Execute Python Script コンポーネント
この記事では、Azure Machine Learning デザイナー内の Python スクリプトの実行コンポーネントについて説明します。
このコンポーネントを使用して Python コードを実行します。 Python のアーキテクチャと設計原則の詳細については、Azure Machine Learning デザイナーで Python コードを実行する方法に関するページを参照してください。
Python を使用すると、既存のコンポーネントではサポートされない次のようなタスクを実行できます。
matplotlibを使用してデータを可視化する。- Python ライブラリを使用してワークスペース内のデータセットとモデルを列挙する。
- データのインポート コンポーネントではサポートされていないソースからデータを読み取り、読み込み、操作する。
- 独自のディープ ラーニング コードを実行する。
サポートされている Python パッケージ
Azure Machine Learning で使用されている Python の Anaconda ディストリビューションには、データ処理のための一般的なユーティリティが数多く含まれています。 ここでは、Anaconda バージョンを自動的に更新します。 現行バージョンは次のとおりです。
- Python 3.6 の Anaconda 4.5 以上のディストリビューション
完全な一覧については、「プレインストールされている Python パッケージ」セクションを参照してください。
プレインストール一覧に含まれていないパッケージ (scikit-misc など) をインストールするには、スクリプトに次のコードを追加します。
import os
os.system(f"pip install scikit-misc")
特に推論の場合は、次のコードを使用してパッケージをインストールした方がパフォーマンスは高くなります。
import importlib.util
package_name = 'scikit-misc'
spec = importlib.util.find_spec(package_name)
if spec is None:
import os
os.system(f"pip install scikit-misc")
注意
プレインストール一覧に含まれていないパッケージを必要とする Python スクリプトの実行コンポーネントがパイプラインに複数含まれている場合は、それぞれのコンポーネントにそれらのパッケージをインストールしてください。
警告
Excute Python スクリプト コンポーネントでは、Java、PyODBC などの "apt-get" などのコマンドを使用して、追加のネイティブ ライブラリに依存するパッケージのインストールはサポートされていません。これは、このコンポーネントは、Python が事前にインストールされ、管理者以外のアクセス許可を持つ単純な環境で実行されるためです。
現在のワークスペースと登録済みデータセットへのアクセス
ワークスペースに登録されているデータセットにアクセスするには、次のサンプル コードを参照してください。
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from azureml.core import Run
run = Run.get_context(allow_offline=True)
