モデルの評価コンポーネント
この記事では Azure Machine Learning デザイナーのコンポーネントについて説明します。
トレーニング済みのモデルの精度は、このコンポーネントで測定します。 モデルから生成されたスコアを含むデータセットを指定すると、モデルの評価コンポーネントにより業界標準の一連の評価メトリックが計算されます。
Evaluate Model (モデルの評価) で返されるメトリックは、評価するモデルの種類によって異なります。
- 分類モデル
- 回帰モデル
- クラスター モデル
ヒント
モデルの評価に慣れていない場合は、EdX の機械学習コースの一部である、Stephen Elston 博士によるビデオ シリーズをお勧めします。
モデルの評価の使用方法
Score Model (モデルのスコア付け) のスコア付けされたデータセットの出力、または Assign Data to Clusters (クラスターへのデータの割り当て) の結果データセットの出力を Evaluate Model (モデルの評価) の左の入力ポートに接続します。
注意
"データセット内の列の選択" などのコンポーネントを使用して入力データセットの一部を選択する場合、AUC、二項分類や異常検出の精度などのメトリックを計算する、(トレーニングで使用される) "スコア付け確率" 列と "スコア付けラベル" 列の実際のラベル列が存在することを確認してください。 実際のラベル列である "Scored Labels (スコア付けラベル)" 列は、多クラス分類/回帰のメトリックを計算するために存在します。 "Assignments (割り当て)" 列、"DistancesToClusterCenter no.X" 列 (X は、0 から重心数 - 1 までの範囲の重心インデックス) は、クラスターのメトリックを計算するために存在します。
重要
- 結果を評価するには、出力データセットに、モデルの評価コンポーネントの要件を満たす特定のスコア列の名前が含まれている必要があります。
Labels列は、実際のラベルと見なされます。- 回帰タスクの場合は、評価するデータセットに、スコア付けされたラベルを表す
Regression Scored Labelsという名前の 1 つの列が含まれている必要があります。 - 二項分類タスクの場合は、評価するデータセットに
Binary Class Scored Labels、Binary Class Scored Probabilitiesという名前の 2 つの列があります。これらはそれぞれ、スコア付けラベルと確率を表します。 - マルチ分類タスクの場合は、評価するデータセットに、スコア付けされたラベルを表す
