チュートリアル:Azure HDInsight での Apache Spark クラスターへのデータの読み込みとクエリの実行
このチュートリアルでは、csv ファイルからデータフレームを作成する方法と、Azure HDInsight で Apache Spark クラスターに対して対話型の Spark SQL クエリを実行する方法を説明します。 Spark で、データフレームは、名前付きの列に編成されたデータの分散型コレクションです。 データフレームは概念的には、リレーショナル データベースのテーブルまたは R/Python のデータ フレームと同等です。
このチュートリアルでは、以下の内容を学習します。
- csv ファイルからデータフレームを作成する
- データフレームでクエリを実行する
前提条件
HDInsight での Apache Spark クラスター。 Apache Spark クラスターの作成に関するページを参照してください。
Jupyter Notebook の作成
Jupyter Notebook は、さまざまなプログラミング言語をサポートする対話型のノートブック環境です。 ノートブックを使うと、データと対話し、Markdown テキストとコードを組み合わせて、簡単な視覚化を実行できます。
URL
https://SPARKCLUSTER.azurehdinsight.net/jupyterを編集して、SPARKCLUSTERを Spark クラスターの名前に置き換えます。 編集した URL を Web ブラウザーに入力します。 入力を求められたら、クラスターのログイン資格情報を入力します。Jupyter の Web ページで、Spark 2.4 クラスターの場合は、[New](新規)>[PySpark] の順に選択して、ノートブックを作成します。 Spark 3.1 リリースでは、代わりに [New](新規)>[PySpark3] を選択してノートブックを作成します。これは、PySpark カーネルが Spark 3.1 で使用できなくなったためです。
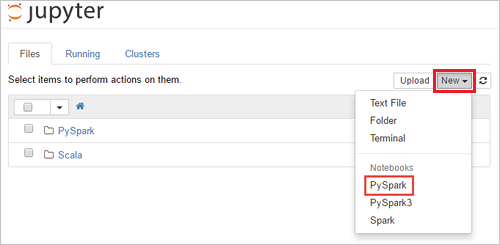
Untitled (
Untitled.ipynb) という名前の新しいノートブックが作成されて開かれます。Note
PySpark または PySpark3 カーネルを使用してノートブックを作成すると、最初のコード セルを実行するときに
sparkセッションが自動的に作成されます。 セッションを明示的に作成する必要はありません。
csv ファイルからデータフレームを作成する
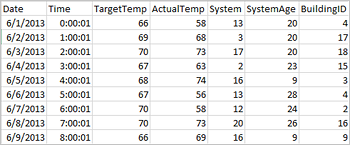
アプリケーションは、リモート ストレージ (Azure Storage、Azure Data Lake Storage など) にあるファイルやフォルダーか、Hive テーブル、または Spark でサポートされている他のデータ ソース (Azure Cosmos DB、Azure SQL DB、DW など) から直接データフレームを作成できます。 次のスクリーンショットは、このチュートリアルで使用されている HVAC.csv ファイルのスナップショットを示しています。 csv ファイルには、すべての HDInsight Spark クラスターが付属します。 このデータは、いくつかのビルの温度の変化をキャプチャしています。
次のコードを Jupyter Notebook の空のセルに貼り付け、Shift + Enter キーを押してコードを実行します。 このコードにより、このシナリオに必要な種類がインポートされます。
from pyspark.sql import * from pyspark.sql.types import *Jupyter で対話型のクエリを実行すると、Web ブラウザー ウィンドウまたはタブのキャプションに [(ビジー)] 状態と Notebook のタイトルが表示されます。 また、右上隅にある PySpark というテキストの横に黒丸も表示されます。 ジョブが完了すると、白丸に変化します。
