Apache Spark History Server の拡張機能を使用して Spark アプリケーションのデバッグと診断を行う
この記事では、Apache Spark History Server の拡張機能を使用して、完成または実行されている Spark アプリケーションのデバッグおよび診断を行う方法を示します。 拡張機能には、 [Data](データ) タブ、 [Graph](グラフ) タブ、 [Diagnosis](診断) タブが含まれています。 [データ] タブでは、Spark ジョブの入力データと出力データを確認できます。 [グラフ] タブでは、データ フローを確認し、ジョブ グラフを再生できます。 [Diagnosis](診断) タブでは、 [Data Skew](データ スキュー) 、 [Time Skew](時間のずれ) 、 [Executor Usage Analysis](Executor 利用状況分析) 機能を参照できます。
Spark History Server へのアクセスを取得する
Spark History Server は、完了して実行中の Spark アプリケーションの Web UI です。 Azure portal または URL から開くことができます。
Spark History Server Web UI を Azure portal から開く
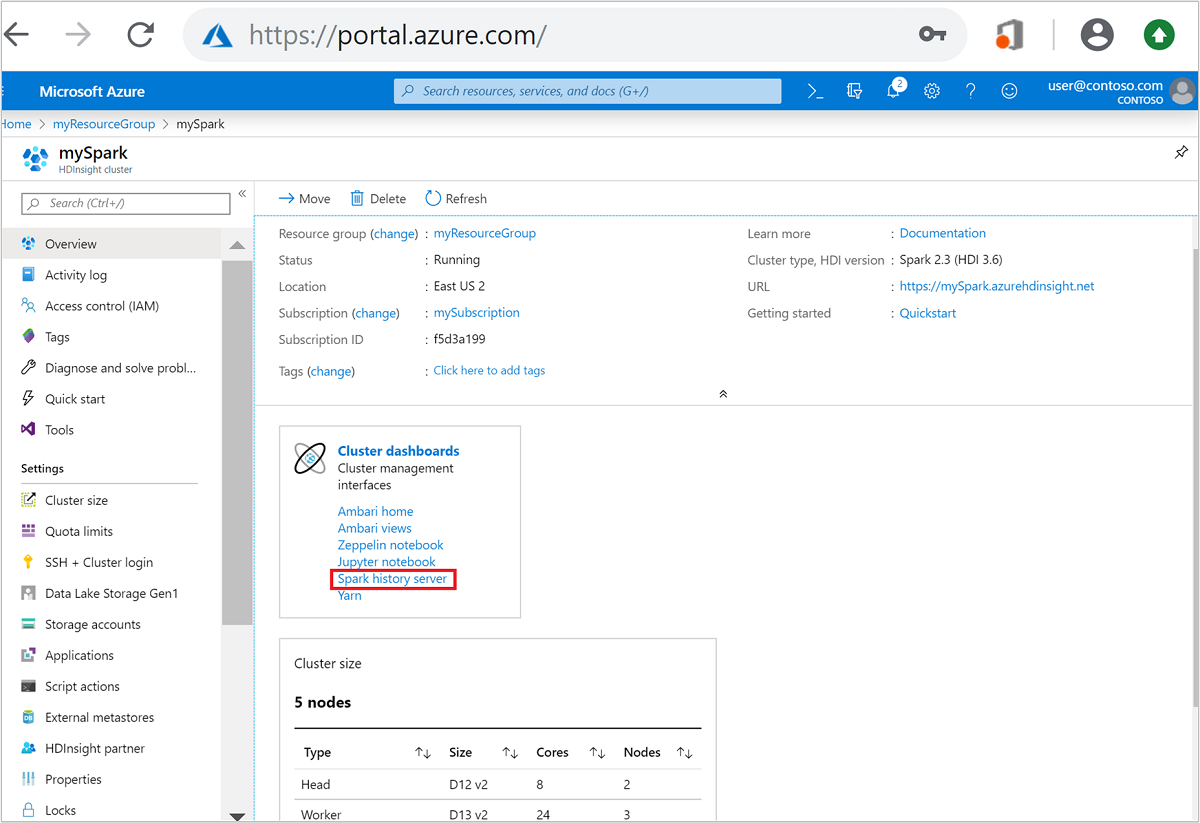
Azure Portal で Spark クラスターを開きます。 詳細については、「クラスターの一覧と表示」を参照してください。
クラスター ダッシュボード上で [Spark History Server] を選択します。 入力を求められたら、Spark クラスターの管理者資格情報を入力します。
 the Azure portal." border="true":::
the Azure portal." border="true":::
URL を指定して Spark History Server Web UI を開く
https://CLUSTERNAME.azurehdinsight.net/sparkhistory にアクセスして、Spark History Server を開きます。CLUSTERNAME はお使いの Spark クラスターの名前です。
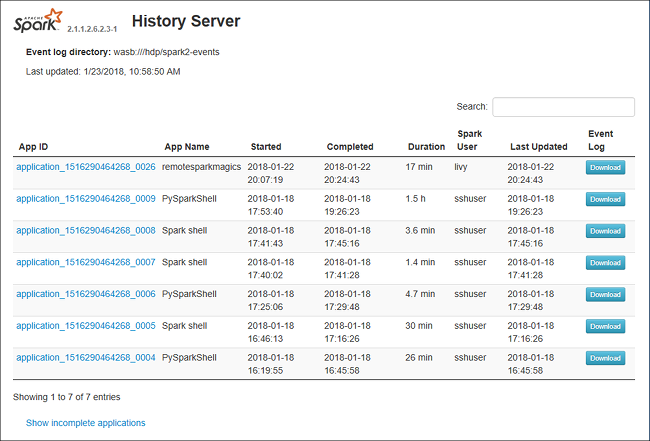
次のイメージのような Spark History Server の Web UI が表示されます。