#access to current workspace
ws = run.experiment.workspace
#access to registered dataset of current workspace
from azureml.core import Dataset
dataset = Dataset.get_by_name(ws, name='test-register-tabular-in-designer')
dataframe1 = dataset.to_pandas_dataframe()
# If a zip file is connected to the third input port,
# it is unzipped under "./Script Bundle". This directory is added
# to sys.path. Therefore, if your zip file contains a Python file
# mymodule.py you can import it using:
# import mymodule
# Return value must be of a sequence of pandas.DataFrame
# E.g.
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
ファイルをアップロードする
Python スクリプトの実行コンポーネントでは、Azure Machine Learning Python SDK を使用したファイルのアップロードがサポートされています。
次の例は、Python スクリプトの実行コンポーネントでイメージ ファイルをアップロードする方法を示しています。
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Imports up here can be used to
import pandas as pd
# The entry point function must have two input arguments:
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
plt.savefig(img_file)
from azureml.core import Run
run = Run.get_context(allow_offline=True)
run.upload_file(f"graphics/{img_file}", img_file)
# Return value must be of a sequence of pandas.DataFrame
# For example:
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
パイプラインの実行が終了したら、コンポーネントの右側のパネルでイメージをプレビューできます。
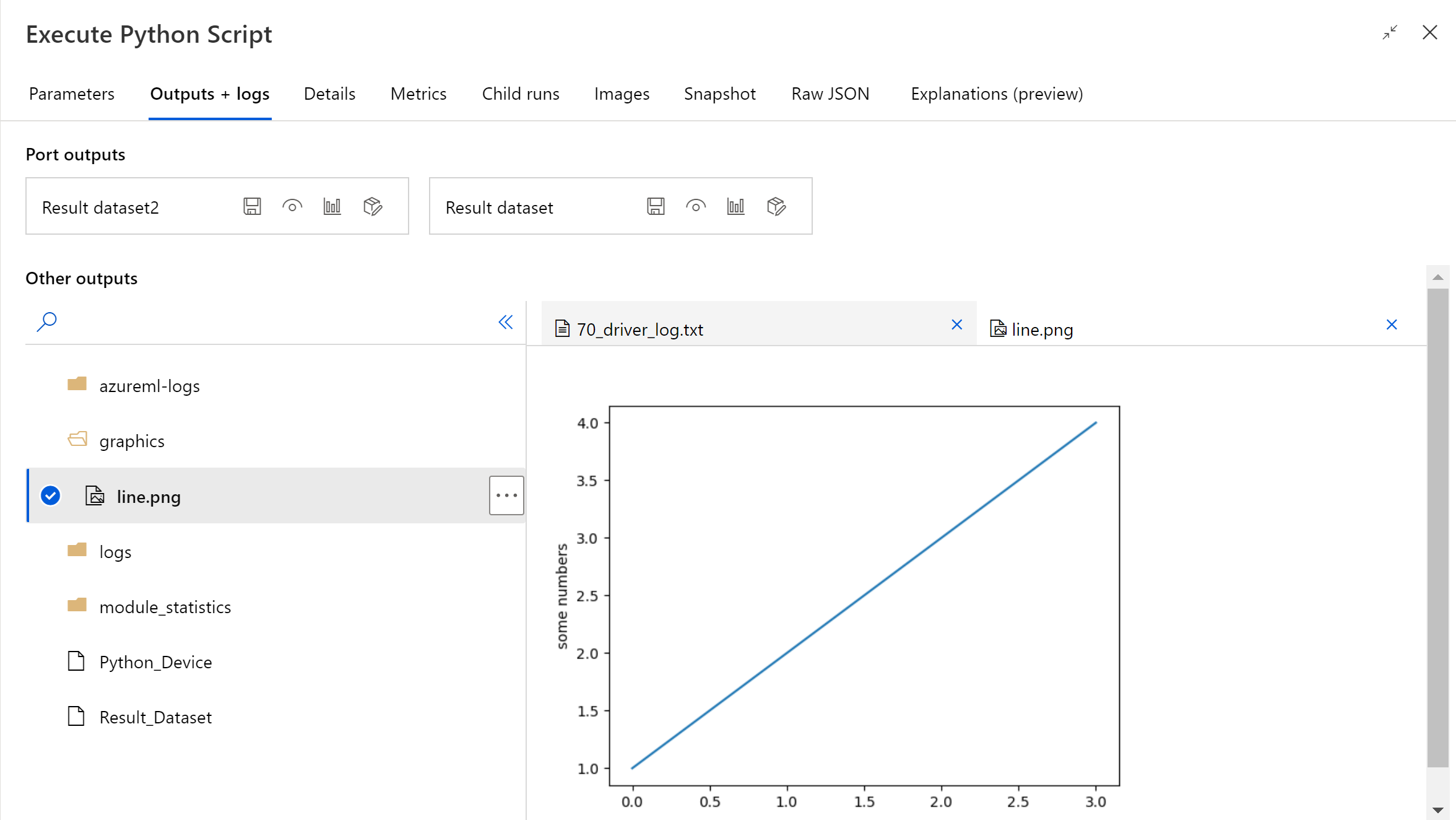
また、次のコードを使用して、任意のデータストアにファイルをアップロードすることもできます。 プレビューできるのは、ストレージ アカウント内のファイルのみです。
import pandas as pd
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be None.
