Create Python Model コンポーネント
この記事では Azure Machine Learning デザイナーのコンポーネントについて説明します。
Create Python Model コンポーネントを使用して、Python スクリプトから未トレーニングのモデルを作成する方法について説明します。 Azure Machine Learning デザイナー環境の Python パッケージに含まれるいずれかの学習器を、モデル作成のベースにできます。
モデルを作成した後は、Azure Machine Learning の他の学習器と同じように、モデルのトレーニングを使用してデータセットでモデルをトレーニングできます。 トレーニング済みのモデルを Score Model に渡し、予測を行うことができます。 その後、トレーニング済みのモデルを保存し、そのスコアリング ワークフローを Web サービスとして公開できます。
警告
現時点では、このコンポーネントを Tune Model Hyperparameters コンポーネントに接続することや、Python モデルのスコアリングされた結果を Evaluate Model に渡すことはできません。 ハイパーパラメーターを調整したり、モデルを評価したりする必要がある場合は、Execute Python Script コンポーネントを使用して、カスタム Python スクリプトを記述できます。
コンポーネントを構成する
このコンポーネントを使用するには、Python の中級またはエキスパートの知識が必要です。 このコンポーネントは、Azure Machine Learning に既にインストールされている Python パッケージに含まれるすべての学習器の使用をサポートしています。 「Execute Python Script」で、プレインストールされた Python パッケージの一覧を参照してください。
Note
スクリプトを記述するときは十分に注意し、宣言されていないオブジェクトやインポートされていないコンポーネントの使用など、構文エラーがないことを確認してください。
Note
また、Python スクリプトの実行で事前にインストールされているコンポーネントの一覧にも、特に注意を払ってください。 事前にインストールされているコンポーネントのみをインポートします。 このスクリプトに "pip install xgboost" などの追加パッケージをインストールしないでください。そうしないと、ダウンストリーム コンポーネントでモデルを読み取るときにエラーが発生します。
この記事では、単純なパイプラインで Create Python Model を使用する方法について説明します。 パイプラインのダイアグラムを以下に示します。
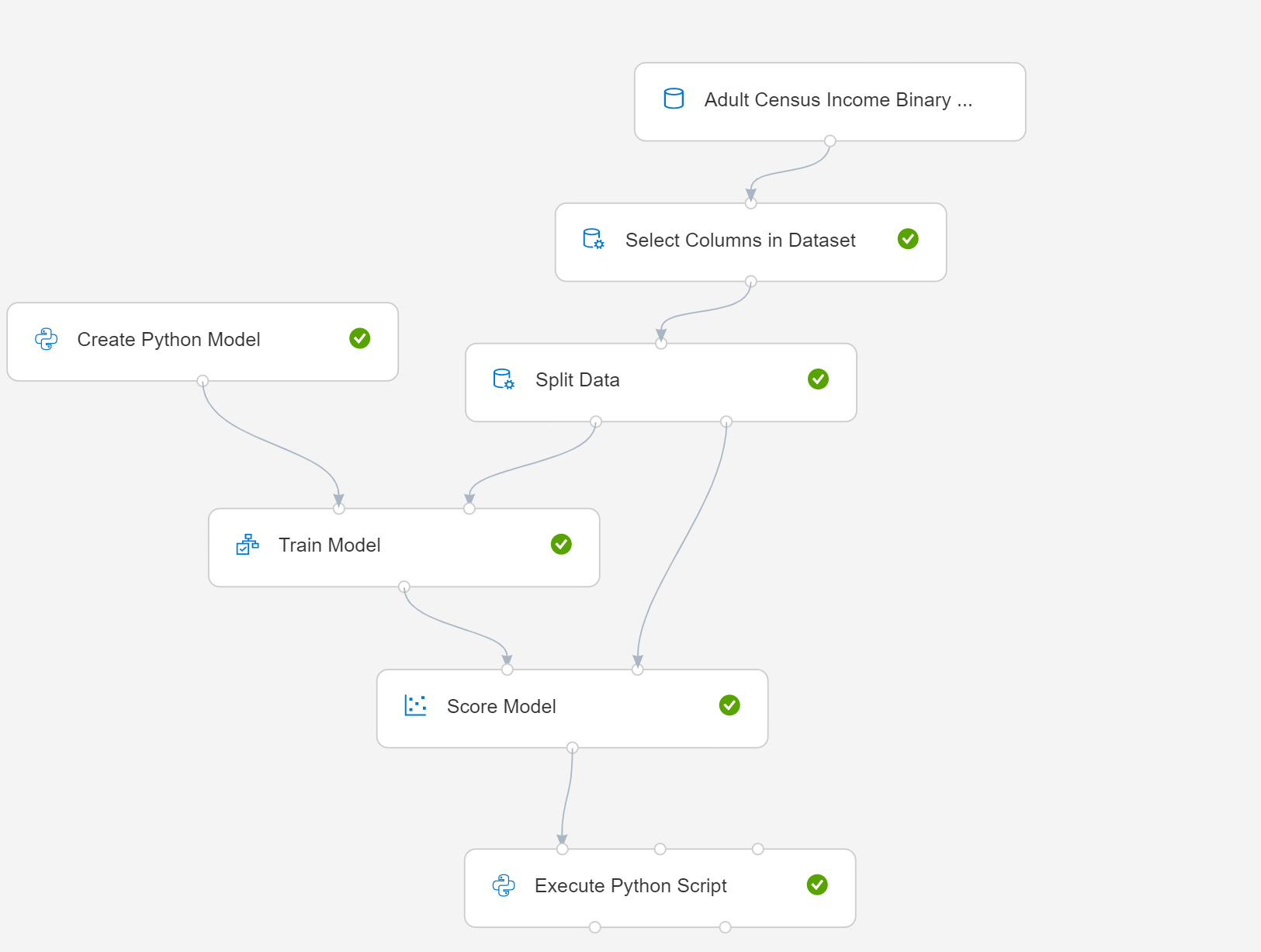
- [Create Python Model] を選択し、モデリングまたはデータ管理プロセスを実装するようにスクリプトを編集します。 Azure Machine Learning 環境の Python パッケージに含まれるいずれかの学習器を、モデル作成のベースにできます。
Note
スクリプトのサンプル コードのコメントに特に注意を払って、スクリプトがクラス名、メソッド、メソッド シグネチャなどの要件に厳密に従っていることを確認してください。 違反があると、例外が発生します。 Python モデルの作成では、sklearn ベースのモデルをモデルのトレーニングを利用して作成することだけが可能です。
2クラス Naive Bayes 分類器の以下のサンプルコードは、一般的な sklearn パッケージを使用しています。
# The script MUST define a class named Azure Machine LearningModel.
# This class MUST at least define the following three methods:
# __init__: in which self.model must be assigned,
# train: which trains self.model, the two input arguments must be pandas DataFrame,
# predict: which generates prediction result, the input argument and the prediction result MUST be pandas DataFrame.
# The signatures (method names and argument names) of all these methods MUST be exactly the same as the following example.
# Please do not install extra packages such as "pip install xgboost" in this script,
# otherwise errors will be raised when reading models in down-stream components.
import pandas as pd