Spark History Server の [データ] タブを使用する
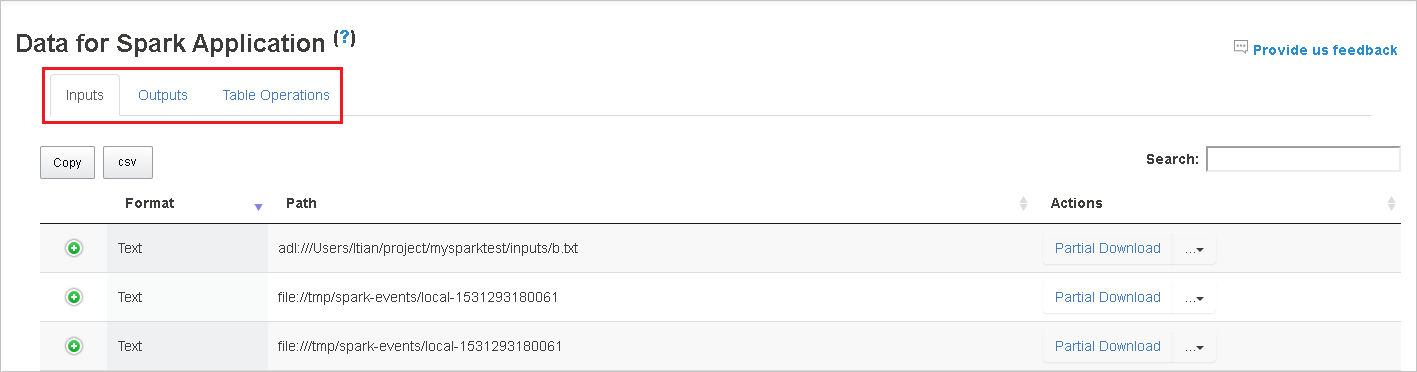
ジョブ ID を選択し、ツール メニューから [データ] を選択して、データ ビューを表示します。
[入力] 、 [出力] 、 [テーブル操作] を個別に選択することで、その内容を確認できます。
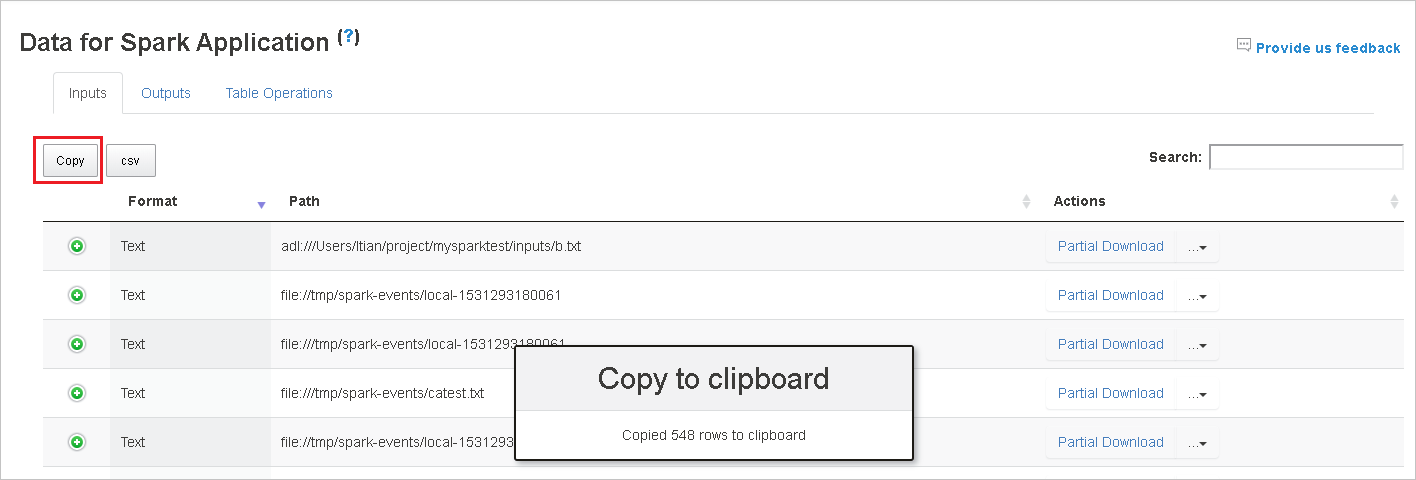
[コピー] ボタンを選択して、すべての行をコピーします。
[csv] ボタンをクリックしてすべてのデータを CSV ファイルとして保存します。
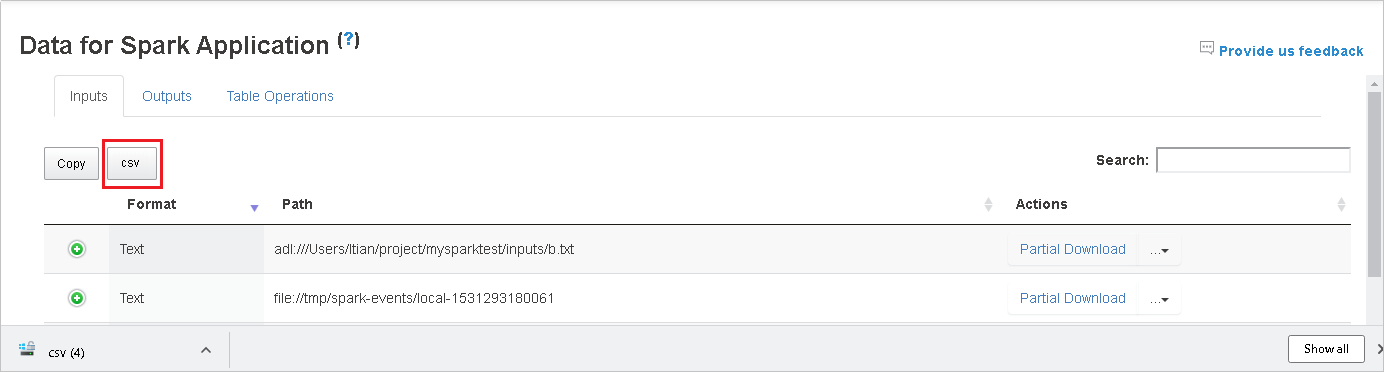
[検索] フィールドにキーワードを入力して、データを検索します。 検索結果はすぐに表示されます。
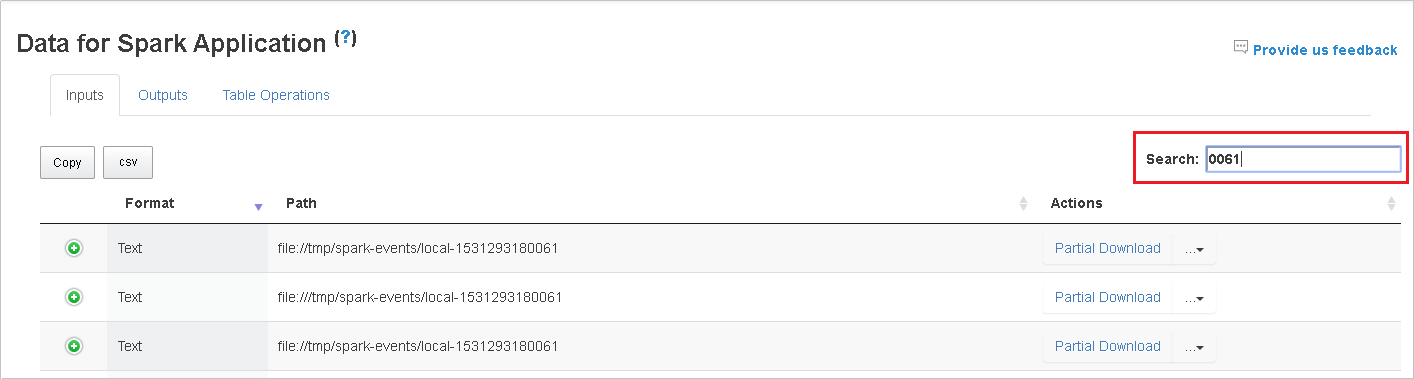
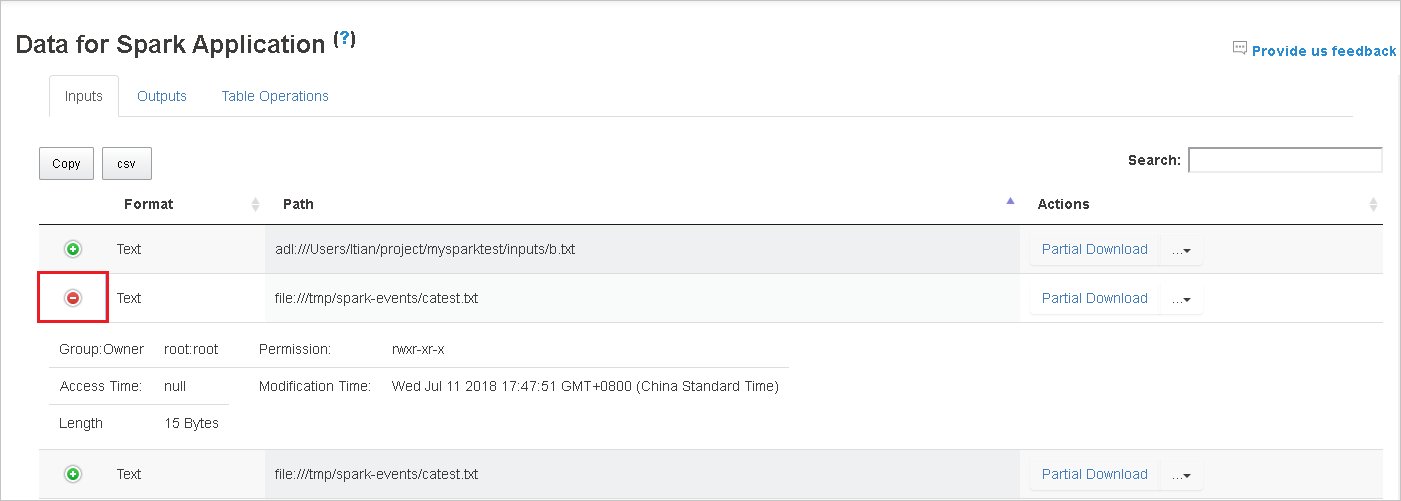
テーブルを並べ替えるには列ヘッダーを選択します。 プラス記号を選択して行を展開すると、詳細が表示されます。 行を折りたたむには、マイナス記号を選択します。
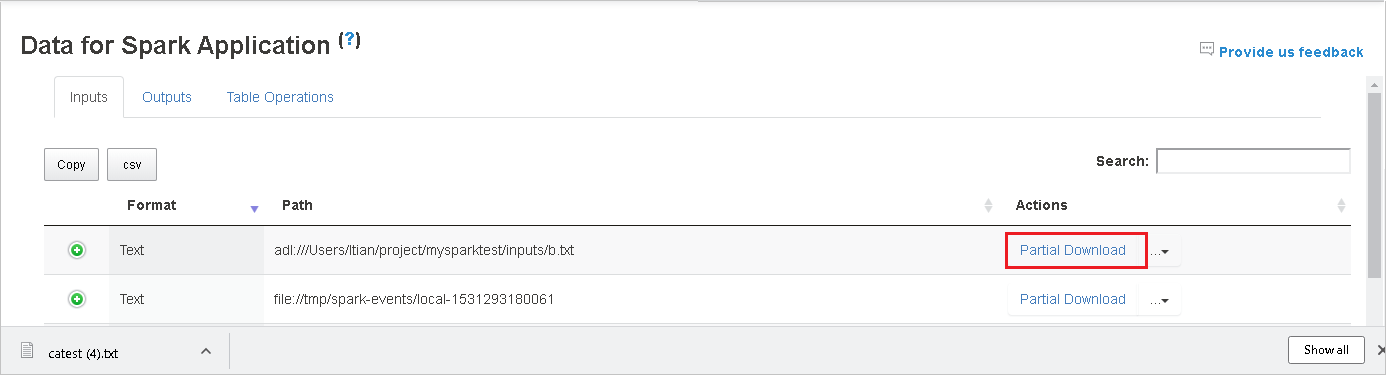
ファイルを 1 つだけダウンロードするには、右側にある [一部ダウンロード] ボタンを選択します。 選択したファイルはローカルにダウンロードされます。 ファイルが存在しない場合は、新しいタブが開き、エラー メッセージが表示されます。
[ダウンロード] メニューから展開する [完全なパスのコピー] または [相対パスのコピー] オプションを選択して、完全パスまたは相対パスをコピーします。 Azure Data Lake Storage ファイルの場合は、 [Azure Storage Explorer で開く] を選択すると Azure Storage Explorer が開き、サインイン後そのフォルダーに移動します。
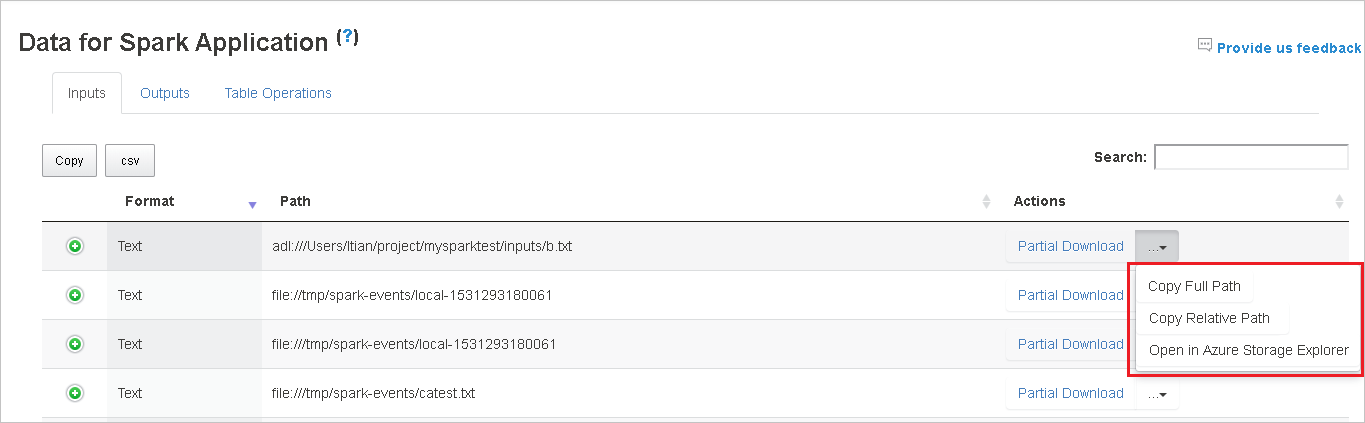
1 つのページに表示するには行が多すぎる場合は、テーブルの下部にあるページ番号を選択して移動します。

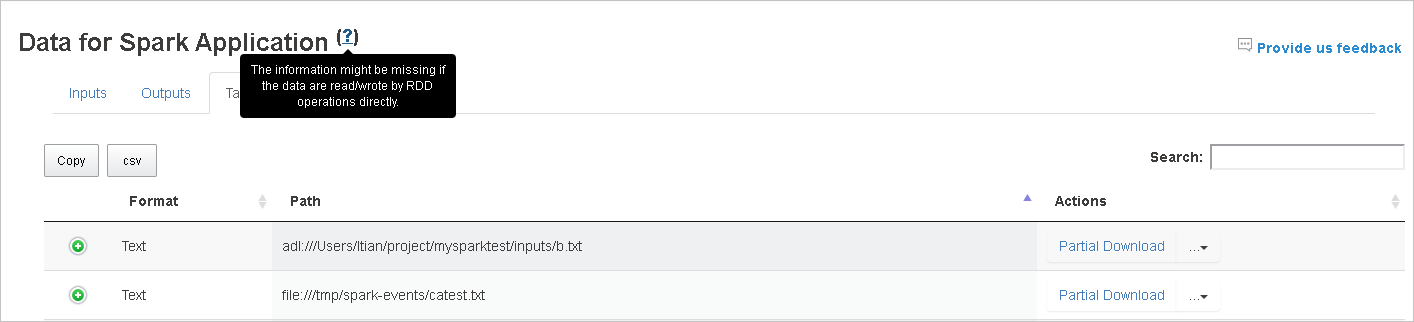
詳細については、 [Spark アプリケーションのデータ] の横にある疑問符をポイントするか選択して、ヒントを表示します。
問題に関するフィードバックを送信するには、 [Provide us feedback](フィードバックをお寄せください) を選択します。
