Unity Catalog の特徴エンジニアリング
このページでは、Unity Catalog で特徴テーブルを作成して操作する方法について説明します。
このページの内容は、Unity Catalog に対して有効になっているワークスペースにのみ該当します。 お使いのワークスペースが Unity Catalog に対して有効になっていない場合、「ワークスペース特徴量ストアで特徴量を操作する」を参照してください。
要件
Unity Catalog の特徴エンジニアリングには、Databricks Runtime 13.2 以降が必要です。 さらに、Unity Catalog メタストアには特権モデル バージョン 1.0 が必要です。
Unity Catalog Python クライアントの機能エンジニアリングをインストールする
Unity Catalog の機能エンジニアリングは、Python クライアント FeatureEngineeringClient を提供します。 クラスは PyPI から databricks-feature-engineering パッケージで入手でき、Databricks Runtime 13.2 ML 以降にはプレインストールされています。 ML 以外の Databricks Runtime を使用している場合は、クライアントを手動でインストールする必要があります。 互換性対応表を使用して、ご使用の Databricks Runtime バージョンに適したバージョンを見つけてください。
%pip install databricks-feature-engineering
dbutils.library.restartPython()
Unity Catalog で特徴テーブルのカタログとスキーマを作成する
特徴テーブルのために新しいカタログを作成するか、既存のカタログを使用する必要があります。
新しいカタログを作成するには、メタストアに対する CREATE CATALOG 権限が必要です。
CREATE CATALOG IF NOT EXISTS <catalog-name>
既存のカタログを使用するには、カタログに対する USE CATALOG 特権が必要です。
USE CATALOG <catalog-name>
Unity Catalog の特徴テーブルはスキーマに格納する必要があります。 カタログに新しいスキーマを作成するには、カタログに対する CREATE SCHEMA 権限が必要です。
CREATE SCHEMA IF NOT EXISTS <schema-name>
Unity Catalog で特徴テーブルを作成する
Note
Unity Catalog の既存の Delta テーブルを特徴量テーブルとして使用することができます。 「Unity Catalog の既存の Delta テーブルを特徴テーブルとして使用する」を参照してください。
Unity Catalog の既存の Delta Live テーブルを特徴量テーブルとして使用することもできます。 「Delta Live Tables パイプラインによって作成された既存のストリーミング テーブルまたは具体化されたビューを特徴テーブルとして使用する」を参照してください。
Unity Catalog の特徴量テーブルは Unity Catalog によって管理される Delta テーブルまたは Delta Live Tables です。 特徴テーブルには主キーが必要です。 Unity Catalog の特徴テーブルの名前には、<catalog-name>.<schema-name>.<table-name> という 3 レベル構造があります。
Databricks SQL または Python FeatureEngineeringClient を使用して、Unity Catalog に特徴量 Delta テーブルを作成できます。 Delta Live Tables パイプラインを使用して、Unity Catalog に特徴量 Delta Live Tables を作成できます。
Databricks SQL
特徴テーブルとして、主キー制約がある任意の Delta テーブルを使用できます。 次のコードは、主キーを使用したテーブルの作成方法を示しています。
CREATE TABLE ml.recommender_system.customer_features (
customer_id int NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id)
);
時系列特徴テーブルを作成するには、主キー列として時間列を追加し、TIMESERIES キーワードを指定します。 TIMESERIES キーワードを使用するには、Databricks Runtime 13.3 LTS 以上が必要です。
CREATE TABLE ml.recommender_system.customer_features (
customer_id int NOT NULL,
ts timestamp NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id, ts TIMESERIES)
);
テーブルを作成したら、他の Delta テーブルを記述するのと同じ方法でデータを書き込みます。そのテーブルは、特徴テーブルとして使用できます。
Python
以下の例で使用されているコマンドとパラメーターの詳細については、「Feature Engineering Python API リファレンス」を参照してください。
- 特徴をコンピューティングする Python 関数を記述します。 各関数の出力は、一意の主キーを持つ Apache Spark DataFrame である必要があります。 主キーは、1 つ以上の列で構成できます。
- 特徴テーブルを作成するには
FeatureEngineeringClientをインスタンス化し、create_tableを使用します。 write_tableを使用して特徴テーブルを設定します。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
# Prepare feature DataFrame
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
customer_features_df = compute_customer_features(df)
# Create feature table with `customer_id` as the primary key.
# Take schema from DataFrame output by compute_customer_features
customer_feature_table = fe.create_table(
name='ml.recommender_system.customer_features',
primary_keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_table` and specify the `df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fe.create_table(
