SQL ウェアハウスを作成する
ワークスペース管理者と十分な特権を持つユーザーは、SQL ウェアハウスを構成および管理できます。 この記事では、既存の SQL ウェアハウスを作成、編集、監視する方法の概要を示します。
SQL Warehouse API、または Terraform を使って、SQL ウェアハウスを作成することもできます。
Databricks では、使用可能な場合はサーバーレス SQL ウェアハウスを使用することをお勧めします。
Note
ほとんどのユーザーは SQL ウェアハウスを作成できませんが、接続できる SQL ウェアハウスを再起動することはできます。 「SQL ウェアハウスとは」を参照してください。
要件
SQL ウェアハウスには、次の要件があります。
SQL ウェアハウスを作成するには、ワークスペース管理者であるか、無制限のクラスター作成アクセス許可を持つユーザーである必要があります。
機能がサポートされているリージョンでサーバーレス SQL ウェアハウスを作成する前に、必要な手順がある場合があります。 「サーバーレス SQL ウェアハウスを有効にする」を参照してください。
クラシックまたはプロ SQL ウェアハウスの場合、Azure アカウントには十分な vCPU クォータが必要です。 通常、既定の vCPU クォータはサーバーレス SQL ウェアハウスを作成するのに十分ですが、SQL ウェアハウスをスケーリングしたり、追加のウェアハウスを作成したりするには不十分な場合があります。 「クラシックおよびプロ SQL ウェアハウスに必要な Azure vCPU クォータ」を参照してください。 追加の vCPU クォータを要求できます。 Azure アカウントには、要求できる vCPU クォータの量に制限がある場合があります。 詳細については、Azure アカウント チームにお問い合わせください。
SQL ウェアハウスを作成する
Web UI を使用して SQL Warehouse を作成するには、次のようにします。
- サイドバーの [SQL Warehouse] (SQL ウェアハウス) をクリックします。
- [Create SQL Warehouse] (SQL ウェアハウスの作成) をクリックします。
- ウェアハウスの名前を入力します。
- (省略可能) ウェアハウスの設定を構成します。 「SQL ウェアハウスの設定を構成する」を参照してください。
- (オプション) 詳細設定オプションを構成します。 「詳細オプション」を参照してください。
- Create をクリックしてください。
- (省略可能) SQL ウェアハウスへのアクセスを構成します。 「SQL ウェアハウスを管理する」を参照してください。
作成したウェアハウスが自動的に開始されます。
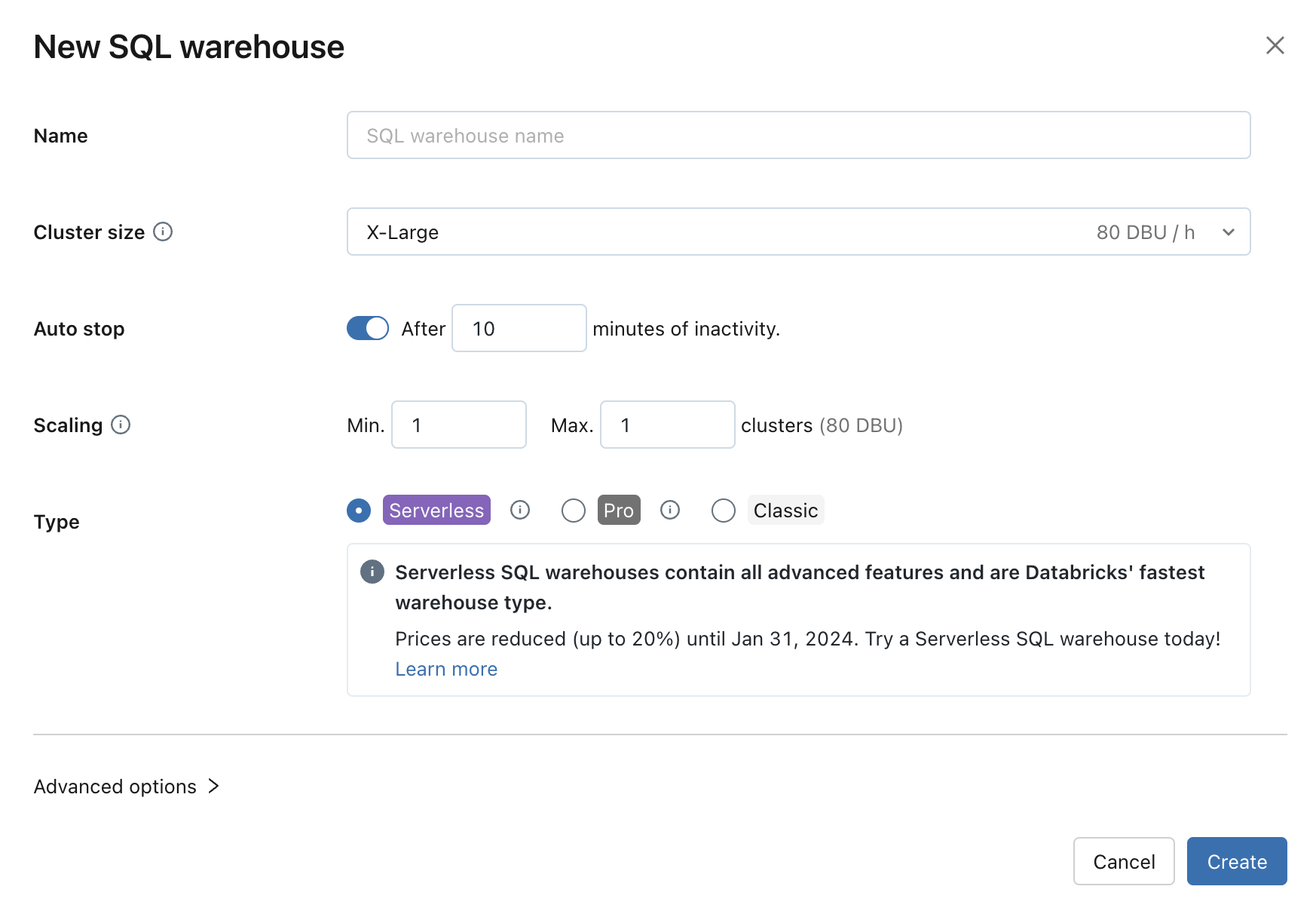
SQL ウェアハウスの設定を構成する
SQL ウェアハウスの作成または編集時、次の設定を変更できます。
[クラスター サイズ] は、ドライバー ノードのサイズと、クラスターに関連付けられているワーカー ノードの数を表します。 既定値は X-Large です。 クエリの待機時間を短縮するには、サイズを増やします。
自動停止は、ウェアハウスが指定された時間 (分) アイドル状態の場合に、停止するかどうかを決定します。 アイドル状態の SQL ウェアハウスには、停止するまで DBU とクラウド インスタンス料金が蓄積し続けます。
- プロおよびクラシック SQL ウェアハウス: 既定値は 45 分で、一般的な使用に推奨されます。 最小値は 10 分です。
- サーバーレス SQL ウェアハウス: 既定値は 10 分で、一般的な使用に推奨されます。 UI を使用する場合の最小値は 5 分です。 SQL warehouses API を使用してサーバーレス SQL ウェアハウスを作成できます。この場合、[自動停止] の値を 1 分に設定できます。
