HDInsight 上の Apache Hadoop で C# と MapReduce ストリーミングを使用する
HDInsight で C# を使用して MapReduce ソリューションを作成する方法について説明します。
Apache Hadoop ストリーミングでは、スクリプトまたは実行可能ファイルを使用して MapReduce ジョブを実行できます。 ここでは、.NET を使用してマッパーとレジューサのワード カウント ソリューションを実装します。
HDInsight の .NET
HDInsight クラスターでは、Mono (https://mono-project.com) を使用して .NET アプリケーションを実行します。 Mono バージョン 4.2.1 は HDInsight バージョン 3.6 に付属しています。 HDInsight に含まれる Mono のバージョンについて詳しくは、「HDInsight の各バージョンで使用できる Apache Hadoop コンポーネント」を参照してください。
.NET Framework のバージョンと Mono の互換性の詳細については、「Mono compatibility」 (Mono の互換性) を参照してください。
Hadoop ストリーミングのしくみ
このドキュメントでストリーミングに使用する基本的なプロセスは、次のとおりです。
- Hadoop は、STDIN のマッパー (この例では mapper.exe) にデータを渡します。
- マッパーはデータを処理し、タブ区切りのキー/値ペアを STDOUT に出力します。
- 出力は Hadoop によって読み取られ、STDIN のレジューサ (この例では reducer.exe) に渡されます。
- レジューサは、タブ区切りのキー/値ペアを読み取り、データを処理した後、タブ区切りのキー/値ペアとして結果を STDOUT に出力します。
- 出力は Hadoop によって読み取られ、出力ディレクトリに書き込まれます。
ストリーミングの詳細については、「Hadoop Streaming」(Hadoop ストリーミング) を参照してください。
前提条件
見ることができます。
.NET Framework 4.5 を対象にした C# コードの記述と構築に精通していること。
クラスターに .exe ファイルをアップロードする方法。 このドキュメントの手順では、Visual Studio の Data Lake ツールを使用して、クラスターのプライマリ ストレージにファイルをアップロードします。
PowerShell を使用している場合は、AZ モジュールが必要になります。
HDInsight の Apache Hadoop クラスター。 Linux での HDInsight の概要に関するページを参照してください。
クラスターのプライマリ ストレージの URI スキーム。 このスキームは、Azure Storage では
wasb://、Azure Data Lake Storage Gen2 ではabfs://、Azure Data Lake Storage Gen1 ではadl://です。 Azure Storage または Data Lake Storage Gen2 で安全な転送が有効になっている場合、URI はそれぞれwasbs://またはabfss://になります。
マッパーの作成
Visual Studio で、"マッパー" と呼ばれる新しい .NET Framework コンソール アプリケーションを作成します。 アプリケーションには次のコードを使用します。
using System;
using System.Text.RegularExpressions;
namespace mapper
{
class Program
{
static void Main(string[] args)
{
string line;
//Hadoop passes data to the mapper on STDIN
while((line = Console.ReadLine()) != null)
{
// We only want words, so strip out punctuation, numbers, etc.
var onlyText = Regex.Replace(line, @"\.|;|:|,|[0-9]|'", "");
// Split at whitespace.
var words = Regex.Matches(onlyText, @"[\w]+");
// Loop over the words
foreach(var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t1",word);
}
}
}
}
}
アプリケーションを作成した後、それをビルドしてプロジェクト ディレクトリに /bin/Debug/mapper.exe ファイルを生成します。
レジューサの作成
Visual Studio で、"レジューサ" と呼ばれる新しい .NET Framework コンソール アプリケーションを作成します。 アプリケーションには次のコードを使用します。
using System;
using System.Collections.Generic;
namespace reducer
{
class Program
{
static void Main(string[] args)
{
//Dictionary for holding a count of words
Dictionary<string, int> words = new Dictionary<string, int>();
string line;
//Read from STDIN
while ((line = Console.ReadLine()) != null)
{
// Data from Hadoop is tab-delimited key/value pairs
var sArr = line.Split('\t');
// Get the word
string word = sArr[0];
// Get the count
int count = Convert.ToInt32(sArr[1]);
//Do we already have a count for the word?