Spark History Server の [グラフ] タブを使用する
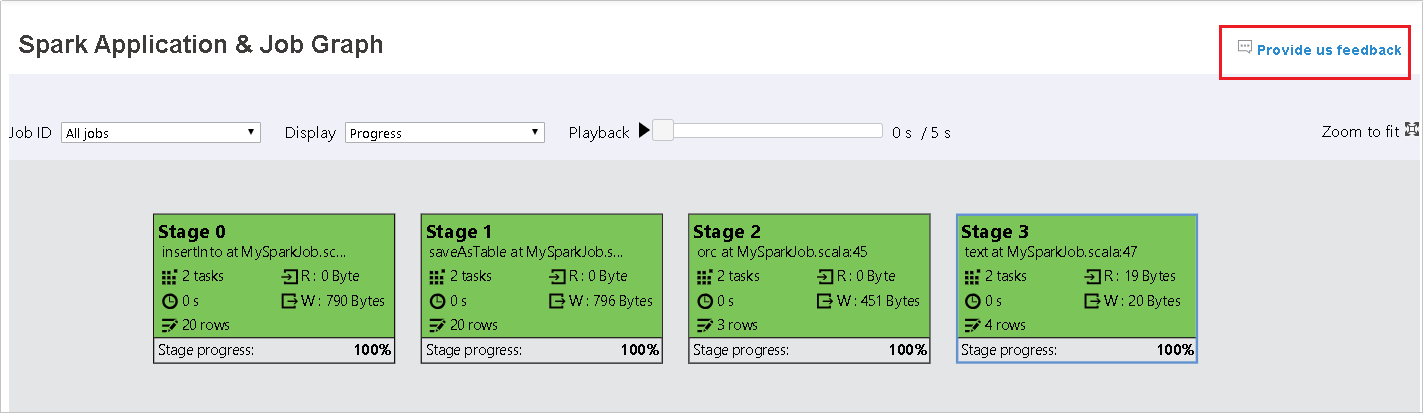
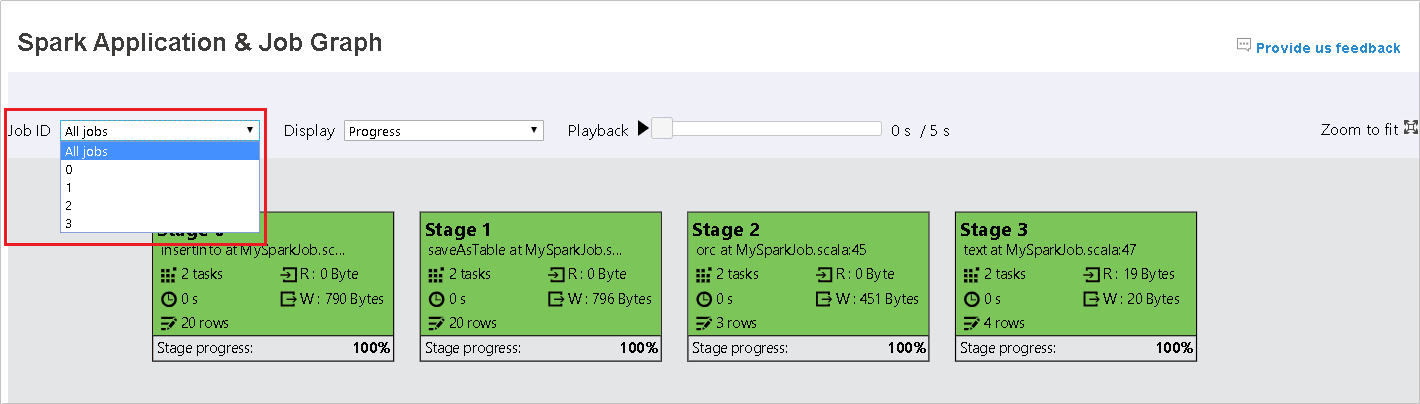
ジョブ ID を選択し、ツール メニューから [グラフ] を選択して、ジョブ グラフを表示します。 既定では、グラフにはすべてのジョブが表示されます。 [ジョブ ID] ドロップダウン メニューを使用して結果をフィルター処理します。
既定では、 [進行状況] が選択されています。 データ フローを確認するには、 [表示] ドロップダウン メニューで [読み取り] または [書き込み] を選択します。
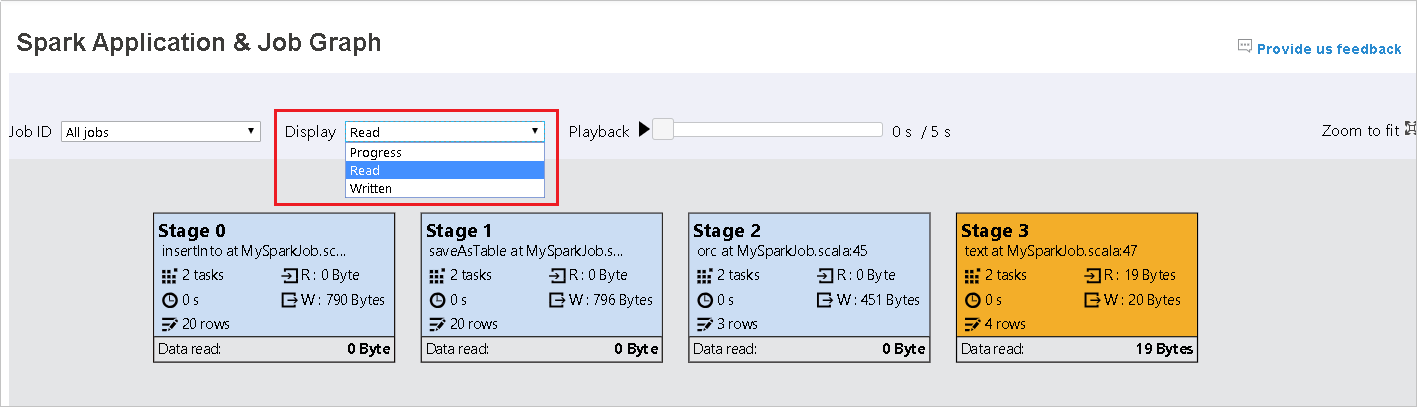
各タスクの背景色はヒートマップに対応します。

Color 説明 [緑] ジョブは正常に完了しました。 オレンジ タスクは失敗しましたが、これはジョブの最終結果には影響しません。 このようなタスクには、後で成功する可能性がある重複するインスタンスまたは再試行インスタンスがあります。 青 タスクは実行中です。 White タスクは実行を待機しているか、ステージがスキップされました。 [赤] タスクは失敗しました。 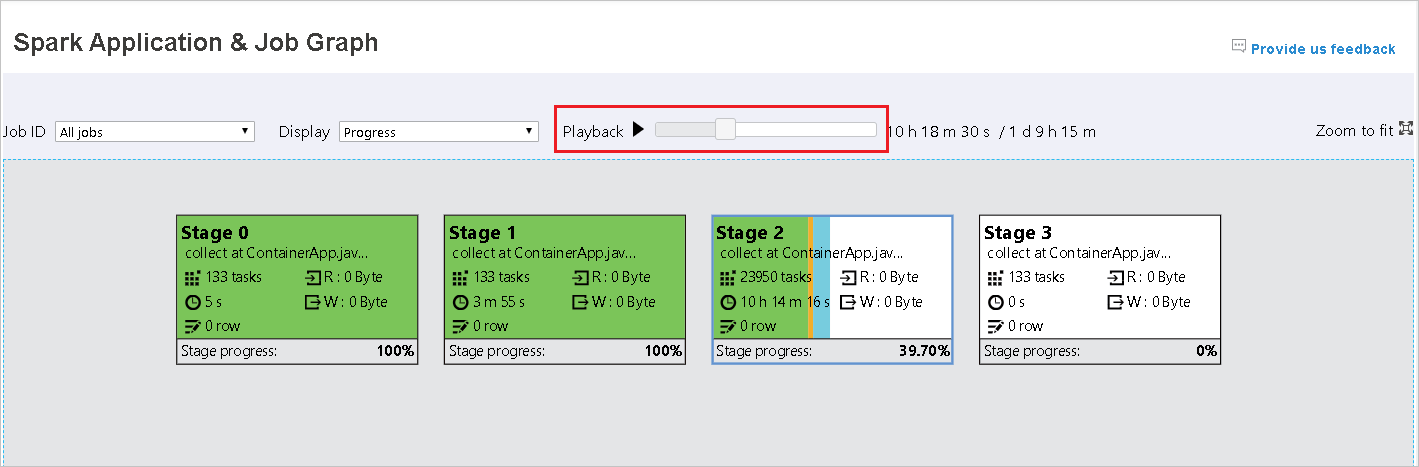
スキップされたステージは白で表示されます。
Note
再生は、完了したジョブに対して使用できます。 [再生] ボタンを選択して、ジョブを再生します。 [停止] ボタンを選択して、いつでもジョブを停止できます。 ジョブが再生されると、各タスクの状態が色別に表示されます。 不完全なジョブでは再生はサポートされていません。
ジョブ グラフを拡大または縮小するにはスクロールするか、画面に合わせるには、 [ウィンドウのサイズに合わせて大きさを変更] を選択します。
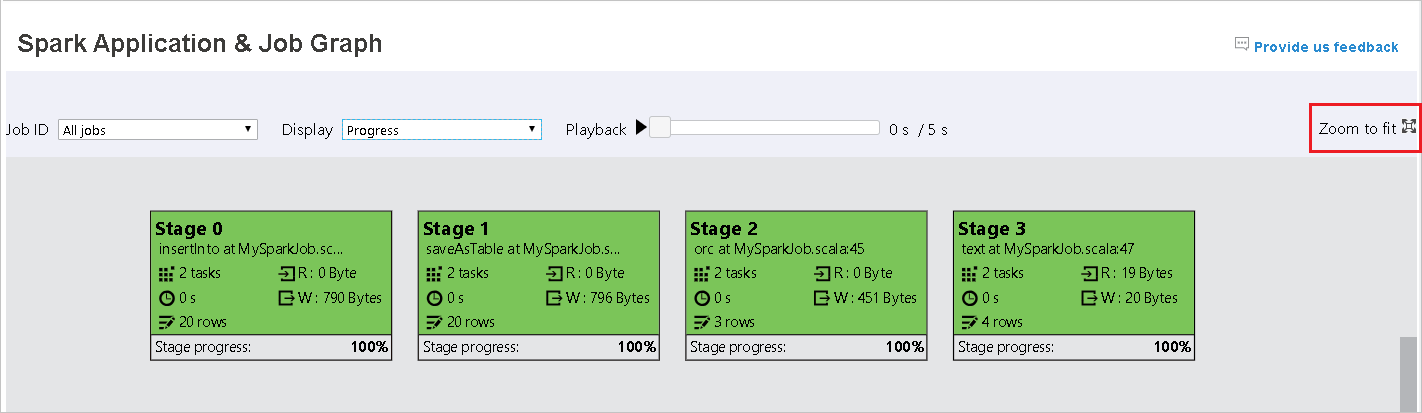
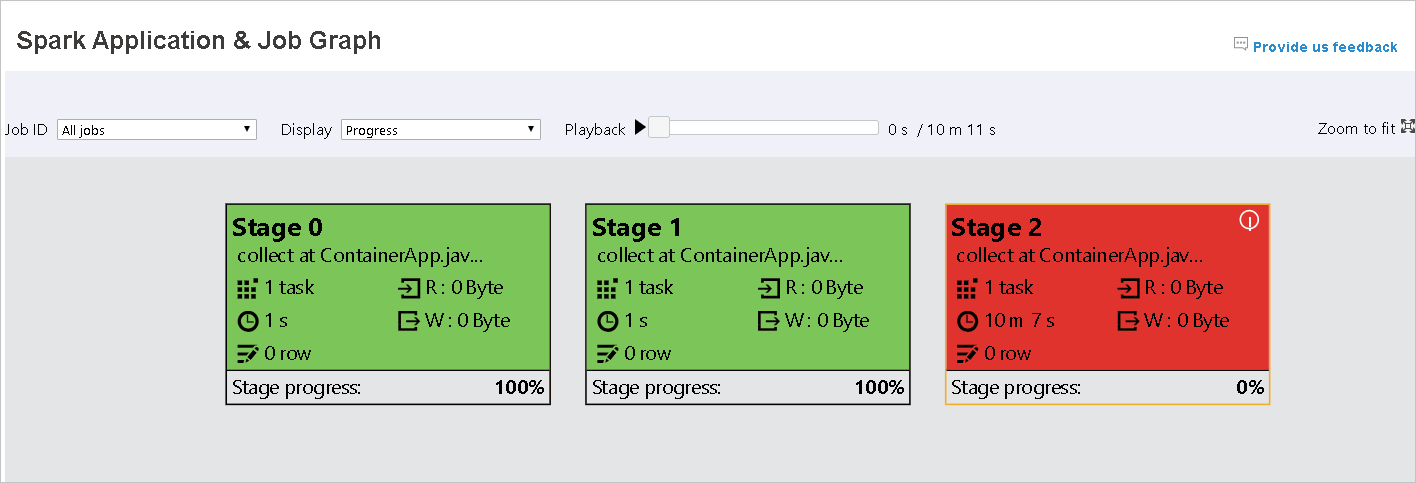
タスクが失敗した場合は、グラフ ノードの上にマウスのポインターを移動してヒントを表示し、ステージを選択して新しいページで開きます。
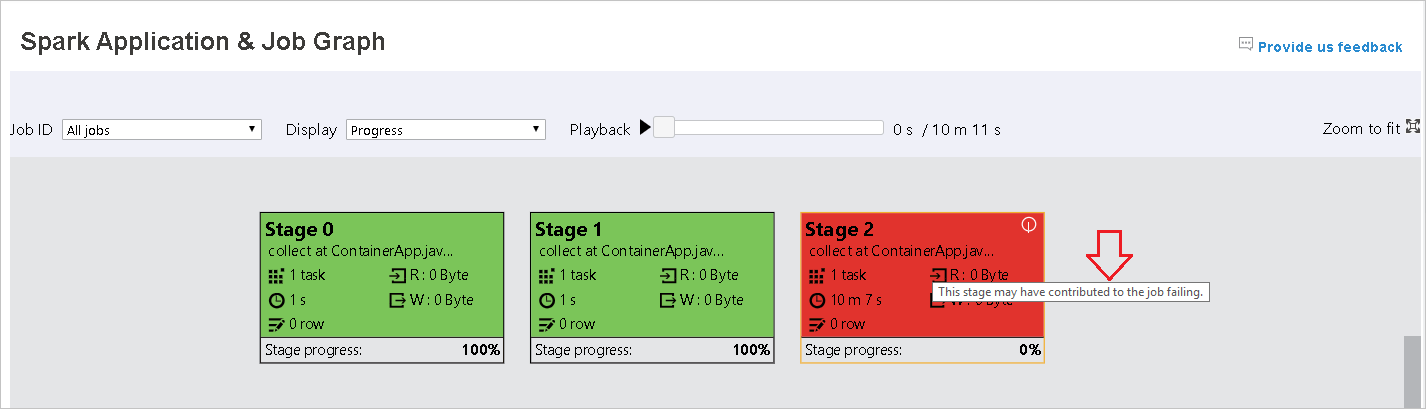
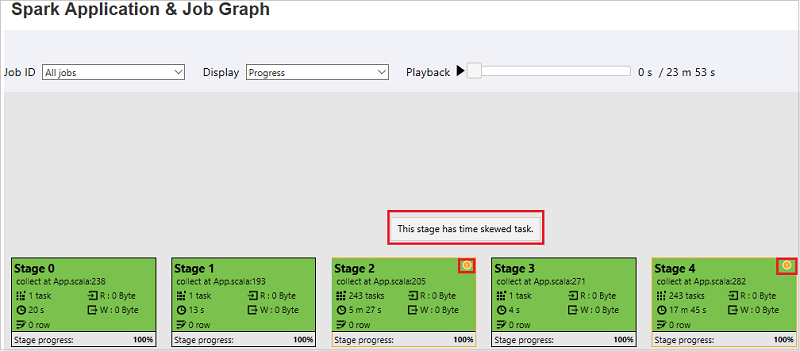
[Spark アプリケーション & ジョブグラフ] ページでは、タスクが次の条件を満たしている場合、ステージにヒントと小さいアイコンが表示されます。
