Azure Databricks での MLOps ワークフロー
この記事では、Databricks プラットフォームで MLOps を使用して、機械学習 (ML) システムのパフォーマンスと長期的な効率を最適化する方法について説明します。 MLOps アーキテクチャに関する一般的なレコメンデーションが含まれており、ML 開発から運用プロセスのモデルとして使用できる Databricks プラットフォームを使用した一般化されたワークフローについて説明します。
詳細については、「MLOps のビッグ ブック」を参照してください。
MLOps とは
MLOps は、コード、データ、モデルを管理するための一連のプロセスと自動化された手順です。 DevOps、DataOps、ModelOps を組み合わせます。
コード、データ、モデルなどの ML 資産は、アクセス制限が厳しくなく、厳密にテストされていない初期の開発段階から、中間テスト ステージを通じて、厳密に制御された最終的な運用ステージに進む段階で開発されます。 Databricks プラットフォームを使用すると、統合されたアクセス制御を使用して、1 つのプラットフォームでこれらの資産を管理できます。 同じプラットフォームでデータ アプリケーションと ML アプリケーションを開発できるため、データの移動に伴うリスクと遅延を軽減できます。
MLOps に関する一般的なレコメンデーション
このセクションには、Databricks 上の MLOps に関するいくつかの一般的なレコメンデーションと、詳細な情報のリンクが含まれています。
各ステージ毎に個別の環境を作成する
実行環境は、モデルとデータがコードによって作成または使用される場所です。 各実行環境は、コンピューティング インスタンス、ランタイムとライブラリ、および自動化されたジョブで構成されます。
Databricks では、ML コードのさまざまなステージと、ステージ間の切り替えを明確に定義したモデル開発用に個別の環境を作成することをお勧めします。 この記事で説明するワークフローは、ステージの共通名を使用して、このプロセスに従います。
その他の構成は、組織の特定のニーズを満たすためにも使用できます。
アクセス制御とバージョン管理
アクセス制御とバージョン管理は、ソフトウェア操作プロセスの主要なコンポーネントです。 Databricks では次を行うことを推奨しています。
- バージョン コントロールに Git を使用する。 パイプラインとコードは、バージョン管理のために Git に格納する必要があります。 ステージ間での ML ロジックの移動は、開発ブランチからステージング ブランチ、リリース ブランチへのコードの移動と解釈できます。 Databricks Git フォルダーを使用して Git プロバイダーと統合し、ノートブックとソース コードを Databricks ワークスペースと同期します。 Databricks には、Git 統合とバージョン管理のための追加のツールも用意されています。開発者ツールとガイダンスを参照してください。
- Delta テーブルを使用してレイクハウスのアーキテクチャにデータを格納します。 データは、クラウド アカウントの レイクハウスのアーキテクチャ に格納する必要があります。 生データと特徴テーブルの両方を、読み取りおよび変更できるユーザーを決定するために、アクセス制御を持つ デルタ テーブル として格納する必要があります。
- MLflow を使用してモデル開発を管理します。 MLflow を使用してモデル開発プロセスを追跡し、コード スナップショット、モデル パラメーター、メトリック、およびその他のメタデータを保存できます。
