HDInsight 上の Apache Hadoop で Apache Ambari Hive ビューを使用する
Ambari Hive ビューを使用して Hive クエリを実行する方法について説明します。 Hive ビューを使用すると、Web ブラウザーからHive クエリを作成、最適化、および実行できます。
前提条件
HDInsight 上の Hadoop クラスター。 Linux での HDInsight の概要に関するページを参照してください。
Hive クエリを実行する
Azure portal でご自身のクラスターを選択します。 手順については、「クラスターの一覧と表示」を参照してください。 このクラスターは、新しいポータル ビューで開かれます。
クラスター ダッシュボードで [Ambari ビュー] を選択します。 認証情報の入力を求められたら、クラスターの作成時に使用したクラスター ログイン (既定値は
admin) アカウント名とパスワードを入力します。 また、ブラウザーでhttps://CLUSTERNAME.azurehdinsight.net/#/main/viewsに移動することもできます。ここで、CLUSTERNAMEはクラスターの名前です。ビューの一覧で、Hive ビュー を選択します。
Hive ビュー ページは次の図のようになります。
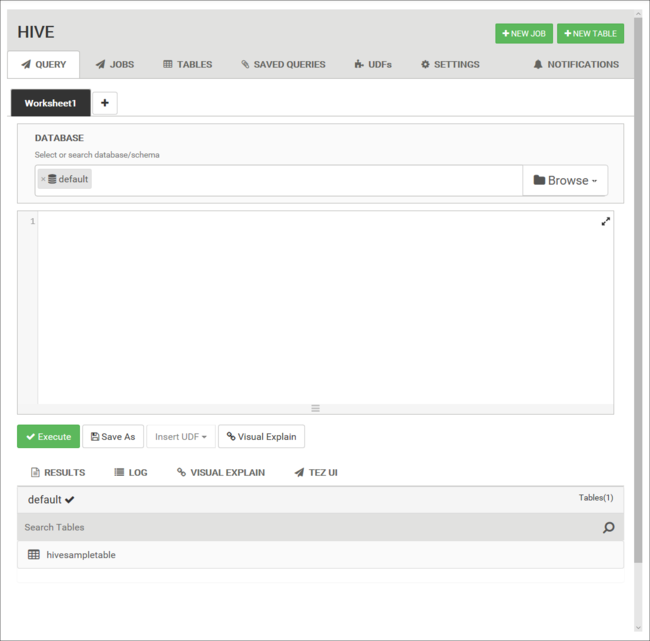
[Query](クエリ) タブから、次の HiveQL ステートメントをワークシートに貼り付けます。
DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS loglevel, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' GROUP BY t4;これらのステートメントによって次のアクションが実行されます。
ステートメント 説明 DROP TABLE テーブルが既に存在する場合は、テーブルとデータ ファイルを削除します。 CREATE EXTERNAL TABLE 新しい "外部" テーブルを Hive に作成します。 外部テーブルは Hive にテーブル定義のみを格納します。 データは元の場所に残されます。 ROW FORMAT データがどのように書式設定されているかを示します。 ここでは、各ログのフィールドは、スペースで区切られています。 STORED AS TEXTFILE LOCATION データが保存されている場所、およびデータがテキストとして保存されていることを示します。 SELECT t4 列の値が [ERROR] であるすべての行の数を選択します。 重要
[Database](データベース) では、 [default](既定) が選択されたままにしておきます。 このドキュメントの例では、HDInsight に含まれている既定のデータベースを使用します。
クエリを開始するには、ワークシートの下にある [実行] を選択します。 ボタンがオレンジ色になり、テキストが [Stop](停止) に変わります。
クエリが完了すると、 [Results](結果) タブに操作の結果が表示されます。 次のテキストは、クエリの結果を示します。
loglevel count [ERROR] 3[ログ] タブを使用すると、ジョブによって作成されたログ情報を表示できます。
ヒント
[結果] タブの [アクション] ドロップダウン ダイアログ ボックスから結果をダウンロードするか保存します。
ビジュアルの説明
クエリ プランの視覚化を表示するために、ワークシートの下にある [Visual Explain](ビジュアルの説明) タブを選択します。
