テキストからの N gram 特徴抽出コンポーネント リファレンス
この記事では Azure Machine Learning デザイナーのコンポーネントについて説明します。 テキストからの N-gram 特徴抽出コンポーネントを使って、非構造化テキスト データの "特徴を抽出" します。
テキストからの N-gram 特徴抽出コンポーネントの構成
このコンポーネントでは、N-gram 辞書を使うための次のシナリオがサポートされています。
フリー テキストの列から新しい N-gram 辞書を作成する。
既存のテキストの特徴のセットを使用して、フリー テキスト列の特徴を抽出する。
n-gram を使用するモデルのスコア付けまたはデプロイを行う。
新しい N-gram 辞書を作成する
テキストからの N-gram 特徴抽出コンポーネントをパイプラインに追加し、処理するテキストが含まれているデータセットを接続します。
テキスト列を使用して、抽出するテキストを含む string 型の列を選択します。 結果は詳細であるため、一度に処理できるのは 1 列だけです。
[Vocabulary mode]\(ボキャブラリ モード\) を [Create]\(作成\) に設定して、新しい N-gram の特徴リストを作成していることを示します。
[N-Grams size]\(N-gram のサイズ\) を設定して、抽出して格納する N-gram の最大サイズを示します。
たとえば、3 を入力すると、unigram、bigram、trigram が作成されます。
[Weighting function]\(重み付け関数\) は、ドキュメントの特徴ベクトルを作成する方法、およびドキュメントからボキャブラリを抽出する方法を指定します。
Binary Weight (バイナリ ウェイト) :抽出された N-gram にバイナリ プレゼンス値を割り当てます。 各 N-gram の値は、ドキュメントに存在する場合は 1 になり、そうでない場合は 0 になります。
TF ウェイト (TF Weight) :抽出された N-gram に、用語頻度 (TF) スコアを割り当てます。 各 N-gram の値は、ドキュメント内の出現頻度です。
IDF ウェイト (IDF Weight) :抽出された N-gram に、逆ドキュメント頻度 (IDF) スコアを割り当てます。 各 N-gram の値は、コーパス全体の出現頻度で割ったコーパス サイズのログです。
IDF = log of corpus_size / document_frequencyTF-IDF ウェイト (TF-IDF Weight) :抽出された N-gram に、用語頻度/逆ドキュメント頻度 (TF/IDF) スコアを割り当てます。 各 N-gram の値は、その TF スコアを IDF スコアで乗算したものです。