Multi Class Scored Labelsという名前の 1 つの列が含まれている必要があります。 アップストリーム コンポーネントの出力にこれらの列が含まれていない場合は、上記の要件に従って変更する必要があります。
[省略可能] Score Model (モデルのスコア付け) のスコア付けされたデータセットの出力、または 2 番目のモデルの Assign Data to Clusters (クラスターへのデータの割り当て) の結果データセットの出力を Evaluate Model (モデルの評価) の右の入力ポートに接続します。 同じデータで 2 つの異なるモデルの結果を簡単に比較できます。 2 つの入力アルゴリズムは、同じアルゴリズムの種類である必要があります。 または、異なるパラメーターを使って同じデータに対する 2 つの異なる実行からのスコアを比較することもできます。
注意
アルゴリズムの種類は、"2 クラス分類"、"多クラス分類"、"回帰"、"機械学習アルゴリズム" の "クラスタリング" を指します。
パイプラインを送信して評価スコアを生成します。
結果
モデルの評価を実行した後、コンポーネントを選択して、右側の [Evaluate Model](モデルの評価) ナビゲーション パネルを開きます。 次に、 [出力 + ログ] タブを選択します。このタブの [データ出力] セクションには複数のアイコンがあります。 [可視化] アイコンには棒グラフのアイコンがあります。これは、結果を確認する第一の方法です。
二項分類の場合は、 [視覚化] アイコンをクリックすると、二項混同行列を視覚化できます。 多クラス分類の場合は、 [出力 + ログ] タブで、次のような混同行列プロット ファイルを見つけることができます。
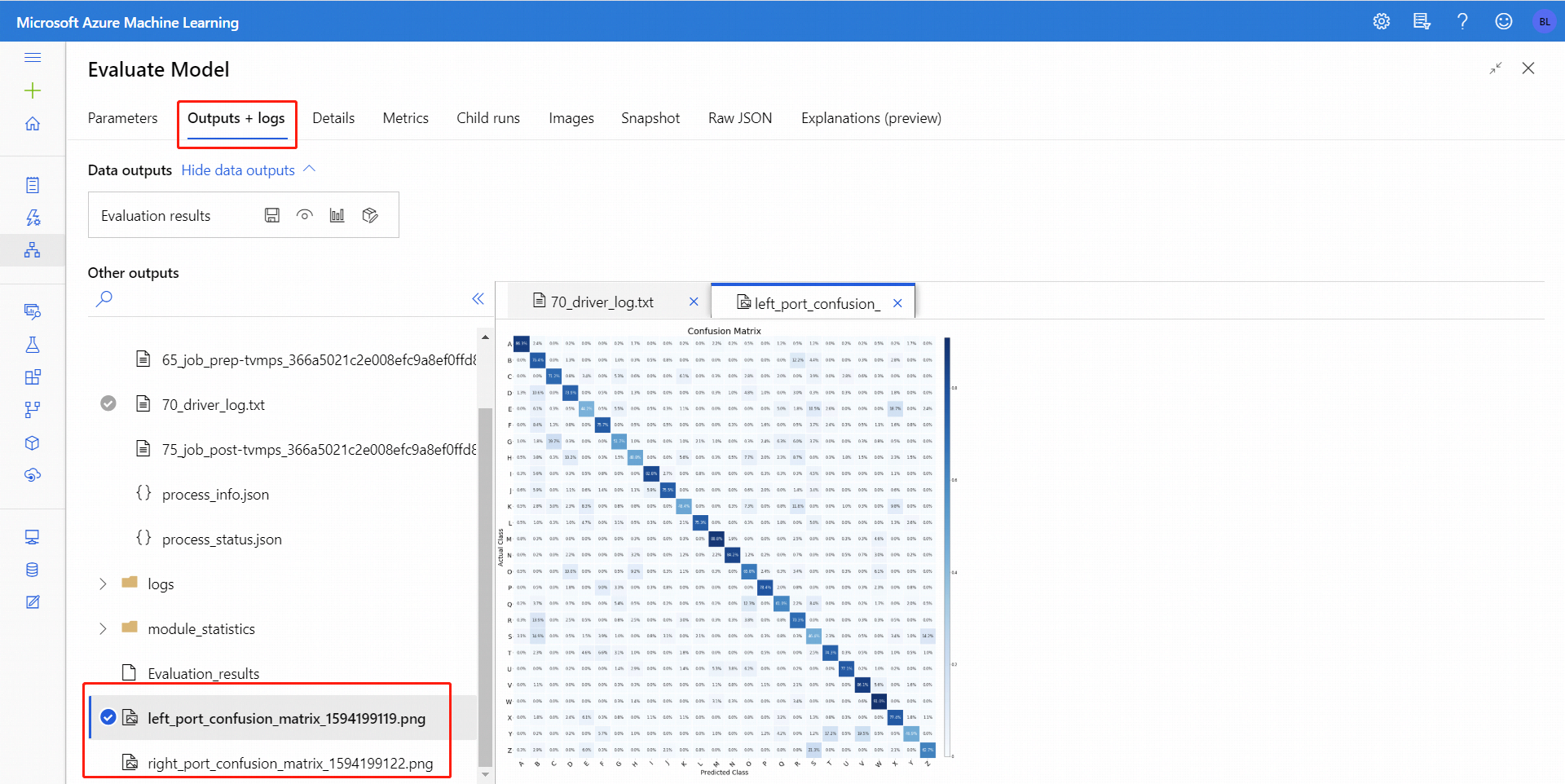
データセットを Evaluate Model (モデルの評価) の両方の入力に接続すると、結果には両方のデータのセットまたは両方のモデルのメトリックが含まれます。 左側のポートに接続されているモデルまたはデータがレポートの先頭に表示され、その後にデータセットのメトリック、または右側のポートに接続されているモデルが表示されます。
たとえば、次の図は、同じデータで異なるパラメーターを使用して構築された 2 つのクラスタリング モデルからの結果の比較を表しています。
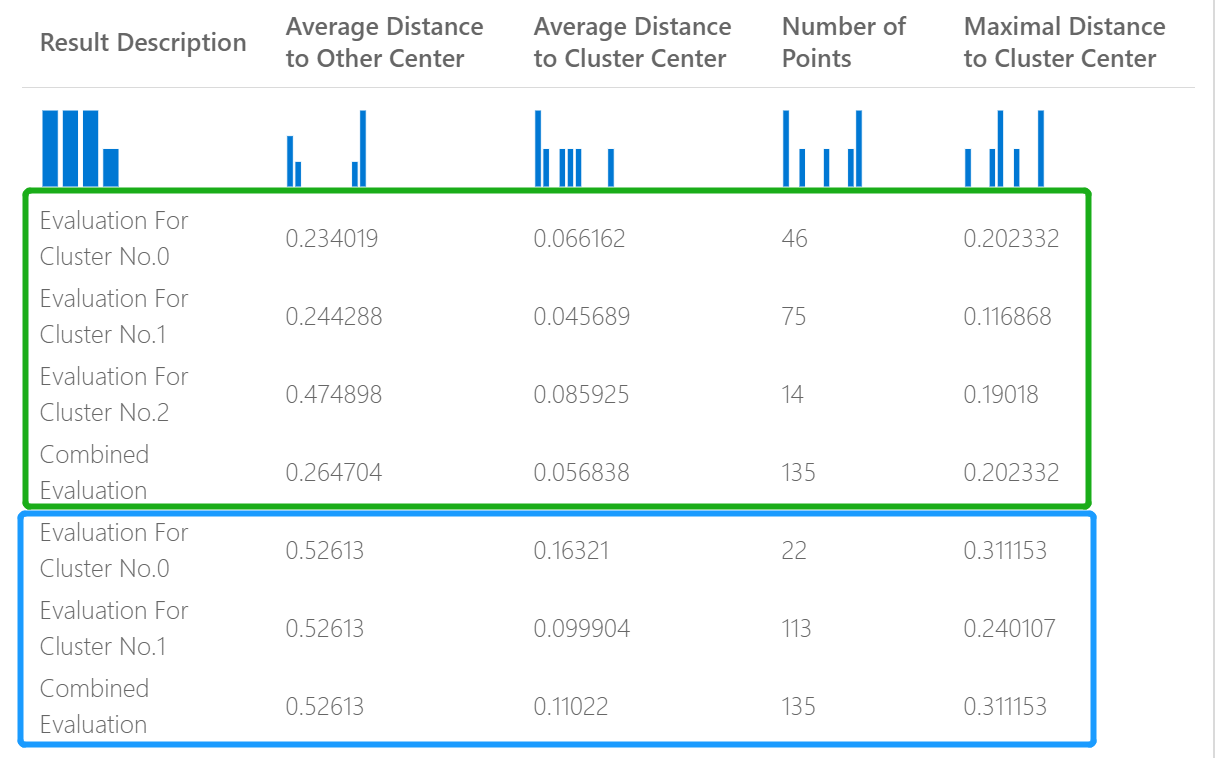
これはクラスタリング モデルであるため、評価結果は 2 つの回帰モデルからのスコアを比較した場合、または 2 つの分類モデルを比較した場合とは異なります。 ただし、全体的な表示は同じです。
メトリック
