Azure HDInsight IO キャッシュを使用して Apache Spark のワークロードのパフォーマンスを改善する
Note
- IO キャッシュは Spark 2.3 までサポートされており、Spark 2.4 (HDInsight 4.0) と Spark 3.1.2 (HDInsight 5.0) ではサポートされません
IO キャッシュは、Apache Spark のジョブのパフォーマンスを改善する、Azure HDInsight 用のデータ キャッシュ サービスです。 IO キャッシュは Apache TEZ や Apache Hive のワークロードでも機能し、Apache Spark のクラスター上で実行できます。 IO キャッシュは RubiX と呼ばれるオープン ソースのキャッシュ コンポーネントを使用します。 RubiX はビッグ データ分析エンジンで使用されるローカル ディスク キャッシュで、クラウド ストレージ システムからデータにアクセスします。 RubiX は、キャッシュ目的でオペレーティング メモリを予約するのではなくソリッド ステート ドライブ (SSD) を使用するため、キャッシュ システム間で一意です。 IO キャッシュ サービスはクラスターの各ワーカー ノード上に RubiX メタデータ サーバーを起動して管理します。 また、RubiX キャッシュの透過的な使用のためにクラスターのすべてのサービスを構成します。
ほとんどの SSD の帯域幅は 1 秒につき 1 GB 以上です。 この帯域幅はオペレーティング システムのインメモリ ファイル キャッシュによって補完され、Apache Spark などのビッグ データ演算処理エンジンを読み込むのに十分な帯域幅を提供します。 オペレーティング メモリは、シャッフルなどのメモリに大きく依存するタスクを処理するために Apache Spark が利用できるように残されています。 オペレーティング メモリを排他的に使用できることにより、Apache Spark が最適なリソース使用量を達成できます。
Note
現在、IO キャッシュは RubiX をキャッシュ コンポーネントとして使用しますが、将来のバージョンのサービスでは変わる可能性があります。 IO キャッシュのインターフェイスを使用し、RubiX の実装に直接依存することはしないでください。 現時点では、IO キャッシュは Azure Blob Storage でのみサポートされています。
Azure HDInsight IO キャッシュの利点
IO キャッシュを使用すると、Azure Blob Storage からデータを読み取るジョブのパフォーマンスを改善します。
IO キャッシュを使用すると、Spark のジョブに変更を加えなくてもパフォーマンスの改善が見られます。 IO キャッシュを無効にすると、Spark コード spark.read.load('wasbs:///myfolder/data.parquet').count() は Azure Blob Storage からデータをリモートで読み取ります。 IO キャッシュをアクティブにすると、IO キャッシュによってそのコードの同じ行で キャッシュされた読み取りが行われます。 続く読み取りでは、データが SSD からローカルで読み取られます。 HDInsight クラスター上のワーカー ノードにはローカルで接続された専用の SSD ドライブが備わっています。 HDInsight IO キャッシュはこれらのローカル SSD を使用してキャッシュを行います。これにより、最小レベルの待ち時間を実現し、帯域幅を最大化します。
