Azure Event Hubs で Azure Blob Storage または Azure Data Lake Storage にイベントをキャプチャする
Azure Event Hubs を利用すると、Event Hubs のストリーミング データをご自分で選択した Gen 1 または Gen 2 の Azure Blob Storage アカウントまたは Azure Data Lake Storage アカウントに自動的に配信できます。その際、時間やサイズの間隔を柔軟に指定できます。 Capture の設定は手軽で、実行しても管理コストは発生しません。また、Event Hubs の Standard レベルでのスループット ユニット数または Premium レベルでの処理ユニット数に応じて、自動的にスケーリングされます。 Event Hubs Capture はストリーミング データを Azure に読み込む最も簡単な方法であり、これを利用すれば、データのキャプチャではなくデータの処理に注力できるようになります。
Note
Azure Data Lake Storage Gen 2 を使用するように Event Hubs Capture を構成することは、Azure Blob Storage を使用するように構成することと同じです。 詳細については、Event Hubs Capture の構成に関する記事をご覧ください。
Event Hubs Capture を利用すると、リアルタイムおよびバッチベースのパイプラインを同じストリームで処理できます。 すなわち、変化するニーズに合わせて拡大可能なソリューションを構築できます。 将来のリアルタイム処理を視野に入れてバッチベースのシステムを構築している場合も、既存のリアルタイム ソリューションに効率的なコールド パスを追加したいと考えている場合も、Event Hubs Capture ならストリーミング データの操作が容易です。
重要
- 宛先となるストレージ (Azure Storage または Azure Data Lake Storage) アカウントは、認証にマネージド ID を使用しないとき、イベント ハブと同じサブスクリプションに存在する必要があります。
- Event Hubs では、Premium Storage アカウントでのイベントのキャプチャはサポートされていません。
- Event Hubs キャプチャでは、ブロック BLOB をサポートする Premium 以外の Azure ストレージ アカウントがサポートされます。
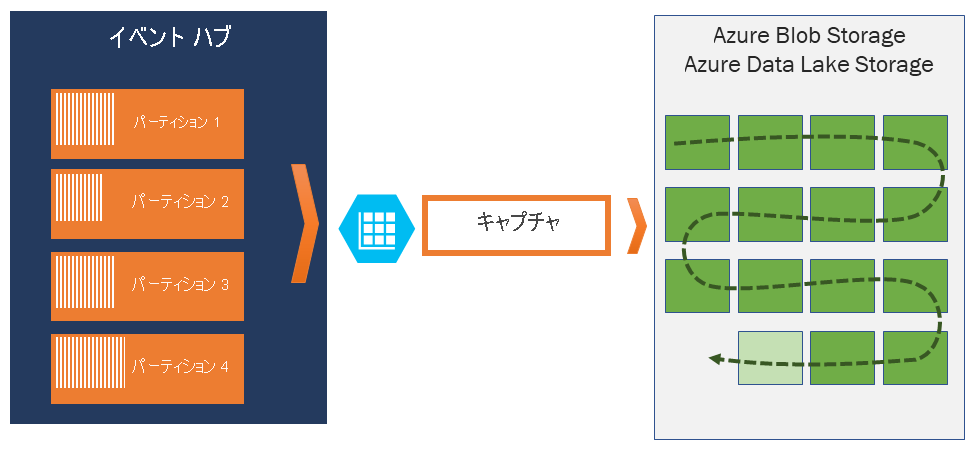
Event Hubs Capture の仕組み
Event Hubs は分散ログに似た、テレメトリの受信のための持続的バッファーです。 Event Hubs でのスケーリングの鍵となるのは、パーティション分割されたコンシューマー モデルです。 各パーティションは独立したデータのセグメントであり、個別に使用されます。 このデータは、構成可能なリテンション期間に基づいて、所定のタイミングで破棄されます。 そのため、特定のイベント ハブが "いっぱい" になることはありません。
Event Hubs Capture を使用すると、キャプチャされたデータを格納するための独自の Azure Blob Storage アカウントとコンテナー、または Azure Data Lake Storage アカウントを指定することができます。 これらのアカウントのリージョンは、イベント ハブと同じであっても、別のリージョンであってもかまわないため、Event Hubs Capture 機能の柔軟性がさらに高まります。
キャプチャされたデータは Apache Avro 形式で書き込まれます。これはコンパクトで高速なバイナリ形式で、インライン スキーマを備えた便利なデータ構造になっています。 この形式は Hadoop エコシステム、Stream Analytics、Azure Data Factory で幅広く使用されています。 Avro の操作の詳細は、この記事の後半に記載してあります。
注意
Azure portal でコード エディターを使用しない場合は、Event Hubs のストリーミング データを Parquet 形式のAzure Data Lake Storage Gen2 アカウントでキャプチャできます。 詳細については、「方法: Parquet 形式で Event Hubs からデータをキャプチャする」と「チュートリアル: Parquet 形式で Event Hubs データをキャプチャし、Azure Synapse Analytics を使用して分析する」を参照してください。
キャプチャのウィンドウ化
Event Hubs Capture では、キャプチャを制御するウィンドウを設定できます。 このウィンドウは "先に来たものが優先されるポリシー" が適用される最小サイズと時間の構成です。つまり、先に生じたトリガーによってキャプチャ操作が行われます。 15 分/100 MB のキャプチャ ウィンドウを設定してあるときに 1 MB/秒で送信する場合は、サイズのウィンドウが時間のウィンドウよりも先にトリガーとなります。 各パーティションのキャプチャは個別に行われ、完了したブロック BLOB がキャプチャ時に (キャプチャが実行されるタイミングとなったときに) 書き込まれます。 ストレージの名前付け規則は次のとおりです。
{Namespace}/{EventHub}/{PartitionId}/{Year}/{Month}/{Day}/{Hour}/{Minute}/{Second}
日付値はゼロ パディングされます。ファイル名の例は次のようになります。
https://mystorageaccount.blob.core.windows.net/mycontainer/mynamespace/myeventhub/0/2017/12/08/03/03/17.avro
Azure Storage Blob が一時的に利用できなくなった場合、Event Hubs Capture では、イベント ハブで構成されたデータ保持期間の間、データが保持され、ストレージ アカウントが再び利用可能になったら、データがバックフィルされます。