- Unity Catalog のモデルを使用して、モデル ライフサイクルを管理します。 Unity Catalog のモデルを使用して、モデルのバージョン、ガバナンス、デプロイ状態を管理します。
モデルではなく、コードをデプロイする
ほとんどの場合、Databricks では、ML 開発プロセス中に、モデルではなくコードをある環境から次の環境にレベルを上げることをお勧めします。 このようにプロジェクト資産を移動すると、ML 開発プロセスのすべてのコードが同じコード レビューと統合テスト プロセスを通過します。 また、モデルの実稼働バージョンが運用コードでトレーニングされるようにします。 オプションとトレードオフの詳細については、「モデル デプロイ パターン」を参照してください。
推奨される MLOps ワークフロー
次のセクションでは、開発、ステージング、運用の 3 つの各ステージをカバーする一般的な MLOps ワークフローについて説明します。
このセクションでは、"データ サイエンティスト" と "ML エンジニア" という用語を典型的なペルソナとして使用します。MLOps ワークフローにおける特定の役割と責任は、チームと組織によって異なります。
開発段階
開発ステージの焦点は実験です。 データ サイエンティストは、特徴量とモデルを開発し、実験を実行してモデルのパフォーマンスを最適化します。 開発プロセスの出力は、特徴量計算、モデルのトレーニング、推論、監視を含めることができる ML パイプライン コードです。
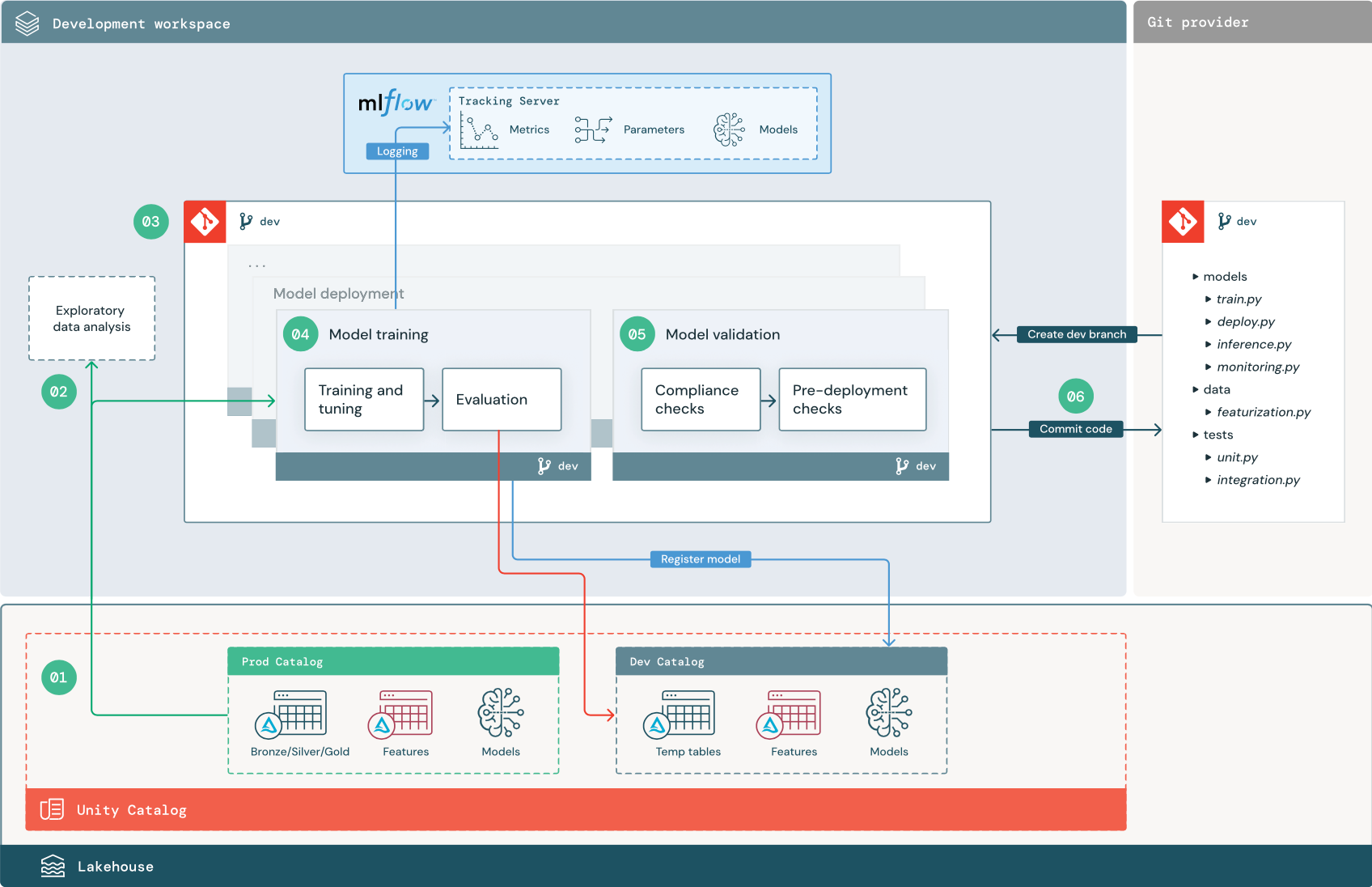
以下に示す番号付きのステップは、ダイアグラムに示された番号に対応します。
1. データ ソース
開発環境は、Unity Catalog の開発カタログによって表されます。 データ サイエンティストは、開発ワークスペースで一時データと特徴量テーブルを作成するため、開発カタログへの読み取り/書き込みアクセス権を持ちます。 開発ステージで作成されたモデルは、開発カタログに登録されます。
開発ワークスペースで作業するデータ サイエンティストは、運用カタログ内の運用データへの読み取り専用アクセスも持っていることが理想的です。 データ サイエンティストに運用カタログ内の運用データ、推論テーブル、メトリック テーブルへの読み取りアクセスを許可することで、データ サイエンティストは現在の運用モデルの予測とパフォーマンスを分析できます。 データ サイエンティストは、実験と分析のために運用モデルを読み込むこともできる必要があります。
運用カタログへの読み取り専用アクセスを許可できない場合は、運用データのスナップショットを開発カタログに書き込んで、データ サイエンティストがプロジェクト コードを開発および評価できるようにすることができます。
2. 探索的データ分析 (EDA)
データ サイエンティストは、ノートブックを使用して、対話型の反復プロセスでデータを探索および分析します。 目標は、利用可能なデータがビジネス上の問題を解決する可能性を持っているかどうかを評価することです。 この手順において、データ サイエンティストはモデル トレーニングのためのデータ準備と特徴量化手順の特定を開始します。 このアドホック プロセスは、通常、他の実行環境にデプロイされるパイプラインの一部にはなりません。
Databricks AutoML は、データセットのベースライン モデルを生成することで、このプロセスを加速します。 AutoML は、一連の試行を実行して記録し、各試行の実行のソース コードが含まれた Python ノートブックを提供するため、ユーザーはそのコードの確認、再現、変更を行えます。 また、AutoML は、データセットの概要統計も計算し、その情報をユーザーが確認できるノートブックに保存します。