[Minimum word length]\(単語の最小長\) を、N-gram 内の任意の 1 つの単語に使用できる最小文字数に設定します。
[Maximum word length]\(単語の最大長\) を使用して、N-gram 内の任意の 1 つの単語に使用できる最大文字数を設定します。
既定では、単語またはトークンごとに最大 25 文字を使用できます。
[Minimum n-gram document absolute frequency]\(N-gram ドキュメント絶対頻度の最小値\) を使用して、N-gram が N-gram 辞書に含まれるために必要な最小出現回数を設定します。
たとえば、既定値の 5 を使用した場合、N-gram が N-gram 辞書に含まれるには、コーパスに 5 回以上出現する必要があります。
[Maximum n-gram document ratio]\(N-gram ドキュメントの最大比率\) を、コーパス全体の行数に対して特定の N-gram を含む行数の最大比率に設定します。
たとえば、比率が 1 の場合は、特定の N-gram がすべての行に存在する場合でも、その N-gram を N-gram 辞書に追加できます。 通常は、すべての行に出現する単語はノイズ ワードと見なされて削除されます。 ドメインに依存するノイズ ワードを除外するには、この比率を小さくしてみてください。
重要
特定の単語の発生率は一様ではありません。 ドキュメントごとに異なります。 たとえば、特定の製品に関する顧客のコメントを分析している場合、製品名の出現頻度は非常に高く、ノイズ ワードに近くなる可能性がありますが、他のコンテキストでは重要な用語になります。
特徴ベクトルを正規化するには、 [Normalize n-gram feature vectors]\(N-gram の特徴ベクトルの正規化\) を選択します。 このオプションが有効になっている場合、各 N-gram の特徴ベクトルは L2 ノルムで除算されます。
パイプラインを送信します。
既存の N-gram 辞書を使用する
テキストからの N-gram 特徴抽出コンポーネントをパイプラインに追加し、処理するテキストが含まれているデータセットを [データセット] ポートに接続します。
[Text column]\(テキスト列\) を使用して、特徴を抽出するテキストを含むテキスト列を選択します。 コンポーネントの既定では、string 型のすべての列が選ばれます。 最良の結果を得るためには、一度に 1 列ずつ処理します。