このセクションでは、Evaluate Model (モデルの評価) で使用するためにサポートされているモデルの特定の種類に対して返されるメトリックについて説明します。
分類モデルのメトリック
二項分類モデルを評価するときに、次のメトリックがレポートされます。
Accuracy (正確性) は、分類モデルの利点をケース全体に対する真の結果の割合として測定します。
Precision (精度) は、すべての肯定的な結果に対する真の結果の割合です。 精度 = TP/(TP + FP)
再現率は、実際に取得された関連するインスタンスの合計量の割合です。 再現率 = TP/(TP + FN)
F1 score (F1 スコア) は、精度と再現率の加重平均として、0 から 1 の範囲で計算されます。理想的な F1 スコアの値は 1 です。
AUC は、真陽性 を x 軸に、偽陽性を y 軸にプロットした曲線の下の領域を測定します。 このメトリックは、さまざまな種類のモデルを比較できる単一の数値を提供するのに役立ちます。 AUC は、分類しきい値のインバリアントです。 選択された分類しきい値に関係なく、これによってモデルの予測の品質が測定されます。
回帰モデルのメトリック
回帰モデルに対して返されるメトリックは、エラーの量を見積もるように設計されています。 観察された値と予測された値の差が小さい場合は、モデルがデータとうまく適合しているとみなされます。 ただし、残差のパターン (任意の 1 つの予測ポイントとそれに対応する実際の値の差) を調べることで、モデル内の潜在的なバイアスに関して多くのことがわかります。
線形回帰モデルを評価するために、次のメトリックが報告されます。 高速フォレスト分位点回帰などの他の再グレクション モデルには、異なるメトリックが含まれる場合があります。
Mean absolute error (MAE) (平均絶対誤差 (MAE)) は、予測が実際の結果とどのくらい近いかを測定します。そのため、スコアは低いほど良好です。
Root mean squared error (RMSE) (二乗平均平方根誤差 (RMSE)) は、モデル内のエラーをまとめた 1 つの値を作成します。 差を 2 乗することで、メトリックは過剰予測と過小予測との差を無視します。
Relative absolute error (RAE) (相対絶対誤差 (RAE)) は、予測した値と実際の値との相対的な絶対差です。相対なのは、平均の差が算術平均で除算されるからです。
Relative squared error (RSE) (相対二乗誤差 (RSE)) は、予測された値の二乗誤差の合計を、実際の値の二乗誤差の合計で除算することで、同様に正規化します。
