Machine Learning Studio (classic) でアルゴリズムを最適化するためにパラメーターを選択する
適用対象: Machine Learning Studio (classic)
Machine Learning Studio (classic)  Azure Machine Learning
Azure Machine Learning
重要
Machine Learning Studio (クラシック) のサポートは、2024 年 8 月 31 日に終了します。 その日までに、Azure Machine Learning に切り替えすることをお勧めします。
2021 年 12 月 1 日以降、新しい Machine Learning Studio (クラシック) リソースは作成できません。 2024 年 8 月 31 日まで、既存の Machine Learning Studio (クラシック) リソースを引き続き使用できます。
- ML Studio (クラシック) から Azure Machine Learning への機械学習プロジェクトの移動に関する情報を参照してください。
- Azure Machine Learning についての詳細を参照してください
ML Studio (クラシック) のドキュメントは廃止予定であり、今後更新されない可能性があります。
このトピックでは、Machine Learning スタジオ (クラシック) でアルゴリズムに適したハイパーパラメーター セットを選択する方法について説明します。 ほとんどの機械学習アルゴリズムに、設定が必要なパラメーターがあります。 モデルをトレーニングするときは、これらのパラメーターに値を提供する必要があります。 トレーニングしたモデルの有効性は、選んだモデル パラメーターによって決まります。 パラメーターの最適なセットを見つけるプロセスのことを、モデルの選択といいます。
モデルの選択を行うにはさまざまな方法があります。 Machine Learning で最も広く使われているモデルの選択方法の 1 つはクロス検証です。これは、Machine Learning スタジオ (クラシック) の既定のモデル選択メカニズムになっています。 Machine Learning スタジオ (クラシック) では R と Python の両方がサポートされているため、R または Python を使って独自のモデル選択メカニズムをいつでも実装できます。
最適なパラメーター セットを見つけるプロセスには、次の 4 つの手順があります。
- パラメーター空間を定義する:アルゴリズムについて、検討の対象にする正確なパラメーター値をまず決めます。
- クロス検証の設定を定義する:データセットのクロス検証のフォールドを選ぶ方法を決定します。
- メトリックを定義する: その後、パラメーターの最適なセットを判別するために使うメトリックを決めます。たとえば、確度、二乗平均平方根の誤差、精度、再現率、f スコアなどがあります。
- トレーニング、評価、および比較を行う: パラメーター値の一意の組み合わせごとに、ユーザーが定義した誤差メトリックを使い、それに基づいて、クロス検証を実行します。 評価と比較が済むと、最適なモデルを選ぶことができます。
次の図は、Machine Learning スタジオ (クラシック) でこのプロセスを実施する方法を示しています。
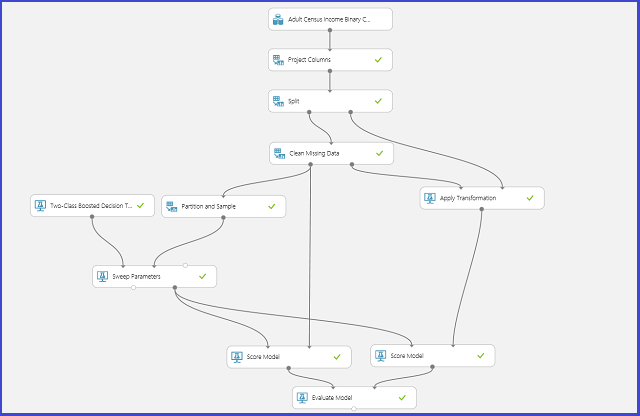
パラメーター空間を定義する
パラメーターのセットは、モデルの初期化ステップで定義できます。 すべての Machine Learning アルゴリズムのパラメーター ウィンドウには 2 つのトレーナー モードがあります。"1 つのパラメーター" と "パラメーター範囲" です。 パラメーター範囲モードを選びます。 パラメーター範囲モードでは、各パラメーターに複数の値を入力できます。 テキスト ボックスには、コンマ区切りの値を入力できます。