# ...
# df=customer_features_df,
# ...
# )
# To use a composite primary key, pass all primary key columns in the create_table call
# customer_feature_table = fe.create_table(
# ...
# primary_keys=['customer_id', 'date'],
# ...
# )
# To create a time series table, set the timeseries_columns argument
# customer_feature_table = fe.create_table(
# ...
# primary_keys=['customer_id', 'date'],
# timeseries_columns='date',
# ...
# )
Delta Live Tables
Note
Delta Live Tables のテーブル制約はパブリック プレビュー段階にあります。 次のコード例は、Delta Live Tables プレビュー チャネルを使用して実行する必要があります。
特徴量テーブルとして、主キー制約がある任意の Delta Live Table を使用できます。 次のコードは、主キーを使用した Delta Live Table の作成方法を示しています。
CREATE LIVE TABLE customer_features (
customer_id int NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id)
) AS SELECT * FROM ...;
時系列特徴テーブルを作成するには、主キー列として時間列を追加し、TIMESERIES キーワードを指定します。
CREATE LIVE TABLE customer_features (
customer_id int NOT NULL,
ts timestamp NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id, ts TIMESERIES)
) AS SELECT * FROM ...;
テーブルを作成したら、他の Delta Live Table を記述するのと同じ方法でデータを書き込みます。そのテーブルは、特徴量テーブルとして使用できます。
Delta Live テーブルのテーブル制約は、SQL でのみサポートされます。 Python で宣言された Delta Live Tables に主キーを設定するには、「Delta Live Tables パイプラインによって作成された既存のストリーミング テーブルまたは具体化されたビューを特徴テーブルとして使用する」を参照してください。
Unity Catalog の既存の Delta テーブルを特徴テーブルとして使用する
主キーを持つ Unity Catalog の Delta テーブルは、Unity Catalog の特徴テーブルにすることができ、そのテーブルを使用して Features UI や API を使用できます。
Note
- 主キー制約を宣言できるのは、テーブルの所有者だけです。 所有者の名前は、Catalog Explorer のテーブルの詳細ページに表示されます。
- Delta テーブルのデータ型が Unity Catalog の特徴エンジニアリングでサポートされていることを確認します。 「サポートされるデータ型」を参照してください。
- TIMESERIES キーワードを使用するには、Databricks Runtime 13.3 LTS 以上が必要です。
既存の Delta テーブルに主キー制約がない場合は、次の手順で作成します。
主キー列を
NOT NULLに設定します。 主キー列ごとに、次を実行します。ALTER TABLE <full_table_name> ALTER COLUMN <pk_col_name> SET NOT NULLテーブルを変更して主キー制約を追加します。
ALTER TABLE <full_table_name> ADD CONSTRAINT <pk_name> PRIMARY KEY(pk_col1, pk_col2, ...)pk_nameは主キー制約の名前です。 規則により、_pkサフィックスを付けたテーブル名 (スキーマとカタログなし) を使用します。 たとえば、名前が"ml.recommender_system.customer_features"のテーブルには主キー制約の名前としてcustomer_features_pkが与えられます。このテーブルを時系列特徴テーブルにするには、次のように、主キー列のいずれかに TIMESERIES キーワードを指定します。
ALTER TABLE <full_table_name> ADD CONSTRAINT <pk_name> PRIMARY KEY(pk_col1 TIMESERIES, pk_col2, ...)テーブルに主キー制約を追加すると、Features UI にテーブルが表示され、それを特徴テーブルとして使用できます。
Delta Live Tables パイプラインによって作成された既存のストリーミング テーブルまたは具体化されたビューを特徴テーブルとして使用する
主キーを持つ Unity Catalog の ストリーミング テーブルまたは具体化されたビューは、Unity Catalog の特徴テーブルにすることができ、そのテーブルを使用して Features UI や API を使用できます。
Note
- Delta Live Tables のテーブル制約はパブリック プレビュー段階にあります。 次のコード例は、Delta Live Tables プレビュー チャネルを使用して実行する必要があります。
- 主キー制約を宣言できるのは、テーブルの所有者だけです。 所有者の名前は、Catalog Explorer のテーブルの詳細ページに表示されます。
- Delta テーブルのデータ型が Unity Catalog の特徴エンジニアリングでサポートされていることを確認します。 「サポートされるデータ型」を参照してください。
SQL を使用して作成されたストリーミング テーブルまたは具体化されたビューに主キーを追加する
SQL を使用して作成された既存のストリーミング テーブルまたは具体化されたビューに主キーを設定するには、そのテーブルを管理するノートブック内のストリーミング テーブルまたは具体化されたビューのスキーマを更新します。 次に、Unity Catalog に適用する制約のテーブルを更新します。
コードは次のようになります。
CREATE OR REFRESH MATERIALIZED VIEW existing_live_table(
id int NOT NULL PRIMARY KEY,
...
) AS SELECT ...
