル パスのみ使用できます。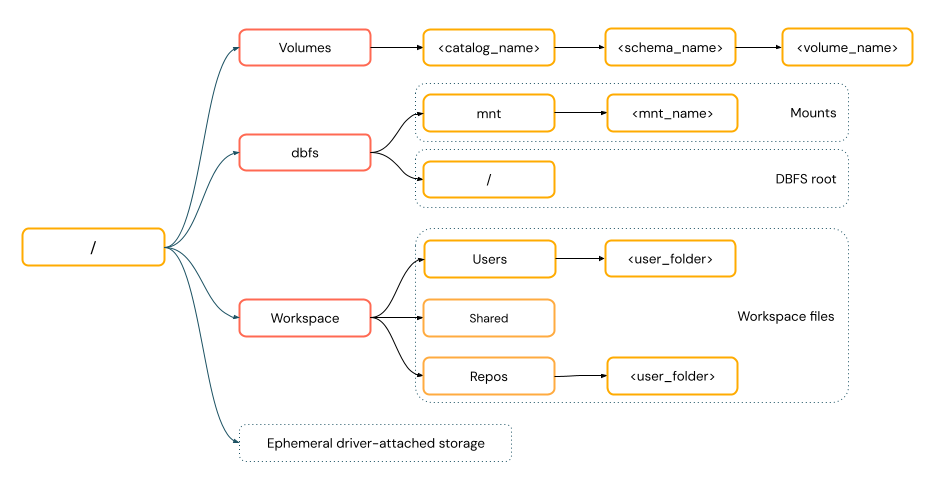
Unity Catalog でファイルを操作する
Databricks では、Unity Catalog ボリュームを使用して、クラウド オブジェクト ストレージ内の表形式以外のデータ ファイルへのアクセスを構成することをお勧めします。 「ボリュームを作成して操作する」を参照してください。
| ツール | 例 |
|---|---|
| Apache Spark | spark.read.format("json").load("/Volumes/my_catalog/my_schema/my_volume/data.json").show() |
| Spark SQL と Databricks SQL | SELECT * FROM csv.`/Volumes/my_catalog/my_schema/my_volume/data.csv`; LIST '/Volumes/my_catalog/my_schema/my_volume/'; |
| Databricks ファイル システム ユーティリティ | dbutils.fs.ls("/Volumes/my_catalog/my_schema/my_volume/") %fs ls /Volumes/my_catalog/my_schema/my_volume/ |
| Databricks CLI | databricks fs cp /path/to/local/file dbfs:/Volumes/my_catalog/my_schema/my_volume/ |
| Databricks REST API | POST https://<databricks-instance>/api/2.1/jobs/create {"name": "A multitask job", "tasks": [{..."libraries": [{"jar": "/Volumes/dev/environment/libraries/logging/Logging.jar"}],},...]} |
| Bash シェル コマンド | %sh curl http://<address>/text.zip -o /Volumes/my_catalog/my_schema/my_volume/tmp/text.zip |
| ライブラリのインストール | %pip install /Volumes/my_catalog/my_schema/my_volume/my_library.whl |
| Pandas | df = pd.read_csv('/Volumes/my_catalog/my_schema/my_volume/data.csv') |
| OSS Python | os.listdir('/Volumes/my_catalog/my_schema/my_volume/path/to/directory') |
Note
dbfs:/ スキーマは、Databricks CLI を操作する場合に必要です。
ボリュームの制限事項
ボリュームには、次の制限事項があります。
Zip や Excel ファイルの書き込みなど、直接追加や連続しない (ランダムな) 書き込みはサポートされていません。 直接追加やランダム書き込みのワークロードでは、まずローカル ディスク上で操作を実行し、その結果を Unity Catalog ボリュームにコピーします。 次に例を示します。
# python import xlsxwriter from shutil import copyfile workbook = xlsxwriter.Workbook('/local_disk0/tmp/excel.xlsx') worksheet = workbook.add_worksheet() worksheet.write(0, 0, "Key") worksheet.write(0, 1, "Value") workbook.close() copyfile('/local_disk0/tmp/excel.xlsx', '/Volumes/my_catalog/my_schema/my_volume/excel.xlsx')スパース ファイルはサポートされていません。 スパース ファイルをコピーするには、
cp --sparse=neverを使用します。$ cp sparse.file /Volumes/my_catalog/my_schema/my_volume/sparse.file error writing '/dbfs/sparse.file': Operation not supported $ cp --sparse=never sparse.file /Volumes/my_catalog/my_schema/my_volume/sparse.file