データ スキュー: データの読み取りサイズ > このステージ内のすべてのタスクの平均データ読み取りサイズ * 2 データ読み取りサイズ > 10 MB
時間のずれ: 実行時間 > このステージ内のすべてのタスクの平均実行時間 * 2 実行時間 > 2 分
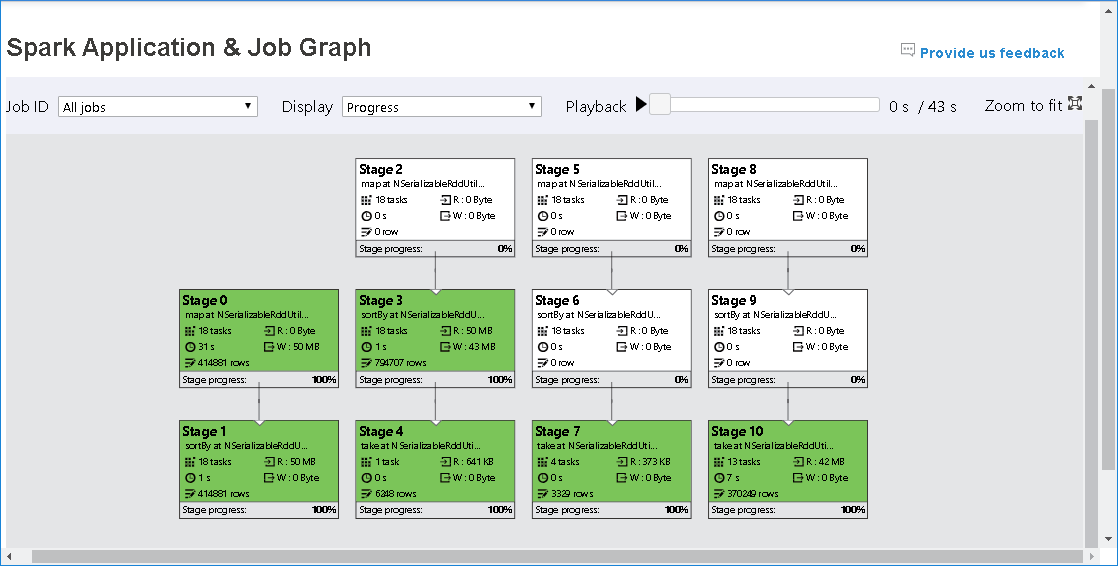
ジョブ グラフ ノードには、各ステージの次の情報が表示されます。
id
名前または説明
合計タスク数
データ読み取り: 入力サイズとシャッフル読み取りサイズの合計
データ書き込み: 出力サイズとシャッフル書き込みサイズの合計
実行時間: 最初の試行の開始時刻と最後の試行の完了時刻の間の時間
行数: 入力レコード、出力レコード、シャッフル読み取りレコード、シャッフル書き込みレコードの合計
進行状況
注意
既定で、ジョブ グラフ ノードには各ステージの最後の試行の情報が表示されます (ステージの実行時間を除く)。 ただし、再生中のジョブ グラフ ノードには、各試行の情報が表示されます。
注意
データの読み取りとデータ書き込みのサイズについては、1 MB = 1000 KB = 1000 * 1000 バイトを使用します。
[Provide us feedback](フィードバックをお寄せください) を選択することで、問題のフィードバックを送信できます。
Spark History Server の [Diagnosis](診断) タブを使用する
ジョブ ID を選択し、ツール メニューから [Diagnosis](診断) を選択して、ジョブ診断を表示します。 [Diagnosis](診断) タブには、 [Data Skew](データ スキュー) 、 [Time Skew](時間のずれ) 、および [Executor Usage Analysis](実行プログラムの使用状況の分析) が含まれます。
それぞれのタブを選択して、 [データ スキュー] 、 [時間のずれ] 、 [Executor Usage Analysis](Executor 利用状況分析) を確認します。
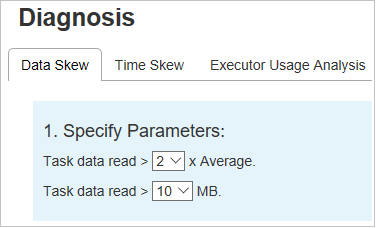
[Data Skew](データ スキュー)
[Data Skew](データ スキュー) タブを選択します。指定したパラメーターに基づいて、対応する偏りのあるタスクが表示されます。
パラメーターの指定