if(words.ContainsKey(word))
{
//If so, increment the count
words[word] += count;
} else
{
//Add the key to the collection
words.Add(word, count);
}
}
//Finally, emit each word and count
foreach (var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t{1}", word.Key, word.Value);
}
}
}
}
アプリケーションを作成した後、それをビルドしてプロジェクト ディレクトリに /bin/Debug/reducer.exe ファイルを生成します。
ストレージにアップロードする
次に、"マッパー" アプリケーションと "レジューサ" アプリケーションを HDInsight ストレージにアップロードする必要があります。
Visual Studio で、 [表示]>[サーバー エクスプローラー] を選択します。
[Azure] を右クリックし、 [Microsoft Azure サブスクリプションへの接続] を選択して、サインイン処理を完了します。
このアプリケーションをデプロイする HDInsight クラスターを展開します。 エントリとテキスト (既定のストレージ アカウント) が一覧表示されます。
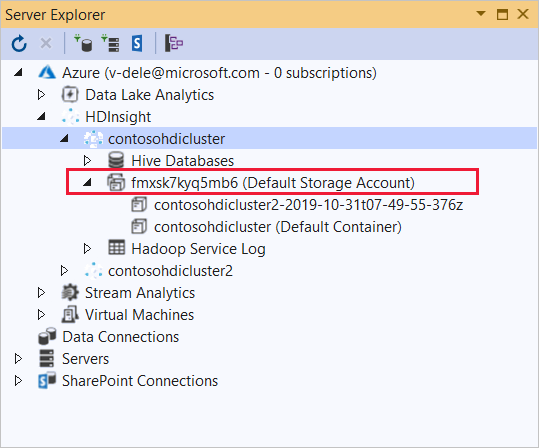
[(既定のストレージ アカウント)] エントリを展開できる場合は、クラスターの既定のストレージとして Azure ストレージ アカウントを使用しています。 クラスターの既定のストレージのファイルを表示するには、エントリを展開し、 [(既定のコンテナー)] をダブルクリックします。
[(既定のストレージ アカウント)] エントリを展開できない場合は、クラスターの既定のストレージとして Azure Data Lake Storage を使用しています。 クラスターの既定のストレージにファイルを表示するには、 (既定のストレージ アカウント) エントリをダブルクリックします。
.exe ファイルをアップロードするには、次のいずれかの方法を使用します。
Azure ストレージ アカウントを使用している場合は、 [BLOB のアップロード] アイコンを選択します。

[新しいファイルのアップロード] ダイアログ ボックスの [ファイル名] で、 [参照] を選択します。 [BLOB のアップロード] ダイアログ ボックスで、"マッパー" プロジェクトの bin\debug フォルダーに移動し、mapper.exe ファイルを選択します。 最後に、 [開く] を選択し、 [OK] を選択してアップロードを完了します。
Azure Data Lake Storage の場合は、ファイルの一覧の空の領域を右クリックし、 [アップロード] を選択します。 最後に、mapper.exe ファイルを選択し、 [開く] を選択します。
mapper.exe のアップロードが完了したら、 reducer.exe ファイルのアップロード プロセスを繰り返します。
ジョブの実行: SSH セッションを使用
次の手順では、SSH セッションを使用して MapReduce ジョブを実行する方法について説明します。
ssh コマンドを使用してクラスターに接続します。 次のコマンドを編集して CLUSTERNAME をクラスターの名前に置き換えてから、そのコマンドを入力します。
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netMapReduce ジョブを開始するには、次のいずれかのコマンドを使用します。
既定のストレージが Azure Storage の場合:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files wasbs:///mapper.exe,wasbs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountout既定のストレージが Data Lake Storage Gen1 の場合:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files adl:///mapper.exe,adl:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountout既定のストレージが Data Lake Storage Gen2 の場合:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files abfs:///mapper.exe,abfs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountout
次の一覧では、各パラメーターおよびオプションによって表されているものについて説明します。
パラメーター 説明 hadoop-streaming.jar ストリーミング MapReduce 機能が含まれる jar ファイルを指定します。 -files このジョブに対する mapper.exe ファイルと reducer.exe ファイルを指定します。 各ファイルの前の wasbs:///、adl:///、またはabfs:///のプロトコル宣言は、クラスターの既定の記憶域のルートへのパスです。-mapper マッパーが実装されているファイルを指定します。 -reducer レジューサが実装されているファイルを指定します。 -input 入力データを指定します。 -output 出力ディレクトリを指定します。 MapReduce ジョブが完了したら、次のコマンドを使用して結果を表示します。
hdfs dfs -text /example/wordcountout/part-00000次のテキストは、このコマンドによって返されるデータの例です。
you 1128 young 38 younger 1 youngest 1 your 338 yours 4 yourself 34 yourselves 3 youth 17
ジョブの実行: PowerShell の使用
次の PowerShell スクリプトを使用して、MapReduce ジョブを実行し、結果をダウンロードします。