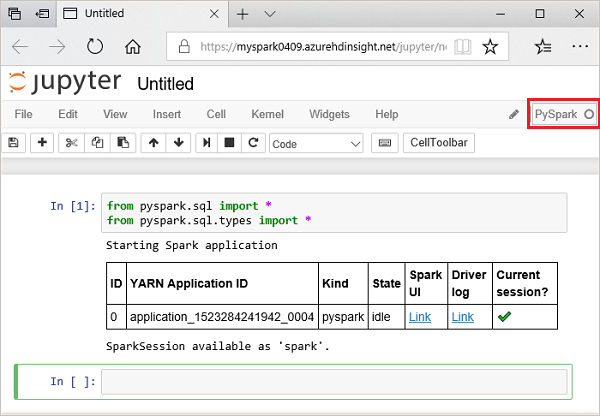
返されたセッション ID をメモしておきます。 上の図では、セッション ID は 0 です。 必要に応じて、
https://CLUSTERNAME.azurehdinsight.net/livy/sessions/ID/statementsに移動してセッションの詳細を取得できます。ここで、CLUSTERNAME は Spark クラスターの名前、ID はセッション ID 番号です。次のコードを実行してデータフレームと一時テーブル (hvac) を作成します。
# Create a dataframe and table from sample data csvFile = spark.read.csv('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write.saveAsTable("hvac")
データフレームでクエリを実行する
テーブルを作成したら、データに対して対話型のクエリを実行できます。
Notebook の空のセルで次のコードを実行します。
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"次の表形式の出力が表示されます。
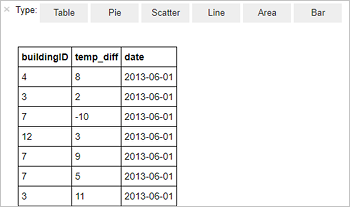
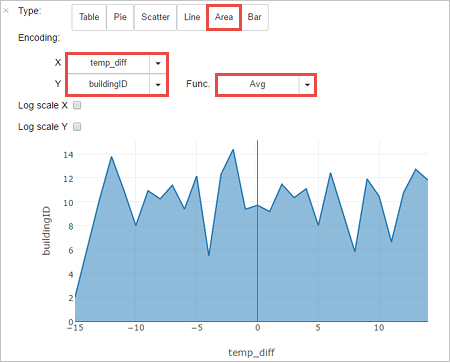
他の視覚化で結果を表示することもできます。 同じ出力に対する領域グラフを表示するには、 [領域] を選択し、他の値を次のように設定します。
ノートブックのメニュー バーから [ファイル]>[Save and Checkpoint]\(保存とチェックポイント) に移動します。
次のチュートリアルをすぐに開始する場合は、Notebook を開いたままにしておきます。 開始しない場合は、ノートブックのメニュー バーから [ファイル]>[Close and Halt]\(閉じて停止) に移動し、ノートブックをシャットダウンしてクラスター リソースを解放します。
リソースをクリーンアップする
HDInsight を使用すると、データと Jupyter Notebook は Azure Storage または Azure Data Lake Storage に格納されるため、クラスターは、使用されていない場合に安全に削除できます。 また、HDInsight クラスターは、使用していない場合でも課金されます。 クラスターの料金は Storage の料金の何倍にもなるため、クラスターを使用しない場合は削除するのが経済的にも合理的です。 すぐに次のチュートリアルに取り掛かる場合は、クラスターを保持することができます。
Azure Portal で、クラスターを開き、 [削除] を選択します。
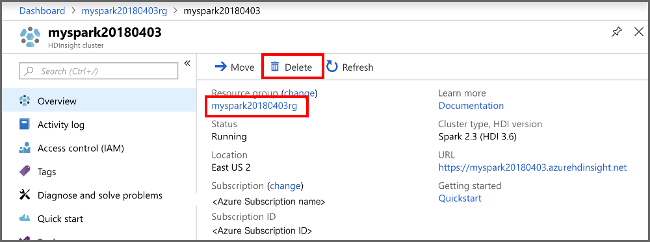
リソース グループ名を選び、リソース グループ ページを開いて、 [リソース グループの削除] を選ぶこともできます。 リソース グループを削除すると、HDInsight Spark クラスターと既定のストレージ アカウントの両方が削除されます。
次のステップ
このチュートリアルでは、csv ファイルからデータフレームを作成する方法と、Azure HDInsight で Apache Spark クラスターに対して対話型の Spark SQL クエリを実行する方法を説明しました。 次の記事に進んで、Apache Spark に登録したデータを Power BI などの BI 分析ツールに取り込む方法を確認してください。