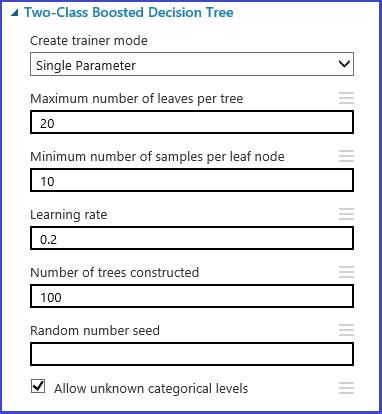
別の方法として、 [範囲ビルダーを使用] で生成されるグリッドの最大ポイントと最小ポイント、および生成するポイントの合計数を定義できます。 既定では、パラメーターの値は線形スケールで生成されます。 しかし、 [対数スケール] チェック ボックスをオンにすると、値が対数スケールで生成されます (つまり、隣接するポイントの差ではなく比率が一定になります)。 整数パラメーターの場合、ハイフンを使って範囲を定義できます。 たとえば、"1-10" は 1 から10 (1 と 10 を含む) のすべての整数によってパラメーター セットが形成されることを意味します。 混合モードもサポートされています。 たとえば、パラメーター セット "1-10, 20, 50" は、整数 1 から 10、20、および 50 を含みます。
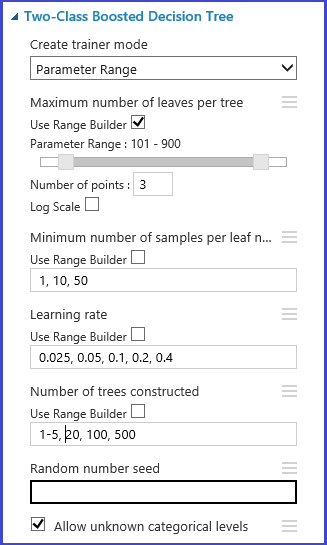
クロス検証のフォールドを定義する
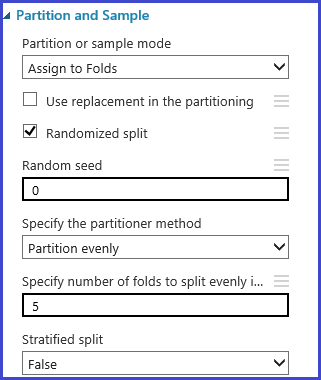
パーティションとサンプル モジュールを使用すると、データにフォールドをランダムに割り当てることができます。 次のモジュールのサンプル構成では、5 つのフォールドを定義し、サンプル インスタンスにフォールド番号をランダムに割り当てています。
メトリックを定義する
調整モデル ハイパーパラメーター モジュールは、特定のアルゴリズムとデータセットに対してパラメーターの最適なセットを経験的に選択するためのサポートを提供します。 モデルのトレーニングに関する他の情報に加えて、このモジュールの [プロパティ] ウィンドウには、最適なパラメーター セットを決定するためのメトリックが含まれています。 また、分類アルゴリズムと回帰アルゴリズムに関する 2 つの異なるドロップダウン リスト ボックスがあります。 検討しているアルゴリズムが分類アルゴリズムの場合は回帰のメトリックが無視され、その逆も同じです。 この例では、メトリックは [確度] です。
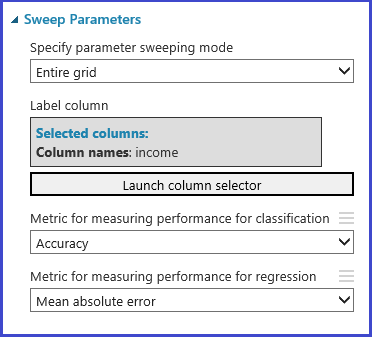
トレーニング、評価、および比較を行う
同じ調整モデル ハイパーパラメーター モジュールで、パラメーターのセットに対応するすべてのモデルをトレーニングし、さまざまなメトリックを評価した後、選ばれたメトリックに基づいて最適なトレーニング済みのモデルを作成します。 このモジュールには、次の 2 つの必須の入力があります。
- トレーニングを受けていない学習モデル
- データセット
このモジュールには、省略可能なデータセット入力もあります。 必須のデータセット入力に対してデータセットをフォールド情報と一緒に接続します。 データセットにフォールド情報を割り当てない場合は、既定で 10 フォールドのクロス検証が自動的に実行されます。 フォールドを割り当てずに、オプションのデータセット ポートに検証データセットを提供した場合は、トレーニング テスト モードが選択されます。このモードでは、最初のデータセットがパラメーターの組み合わせごとにモデルのトレーニングに使用されます。
次に検証データセットでモデルの評価が実行されます。 モジュールの左側の出力ポートは、パラメーター値の関数としての異なるメトリックを示しています。 右側の出力ポートからは、選択されたメトリック (ここでは確度) に従う最適なモデルに対応するトレーニング済みのモデルを使用できます。
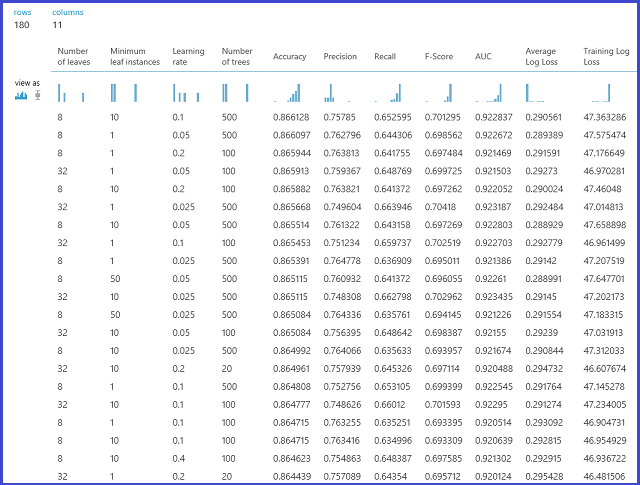
右側の出力ポートを視覚化すると、選択された正確なパラメーターを確認できます。 このモデルは、トレーニング済みのモデルとして保存した後、テスト セットのスコア付けや、運用可能な Web サービスとして使用できます。