3. コード
コード リポジトリには、ML プロジェクトのすべてのパイプライン、モジュール、およびその他のプロジェクト ファイルが含まれています。 データ サイエンティストは、プロジェクト リポジトリの開発 (“dev”) ブランチに新しいパイプラインや更新されたパイプラインを作成します。 データ サイエンティストは、EDA とプロジェクトの初期フェーズから、リポジトリ内で作業してコードを共有し変更を追跡する必要があります。
4.モデルをトレーニングする (開発)
データ サイエンティストは、開発カタログまたは運用カタログのテーブルを使用して、開発環境でモデル トレーニング パイプラインを開発します。
このパイプラインには、次の 2 つのタスクが含まれています。
トレーニングとチューニング。 トレーニング プロセスは、モデルのパラメーター、メトリック、成果物を MLflow 追跡サーバーにログ記録します。 ハイパーパラメーターのトレーニングとチューニング後に、モデル、モデルがトレーニングされた入力データ、およびモデルの生成に使用されたコードの間のリンクを記録するために、最終的なモデル成果物が追跡サーバーにログ記録されます。
評価。 保留データをテストしてモデルの品質を評価します。 これらのテストの結果は、MLflow 追跡サーバーにログ記録されます。 評価の目的は、新しく開発されたモデルが現在の運用モデルよりも優れたパフォーマンスを発揮するかを決定することです。 十分なアクセス許可があれば、運用カタログに登録されているどの運用モデルも開発ワークスペースに読み込み、新しくトレーニングされたモデルと比較できます。
組織のガバナンス要件にモデルに関する追加情報が含まれている場合は、MLflow 追跡を使用して保存できます。 典型的な成果物は、SHAP によって生成されたプロットのようなプレーン テキストの説明とモデル解釈です。 特定のガバナンス要件は、データ ガバナンス責任者またはビジネスの利害関係者によってもたらされる場合があります。
モデル トレーニング パイプラインの出力は、開発環境用の MLflow 追跡サーバーに保存される ML モデル成果物です。 パイプラインがステージング ワークスペースまたは運用ワークスペースで実行されると、モデル成果物はそのワークスペースの MLflow 追跡サーバーに保存されます。
モデル トレーニングが完了したら、モデルを Unity Catalog に登録します。 モデル パイプラインが実行された環境 (この例では開発カタログ) に対応するカタログにモデルを登録するようにパイプライン コードを設定します。
推奨アーキテクチャでは、最初のタスクがモデル トレーニング パイプラインで、その後にモデル検証タスクとモデル デプロイ タスクが続くマルチタスク Databricks ワークフローをデプロイします。 モデル トレーニング タスクは、モデル検証タスクが使用できるモデル URI を生成します。 タスク値を使用して、この URI をモデルに渡すことができます。
5.モデルを検証してデプロイする (開発)
モデル トレーニング パイプラインに加えて、モデル検証パイプラインやモデル デプロイ パイプラインなどの他のパイプラインも開発環境で開発されます。
モデルの検証。 モデル検証パイプラインは、モデル トレーニング パイプラインからモデル URI を取得し、Unity Catalog からモデルを読み込み、検証チェックを実行します。
検証チェックはコンテキストに依存します。 これには、形式や必要なメタデータの確認などの基本的なチェックと、あらかじめ定義されたコンプライアンスのチェックや選択したデータ スライスでのモデル パフォーマンスの確認など、規制が厳しい業界で必要とされる場合があるより複雑なチェックを含めることができます。