[パラメーターの指定] セクションには、データ スキューの検出に使用するパラメーターが表示されます。 既定の規則は次のとおりです。読み取られたタスク データが、読み取られたタスク データの平均量の 3 倍を超えており、なおかつ 10 MB を超えていることが指定されている。 傾斜したタスクに独自の規則を定義する場合は、パラメーターを選択できます。 [Skewed Stage](傾斜したステージ) と [Skew Chart](スキュー グラフ) セクションは、それに応じて更新されます。
傾斜したステージ
[Skewed Stage](傾斜したステージ) セクションには、指定された条件を満たす傾斜したタスクが表示されます。 ステージに傾斜したタスクが複数ある場合、 [Skewed Stage](傾斜したステージ) セクションには、最も傾斜しているタスク (データ スキューのデータが最大のタスク) だけが表示されます。
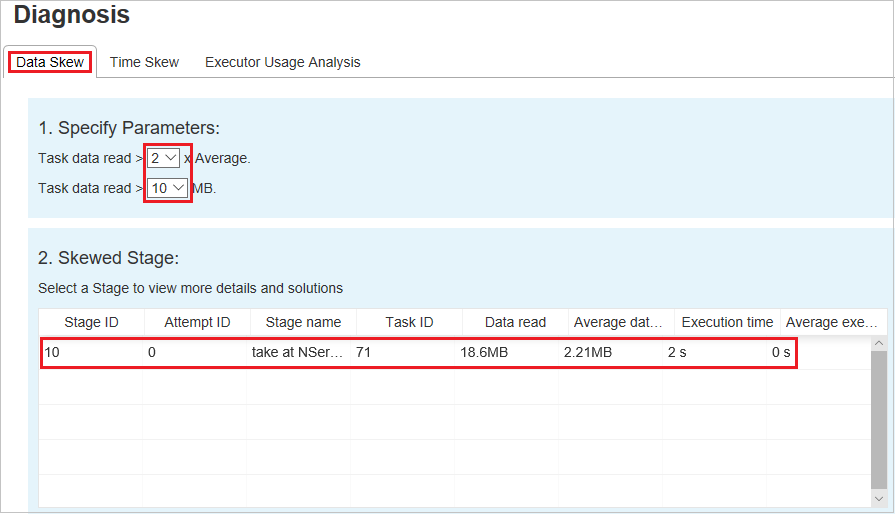
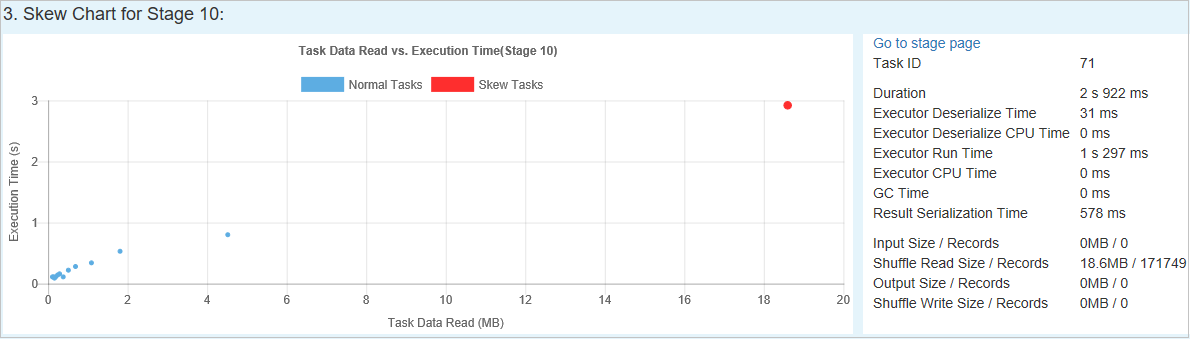
スキュー グラフ
[Skew Stage](傾斜したステージ) テーブルの行を選択すると、データの読み取りと実行時間に基づいて、 [Skew Chart](スキュー グラフ) にさらに多くのタスク分布の詳細が表示されます。 傾斜したタスクは赤でマークされ、通常のタスクは青でマークされます。 パフォーマンスを考慮し、グラフには最大 100 個のサンプル タスクが表示されます。 タスクの詳細は、右下のパネルに表示されます。
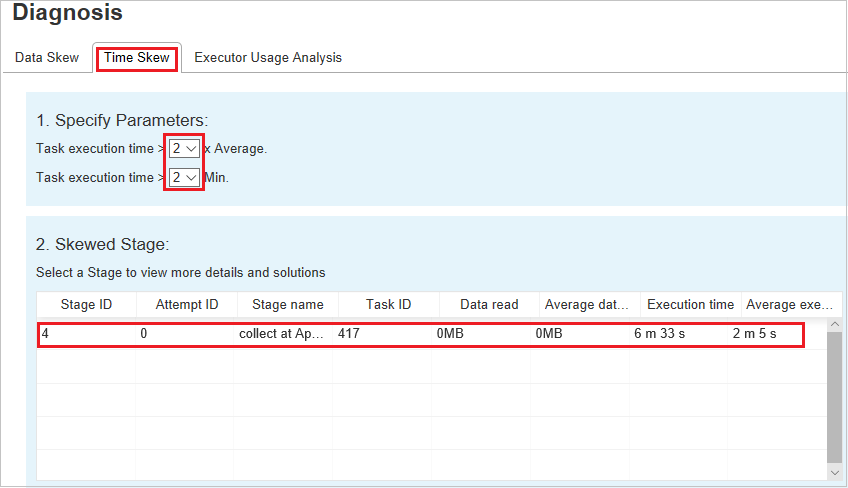
[Time Skew](時間のずれ)
[Time Skew](時間のずれ) タブには、タスクの実行時間に基づいて偏りのあるタスクが表示されます。
パラメーターの指定
[パラメーターの指定] セクションには、時間のずれの検出に使用するパラメーターが表示されます。 既定の規則は次のとおりです。タスクの実行時間が平均実行時間の 3 倍を超えており、なおかつ 30 秒を超えていることです。 必要に応じてパラメーターを変更できます。 [Skewed Stage](傾斜したステージ) と [Skew Chart](スキュー グラフ) には、 [Data Skew](データ スキュー) タブと同様に対応するステージとタスクの情報が表示されます。
[Time Skew](時間のずれ) を選択すると、 [パラメーターの指定] セクションで設定されたパラメーターに従って、フィルター処理された結果が [Skewed Stage](傾斜したステージ) セクションに表示されます。 [Skewed Stage](傾斜したステージ) セクションで 1 つの項目を選択すると、3 番目のセクションに対応するグラフがドラフト表示され、右下のパネルにタスクの詳細が表示されます。