# Login to your Azure subscription
$context = Get-AzContext
if ($context -eq $null)
{
Connect-AzAccount
}
$context
# Get HDInsight info
$clusterName = Read-Host -Prompt "Enter the HDInsight cluster name"
$creds=Get-Credential -Message "Enter the login for the cluster"
# Path for job output
$outputPath="/example/wordcountoutput"
# Progress indicator
$activity="C# MapReduce example"
Write-Progress -Activity $activity -Status "Getting cluster information..."
#Get HDInsight info so we can get the resource group, storage, etc.
$clusterInfo = Get-AzHDInsightCluster -ClusterName $clusterName
$resourceGroup = $clusterInfo.ResourceGroup
$storageActArr=$clusterInfo.DefaultStorageAccount.split('.')
$storageAccountName=$storageActArr[0]
$storageType=$storageActArr[1]
# Progress indicator
#Define the MapReduce job
# Note: using "/mapper.exe" and "/reducer.exe" looks in the root
# of default storage.
$jobDef=New-AzHDInsightStreamingMapReduceJobDefinition `
-Files "/mapper.exe","/reducer.exe" `
-Mapper "mapper.exe" `
-Reducer "reducer.exe" `
-InputPath "/example/data/gutenberg/davinci.txt" `
-OutputPath $outputPath
# Start the job
Write-Progress -Activity $activity -Status "Starting MapReduce job..."
$job=Start-AzHDInsightJob `
-ClusterName $clusterName `
-JobDefinition $jobDef `
-HttpCredential $creds
#Wait for the job to complete
Write-Progress -Activity $activity -Status "Waiting for the job to complete..."
Wait-AzHDInsightJob `
-ClusterName $clusterName `
-JobId $job.JobId `
-HttpCredential $creds
Write-Progress -Activity $activity -Completed
# Download the output
if($storageType -eq 'azuredatalakestore') {
# Azure Data Lake Store
# Fie path is the root of the HDInsight storage + $outputPath
$filePath=$clusterInfo.DefaultStorageRootPath + $outputPath + "/part-00000"
Export-AzDataLakeStoreItem `
-Account $storageAccountName `
-Path $filePath `
-Destination output.txt
} else {
# Az.Storage account
# Get the container
$container=$clusterInfo.DefaultStorageContainer
#NOTE: This assumes that the storage account is in the same resource
# group as HDInsight. If it is not, change the
# --ResourceGroupName parameter to the group that contains storage.
$storageAccountKey=(Get-AzStorageAccountKey `
-Name $storageAccountName `
-ResourceGroupName $resourceGroup)[0].Value
#Create a storage context
$context = New-AzStorageContext `
-StorageAccountName $storageAccountName `
-StorageAccountKey $storageAccountKey
# Download the file
Get-AzStorageBlobContent `
-Blob 'example/wordcountoutput/part-00000' `
-Container $container `
-Destination output.txt `
-Context $context
}
このスクリプトには、クラスター ログインのアカウント名とパスワードに加え、HDInsight のクラスター名が求められます。 ジョブが完了すると、出力が output.txt というファイルにダウンロードされます。 次のテキストは、output.txtファイル内のデータの例です。
you 1128
young 38
younger 1
youngest 1
your 338
yours 4
yourself 34
yourselves 3
youth 17