ワークスペース ファイルを操作する
Databricks ワークスペース ファイルは、ワークスペース内のノートブックではないファイルのセットです。 ワークスペース ファイルを使用して、ノートブックやその他のワークスペース アセットと一緒に保存されたデータやその他のファイルに保存したり、アクセスしたりできます。 ワークスペース ファイルにはサイズ制限があるため、Databricks では主に開発およびテスト用に小さなデータ ファイルのみをここに保存することをお勧めします。
| ツール | 例 |
|---|---|
| Apache Spark | spark.read.format("json").load("file:/Workspace/Users/<user-folder>/data.json").show() |
| Spark SQL と Databricks SQL | SELECT * FROM json.`file:/Workspace/Users/<user-folder>/file.json`; |
| Databricks ファイル システム ユーティリティ | dbutils.fs.ls("file:/Workspace/Users/<user-folder>/") %fs ls file:/Workspace/Users/<user-folder>/ |
| Databricks CLI | databricks workspace list |
| Databricks REST API | POST https://<databricks-instance>/api/2.0/workspace/delete {"path": "/Workspace/Shared/code.py", "recursive": "false"} |
| Bash シェル コマンド | %sh curl http://<address>/text.zip -o /Workspace/Users/<user-folder>/text.zip |
| ライブラリのインストール | %pip install /Workspace/Users/<user-folder>/my_library.whl |
| Pandas | df = pd.read_csv('/Workspace/Users/<user-folder>/data.csv') |
| OSS Python | os.listdir('/Workspace/Users/<user-folder>/path/to/directory') |
Note
file:/ スキーマは、Databricks Utilities、Apache Spark、または SQL を操作する場合に必要です。
ワークスペース ファイルの制限事項
ワークスペース ファイルには、次の制限事項があります。
UI では、ワークスペース ファイルのサイズは 500 MB に制限されています。 クラスターからの書き込み時に許容される最大ファイル サイズは 256 MB です。
ワークフローでリモート Git リポジトリにあるソース コードを使っている場合、現在のディレクトリに書き込んだり、相対パスを使って書き込んだりすることはできません。 ほかの場所オプションにデータを書き込んでください。
ワークスペース ファイルに保存するときに
gitコマンドを使用することはできません。 ワークスペース ファイルでは、.gitディレクトリの作成は許可されません。サーバーレス コンピューティングからのワークスペース ファイル操作のサポートには制限があります。
Executor はワークスペース ファイルに書き込めません。
シンボリックリンクはサポートされていません。
共有アクセス モードを使用しているクラスター上のユーザー定義関数 (UDF) からワークスペース ファイルにアクセスすることはできません。
削除されたワークスペース ファイルはどこに移動しますか?