[スケーリング] により、クエリに使われるクラスターの最小数と最大数を設定できます。 既定値は最小、最大 1 台のクラスターです。 特定のクエリに対してより多くの同時ユーザーを処理したい場合は、クラスターの最大数を増やすことができます。 Azure Databricks では、10 個の同時クエリごとに 1 台のクラスターが推奨されます。
最適なパフォーマンスを維持するために、Databricks はクラスターを定期的にリサイクルします。 リサイクル期間中、一時的に最大数を超えるクラスター数が表示されることがあります。Databricks が新しいワークロードを新しいクラスターに移行し、開いているすべてのワークロードが完了するまで古いクラスターのリサイクルを待機しているためです。
[種類] によって、ウェアハウスの種類が決まります。 アカウントでサーバーレスが有効になっている場合、サーバーレスが既定値になります。 一覧については、「SQL ウェアハウスの種類」を参照してください。
詳細オプション
新しい SQL ウェアハウスを作成するとき、または既存の SQL ウェアハウスを編集するときに、[詳細オプション] 領域を展開することで、次の詳細オプションを構成します。 これらのオプションは、SQL Warehouse API を使って構成することもできます。
[タグ]: タグを使うと、組織内のユーザーとグループが使用するクラウド リソースのコストを監視できます。 タグはキーと値のペアとして指定します。
Unity Catalog: ワークスペースに対して Unity Catalog が有効になっている場合、それがワークスペース内のすべての新しいウェアハウスの既定値になります。 ワークスペースに対して Unity Catalog が有効になっていない場合、このオプションは表示されません。 「Unity Catalog とは」を参照してください。
[チャネル]: Databricks SQL の標準になる前に、プレビュー チャネルを使って、クエリやダッシュボードなどの新しい機能をテストします。
リリース ノートには、最新のプレビュー バージョンの内容が記載されています。
重要
Databricks では、実稼働ワークロードにプレビュー バージョンの使用を推奨しています。 ウェアハウスのプロパティ (チャネルを含む) を表示できるのはワークスペース管理者のみであるため、Databricks SQL ウェアハウスがプレビュー バージョンを使っていることをそのウェアハウスの名前で示し、ユーザーが運用ワークロードに使わないようにすることを検討してください。
SQL ウェアハウスを管理する
ワークスペース管理者と、SQL ウェアハウスに対する CAN MANAGE 特権を持つユーザーは、既存の SQL ウェアハウスで次のタスクを実行できます。
- 実行中のウェアハウスを停止するには、ウェアハウスの横にある停止アイコンをクリックします。
- 停止したウェアハウスを起動するには、ウェアハウスの横にある起動アイコンをクリックします。
- ウェアハウスを編集するには、ケバブ メニュー
 をクリックしてから、[編集] をクリックします。
をクリックしてから、[編集] をクリックします。 - アクセス許可を追加および編集するには、ケバブ メニュー をクリックしてから、[アクセス許可] をクリックします。 アクセス許可レベルの詳細については、「SQL ウェアハウスの ACL」を参照してください。
- SQL ウェアハウスをサーバーレスにアップグレードするには、ケバブ メニュー をクリックし、[サーバーレスへのアップグレード] をクリックします。
- ウェアハウスを削除するには、ケバブ メニュー をクリックしてから、[削除] をクリックします。
Note
削除されたウェアハウスを 14 日以内に復元するには、Databricks の担当者にお問い合わせください。