
This article explains how to trigger partition pruning in Delta Lake MERGE INTO (AWS | Azure | GCP) queries from Databricks.
Partition pruning is an optimization technique to limit the number of partitions that are inspected by a query.
Discussion
MERGE INTO can be computationally expensive if done inefficiently. You should partition the underlying data before using MERGE INTO. If you do not, query performance can be negatively impacted.
The main lesson is this: if you know which partitions a MERGE INTO query needs to inspect, you should specify them in the query so that partition pruning is performed.
Demonstration: no partition pruning
Here is an example of a poorly performing MERGE INTO query without partition pruning.
Start by creating the following Delta table, called delta_merge_into:
%scala
val df = spark.range(30000000)
.withColumn("par", ($"id" % 1000).cast(IntegerType))
.withColumn("ts", current_timestamp())
.write
.format("delta")
.mode("overwrite")
.partitionBy("par")
.saveAsTable("delta_merge_into")
Then merge a DataFrame into the Delta table to create a table called update:
%scala
val updatesTableName = "update"
val targetTableName = "delta_merge_into"
val updates = spark.range(100).withColumn("id", (rand() * 30000000 * 2).cast(IntegerType))
.withColumn("par", ($"id" % 2).cast(IntegerType))
.withColumn("ts", current_timestamp())
.dropDuplicates("id")
updates.createOrReplaceTempView(updatesTableName)
The update table has 100 rows with three columns, id, par, and ts. The value of par is always either 1 or 0.
Let’s say you run the following simple MERGE INTO query:
%scala
spark.sql(s"""
|MERGE INTO $targetTableName
|USING $updatesTableName
|ON $targetTableName.id = $updatesTableName.id
|WHEN MATCHED THEN
| UPDATE SET $targetTableName.ts = $updatesTableName.ts
|WHEN NOT MATCHED THEN
| INSERT (id, par, ts) VALUES ($updatesTableName.id, $updatesTableName.par, $updatesTableName.ts)
""".stripMargin)
The query takes 13.16 minutes to complete:
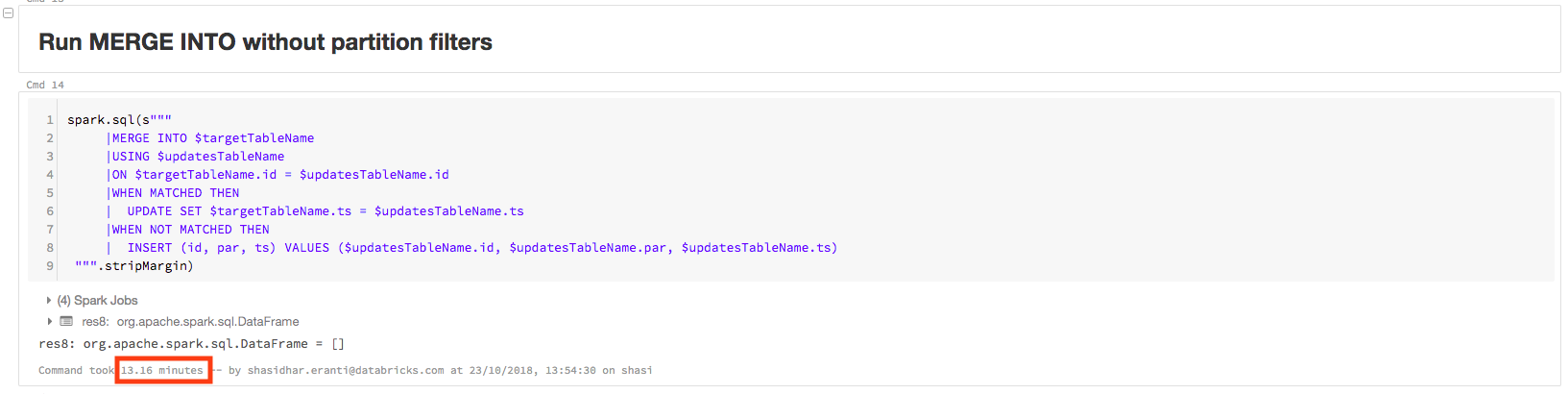
The physical plan for this query contains PartitionCount: 1000, as shown below. This means Apache Spark is scanning all 1000 partitions in order to execute the query. This is not an efficient query, because the update data only has partition values of 1 and 0:
== Physical Plan ==
*(5) HashAggregate(keys=[], functions=[finalmerge_count(merge count#8452L) AS count(1)#8448L], output=[count#8449L])
+- Exchange SinglePartition
+- *(4) HashAggregate(keys=[], functions=[partial_count(1) AS count#8452L], output=[count#8452L])
+- *(4) Project
+- *(4) Filter (isnotnull(count#8440L) && (count#8440L > 1))
+- *(4) HashAggregate(keys=[_row_id_#8399L], functions=[finalmerge_sum(merge sum#8454L) AS sum(cast(one#8434 as bigint))#8439L], output=[count#8440L])
+- Exchange hashpartitioning(_row_id_#8399L, 200)
+- *(3) HashAggregate(keys=[_row_id_#8399L], functions=[partial_sum(cast(one#8434 as bigint)) AS sum#8454L], output=[_row_id_#8399L, sum#8454L])
+- *(3) Project [_row_id_#8399L, UDF(_file_name_#8404) AS one#8434]
+- *(3) BroadcastHashJoin [cast(id#7514 as bigint)], [id#8390L], Inner, BuildLeft, false
:- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint)))
: +- *(2) HashAggregate(keys=[id#7514], functions=[], output=[id#7514])
: +- Exchange hashpartitioning(id#7514, 200)
: +- *(1) HashAggregate(keys=[id#7514], functions=[], output=[id#7514])
: +- *(1) Filter isnotnull(id#7514)
: +- *(1) Project [cast(((rand(8188829649009385616) * 3.0E7) * 2.0) as int) AS id#7514]
: +- *(1) Range (0, 100, step=1, splits=36)
+- *(3) Filter isnotnull(id#8390L)
+- *(3) Project [id#8390L, _row_id_#8399L, input_file_name() AS _file_name_#8404]
+- *(3) Project [id#8390L, monotonically_increasing_id() AS _row_id_#8399L]
+- *(3) Project [id#8390L, par#8391, ts#8392]
+- *(3) FileScan parquet [id#8390L,ts#8392,par#8391] Batched: true, DataFilters: [], Format: Parquet, Location: TahoeBatchFileIndex[dbfs:/user/hive/warehouse/delta_merge_into], PartitionCount: 1000, PartitionFilters: [], PushedFilters: [], ReadSchema: struct<id:bigint,ts:timestamp>
Solution
Rewrite the query to specify the partitions.
This MERGE INTO query specifies the partitions directly:
%scala
spark.sql(s"""
|MERGE INTO $targetTableName
|USING $updatesTableName
|ON $targetTableName.par IN (1,0) AND $targetTableName.id = $updatesTableName.id
|WHEN MATCHED THEN
| UPDATE SET $targetTableName.ts = $updatesTableName.ts
|WHEN NOT MATCHED THEN