モデル検証パイプラインの主な機能は、モデルがデプロイ手順に進むべきかどうかを決定することです。 モデルがデプロイ前のチェックに合格した場合は、Unity Catalog 内で “Challenger” エイリアスを割り当てることができます。 チェックが失敗すると、プロセスは終了します。 検証の失敗をユーザーに通知するようにワークフローを構成できます。 「ジョブ イベントのメール通知とシステム通知を追加する」を参照してください。
モデル デプロイ。 モデル デプロイ パイプラインは、通常、エイリアス更新を使用して新しくトレーニングされた “Challenger” モデルを “Champion” 状態に直接昇格するか、既存の “Champion” モデルと新しい “Challenger” モデルの比較を支援します。 このパイプラインでは、Model Serving エンドポイントなど、何らかの必要な推論インフラストラクチャを設定することもできます。 モデル デプロイ パイプラインに関連する手順の詳細については、「運用」を参照してください。
6. コードをコミットする
トレーニング、検証、デプロイ、およびその他のパイプライン用のコードを開発した後、データ サイエンティストまたは ML エンジニアは、開発ブランチの変更をソース管理にコミットします。
ステージング ステージ
このステージの焦点は、ML パイプライン コードをテストして、運用の準備ができていることを確認することです。 モデル トレーニング用のコードや特徴エンジニアリング パイプライン、推論コードなど、すべての ML パイプライン コードがこのステージでテストされます。
ML エンジニアは、このステージで実行される単体テストと統合テストを実装する CI パイプラインを作成します。 ステージング プロセスの出力は、CI/CD システムをトリガーして実稼働ステージを開始するリリース ブランチです。
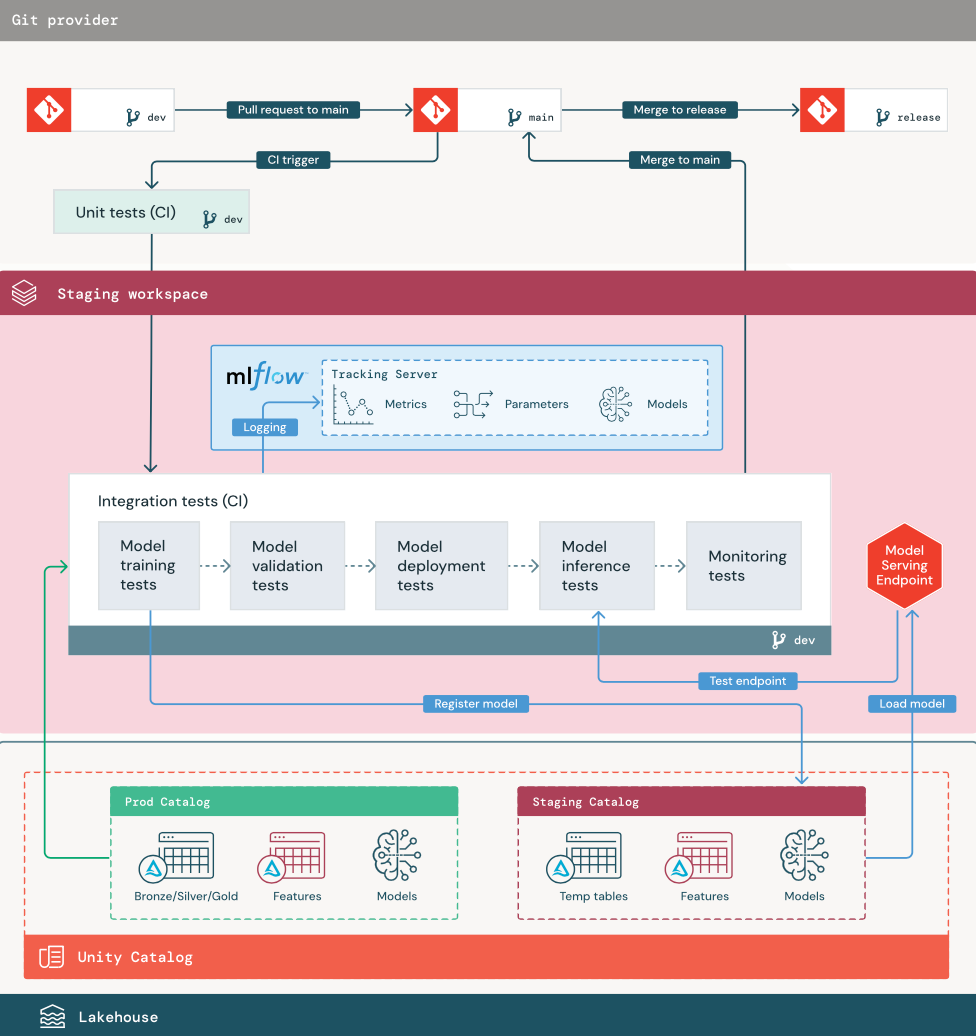
1.Data
ステージング環境は、ML パイプラインをテストし、モデルを Unity Catalog に登録するための独自のカタログを Unity Catalog 内に持っている必要があります。 このカタログは、図の中で “staging” カタログとして表示されています。 このカタログに書き込まれる資産は一般的に一時的なもので、テストが完了するまでしか保持されません。 開発環境では、デバッグ目的でこのステージング カタログへのアクセスも必要になる場合があります。
2.コードをマージする
データ サイエンティストは、開発または運用カタログのテーブルを使用して、開発環境でモデル トレーニング パイプラインを開発します。
pull request。 デプロイ プロセスは、ソース管理内のプロジェクトのメイン ブランチに対して pull request が作成されると開始されます。
単体テスト (CI)。 pull request によってソース コードが自動的にビルドされ、単体テストがトリガーされます。 単体テストが失敗した場合、pull request は拒否されます。
単体テストはソフトウェア開発プロセスの一部であり、何らかのコードの開発中に継続的に実行され、コードベースに追加されます。 CI パイプラインの一部として単体テストを実行することによって、開発ブランチで行われた変更が既存の機能を壊さないことが保証されます。
3. 統合テスト (CI)
その後、CI プロセスによって統合テストが実行されます。 統合テストでは、すべてのパイプライン (特徴エンジニアリング、モデル トレーニング、推論、監視を含む) を実行して、それらが正しく連携して機能することを確認します。 ステージング環境は、合理的な範囲で運用環境と一致する必要があります。
