データのインポート コンポーネント
この記事では Azure Machine Learning デザイナーのコンポーネントについて説明します。
このコンポーネントを使用し、既存のクラウド データ サービスのデータを機械学習パイプラインに読み込みます。
注意
このコンポーネントによって提供されるすべての機能は、ワークスペースのランディング ページのデータストアおよびデータセットによって実行されます。 データ監視などの追加機能が含まれるデータストアおよびデータセットの使用をお勧めします。 詳細については、データへのアクセス方法およびデータセットの登録方法に関する記事を参照してください。 データセットを登録すると、デザイナー インターフェイスのデータセット ->My Datasets カテゴリで確認できます。 このコンポーネントは、使い慣れたエクスペリエンスを実現するために、スタジオ (クラシック) ユーザー向けに予約されています。
データのインポート コンポーネントでは、次のソースから読み込んだデータがサポートされます。
- HTTP を使用する URL
- データストア) を使用する Azure クラウド ストレージ
- Azure BLOB コンテナー
- Azure ファイル共有
- Azure Data Lake
- Azure Data Lake Gen2
- Azure SQL データベース
- Azure PostgreSQL
クラウドストレージを使用する前に、まずは Azure Machine Learning ワークスペースにデータストアを登録する必要があります。 詳細については、データのアクセス方法に関するページを参照してください。
必要なデータを定義し、ソースに接続すると、 データのインポート では、列に含まれる値に基づいて各列のデータ型が推測され、デザイナー パイプラインにデータが読み込まれます。 データのインポートからは、あらゆるデザイナー パイプラインで使用できるデータセットが出力されます。
ソース データが変更された場合、データのインポートを再実行することでデータセットを更新し、新しいデータを追加できます。
警告
ワークスペースが仮想ネットワーク内にある場合は、デザイナーのデータ視覚化機能を使用するようにデータストアを構成する必要があります。 仮想ネットワークでデータストアとデータセットを使用する方法の詳細については、「Azure 仮想ネットワークで Azure Machine Learning Studio を使用する」を参照してください。
データのインポートを構成する方法
[データのインポート] コンポーネントをパイプラインに追加します。 このコンポーネントは、デザイナーの [データの入力と出力] カテゴリにあります。
コンポーネントを選択して、右ペインを開きます。
[データ ソース] を選択し、データ ソースの種類を選択します。 HTTP またはデータストアの場合もあります。
データストアを選択する場合、Azure Machine Learning ワークスペースに既に登録されている既存のデータストアを選択するか、新しいデータストアを作成できます。 次に、データストアにインポートするデータのパスを定義します。 パスは [パスの参照] を選択することで簡単に参照できます。
![[パスの選択] ダイアログ ボックスを開く [パスの参照] リンクを示すスクリーンショット。](media/module/import-data-path.png?view=azureml-api-2)
注意
[データのインポート] コンポーネントは、表形式データのみを対象としています。 複数の表形式データ ファイルを一度にインポートする場合は、次の条件を満たす必要があります。それ以外の場合はエラーが発生します。
- すべてのデータ ファイルをフォルダーに含めるには、 [パス] に
folder_name/**を入力する必要があります。 - すべてのデータ ファイルは、Unicode-8 でエンコードされている必要があります。
- すべてのデータ ファイルで列番号と列名が同じである必要があります。
- 複数のデータ ファイルをインポートすると、複数のファイルのすべての行が順番に連結されます。
- すべてのデータ ファイルをフォルダーに含めるには、 [パス] に
プレビュー スキーマを選択して、含める列にフィルターを適用します。 解析オプションで、区切り記号などの詳細設定を定義することもできます。
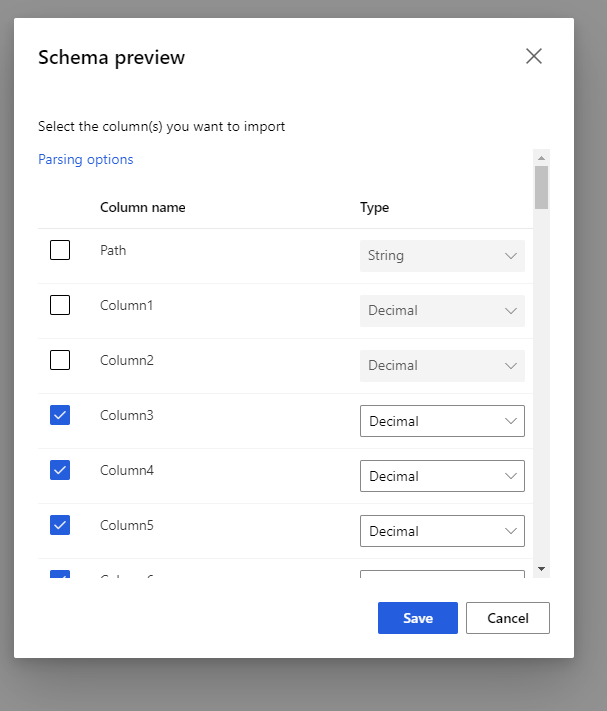
[出力の再生成] チェックボックスを使用して、実行時に出力を再生成するようにコンポーネントを実行するかどうかを決定します。
それは既定ではオフになっています。つまり、コンポーネントが前と同じパラメーターを使用して実行された場合は、実行時間を短縮するために、最後の実行からの出力が再利用されます。
オンにした場合は、コンポーネントが再び実行されて出力が再生成されます。 このため、ストレージ内の基になるデータが更新されたときにこのオプションを選択すると、最新のデータを取得するのに役立ちます。
パイプラインを送信します。
データのインポートによりデザイナーにデータが読み込まれるとき、列に含まれる値 (数値またはカテゴリ) に基づいて各列のデータ型が推測されます。
ヘッダーが存在する場合、出力されるデータセットの列に名前を付ける際、ヘッダーが使用されます。
データに既存の列ヘッダーがない場合、「col1, col2,…, coln*」の形式で新しい列に名前が付けられます。
![[パスの選択] ダイアログ ボックスを開く [パスの参照] リンクを示すスクリーンショット。](media/module/import-data-path.png?view=azureml-api-2#lightbox)
結果
インポートが完了したら、出力されたデータセットを右クリックして [Visualize](視覚化) を選択し、データが正常にインポートされたかどうかを確認します。
パイプラインを実行するたびに新しいデータセットをインポートせず、再利用のためにデータを保存する場合は、コンポーネントの右側のパネルの [出力 + ログ] タブの下にある [データセットの登録] アイコンを選択します。 データセットの名前を選択します。 保存されたデータセットでは、保存時にデータが保持されます。 データセットは、パイプラインのデータセットが変更された場合であっても、パイプラインの再実行時に更新されることはありません。 これはデータのスナップショットを作成する場合に便利です。
データのインポート後、モデル化と分析のために追加の準備が必要になることがあります。
列名を変更したり、列を別のデータ型として処理したり、一部の列がラベルまたはフィーチャーであることを指定したりするには、メタデータの編集を使用します。
変換する、またはモデル化で使用する列のサブセットを選択するには、[データセット内の列の選択] を使用します。 変換された列や削除された列は、列の追加コンポーネントを使用することで、元のデータセットに簡単に戻すことができます。
データセットを分割したり、サンプリングを実行したり、上位 n 行を取得したりするには、[パーティションとサンプル] を使用します。
制限事項
データストアのアクセス制限により、推論パイプラインにデータのインポート コンポーネントが含まれている場合、これはリアルタイム エンドポイントへのデプロイ時に自動的に削除されます。
次の手順
Azure Machine Learning で使用できる一連のコンポーネントを参照してください。