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
import os
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
# Set path
path = "./img_folder"
os.mkdir(path)
plt.savefig(os.path.join(path,img_file))
# Get current workspace
from azureml.core import Run
run = Run.get_context(allow_offline=True)
ws = run.experiment.workspace
# Get a named datastore from the current workspace and upload to specified path
from azureml.core import Datastore
datastore = Datastore.get(ws, datastore_name='workspacefilestore')
datastore.upload(path)
return dataframe1,
Execute Python Script を構成する方法
Python スクリプトの実行コンポーネントには、出発点として利用できるサンプル Python コードが含まれています。 Python スクリプトの実行コンポーネントを構成するには、実行する Python コードと一連の入力を [Python スクリプト] テキスト ボックスに指定します。
Python スクリプトの実行コンポーネントをパイプラインに追加します。
デザイナーから、入力に使用するデータセットを追加して Dataset1 に接続します。 Python スクリプトでは、このデータセットを DataFrame1 として参照します。
データセットの使用は任意です。 Python を使用してデータを生成したい場合に使用します。データを直接コンポーネントにインポートしたい場合は Python コードを使用してください。
このコンポーネントは、第 2 のデータセットを Dataset2 で追加することができます。 Python スクリプトでは、第 2 のデータセットを DataFrame2 として参照します。
Azure Machine Learning に格納されたデータセットは、このコンポーネントに読み込まれた時点で自動的に pandas data.frames に変換されます。
新しい Python パッケージまたはコードをインクルードするには、それらのカスタム リソースが含まれる ZIP ファイルをスクリプト バンドル ポートに接続します。 または、スクリプトが 16 KB を超える場合は、スクリプト バンドル ポートを使用すると、CommandLine exceeds the limit of 16597 characters (CommandLine が上限の 16,597 文字を超えています) などのエラーを回避できます。
- スクリプトとその他のカスタム リソースを zip ファイルにバンドルます。
- この zip ファイルを [ファイル データセット] として Studio にアップロードします。
- [デザイナー作成] ページの左側のコンポーネント ペインにある [データセット] の一覧から、データセット コンポーネントをドラッグします。
- データセット コンポーネントを Python スクリプトの実行コンポーネントのスクリプト バンドル ポートに接続します。
アップロード済みの ZIP アーカイブに格納されていれば、どのファイルでもパイプラインの実行中に使用できます。 アーカイブにディレクトリ構造が含まれる場合、その構造が保持されます。
重要
一部の一般的な単語 (
test、appなど) は組み込みサービス用に予約されているため、スクリプト バンドル内のファイルには一意でわかりやすい名前を使用してください。Python スクリプト ファイルと txt ファイルが含まれているスクリプト バンドルの例を次に示します。
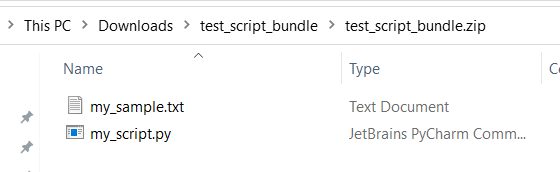
my_script.pyの内容を次に示します。def my_func(dataframe1): return dataframe1スクリプト バンドルでファイルを使用する方法を示すサンプル コードを次に示します。
import pandas as pd from my_script import my_func def azureml_main(dataframe1 = None, dataframe2 = None): # Execution logic goes here print(f'Input pandas.DataFrame #1: {dataframe1}') # Test the custom defined Python function dataframe1 = my_func(dataframe1) # Test to read custom uploaded files by relative path with open('./Script Bundle/my_sample.txt', 'r') as text_file: sample = text_file.read() return dataframe1, pd.DataFrame(columns=["Sample"], data=[[sample]])[Python スクリプト] ボックスに、有効な Python スクリプトを入力するか貼り付けます。
注意
スクリプトを記述するときは注意が必要です。 宣言されていない変数やインポートされていないコンポーネントまたは関数の使用など、構文エラーがないことを確認してください。 事前にインストールされているコンポーネントの一覧にも特別な注意を払ってください。 一覧表示されていないコンポーネントをインポートするには、対応するパッケージを次のようなスクリプトでインストールします。
import os os.system(f"pip install scikit-misc")[Python スクリプト] ボックスには、データへのアクセスと出力に使用するサンプル コードと共に、いくつかの指示がコメントとして事前に入力されています。 このコードを編集するか置き換える必要があります。 大文字と小文字の区別およびインデントに関する Python の規則に従ってください。
- スクリプトには、このコンポーネントのエントリ ポイントとして、
azureml_mainという名前の関数が含まれている必要があります。 Param<dataframe1>とParam<dataframe2>の 2 つの入力引数がスクリプトで使用されていない場合でも、エントリ ポイント関数にはこれらの引数が必要です。- 第 3 の入力ポートに接続された ZIP ファイルは解凍されて
.\Script Bundleディレクトリに格納されます。Python のsys.pathには、このディレクトリも追加されます。
ZIP ファイルに
mymodule.pyが含まれている場合は、import mymoduleを使用してインポートすることになります。デザイナーに対しては 2 つのデータセットを返すことができます。このとき、データセットは
pandas.DataFrame型のシーケンスになっている必要があります。 その他の出力は Python コードで作成し、直接 Azure Storage に書き込むことができます。警告