リアルタイム推論を含む ML アプリケーションをデプロイする場合は、ステージング環境でサービス インフラストラクチャを作成してテストする必要があります。 これには、ステージング環境にサービス エンドポイントを作成し、モデルを読み込むモデル デプロイ パイプラインのトリガーが含まれます。
統合テストの実行に必要な時間を短縮するために、いくつかの手順では、テストの忠実性と速度やコストの間のトレードオフのバランスを取る場合があります。 たとえば、モデルのトレーニングが高価だったり時間がかかる場合は、データの小さなサブセットを使用したり、実行するトレーニングの反復回数を減らす場合があります。 モデル提供に関しては、運用要件に応じて、統合テストでフルスケールのロード テストを行う場合もあれば、小規模なバッチ ジョブや一時的なエンドポイントへの要求をテストする場合もあります。
4. ステージング ブランチにマージする
すべてのテストが合格であれば、その新しいコードはプロジェクトのメイン ブランチにマージされます。 テストが失敗した場合、CI/CD システムはユーザーに通知を行い、pull request に結果を投稿する必要があります。
メイン ブランチで定期的な統合テストをスケジュールすることができます。 これは、ブランチが複数のユーザーからの並行した pull request で頻繁に更新される場合に適した考え方です。
5. リリース ブランチの作成
CI テストが合格となり、開発ブランチがメイン ブランチにマージされると、ML エンジニアはリリース ブランチを作成し、これによって CI/CD システムがトリガーされて運用ジョブが更新されます。
運用環境のステージ
ML エンジニアは、ML パイプラインがデプロイされ実行される運用環境を所有しています。 これらのパイプラインは、モデル トレーニングのトリガー、新しいモデル バージョンの検証とデプロイ、ダウンストリーム テーブルまたはアプリケーションへの予測の発行、パフォーマンスの低下と不安定性を回避するためのプロセス全体の監視を行います。
通常、データ サイエンティストは運用環境で書き込みアクセスまたはコンピューティング アクセス権を持っていません。 ただし、データ サイエンティストが、テスト結果、ログ、モデル成果物、運用パイプラインの状態、および監視テーブルに対する可視性を持っていることが重要です。 この可視性により、データ サイエンティストは、運用における問題を特定して診断し、新しいモデルのパフォーマンスを現在運用中のモデルと比較することができます。 これらの目的で、データ サイエンティストに運用カタログ内の資産への読み取り専用アクセス権を付与して構いません。
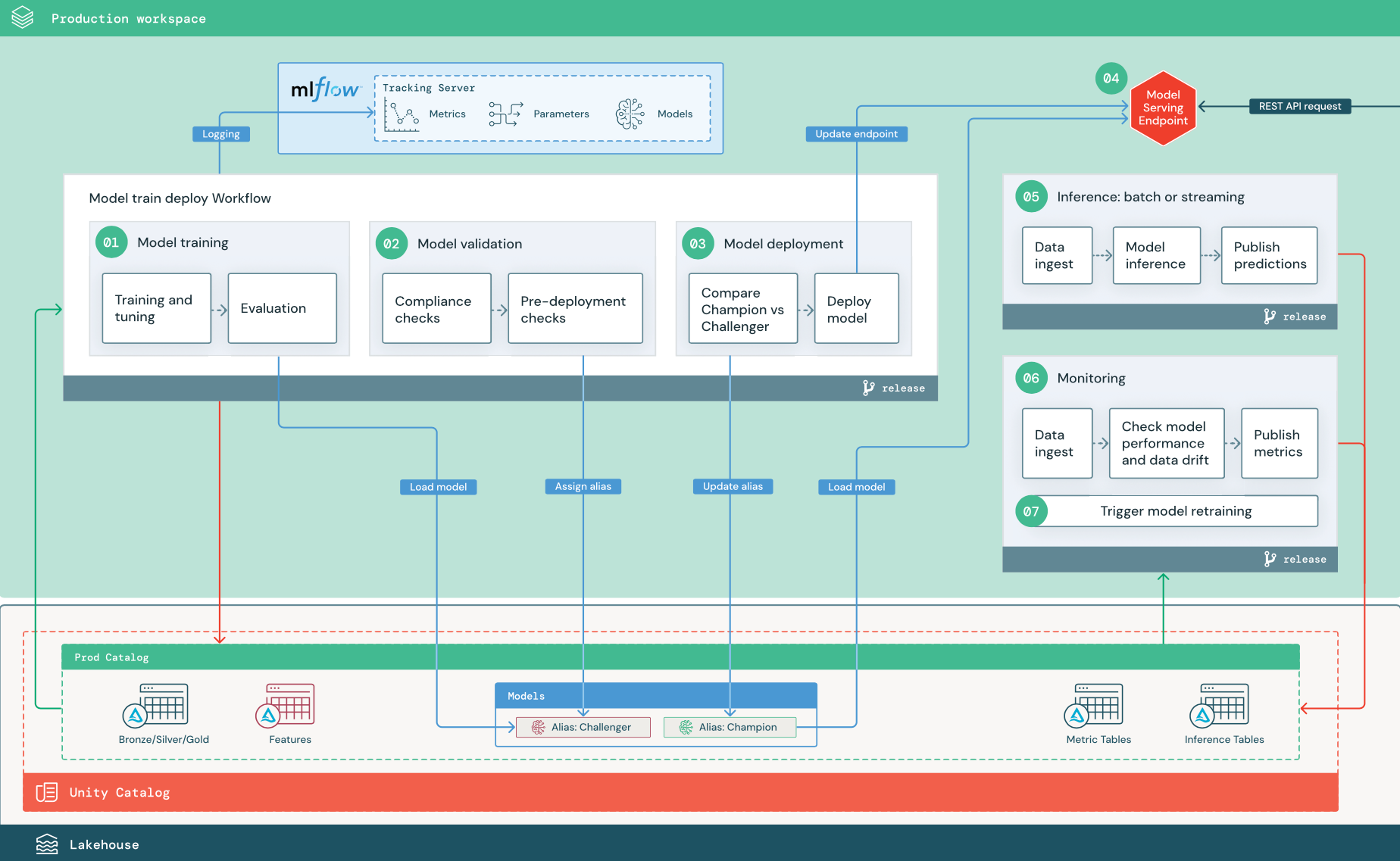
以下に示す番号付きのステップは、ダイアグラムに示された番号に対応します。
1.モデルのトレーニング
このパイプラインは、コードの変更または自動再トレーニング ジョブによってトリガーできます。 この手順では、運用カタログのテーブルが以下の手順で使用されます。
トレーニングとチューニング。 トレーニング プロセス中に、ログは運用環境の MLflow 追跡サーバーに記録されます。 これらのログには、モデル メトリック、パラメーター、タグ、およびモデル自体が含まれます。 特徴量テーブルを使用する場合、モデルは Databricks Feature Store クライアントを使用して MLflow にログ記録されます。このクライアントは、推論時に使用される特徴量検索情報と共にモデルをパッケージ化します。