以前に生成した N-gram 辞書を含む保存済みデータセットを追加して、 [Input vocabulary]\(入力ボキャブラリ\) ポートに接続します。 また、テキストからの N-gram 特徴抽出コンポーネントの上流インスタンスの [Result vocabulary]\(結果のボキャブラリ\) 出力も接続できます。
[Vocabulary mode]\(ボキャブラリ モード\) に対して、ドロップダウン リストから [ReadOnly]\(読み取り専用\) 更新オプションを選択します。
[ReadOnly]\(読み取り専用\) オプションは、入力ボキャブラリの入力コーパスを表します。 新しいテキスト データセット (左側の入力) から用語の頻度を計算するのではなく、入力ボキャブラリの N-gram の重みがそのまま適用されます。
ヒント
このオプションは、テキスト分類器のスコアを付けるときに使用します。
他のすべてのオプションについては、前のセクションにあるプロパティの説明を参照してください。
パイプラインを送信します。
n-gram を使用してリアルタイム エンドポイントをデプロイする推論パイプラインを構築する
テスト データセットに対して予測を行うための [Extract N-Grams Feature From Text]\(テキストから N-Grams 特徴を抽出する\) および [モデルのスコア付け] が含まれるトレーニング パイプラインは、以下のような構造で構築されています。
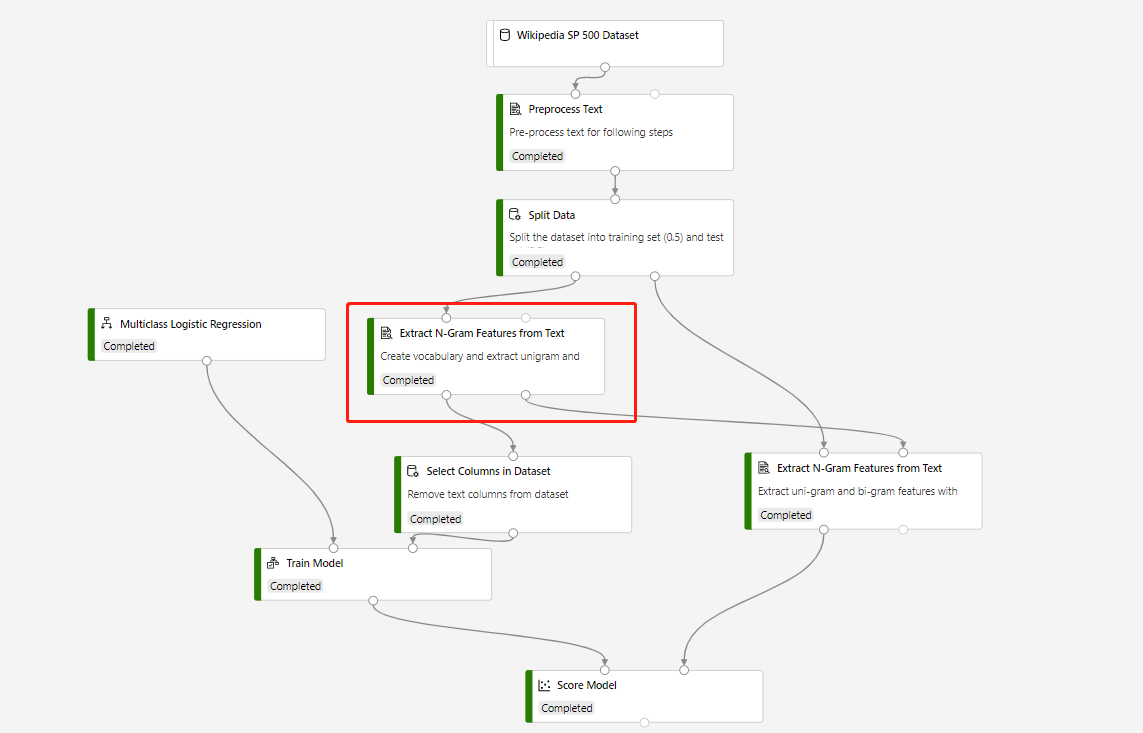
囲まれている [Extract N-Grams Feature From Text]\(テキストから N-Grams 特徴を抽出する\) コンポーネントの [Vocabulary mode]\(ボキャブラリ モード\) は [Create]\(作成\) であり、 [モデルのスコア付け] コンポーネントに接続されているコンポーネントの [Vocabulary mode]\(ボキャブラリ モード\) は [ReadOnly]\(読み取り専用\) です。
上記のトレーニング パイプラインを正常に送信した後、囲まれたコンポーネントの出力をデータセットとして登録できます。
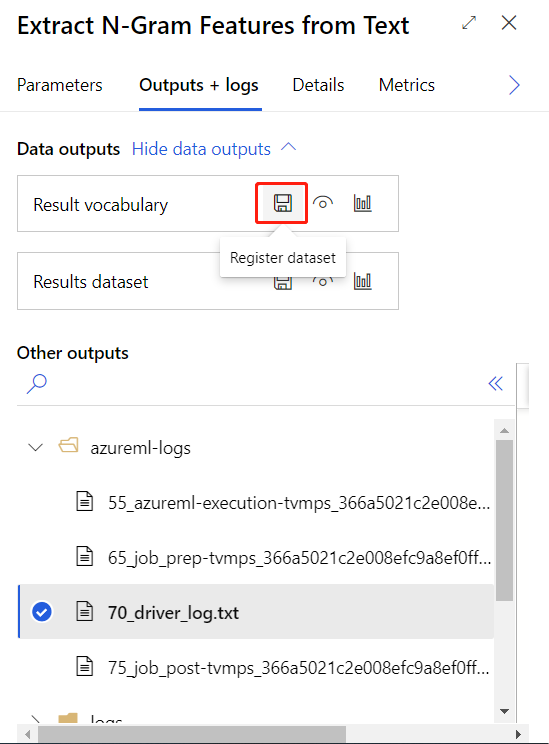
次に、リアルタイムの推論パイプラインを作成できます。 推論パイプラインを作成したら、次のように手動で推論パイプラインを調整する必要があります。
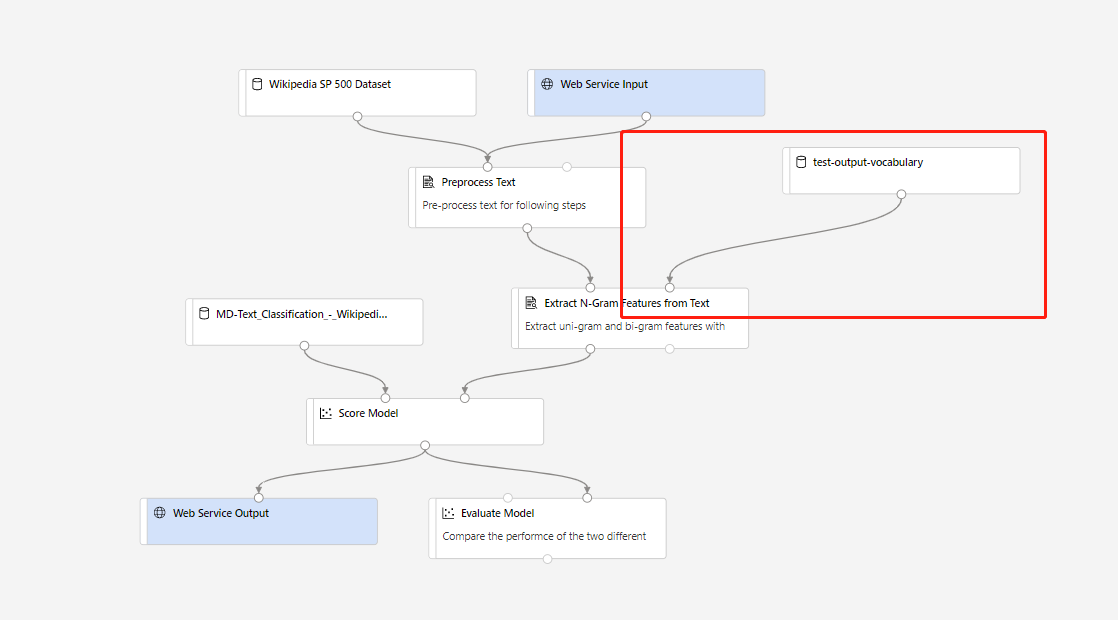
次に、推論パイプラインを送信し、リアルタイム エンドポイントをデプロイします。