クエリの [Visual Explain] ビューは、複雑なクエリのフローを理解する際に役立ちます。
Tez UI
クエリの Tez UI を表示するには、ワークシートの下にある [Tez UI] タブを選択します。
重要
Tez を使用してもすべてのクエリが解決するとは限りません。 多くのクエリは、Tez を使用することなく解決できます。
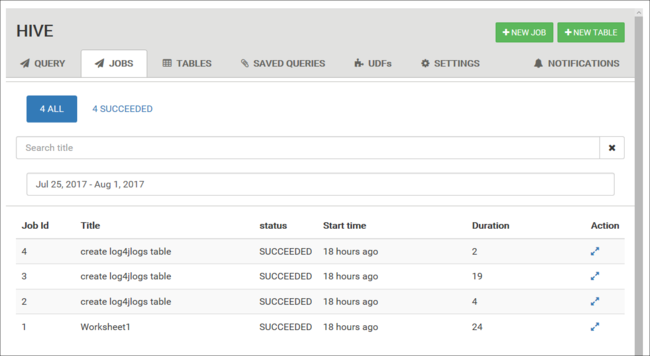
ジョブ履歴の表示
[Jobs](ジョブ) タブには、Hive クエリの履歴が表示されます。
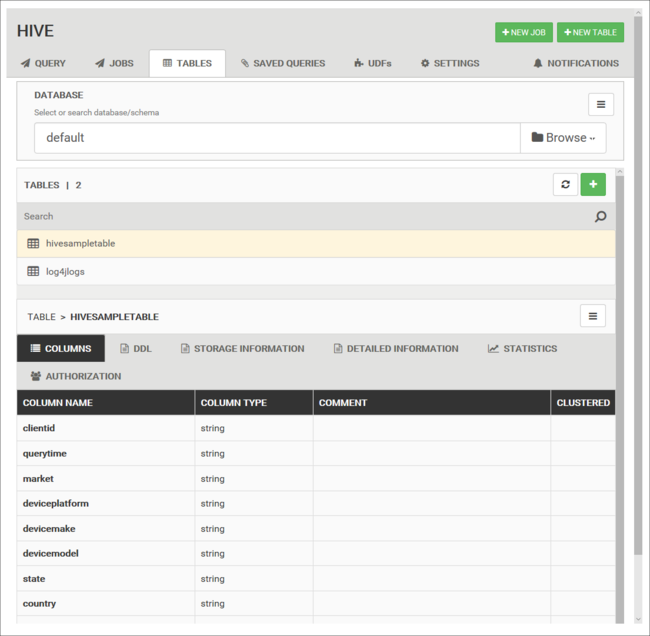
データベース テーブル
[Tables](テーブル) タブを使用して、Hive データベース内のテーブルを操作できます。
保存済みのクエリ
[Query](クエリ) タブでは、必要に応じてクエリを保存できます。 クエリを保存すると、 [Saved Queries](保存済みクエリ) タブでそのクエリを再利用できます。
ヒント
保存済みのクエリは、既定のクラスター記憶域に格納されます。 保存済みのクエリは、パス /user/<username>/hive/scripts の下にあります。 これらはプレーンテキストの .hql ファイルとして格納されます。
クラスターを削除して、記憶域は保持した場合、Azure Storage Explorer や Data Lake Storage Explorer などのユーティリティを (Azure Portal から) 使用してクエリを取得することができます。
ユーザー定義関数
ユーザー定義関数 (UDF) を使用して、Hive を拡張できます。 UDF を使用すると、HiveQL では簡単にモデル化できない機能またはロジックを実装できます。
Hive ビューの上部にある [UDF] タブを使用して、UDF のセットを宣言および保存します。 これらの UDF はクエリ エディターで使用できます。

[Insert udfs] (UDF の挿入) ボタンは、クエリ エディターの下部に表示されます。 このエントリには、Hive ビューで定義された UDF のドロップダウン リストが表示されます。 UDF を選択すると、HiveQL ステートメントがクエリに追加され、UDF が有効になります。
たとえば、以下のプロパティで UDF を定義したとします。
リソース名: myudfs
リソースのパス: /myudfs.jar
UDF 名: myawesomeudf
UDF のクラス名: com.myudfs.Awesome
[Insert udfs](UDF の挿入) ボタンを使用すると、myudfs という名前のエントリと、そのリソースに定義されている UDF ごとにドロップダウン リストが表示されます。 この場合は、myawesomeudf が表示されます。 このエントリを選択すると、クエリの先頭に次の内容が追加されます。
add jar /myudfs.jar;
create temporary function myawesomeudf as 'com.myudfs.Awesome';
これにより、クエリでこの UDF を使用できます。 たとえば、「 SELECT myawesomeudf(name) FROM people; 」のように入力します。
HDInsight において Hive で UDF を使用する方法の詳細については、以下の記事を参照してください。
Hive の設定
Hive の実行エンジンを Tez (既定値) から MapReduce に変更するなど、さまざまな Hive 設定を変更できます。
次のステップ
HDInsight での Hive に関する全般的な情報