Python スクリプトの実行コンポーネントで、データベースまたはその他の外部ストレージに接続することはお勧めしません。 [データのインポート] コンポーネントと [データのエクスポート] コンポーネントを使用できます。
- スクリプトには、このコンポーネントのエントリ ポイントとして、
パイプラインを送信します。
このコンポーネントを完了したら、出力が想定どおりかどうかを確認します。
コンポーネントが失敗する場合は、何らかのトラブルシューティングを行う必要があります。 コンポーネントを選択し、右側のペインにある [出力とログ] を開きます。 70_driver_log.txt を開き、in azureml_main を検索すると、エラーの原因となった行を見つけることができます。 たとえば、"File "/tmp/tmp01_ID/user_script.py", line 17, in azureml_main" は、Python スクリプトの 17 行目でエラーが発生したことを示します。
結果
埋め込み Python コードによる計算の結果は pandas.DataFrame として返す必要があります。そうすることで自動的に Azure Machine Learning データセット形式に変換されます。 その結果は、パイプライン内の他のコンポーネントで使用することができます。
コンポーネントは、次の 2 つのデータセットを返します。
Results Dataset 1: Python スクリプトで最初に返される pandas データフレームによって定義されます。
Result Dataset 2: Python スクリプトで 2 番目に返される pandas データフレームによって定義されます。
プレインストールされている Python パッケージ
プレインストールされているパッケージは次のとおりです。
- adal==1.2.2
- applicationinsights==0.11.9
- attrs==19.3.0
- azure-common==1.1.25
- azure-core==1.3.0
- azure-graphrbac==0.61.1
- azure-identity==1.3.0
- azure-mgmt-authorization==0.60.0
- azure-mgmt-containerregistry==2.8.0
- azure-mgmt-keyvault==2.2.0
- azure-mgmt-resource==8.0.1
- azure-mgmt-storage==8.0.0
- azure-storage-blob==1.5.0
- azure-storage-common==1.4.2
- azureml-core==1.1.5.5
- azureml-dataprep-native==14.1.0
- azureml-dataprep==1.3.5
- azureml-defaults==1.1.5.1
- azureml-designer-classic-modules==0.0.118
- azureml-designer-core==0.0.31
- azureml-designer-internal==0.0.18
- azureml-model-management-sdk==1.0.1b6.post1
- azureml-pipeline-core==1.1.5
- azureml-telemetry==1.1.5.3
- backports.tempfile==1.0
- backports.weakref==1.0.post1
- boto3==1.12.29
- botocore==1.15.29
- cachetools==4.0.0
- certifi==2019.11.28
- cffi==1.12.3
- chardet==3.0.4
- click==7.1.1
- cloudpickle==1.3.0
- configparser==3.7.4
- contextlib2==0.6.0.post1
- cryptography==2.8
- cycler==0.10.0
- dill==0.3.1.1
- distro==1.4.0
- docker==4.2.0
- docutils==0.15.2
- dotnetcore2==2.1.13
- flask==1.0.3
- fusepy==3.0.1
- gensim==3.8.1
- google-api-core==1.16.0
- google-auth==1.12.0
- google-cloud-core==1.3.0
- google-cloud-storage==1.26.0
- google-resumable-media==0.5.0
- googleapis-common-protos==1.51.0
- gunicorn==19.9.0
- idna==2.9
- imbalanced-learn==0.4.3
- isodate==0.6.0
- itsdangerous==1.1.0
- jeepney==0.4.3
- jinja2==2.11.1
- jmespath==0.9.5
- joblib==0.14.0
- json-logging-py==0.2
- jsonpickle==1.3
- jsonschema==3.0.1
- kiwisolver==1.1.0
- liac-arff==2.4.0
- lightgbm==2.2.3
- markupsafe==1.1.1
- matplotlib==3.1.3
- more-itertools==6.0.0
- msal-extensions==0.1.3
- msal==1.1.0
- msrest==0.6.11
- msrestazure==0.6.3
- ndg-httpsclient==0.5.1
- nimbusml==1.6.1
- numpy==1.18.2
- oauthlib==3.1.0
- pandas==0.25.3
- pathspec==0.7.0
- pip==20.0.2
- portalocker==1.6.0
- protobuf==3.11.3
- pyarrow==0.16.0
- pyasn1-modules==0.2.8
- pyasn1==0.4.8
- pycparser==2.20
- pycryptodomex==3.7.3
- pyjwt==1.7.1
- pyopenssl==19.1.0
- pyparsing==2.4.6
- pyrsistent==0.16.0
- python-dateutil==2.8.1
- pytz==2019.3
- requests-oauthlib==1.3.0
- requests==2.23.0
- rsa==4.0
- ruamel.yaml==0.15.89
- s3transfer==0.3.3
- scikit-learn==0.22.2
- scipy==1.4.1
- secretstorage==3.1.2
- setuptools==46.1.1.post20200323
- six==1.14.0
- smart-open==1.10.0
- urllib3==1.25.8
- websocket-client==0.57.0
- werkzeug==0.16.1
- wheel==0.34.2
次のステップ
Azure Machine Learning で使用できる一連のコンポーネントを参照してください。