開発中、データ サイエンティストは多くのアルゴリズムとハイパーパラメーターをテストする可能性があります。 運用トレーニング コードでは、最もパフォーマンスの高いオプションのみを考慮するのが一般的です。 この方法でチューニングを制限すると、時間が節約され、自動再トレーニングでのチューニングの差異を減らすことができます。
データ サイエンティストが運用カタログへの読み取り専用アクセス権を持っている場合、モデルに最適なハイパーパラメーターのセットを特定できる場合があります。 この場合、運用環境にデプロイされたモデル トレーニング パイプラインは、選択したハイパーパラメーターのセット (通常は構成ファイルとしてパイプラインに含められます) を使用して実行できます。
評価。 モデルの品質は、保留された運用データのテストによって評価されます。 これらのテストの結果は、MLflow 追跡サーバーにログされます。 このステップでは、開発ステージのデータ サイエンティストによって指定された評価メトリックを使用します。 これらのメトリックには、カスタム コードが含まれる場合があります。
モデルの登録。 モデル トレーニングが完了すると、モデル成果物は、Unity Catalog の運用カタログ内で指定されたモデル パスに登録済みモデル バージョンとして保存されます。 モデル トレーニング タスクは、モデル検証タスクが使用できるモデル URI を生成します。 タスク値を使用して、この URI をモデルに渡すことができます。
2.モデルを検証する
このパイプラインは、手順 1 のモデル URI を使用して、Unity Catalog からモデルを読み込みます。 その後、一連の検証チェックを実行します。 これらのチェックは組織とユース ケースによって異なり、基本的な形式とメタデータの検証、選択したデータ スライス上のパフォーマンス評価、タグやドキュメントのコンプライアンス チェックなどの組織内要件に関するコンプライアンスなどを含めることができます。
モデルがすべての検証チェックに無事合格した場合は、Unity Catalog 内のそのモデル バージョンに “Challenger” エイリアスを割り当てることができます。 モデルがすべての検証チェックに合格しない場合は、プロセスが終了し、ユーザーが自動的に通知を受け取るようにできます。 これらの検証チェックの結果に応じて、タグを使用してキーと値の属性を追加できます。 たとえば、タグ “model_validation_status” を作成し、テストの実行時に値を “PENDING” に設定し、パイプラインが完了したらそれを “PASSED” または “FAILED” に更新できます。
モデルは Unity Catalog に登録されているため、開発環境で作業しているデータ サイエンティストは、このモデル バージョンを運用カタログから読み込み、モデルが検証に失敗したかどうかを調査できます。 合否に関係なく、結果は、モデル バージョンへの注釈を使用して、運用カタログ内の登録済みモデルに記録されます。
3.モデルのデプロイ
検証パイプラインと同様に、モデル デプロイ パイプラインは組織とユース ケースによって異なります。 このセクションでは、新しく検証されたモデルに “Challenger” エイリアスを割り当て、既存の運用モデルに “Champion” エイリアスを割り当て済みであることを前提とします。 新しいモデルをデプロイする前の最初の手順は、それが現在の運用モデルと少なくとも同程度のパフォーマンスを示すことを確認することです。