実行プログラムの使用状況の分析グラフ
[Executor Usage Graph](実行プログラムの使用状況グラフ) は、ジョブの実際の実行プログラムの割り当てと実行状態を視覚化します。
[実行プログラムの使用状況の分析] を選択すると、実行プログラムの使用に関する 4 つの異なる曲線がドラフトされます。 [Allocated Executors](割り当て済みの実行プログラム) 、 [Running Executors](実行中の実行プログラム) 、 [idle Executors](アイドルの実行プログラム) 、 [Max Executor Instances](最大実行プログラム インスタンス) 。 [Executor added](実行プログラムの追加) イベントまたは [Executor removed](実行プログラムの削除) イベントごとに割り当て済み実行プログラムが増減します。 詳細な比較については、 [Jobs](ジョブ) タブの [Event Timeline](イベントのタイムライン) を確認します。
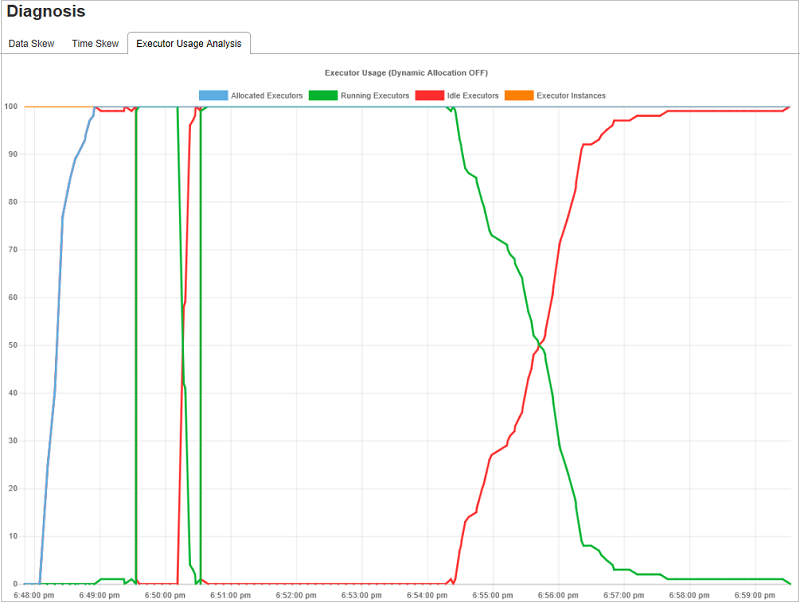
色のアイコンを選択すると、すべての下書きの対応する内容が選択または選択解除されます。

よく寄せられる質問
コミュニティ バージョンに戻すにはどうすればよいですか。
コミュニティ バージョンに戻すには、次の手順を実行します。
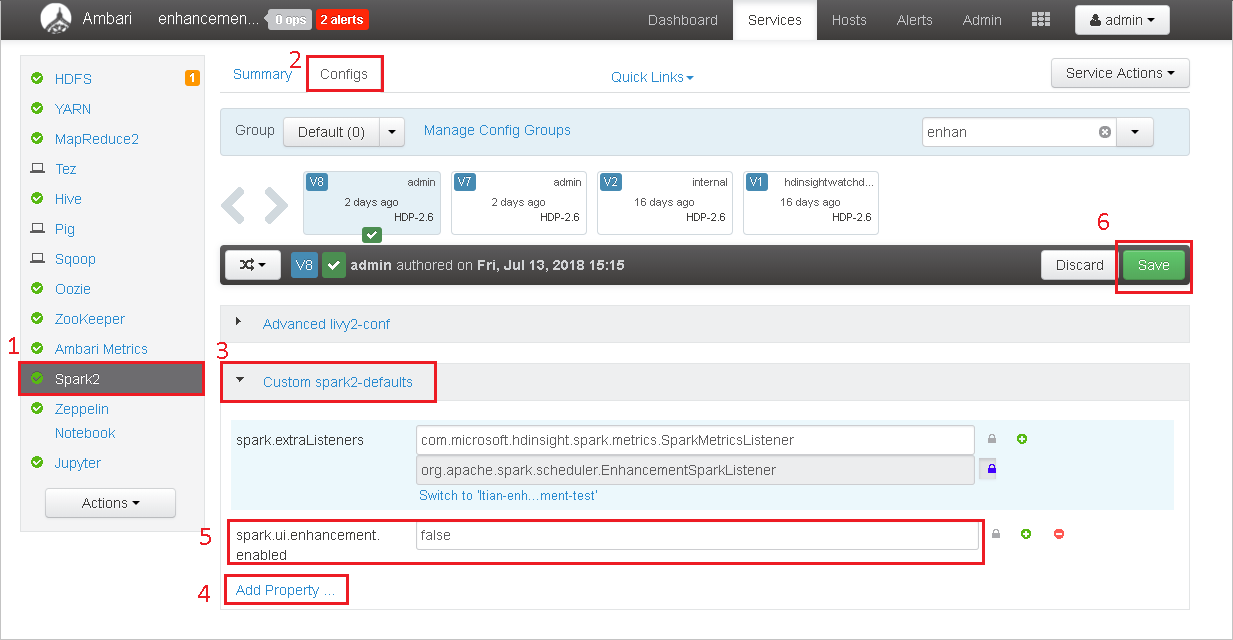
Ambari でクラスターを開きます。
Spark2>[構成] に移動します。
[Custom spark2-defaults](カスタム Spark2 既定値) を選択します。
[Add Property](プロパティの追加) を選択します。
spark.ui.enhancement.enabled=false を追加してから保存します。
これで、プロパティが false に設定されます。
[保存] を選んで構成を保存します。
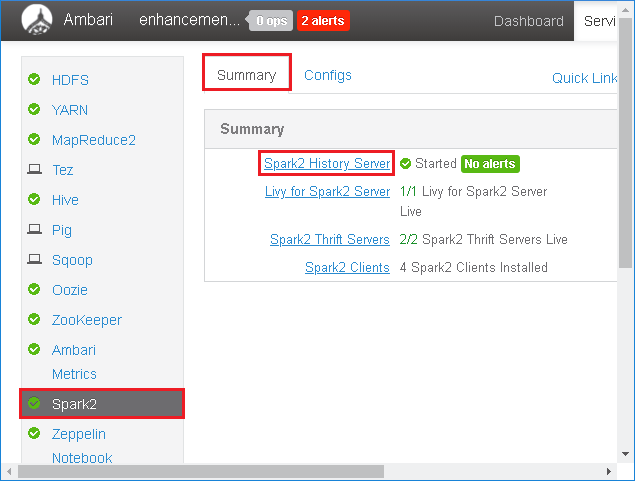
左側のパネルで Spark2 を選択します。 次に、 [概要] タブで、 [Spark2.x History Server] を選択します。
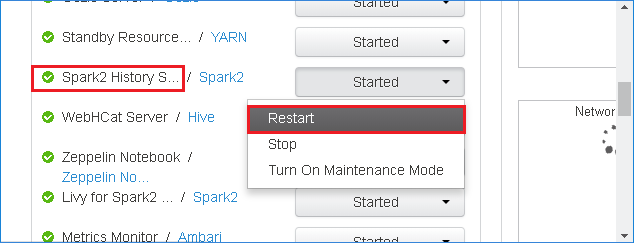