スループット ユニット数または処理ユニット数のスケーリング
Event Hubs の Standard レベルでは、トラフィックはスループット ユニット数によって制御され、Premium レベルの Event Hubs では、処理ユニット数によって制御されます。 Event Hubs Capture では、内部の Event Hubs ストレージからデータが直接コピーされるため、スループット ユニットまたは処理ユニットのエグレス クォータが回避され、他の処理リーダー (Stream Analytics や Spark など) に対するエグレスを節約できます。
構成されると、Event Hubs Capture は最初のイベント送信時に自動的に実行され、そのまま実行を継続します。 ダウンストリーム処理で処理が行われていることを把握しやすいように、Event Hubs はデータがないときは空のファイルを書き込みます。 このプロセスにより、バッチ プロセッサに提供可能な、予測しやすいパターンとマーカーが得られます。
Event Hubs Capture の設定
Azure Portal または Azure Resource Manager テンプレートを使用して、イベント ハブの作成時に Capture を構成できます。 詳細については、次の記事を参照してください。
- Azure Portal を使用して Event Hubs Capture を有効にする
- Azure Resource Manager テンプレートを使用して、イベント ハブを含んだ Event Hubs 名前空間を作成して Capture を有効にする
Note
既存のイベント ハブの Capture 機能を有効にすると、この機能が有効になった後に、イベント ハブに到着したイベントが取り込まれるようになります。 この機能を有効にする前にイベント ハブに存在していたイベントは取り込まれません。
Event Hubs Capture に対する課金方法
キャプチャ機能は Premium レベルに含まれているため、そのレベルには追加料金はかかりません。 Standard レベルの場合、この機能は毎月課金され、料金は名前空間に対して購入されたスループット ユニットまたは処理ユニットの数に直接比例します。 スループット ユニットまたは処理ユニットが増減すると、Event Hubs Capture の測定もそれに応じたパフォーマンスを提供するために調整されます。 測定は連携して行われます。 料金の詳細については、「Event Hubs の価格」をご覧ください。
エグレス クォータは別途請求されるため、Capture では消費されません。
Event Grid との統合
Event Hubs 名前空間をソースとして Azure Event Grid サブスクリプションを作成できます。 以下のチュートリアルでは、イベント ハブをソースとして、Azure Functions アプリをシンクとして使用して、Event Grid サブスクリプションを作成する方法を示します。Event Grid および Azure Functions を使用して、キャプチャされた Event Hubs データを処理し、Azure Synapse Analytics に移行します。
キャプチャされたファイルを調べる
キャプチャされた Avro ファイルを調べる方法については、「キャプチャされた Avro ファイルを調べる」を参照してください。
Azure Storageアカウントを保存先とする
キャプチャ先として Azure Storage を使用してイベント ハブでキャプチャを有効にしたり、キャプチャ先として Azure Storage を使用してイベント ハブのプロパティを更新したりするには、ユーザーまたはサービス プリンシパルに、ストレージ アカウント スコープで以下の権限が割り当てられた RBAC ロールが必要です。
Microsoft.Storage/storageAccounts/blobServices/containers/write
Microsoft.Storage/storageAccounts/blobServices/containers/blobs/write
上記の権限がないと、次のエラーが表示されます:
Generic: Linked access check failed for capture storage destination <StorageAccount Arm Id>.
User or the application with object id <Object Id> making the request doesn't have the required data plane write permissions.
Please enable Microsoft.Storage/storageAccounts/blobServices/containers/write, Microsoft.Storage/storageAccounts/blobServices/containers/blobs/write permission(s) on above resource for the user or the application and retry.
TrackingId:<ID>, SystemTracker:mynamespace.servicebus.windows.net:myhub, Timestamp:<TimeStamp>
Storage Blob Data Owneは、上記の権限を持つ組み込みロールであるため、このロールにユーザー アカウントまたはサービス プリンシパルを追加します。
次のステップ
Event Hubs Capture は Azure にデータを取得する最も簡単な方法です。 Azure Data Lake、Azure Data Factory、Azure HDInsight を利用することで、使い慣れたツールとプラットフォームを使用して、必要なスケールでバッチ処理やその他の分析を実行できます。
Azure portal および Azure Resource Manager テンプレートを使用してこの機能を有効にする方法を学習してください。