“CHALLENGER” モデルを “CHAMPION” モデルと比較します。 この比較は、オフラインまたはオンラインで実行できます。 オフライン比較は、両方のモデルをホールドアウト データ セットを使用して評価し、MLflow 追跡サーバーを使用して結果を追跡します。 リアルタイム モデル提供の場合は、A/B テストや新しいモデルの段階的なロールアウトなど、より実行時間の長いオンライン比較を実行したい場合があります。 比較で “Challenger” モデル バージョンの方が良いパフォーマンスを示した場合、このバージョンが現在の “Champion” エイリアスに取って代わります。
Databricks Model Serving と Databricks レイクハウス監視を使用すると、エンドポイントの要求データと応答データを含む推論テーブルを自動的に収集および監視できます。
既存の “Champion” モデルがない場合は、“Challenger” モデルをベースラインとしてビジネス ヒューリスティックまたはその他のしきい値と比較できます。
ここで説明するプロセスは完全に自動化されています。 手動の承認手順が必要な場合は、モデル デプロイ パイプラインからのワークフロー通知または CI/CD コールバックを使用してそれらの手順を設定できます。
モデルをデプロイします。 バッチ推論パイプラインまたはストリーミング推論パイプラインは、“Champion” エイリアスを持つモデルを使用するように設定できます。 リアルタイムのユース ケースでは、モデルを REST API エンドポイントとしてデプロイするようにインフラストラクチャを設定する必要があります。 このエンドポイントは、Databricks Model Serving を使用して作成および管理できます。 エンドポイントが現在のモデルで既に使用されている場合は、新しいモデルでそのエンドポイントを更新できます。 Databricks Model Serving は、新しい構成の準備ができるまで既存構成の実行を続けることで、ダウンタイムなしの更新を実行します。
4.Model Serving
Model Serving エンドポイントを構成する場合は、Unity Catalog 内のモデルの名前と提供するバージョンを指定します。 モデル バージョンが Unity Catalog 内のテーブルの特徴量を使用してトレーニングされた場合、モデルはその特徴量と関数の依存関係を保存します。 Model Serving は、この依存関係グラフを自動的に使用して、推論時に適切なオンライン ストアから特徴量を検索します。 この方法は、データの前処理に関数を適用したり、モデル スコアリング中にオンデマンド特徴量を計算したりするためにも使用できます。
複数のモデルを持つ単一のエンドポイントを作成し、それらのモデル間でのエンドポイント トラフィックの分割を指定すると、オンラインでの “Champion” と “Challenger” の比較を実行することができます。
5. 推論: バッチまたはストリーミング
推論パイプラインは、運用カタログから最新のデータを読み取り、オンデマンド特徴量を計算する関数を実行し、“Champion” モデルを読み込み、データにスコアを付け、予測を返します。 一般に、バッチ推論またはストリーミング推論は、スループットが高く、待機時間が長いユース ケースで最もコスト効率の高いオプションです。 待機時間の短い予測は必要でも、予測をオフラインで計算できるシナリオでは、これらのバッチ予測を DynamoDB や Cosmos DB などのオンラインのキーと値のストアに発行できます。