Spark History Server を再起動するには Spark2 History Serverの右側にある [開始] ボタンを選択し、ドロップダウン メニューから [再起動] を選択します。
Spark History Server Web UI を更新します。 こうすることで、コミュニティ バージョンに戻ります。
Spark History Server イベントを問題としてアップロードして報告するにはどうしたらいいですか。
Spark History Server でエラーが発生した場合は、次の手順を実行してイベントを報告します。
Spark History Server の Web UI で [ダウンロード] を選択して、イベントをダウンロードします。

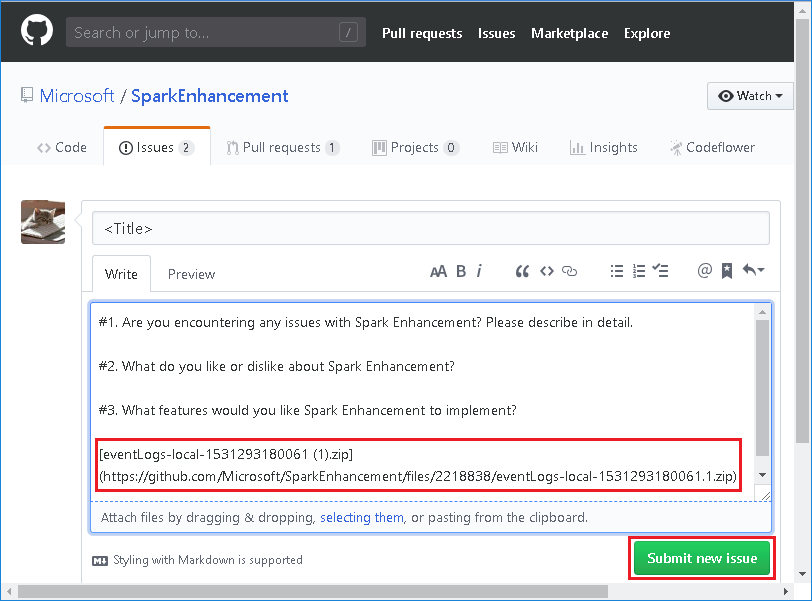
[Spark アプリケーションとジョブ グラフ] ページで [Provide us feedback]\(フィードバックをお寄せください\) を選択します。
エラーのタイトルと説明を入力します。 次に、.zip ファイルを編集フィールドにドラッグし、 [Submit new issue](新しい問題の送信) を選択します。
修正プログラムのシナリオで .jar ファイルをアップグレードするにはどうしたらいいですか。
修正プログラムを使用してアップグレードする場合は、次のスクリプトを使用して spark-enhancement.jar* をアップグレードします。
upgrade_spark_enhancement.sh:
#!/usr/bin/env bash
# Copyright (C) Microsoft Corporation. All rights reserved.
# Arguments:
# $1 Enhancement jar path
if [ "$#" -ne 1 ]; then
>&2 echo "Please provide the upgrade jar path."
exit 1
fi
install_jar() {
tmp_jar_path="/tmp/spark-enhancement-hotfix-$( date +%s )"
if wget -O "$tmp_jar_path" "$2"; then
for FILE in "$1"/spark-enhancement*.jar
do
back_up_path="$FILE.original.$( date +%s )"
echo "Back up $FILE to $back_up_path"
mv "$FILE" "$back_up_path"