Coefficient of determination (決定係数) (大抵は R2 と呼ばれます) は、モデルの予測能力を 0 から 1 の値で表します。 ゼロはモデルがランダム (何も説明しない) であることを意味し、1 は完全一致があることを意味します。 ただし、R2 値の解釈には注意が必要です。低い値はまったく正常で、高い値は疑わしい場合があります。
クラスター モデルのメトリック
クラスター モデルは、多くの点で分類モデルと回帰モデルと大きく異なるため、モデルの評価ではクラスター モデルに対して別の統計セットも返されます。
クラスター モデルに対して返される統計には、各クラスターに割り当てられたデータ ポイントの数、クラスター間の間隔、各クラスター内でのデータ ポイントの集中度合いが示されます。
クラスター モデルの統計は、クラスターごとの統計を含む追加の行と共に、データセット全体で平均化されます。
クラスター モデルを評価するために、次のメトリックが報告されます。
列 Average Distance to Other Center (その他の中心への平均距離) のスコアは、クラスター内の各ポイントが他のすべてのクラスターの重心に平均でどれだけ近いかを表します。
列 Average Distance to Cluster Center (クラスターの中心への平均距離) のスコアは、クラスター内のすべてのポイントからそのクラスターの重心までの近さを表します。
Number of Points (ポイントの数) 列には、各クラスターに割り当てられたデータ ポイントの数と、クラスター内のデータ ポイントの総数が示されます。
クラスターに割り当てられたデータ ポイントの数が、使用可能なデータ ポイントの総数よりも少ない場合は、データ ポイントがクラスターに割り当てられなかったことを意味します。
Maximal Distance to Cluster Center (クラスターの中心までの最大距離) 列のスコアは、各ポイントとそのポイントのクラスターの重心との最大距離を表します。
この数が大きい場合は、クラスターが広範囲に分散していることを意味する可能性があります。 クラスターの分散を特定するには、この統計を Average Distance to Cluster Center (クラスターの中心への平均距離) と共に確認する必要があります。
結果の各セクションの下部にある Combined Evaluation (結合した評価) スコアには、その特定のモデルで作成されたクラスターの平均スコアが一覧表示されます。
次のステップ
Azure Machine Learning で使用できる一連のコンポーネントを参照してください。