作業の開始
Azure HDInsight IO キャッシュはプレビューでは既定で非アクティブ化されます。 IO キャッシュは Azure HDInsight 3.6 以上の Spark クラスターで利用可能で、Apache Spark 2.3 を実行します。 HDInsight 4.0 上で IO キャッシュをアクティブ化するには、次の手順を実行します。
Web ブラウザーから、
https://CLUSTERNAME.azurehdinsight.netに移動します。ここで、CLUSTERNAMEはクラスターの名前です。左側の [IO キャッシュ] を選択します。
[アクション] (HDI 3.6 では [Service Actions](サービス アクション))、[有効にする] の順に選択します。
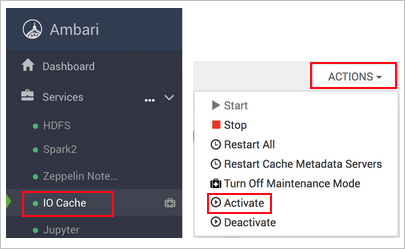
影響を受けるクラスター上のすべてのサービスの再起動を確認します。
Note
進行状況バーにアクティブ化と表示されていても、IO キャッシュは実際には 影響を受ける他のサービスを再起動するまで有効になりません。
トラブルシューティング
IO キャッシュを有効にした後に Spark のジョブを実行するとディスク領域エラーが発生することがあります。 これらのエラーは、Spark がシャッフル操作中にデータの格納にもローカル ディスク ストレージを使用することが原因で発生します。 IO キャッシュが有効になり、Spark のストレージ領域が減ると、Spark で SSD 領域が不足する場合があります。 IO キャッシュで使用されるディスク領域は既定で SSD の合計領域の半分になります。 IO キャッシュのディスク領域使用量は Ambari で構成できます。 ディスク領域のエラーが発生した場合は、IO キャッシュで使用されるSSD 領域を減らし、サービスを再起動してください。 IO キャッシュに設定されている領域を変更するには、次の手順を実行します。
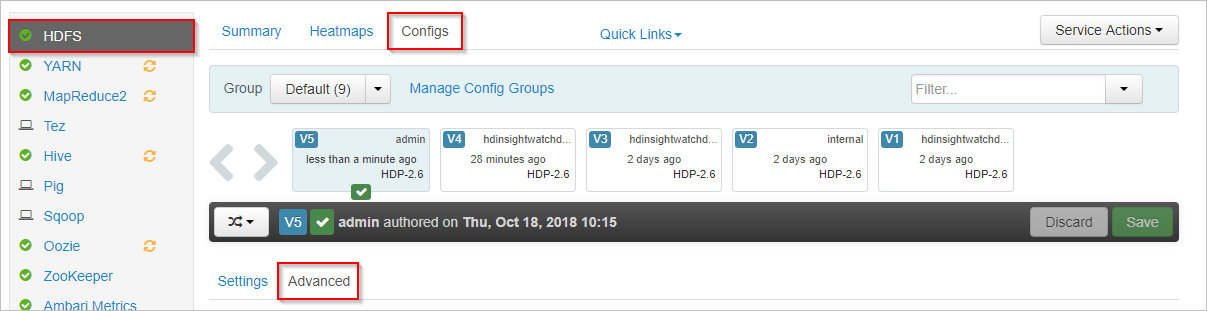
Apache Ambari で、左側にある [HDFS] サービスを選択します。
[Configs](構成) タブを選択し、[Advanced](詳細) タブを選択します。
下にスクロールし、[Custom core-site](カスタム コアサイト) 領域を展開します。
プロパティ hadoop.cache.data.fullness.percentage を探します。
ボックスの値を変更します。
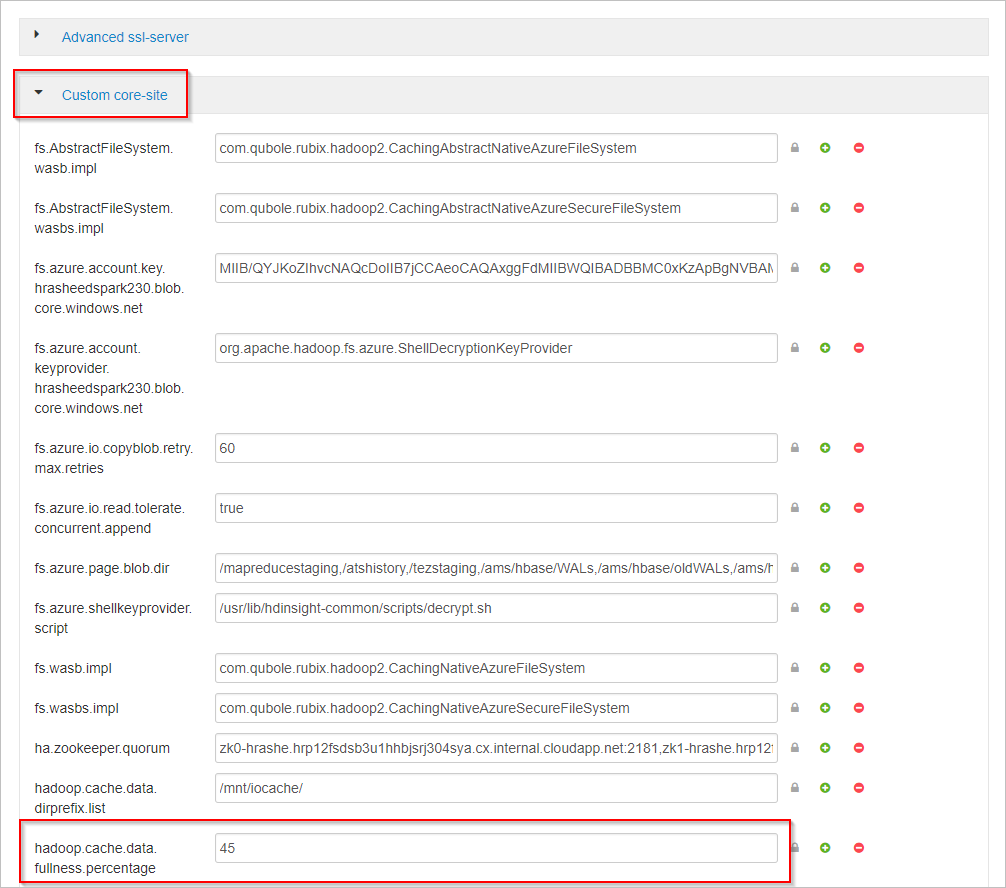
右上の [Save](保存) を選択します。
[Restart](再起動)>[Restart All Affected](影響を受けるすべてを再起動) を選択します。

[Confirm Restart All](すべて再起動) を選択します。
それでもうまくいかない場合は、IO キャッシュを無効にしてください。
次の手順
IO キャッシュとパフォーマンスのベンチマークについて詳しくは、ブログ投稿「Apache Spark jobs gain up to 9x speed up with HDInsight IO キャッシュ」(HDInsight IO キャッシュにより Apache Spark のジョブの速度が最大で 9 倍に) をご覧ください。