Python を使用して作成されたストリーミング テーブルまたは具体化されたビューに主キーを追加する
Delta Live Tables パイプラインによって作成された既存のストリーミング テーブルまたは具体化されたビューに主キーを作成するには、ストリーミング テーブルまたは具体化されたビューが Python を使用して作成された場合でも、SQL を使用する必要があります。 新しい SQL ノートブックを作成して、既存のものから読み取る新しいストリーミング テーブルまたは具体化されたビューを定義します。 次に、既存の Delta Live Tables パイプラインまたは新しいパイプラインのステップとしてそのノートブックを実行します。
新しい SQL ノートブックには、次のようなコードが含まれている必要があります。
CREATE OR REFRESH MATERIALIZED VIEW new_live_table_with_constraint(
id int NOT NULL PRIMARY KEY,
...
) AS SELECT * FROM existing_live_table
Unity Catalog の特徴テーブルへのアクセスを制御する
Unity Catalog の特徴テーブルのアクセス制御は、Unity Catalog によって管理されます。 「Unity Catalog の特権」を参照してください。
Unity Catalog の特徴テーブルを更新する
Unity Catalog の特徴テーブルを更新するには、新しい特徴を追加するか、主キーに基づいて特定の行を変更します。
次の特徴テーブルのメタデータは更新しないでください。
- 主キー
- パーティション キーです。
- 既存の特徴の名前またはデータ型。
変更すると、モデルのトレーニングや提供に特徴を利用するダウンストリーム パイプラインが壊れます。
Unity Catalog の既存の特徴テーブルに新しい特徴を追加する
既存の特徴テーブルに新しい特徴を追加するには、次の 2 つの方法があります。
- 既存の特徴評価関数を更新し、返された DataFrame を使用して
write_tableを実行します。 これにより、特徴テーブル スキーマが更新され、主キーに基づいて新しい特徴値がマージされます。 - 新しい特徴の値を計算する新しい特徴評価関数を作成します。 この新しい評価関数によって返される DataFrame には、特徴テーブルの主キーとパーティション キー (定義されている場合) が含まれている必要があります。 DataFrame を使用して
write_tableを実行し、同じ主キーを使用して既存の特徴テーブルに新しい特徴を書き込みます。
特徴テーブル内の特定の行のみを更新する
write_table で mode = "merge" を使用します。 write_table 呼び出しで送信された DataFrame に主キーが存在しない行は変更されません。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
fe.write_table(
name='ml.recommender_system.customer_features',
df = customer_features_df,
mode = 'merge'
)
特徴テーブルを更新するジョブをスケジュールする
特徴テーブルの特徴に常に最新の値が含まれるようにするため、Databricks では、毎日のように定期的に特徴テーブルを更新するノートブックを実行するジョブを作成することをお勧めします。 スケジュールされていないジョブが既に作成されている場合は、スケジュールされたジョブに変換して、特徴の値が常に最新になるようにします。
特徴テーブルを更新するコードでは、次の例に示すように mode='merge' を使用します。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
customer_features_df = compute_customer_features(data)
fe.write_table(
df=customer_features_df,
name='ml.recommender_system.customer_features',
mode='merge'
)
日次特徴の過去の値を格納する
複合主キーを使用して特徴テーブルを定義します。 主キーに日付を含めます。 たとえば、特徴テーブル customer_features の場合、効率的な読み取りのために複合主キー (date、customer_id) とパーティション キー date を使用できます。
Databricks SQL
CREATE TABLE ml.recommender_system.customer_features (
customer_id int NOT NULL,
`date` date NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (`date`, customer_id)
)
PARTITIONED BY (`date`)
COMMENT "Customer features";
Python
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
fe.create_table(
name='ml.recommender_system.customer_features',
primary_keys=['date', 'customer_id'],
partition_columns=['date'],
schema=customer_features_df.schema,
description='Customer features'
)
その後、特徴テーブルの date のフィルター処理から関心のある期間まで読み取るコードを作成できます。
create_training_set または score_batch を使用するときにポイントインタイム検索を有効にする時系列特徴テーブルを作成することもできます。 「Unity Catalog で特徴テーブルを作成する」を参照してください。
特徴テーブルを最新の状態に保つには、定期的にスケジュールされたジョブを設定して特徴を書き込むか、新しい特徴の値を特徴テーブルにストリーム配信します。
