データの正規化コンポーネント
この記事では Azure Machine Learning デザイナーのコンポーネントについて説明します。
このコンポーネントを使用して、正規化によってデータセットを変換します。
正規化は、機械学習のためにデータを準備する一環として、適用されることが多い手法です。 正規化の目的は、値の範囲の差異がゆがんだり、情報を失ったりすることなく、共通スケールで使用できるように、データセット内の数値列の値を変更することです。 正規化は、一部のアルゴリズムでデータを正しくモデル化するためにも必要です。
たとえば、0 から 1 までの範囲の値を含む 1 つの列と、10,000 から 100,000 までの範囲の値を含むもう 1 つの列がある入力データセットがあるとします。 モデリング中のフィーチャーとして値を結合しようとした場合、数値のスケールにおける大きな違いによって問題が発生する場合があります。
正規化では、モデルで使用されるすべての数値列にわたって適用されるスケール内に値を保持しながら、ソース データで一般的な分布と比率を維持する新しい値を作成することで、これらの問題を回避します。
このコンポーネントでは、数値を変換するために、いくつかのオプションが提供されます。
- すべての値を 0-1 スケールに変換したり、絶対値ではなく、パーセンタイル順位として表すことで、値を変換したりすることができます。
- 1 つの列、または同じデータセット内の複数の列に正規化を適用できます。
- パイプラインを繰り返す必要があったり、同じ正規化の手順を他のデータに適用したりする場合は、正規化の変換として手順を保存し、同じスキーマを含む他のデータセットに適用することができます。
警告
一部のアルゴリズムでは、モデルをトレーニングする前に、データを正規化する必要があります。 他のアルゴリズムでは、独自のデータのスケーリングや正規化を実行します。 そのため、予測モデルのビルドで使用する機械学習アルゴリズムを選ぶ場合、トレーニング データに正規化を適用する前に、アルゴリズムのデータ要件を確認してください。
Normalize Data (データの正規化) を構成する
このコンポーネントを使用するときは、1 つの正規化メソッドのみを適用できます。 そのため、同じ正規化メソッドが、選択したすべての列に適用されます。 異なる正規化メソッドを使用するには、Normalize Data (データの正規化) の 2 つ目のインスタンスを使用します。
Normalize Data (データの正規化) コンポーネントをパイプラインに追加します。 Azure Machine Learning で、 [Data Transformation](データ変換) の下の [Scale and Reduce](拡大縮小) カテゴリでそのコンポーネントを見つけることができます。
すべての数値で少なくとも 1 列を含むデータセットに接続します。
列セレクターを使用して、正規化する数値列を選びます。 個別の列を選択しない場合、既定では、入力にあるすべての数値型の列が含まれ、同じ正規化のプロセスが選択したすべての列に適用されます。
正規化されるべきではない数値列を含める場合は、予期しない結果につながる可能性があります。 常に、慎重に列を確認してください。
数値列が検出されない場合、列のメタデータを確認して、列のデータ型がサポートされる数値型であることを確認します。
ヒント
特定の型の列が入力として確実に提供されようにするには、Normalize Data (データの正規化) の前に、Select Columns in Dataset (データセット内の列の選択) コンポーネントを使用するようにします。
[Use 0 for constant columns when checked](チェック時に定数の列に 0 を使用する): 任意の数値列に 1 つの変わらない値が含まれるときに、このオプションを選択します。 これにより、このような列は正規化の操作で使用されなくなります。
[Transformation method](変換メソッド) ドロップダウン リストから、すべての選択した列に適用する 1 つの数学関数を選びます。
[Zscore] : すべての値を Z スコアに変換します。
列の値は、次の数式を使用して変換されます。
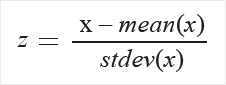
平均と標準偏差は、各列でそれぞれ計算されます。 母標準偏差が使用されます。
[MinMax] : 最小最大ノーマライザーは、すべての特徴を [0,1] 間隔に再スケーリングします。
最小値が 0 になるように、各機能の値がシフトされ、新しい最大値 (元の最大値と最小値の差) で区切られることで、[0,1] 間隔に縦横比が変更されます。
列の値は、次の数式を使用して変換されます。

Logistic: 列の値は、次の数式を使用して変換されます。

LogNormal: このオプションでは、すべての値が対数スケールに変換されます。
列の値は、次の数式を使用して変換されます。

ここでの μ と σ は、各列ごとに最大推定確率値から経験的に計算される分布のパラメーターです。
TanH: すべての値が双曲線正接に変換されます。
列の値は、次の数式を使用して変換されます。

パイプラインを送信するか、Normalize Data (データの正規化) コンポーネントをダブルクリックして [Run Selected](選択した項目を実行) を選択します。
結果
Normalize Data (データの正規化) コンポーネントでは、2 つの出力が生成されます。
変換後の値を表示するには、コンポーネントを右クリックして [可視化] を選択します。
既定では、値はその場で変換されます。 変換された値を元の値と比較する場合は、Add Columns (列の追加) コンポーネントを使用して、データセットを再結合し、列を並べて表示します。
同じ正規化メソッドを別のデータセットに適用できるように変換を保存するには、コンポーネントを選択し、右側のパネルの [出力] タブの下にある [データ セットの登録] を選択します。
ナビゲーション ウィンドウの左側の [変換] グループから保存された変換を読み込み、Apply Transformation を使用することで同じスキーマを使ってデータセットに適用することができます。
次の手順
Azure Machine Learning で使用できる一連のコンポーネントを参照してください。