Machine Learning Studio (クラシック) での Net# ニューラル ネットワーク仕様言語について
適用対象: Machine Learning Studio (classic)
Machine Learning Studio (classic)  Azure Machine Learning
Azure Machine Learning
重要
Machine Learning Studio (クラシック) のサポートは、2024 年 8 月 31 日に終了します。 その日までに、Azure Machine Learning に切り替えすることをお勧めします。
2021 年 12 月 1 日以降、新しい Machine Learning Studio (クラシック) リソースは作成できません。 2024 年 8 月 31 日まで、既存の Machine Learning Studio (クラシック) リソースを引き続き使用できます。
- ML Studio (クラシック) から Azure Machine Learning への機械学習プロジェクトの移動に関する情報を参照してください。
- Azure Machine Learning についての詳細を参照してください
ML Studio (クラシック) のドキュメントは廃止予定であり、今後更新されない可能性があります。
Net# は、ディープ ニューラル ネットワークや任意次元の畳み込みなどの複雑なニューラル ネットワーク アーキテクチャを定義するために使用される、Microsoft が開発した言語です。 複雑な構造体を使用して、イメージ、ビデオ、オーディオなどのデータに関する学習を強化できます。
Net# アーキテクチャ仕様は、Machine Learning スタジオ (クラシック) のすべてのニューラル ネットワーク モジュールで使用できます。
この記事では、Net# でのカスタム ニューラル ネットワーク開発に必要な基本概念と構文について説明します。
- ニューラル ネットワークの前提条件と主なコンポーネントの定義方法
- Net# 仕様言語の構文とキーワード
- Net# を使用したカスタム ニューラル ネットワークの例
ニューラル ネットワークの基本
ニューラル ネットワーク構造は、いくつかのレイヤーに編成されたノードによって構成され、各ノード間には、重みが付けられた結合 (またはエッジ) があります。 結合にはそれぞれ方向があり、結合ごとにソース ノードと宛先ノードを持ちます。
それぞれのトレーニング可能レイヤー (非表示レイヤーまたは出力レイヤー) には 1 つ以上の結合バンドルがあります。 結合バンドルは、ソース層と、そのソース層からの結合の仕様で構成されています。 特定のバンドル内では、すべての結合がソース レイヤーと宛先レイヤーを共有します。 Net# では、結合バンドルはバンドルの宛先層に属すると見なされます。
Net# では、さまざまな種類の結合バンドルがサポートされていて、入力がどのように非表示レイヤーや出力にマップされるかをカスタマイズできます。
既定つまり標準のバンドルは、フル バンドルです。このバンドルでは、ソース層の各ノードが宛先層のすべてのノードに結合します。
これに加えて、Net# は以下の 4 種類の詳細な結合バンドルをサポートします。
フィルター バンドル。 ソース レイヤー ノードと宛先レイヤー ノードの場所を使用すると、述語を定義できます。 述語が True の場合は常にノードが結合されます。
畳み込みバンドル。 ソース レイヤーには、少数の隣接ノードを定義できます。 宛先層の各ノードは、ソース層の隣接ノードの 1 つに結合します。
プーリング バンドルおよび応答正規化バンドル。 これは、ユーザーがソース層の少数の隣接ノードを定義するという点で畳み込みバンドルと似ています。 違いは、これらのバンドルのエッジの重みがトレーニング可能でないことです。 代わりに、定義済みの関数がソース ノード値に適用され、宛先ノードの値を判断します。
サポートされるカスタマイズ
Machine Learning スタジオ (クラシック) で作成するニューラル ネットワーク モデルのアーキテクチャは、Net# を使用して高度にカスタマイズできます。 次のようにすることができます。
- 隠れ層を作成し、各層のノード数を管理する。
- 層間の結合方法を指定する。
- 畳み込みや重み共有バンドルなどの特殊な結合性の構造を定義する。
- 複数のアクティブ化関数を指定する。
仕様言語の構文の詳細については、「構造の仕様」をご覧ください。
一般的な機械学習タスク用にニューラル ネットワークを定義する単純または複雑な例については、「例」をご覧ください。
一般的な要件
- 厳密に 1 つの出力層、少なくとも 1 つの入力層、およびゼロかそれ以上の隠れ層がなければなりません。
- 各層には固定された数のノードが含まれ、これらのノードは概念的には任意の次元を長方形配列に格納したものです。
- 入力層には関連付けられているトレーニング済みのパラメーターはなく、インスタンス データがネットワークに入る点を表します。
- トレーニング可能な層 (隠れ層と出力層) には、重みおよびバイアスと呼ばれるトレーニング済みパラメーターが関連付けられています。
- ソース ノードと宛先ノードは別々の層になければなりません。
- 結合は非循環でなければなりません。つまり、最初のソース ノードに戻る環状の結合が存在することはできません。
- 結合バンドルのソース層を出力層にすることはできません。
構造の仕様
ニューラル ネットワーク構造仕様は 3 つのセクションで構成されます。定数宣言、レイヤー宣言、接続宣言です。 また、オプションの共有宣言セクションもあります。 セクションは任意の順序で指定できます。
定数宣言
定数宣言は省略可能です。 これは、ニューラル ネットワーク定義内で使用する値を定義する手段を提供します。 宣言のステートメントは、識別子とそれに続く等号、および値の式で構成されています。
たとえば、次のステートメントは x 定数を定義します。
Const X = 28;
2 つ以上の定数を同時に定義するには、識別子の名前と値を中かっこで囲み、セミコロンで区切ります。 次に例を示します。
Const { X = 28; Y = 4; }
それぞれの代入式の右側には、整数、実数、ブール値 (True または False)、あるいは数式を使用することができます。 次に例を示します。
Const { X = 17 * 2; Y = true; }
層の宣言