echo "Copy the hotfix jar file from $tmp_jar_path to $FILE"
cp "$tmp_jar_path" "$FILE"
"Hotfix done."
break
done
else
>&2 echo "Download jar file failed."
exit 1
fi
}
jars_folder="/usr/hdp/current/spark2-client/jars"
jar_path=$1
if ls ${jars_folder}/spark-enhancement*.jar 1>/dev/null 2>&1; then
install_jar "$jars_folder" "$jar_path"
else
>&2 echo "There is no target jar on this node. Exit with no action."
exit 0
fi
使用法
upgrade_spark_enhancement.sh https://${jar_path}
例
upgrade_spark_enhancement.sh https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar
bash ファイルを Azure Portal から使用する
Azure portal を起動し、クラスターを選択します。
次のパラメーターを使用して、スクリプト操作を完了します。
プロパティ 値 スクリプトの種類 - Custom 名前 UpgradeJar Bash スクリプト URI https://hdinsighttoolingstorage.blob.core.windows.net/shsscriptactions/upgrade_spark_enhancement.shノードの種類 ヘッド、ワーカー パラメーター https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar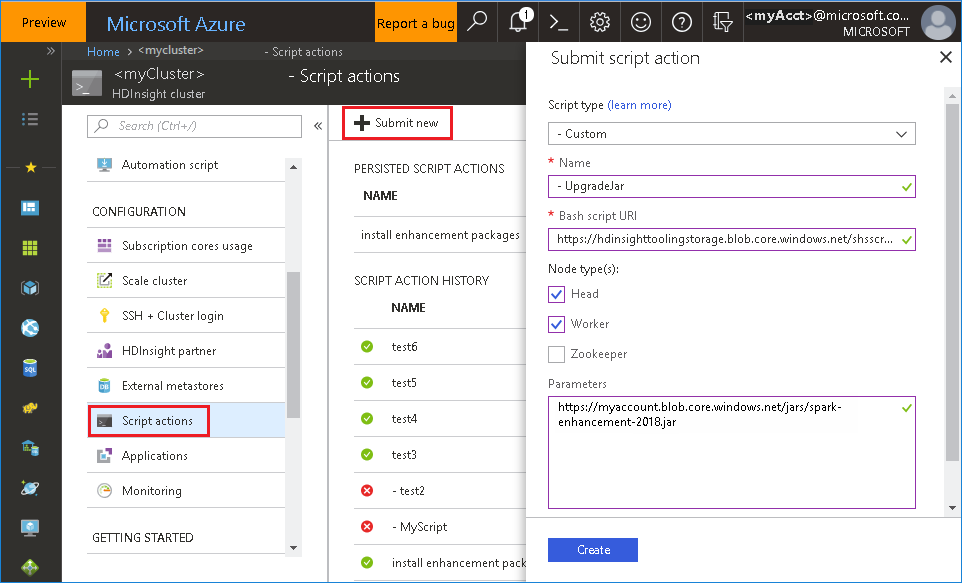
既知の問題
現時点では、Spark History Server は Spark 2.3 と Spark 2.4 に対してのみ機能します。
RDD を使用する入力データと出力データは、 [Data](データ) タブに表示されません。
次のステップ
検索候補
フィードバックがある場合やこのツールの使用中に問題が発生した場合は、hdivstool@microsoft.com にメールをお送りください。