ストリーミング機能評価パイプラインを作成して特徴を更新する
ストリーミング機能評価パイプラインを作成するには、ストリーミング DataFrame を引数として write_table に渡します。 このメソッドから StreamingQuery オブジェクトが返されます。
def compute_additional_customer_features(data):
''' Returns Streaming DataFrame
'''
pass
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
customer_transactions = spark.readStream.load("dbfs:/events/customer_transactions")
stream_df = compute_additional_customer_features(customer_transactions)
fe.write_table(
df=stream_df,
name='ml.recommender_system.customer_features',
mode='merge'
)
Unity Catalog の特徴テーブルから読み込む
特徴の値を読み取る場合は、read_table を使用します。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
customer_features_df = fe.read_table(
name='ml.recommender_system.customer_features',
)
Unity Catalog で特徴テーブルを検索し、参照する
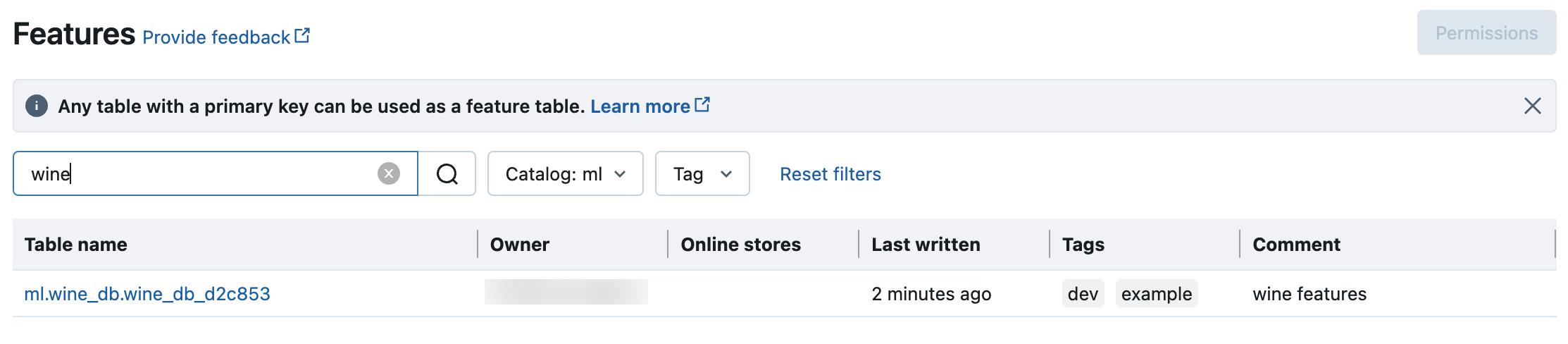
Features UI を使用して Unity Catalog で特徴テーブルを検索し、参照します。
サイドバーの
 特徴をクリックすると、Features UI が表示されます。
特徴をクリックすると、Features UI が表示されます。カタログ セレクターでカタログを選択すると、そのカタログで利用できるすべての特徴テーブルが表示されます。 検索ボックスに、特徴テーブル、特徴、またはコメントの名前の全部または一部を入力します。 タグのキーまたは値のすべてまたは一部を入力することもできます。 検索テキストでは大文字と小文字が区別されません。
Unity Catalog で特徴テーブルのメタデータを取得する
get_table を使用して特徴テーブルのメタデータを取得します。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
ft = fe.get_table(name="ml.recommender_system.user_feature_table")
print(ft.features)
Unity Catalog の特徴テーブルと特徴にタグを使用する
タグ (単純なキーと値のペア) を使用して、特徴テーブルと特徴を分類および管理できます。
特徴テーブルの場合は、Catalog Explorer UI、Databricks SQL、または Feature Engineering Python API を使用してタグを作成、編集、削除できます。
特徴の場合は、Catalog Explorer UI または Databricks SQL を使用してタグを作成、編集、削除できます。
次の例は、Feature Engineering Python API を使用して、特徴テーブルのタグを作成、更新、削除する方法を示しています。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
# Create feature table with tags
customer_feature_table = fe.create_table(
# ...
tags={"tag_key_1": "tag_value_1", "tag_key_2": "tag_value_2", ...},
# ...
)
# Upsert a tag
fe.set_feature_table_tag(name="customer_feature_table", key="tag_key_1", value="new_key_value")
# Delete a tag
fe.delete_feature_table_tag(name="customer_feature_table", key="tag_key_2")
Unity Catalog の特徴テーブルを削除する
Unity Catalog の特徴テーブルを削除するには、Catalog Explorer を使用するか Feature Engineering Python API を使用して、Unity Catalog の Delta テーブルを直接削除します。
Note
- 特徴テーブルを削除すると、アップストリーム プロデューサーとダウンストリーム コンシューマー (モデル、エンドポイント、スケジュールされたジョブ) で予期しないエラーが発生する可能性があります。 公開済みのオンライン ストアは、クラウド プロバイダーで削除する必要があります。
- Unity Catalog の特徴テーブルを削除すると、基になる Delta テーブルも削除されます。
drop_tableは Databricks Runtime 13.1 ML 以前ではサポートされていません。 SQL コマンドを使用してテーブルを削除します。
Databricks SQL または FeatureEngineeringClient.drop_table を使用し、Unity Catalog の特徴テーブルを削除できます。
Databricks SQL
DROP TABLE ml.recommender_system.customer_features;
Python
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
fe.drop_table(
name='ml.recommender_system.customer_features'
)