from sklearn.naive_bayes import GaussianNB
class AzureMLModel:
def __init__(self):
self.model = GaussianNB()
self.feature_column_names = list()
def train(self, df_train, df_label):
# self.feature_column_names records the column names used for training.
# It is recommended to set this attribute before training so that the
# feature columns used in predict and train methods have the same names.
self.feature_column_names = df_train.columns.tolist()
self.model.fit(df_train, df_label)
def predict(self, df):
# The feature columns used for prediction MUST have the same names as the ones for training.
# The name of score column ("Scored Labels" in this case) MUST be different from any other columns in input data.
return pd.DataFrame(
{'Scored Labels': self.model.predict(df[self.feature_column_names]),
'probabilities': self.model.predict_proba(df[self.feature_column_names])[:, 1]}
)
作成した Create Python Model コンポーネントを、Train Model および Score Model に接続します。
モデルを評価する必要がある場合には、Execute Python Script コンポーネントを追加し、Python スクリプトを編集します。
以下のスクリプトは、サンプル評価コードです。
# The script MUST contain a function named azureml_main # which is the entry point for this component. # imports up here can be used to import pandas as pd # The entry point function MUST have two input arguments: # Param<dataframe1>: a pandas.DataFrame # Param<dataframe2>: a pandas.DataFrame def azureml_main(dataframe1 = None, dataframe2 = None): from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score, roc_curve import pandas as pd import numpy as np scores = dataframe1.ix[:, ("income", "Scored Labels", "probabilities")] ytrue = np.array([0 if val == '<=50K' else 1 for val in scores["income"]]) ypred = np.array([0 if val == '<=50K' else 1 for val in scores["Scored Labels"]]) probabilities = scores["probabilities"] accuracy, precision, recall, auc = \ accuracy_score(ytrue, ypred),\ precision_score(ytrue, ypred),\ recall_score(ytrue, ypred),\ roc_auc_score(ytrue, probabilities) metrics = pd.DataFrame(); metrics["Metric"] = ["Accuracy", "Precision", "Recall", "AUC"]; metrics["Value"] = [accuracy, precision, recall, auc] return metrics,
次のステップ
Azure Machine Learning で使用できる一連のコンポーネントを参照してください。