| INSERT (id, par, ts) VALUES ($updatesTableName.id, $updatesTableName.par, $updatesTableName.ts)
""".stripMargin)
Now the query takes just 20.54 seconds to complete on the same cluster:
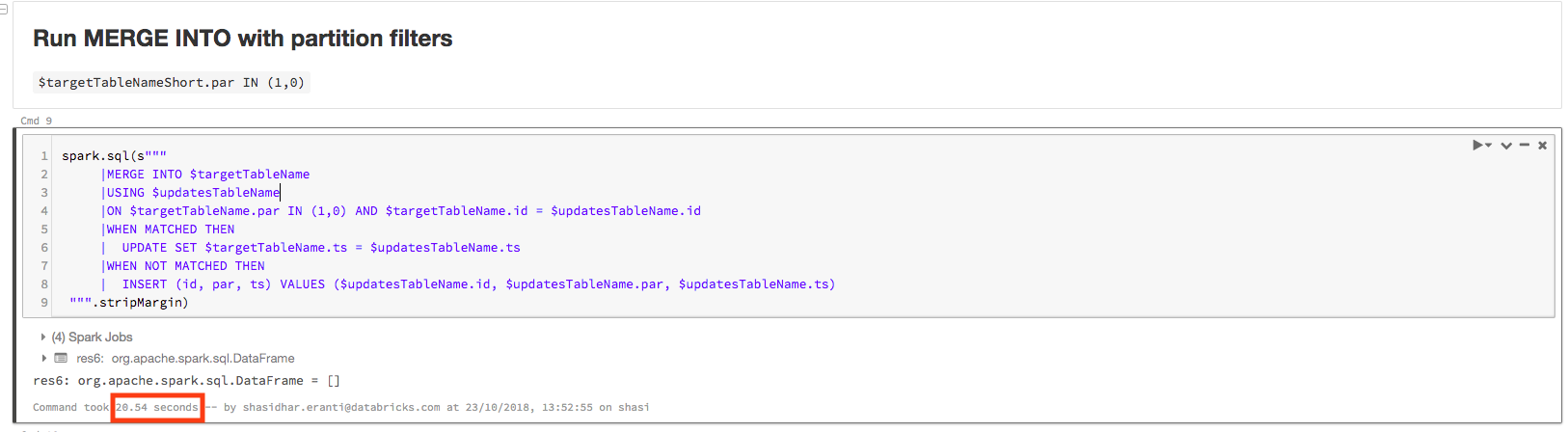
The physical plan for this query contains PartitionCount: 2, as shown below. With only minor changes, the query is now more than 40X faster:
== Physical Plan ==
*(5) HashAggregate(keys=[], functions=[finalmerge_count(merge count#7892L) AS count(1)#7888L], output=[count#7889L])
+- Exchange SinglePartition
+- *(4) HashAggregate(keys=[], functions=[partial_count(1) AS count#7892L], output=[count#7892L])
+- *(4) Project
+- *(4) Filter (isnotnull(count#7880L) && (count#7880L > 1))
+- *(4) HashAggregate(keys=[_row_id_#7839L], functions=[finalmerge_sum(merge sum#7894L) AS sum(cast(one#7874 as bigint))#7879L], output=[count#7880L])
+- Exchange hashpartitioning(_row_id_#7839L, 200)
+- *(3) HashAggregate(keys=[_row_id_#7839L], functions=[partial_sum(cast(one#7874 as bigint)) AS sum#7894L], output=[_row_id_#7839L, sum#7894L])
+- *(3) Project [_row_id_#7839L, UDF(_file_name_#7844) AS one#7874]
+- *(3) BroadcastHashJoin [cast(id#7514 as bigint)], [id#7830L], Inner, BuildLeft, false
:- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint)))
: +- *(2) HashAggregate(keys=[id#7514], functions=[], output=[id#7514])
: +- Exchange hashpartitioning(id#7514, 200)
: +- *(1) HashAggregate(keys=[id#7514], functions=[], output=[id#7514])
: +- *(1) Filter isnotnull(id#7514)
: +- *(1) Project [cast(((rand(8188829649009385616) * 3.0E7) * 2.0) as int) AS id#7514]
: +- *(1) Range (0, 100, step=1, splits=36)
+- *(3) Project [id#7830L, _row_id_#7839L, _file_name_#7844]
+- *(3) Filter (par#7831 IN (1,0) && isnotnull(id#7830L))
+- *(3) Project [id#7830L, par#7831, _row_id_#7839L, input_file_name() AS _file_name_#7844]
+- *(3) Project [id#7830L, par#7831, monotonically_increasing_id() AS _row_id_#7839L]
+- *(3) Project [id#7830L, par#7831, ts#7832]
+- *(3) FileScan parquet [id#7830L,ts#7832,par#7831] Batched: true, DataFilters: [], Format: Parquet, Location: TahoeBatchFileIndex[dbfs:/user/hive/warehouse/delta_merge_into], PartitionCount: 2, PartitionFilters: [], PushedFilters: [], ReadSchema: struct<id:bigint,ts:timestamp>