Unity Catalog に登録されているモデルは、そのエイリアスによって参照されます。 推論パイプラインは、“Champion” モデル バージョンを読み込んで適用するように構成されています。 “Champion” バージョンが新しいモデル バージョンに更新されると、推論パイプラインは次の実行で新しいバージョンを自動的に使用します。 このようにしてモデル デプロイ手順は推論パイプラインから分離されています。
バッチ ジョブは、通常、運用カタログ内のテーブルやフラット ファイルへ、または JDBC 接続経由で予測を発行します。 ストリーミング ジョブは、通常、Unity Catalog テーブルへか Apache Kafka などのメッセージ キューへ予測を発行します。
6.レイクハウス監視
レイクハウス監視は、入力データとモデル予測の統計的特性 (データ ドリフトやモデルパフォーマンスなど) を監視します。 これらのメトリックに基づいてアラートを作成したり、ダッシュボードで発行したりできます。
- データ インジェスト。 このパイプラインは、バッチ、ストリーミング、またはオンライン推論からログを読み取ります。
- 精度とデータの誤差を確認します。 パイプラインは、入力データ、モデルの予測、インフラストラクチャのパフォーマンスに関するメトリックを計算します。 データ サイエンティストは、開発中にデータとモデルのメトリックを指定し、ML エンジニアはインフラストラクチャ メトリックを指定します。 レイクハウス監視でカスタム メトリックを定義することもできます。
- メトリックを発行しアラートを設定します。 このパイプラインは、運用カタログ内のテーブルに分析とレポートの書き込みを行います。 データ サイエンティストが分析にアクセスできるように、これらのテーブルを開発環境から読み取ることができるように構成する必要があります。 Databricks SQL を使用して、モデルのパフォーマンスを追跡する監視ダッシュボードを作成し、メトリックが指定されたしきい値を超えたときに通知を発行するように監視ジョブまたはダッシュボード ツールを設定できます。
- モデルの再トレーニングをトリガーします。 監視メトリックがパフォーマンスの問題や入力データの変化を示している場合、データ サイエンティストは新しいモデル バージョンを開発する必要があるかもしれません。 そのような事態にデータ サイエンティストに通知を行うための SQL アラートを設定できます。
7.再トレーニング
このアーキテクチャは、上記と同じモデル トレーニング パイプラインを使用する自動再トレーニングをサポートしています。 Databricks は、スケジュールされた定期的な再トレーニングから始めて、必要に応じてトリガーされる再トレーニングに移行することを推奨しています。
- スケジュール。 新しいデータが定期的に使用可能な場合は、 スケジュールされたジョブ を作成して、利用可能な最新のデータに対してモデル トレーニング コードを実行できます。
- トリガー。 監視パイプラインがモデル パフォーマンスの問題を特定し、アラートを送信できる場合は、再トレーニングをトリガーすることもできます。 たとえば、受信データの分布が大きく変化したり、モデル パフォーマンスが低下した場合、自動再トレーニングと再デプロイにより、人間の介入を最小限に抑えてモデル パフォーマンスを向上させることができます。 これは、SQL アラートを通してメトリックが異常かどうかを確認することで実現できます (たとえば、しきい値に対してドリフトやモデルの品質をチェックします)。 アラートは、Webhook の宛先を使用するように構成でき、これによって続けてトレーニング ワークフローをトリガーできます。
再トレーニング パイプラインまたはその他のパイプラインがパフォーマンスの問題を示した場合、データ サイエンティストは、問題に対処するための追加の実験のために開発環境に戻る必要があるかもしれません。