ワークスペース ファイルを削除すると、ごみ箱に送信されます。 UI を使用して、ごみ箱からファイルを復旧または完全に削除できます。
「オブジェクトを削除する」を参照してください。
クラウド オブジェクト ストレージ内のファイルを操作する
Databricks では、Unity Catalog ボリュームを使用して、クラウド オブジェクト ストレージ内のファイルへのセキュリティで保護されたアクセスを構成することをお勧めします。 URI を使用してクラウド オブジェクト ストレージのデータに直接アクセスすることを選択する場合は、アクセス許可を構成する必要があります。 「外部の場所、外部テーブル、外部ボリュームを管理する」を参照してください。
次の例では、クラウド オブジェクト ストレージのデータにアクセスするために URI を使用しています。
| ツール | 例 |
|---|---|
| Apache Spark | spark.read.format("json").load("abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json").show() |
| Spark SQL と Databricks SQL | SELECT * FROM csv.`abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json`; LIST 'abfss://container-name@storage-account-name.dfs.core.windows.net/path'; |
| Databricks ファイル システム ユーティリティ | dbutils.fs.ls("abfss://container-name@storage-account-name.dfs.core.windows.net/path/") %fs ls abfss://container-name@storage-account-name.dfs.core.windows.net/path/ |
| Databricks CLI | サポートされていません |
| Databricks REST API | サポートされていません |
| Bash シェル コマンド | サポートされていません |
| ライブラリのインストール | %pip install abfss://container-name@storage-account-name.dfs.core.windows.net/path/to/library.whl |
| Pandas | サポートされていません |
| OSS Python | サポートされていません |
Note
クラウド オブジェクト ストレージでは、資格情報のパススルーはサポートされていません。
DBFS マウントと DBFS ルートでファイルを操作する
DBFS マウントは Unity Catalog を使用してセキュリティ保護することはできず、Databricks では推奨していません。 DBFS ルートの格納データには、ワークスペース内のすべてのユーザーがアクセスできます。 Databricks では、機密コードまたは運用コードを DBFS ルートに格納しないことをお勧めしています。 「Databricks ファイル システム (DBFS) とは」を参照してください。
| ツール | 例 |
|---|---|
| Apache Spark | spark.read.format("json").load("/mnt/path/to/data.json").show() |
| Spark SQL と Databricks SQL | SELECT * FROM json.`/mnt/path/to/data.json`; |
| Databricks ファイル システム ユーティリティ | dbutils.fs.ls("/mnt/path") %fs ls /mnt/path |
| Databricks CLI | databricks fs cp dbfs:/mnt/path/to/remote/file /path/to/local/file |
| Databricks REST API | POST https://<host>/api/2.0/dbfs/delete --data '{ "path": "/tmp/HelloWorld.txt" }' |
| Bash シェル コマンド | %sh curl http://<address>/text.zip > /dbfs/mnt/tmp/text.zip |
| ライブラリのインストール | %pip install /dbfs/mnt/path/to/my_library.whl |
| Pandas | df = pd.read_csv('/dbfs/mnt/path/to/data.csv') |
| OSS Python | os.listdir('/dbfs/mnt/path/to/directory') |
Note
dbfs:/ スキーマは、Databricks CLI を操作する場合に必要です。
ドライバー ノードにアタッチされたエフェメラル ストレージでファイルを操作する
ドライバー ノードにアタッチされたエフェメラル ストレージは、ネイティブな POSIX ベースのパスのアクセスを使用したブロック ストレージです。 この場所の任意の格納データは、クラスターが終了または再起動した場合に表示されなくなります。
| ツール | 例 |
|---|---|
| Apache Spark | サポートされていません |
| Spark SQL と Databricks SQL | サポートされていません |
| Databricks ファイル システム ユーティリティ | dbutils.fs.ls("file:/path") %fs ls file:/path |
| Databricks CLI | サポートされていません |
| Databricks REST API | サポートされていません |
| Bash シェル コマンド | %sh curl http://<address>/text.zip > /tmp/text.zip |
| ライブラリのインストール | サポートされていません |
| Pandas | df = pd.read_csv('/path/to/data.csv') |
| OSS Python | os.listdir('/path/to/directory') |
Note
file:/ スキーマは、Databricks Utilities を操作する場合に必要です。
エフェメラル ストレージからボリュームにデータを移動する
Apache Spark を使用して、エフェメラル ストレージにダウンロードされたデータまたは保存データにアクセスする必要がある場合があります。 エフェメラル ストレージはドライバーにアタッチされ、Spark は分散処理エンジンであるため、ここにあるデータに直接アクセスできない操作もあります。 ドライバー ファイル システムから Unity Catalog ボリュームにデータを移動する必要がある場合は、次の例のようにマジック コマンドまたは Databricks ユーティリティを使用してファイルをコピーできます。
dbutils.fs.cp ("file:/<path>", "/Volumes/<catalog>/<schema>/<volume>/<path>")
%sh cp /<path> /Volumes/<catalog>/<schema>/<volume>/<path>
%fs cp file:/<path> /Volumes/<catalog>/<schema>/<volume>/<path>