結果
テキストからの N-gram 特徴抽出コンポーネントでは、次の 2 つの種類の出力が作成されます。
結果データセット: この出力は、抽出された N-gram と結合された分析済みテキストの概要です。 [Text column]\(テキスト列\) オプションで選択しなかった列は、出力にパススルーされます。 分析するテキストの列ごとに、コンポーネントによって次の列が生成されます。
- Matrix of n-gram occurrences (N-gram の出現のマトリックス) : コンポーネントは、全コーパスで見つかった N-gram ごとに列を生成し、各列にスコアを追加して、その行の N-gram の重みを示します。
Result vocabulary (結果のボキャブラリ) :ボキャブラリには、実際の N-gram 辞書と、分析の一部として生成される用語の頻度スコアが含まれています。 データセットは、別の入力セットで利用したり、後で更新したりするために保存できます。 また、モデル化とスコアリングのためにボキャブラリを再利用することもできます。
結果のボキャブラリ
ボキャブラリには、N-gram 辞書と、分析の一部として生成される用語の頻度スコアが含まれています。 DF スコアと IDF スコアは、他のオプションに関係なく生成されます。
- [ID] :一意の N-gram ごとに生成される識別子。
- NGram:N-gram。 スペースやその他の単語の区切り文字は、アンダースコア文字に置き換えられます。
- DF:元のコーパスの N-gram の用語頻度スコア。
- IDF:元のコーパスの N-gram の逆ドキュメント頻度スコア。
このデータセットは手動で更新できますが、エラーが発生する可能性があります。 次に例を示します。
- 入力ボキャブラリで同じキーを使っている重複行がコンポーネントによって検出されると、エラーが発生します。 ボキャブラリ内の 2 つの行に同じ単語が含まれていないことを確認してください。
- ボキャブラリ データセットの入力スキーマは、列名と列の型を含め、完全に一致している必要があります。
- ID 列と DF 列は、integer 型でなければなりません。
- IDF 列は、float 型でなければなりません。
注意
データ出力をモデルのトレーニング コンポーネントに直接接続しないでください。 モデルのトレーニングに取り込まれる前に、フリー テキスト列を削除する必要があります。 そうしないと、フリー テキスト列はカテゴリ別の特徴として扱われます。
次のステップ
Azure Machine Learning で使用できる一連のコンポーネントを参照してください。