層の宣言が必要です。 これは、サイズと、接続のバンドルと属性を含む、層のソースを定義します。 宣言ステートメントは、層の名前 (input、hidden または output) で始まり、それに層の次元 (正の整数のタプル) が続きます。 次に例を示します。
input Data auto;
hidden Hidden[5,20] from Data all;
output Result[2] from Hidden all;
- 次元を乗算すると、層内のノード数になります。 この例では、[5,20] という 2 つの次元があり、これは、層内に 100 個のノードがあることを意味します。
- 層は任意の順序で宣言することができます。ただし例外的に、2 つ以上の入力層を定義する場合は、定義の順序が入力データ内の機能の順序に一致する必要があります。
レイヤー内のノード数を自動的に決定するように指定するには、auto キーワードを使います。 auto キーワードは、以下のように、レイヤーの種類によって結果が異なります。
- 入力層の宣言では、ノード数は入力データの機能の数になります。
- 隠れ層の宣言では、ノード数は、隠れノードの数のパラメーター値で指定した数になります。
- 出力層の宣言におけるノード数は、2 クラスの分類の場合は 2、回帰の場合は 1、複数クラスの分類では出力ノードの数と同数になります。
たとえば、次のようにネットワークを定義すると、すべての層のサイズを自動的に決定できます。
input Data auto;
hidden Hidden auto from Data all;
output Result auto from Hidden all;
トレーニング可能な層 (隠れ層または出力層) の宣言では、分類モデルの場合は既定が sigmoid で、回帰モデルの場合は linear の出力関数 (アクティブ化関数とも呼ばれる) をオプションで含めることができます。 既定を使用する場合でも、わかりやすくするのであれば、アクティブ化関数を明示的に指定できます。
次の出力関数がサポートされています。
- sigmoid
- linear
- softmax
- rlinear
- square
- sqrt
- srlinear
- abs
- tanh
- brlinear
たとえば、次の宣言では、softmax 関数を使います。
output Result [100] softmax from Hidden all;
結合の宣言
トレーニング可能な層の定義が終了したら、その直後に、定義した層間の結合を宣言する必要があります。 結合バンドルの宣言は、from キーワードから始まり、次にバンドルのソース レイヤーの名前、作成する結合バンドルの種類と続きます。
現在、以下の 5 種類の結合バンドルがサポートされています。
- フル バンドル。
allキーワードで表されます - フィルター バンドル。
whereキーワードと、それに続く述語式で表されます - 畳み込みバンドル。
convolveキーワードと、それに続く畳み込み属性で表されます - プーリング バンドル。キーワード max pool または mean pool で表されます。
- 応答正規化バンドル。キーワード response norm で表されます。
フル バンドル
ソース層の各ノードから宛先層の各ノードへの結合を含む、全結合バンドルです。 これが既定のネットワーク結合のタイプです。
フィルター バンドル
フィルター処理される結合バンドル仕様には、C# lambda 式によく似た構文で表された述語が含まれています。 以下に、2 つのフィルター バンドルの定義例を示します。
input Pixels [10, 20];
hidden ByRow[10, 12] from Pixels where (s,d) => s[0] == d[0];
hidden ByCol[5, 20] from Pixels where (s,d) => abs(s[1] - d[1]) <= 1;
ByRowの述語で、sは、入力レイヤーPixelsのノードの長方形配列に対するインデックスを表すパラメーターです。また、dは、非表示レイヤーByRowのノードの配列に対するインデックスを表すパラメーターです。sとdの両方の型は、長さ 2 の整数のタプルです。 概念的に、sの範囲は0 <= s[0] < 10および0 <= s[1] < 20である整数のすべてのペア、dの範囲は0 <= d[0] < 10および0 <= d[1] < 12である整数のすべてのペアです。述語式の右側に条件があります。 この例では、
sおよびdのすべての値について条件が True であり、ソース レイヤー ノードと宛先レイヤー ノードの間にエッジが存在します。 したがって、このフィルター式は、s[0] および d[0] が等しいすべての場合において、バンドルのsで定義されたノードとdで定義されたノードの間に、結合が含まれることを示します。
フィルター処理されたバンドルにはオプションで重みのセットを指定できます。 Weights 属性の値は、長さがバンドルで定義されている結合数に一致する浮動小数点値のタプルでなければなりません。 既定では、重みは無作為に生成されます。
重みの値は、宛先ノードのインデックスでグループ化されます。 つまり、最初の宛先ノードが K 個のソース ノードに結合する場合、Weights タプルの最初の K 要素は、ソースのインデックス順で、最初の宛先ノードの重みになります。 残りの宛先ノードについても同様に適用されます。
重みは、定数値として直接指定することができます。 たとえば、以前の重みを知っている場合は、次の構文で定数値として重みを指定できます。
const Weights_1 = [0.0188045055, 0.130500451, ...]
畳み込みバンドル
トレーニング データが同質な構造を持つ場合、データの高レベル機能を学習するためには、一般に、畳み込み結合が使用されます。 たとえば、画像、音声、映像のデータでは、空間的または時間的なディメンショナリティがかなり均一です。
畳み込みバンドルでは、次元間をスライドする四角形のカーネルを採用しています。 本質的に、各カーネルは、局所的な隣接点に適用される重みのセットを定義し、これらはカーネル アプリケーションと呼ばれます。 ソース層のノードに対応するそれぞれのカーネル アプリケーションは中央ノードと呼ばれます。 カーネルの重みは多くの結合で共有されます。 畳み込みバンドルでは、各カーネルは四角形ですべてのカーネル アプリケーションは同一サイズです。
畳み込みバンドルは、以下の属性をサポートします。
InputShape は、この畳み込みバンドル用に、ソース層のディメンショナリティを定義します。 値は正の整数のタプルとする必要があります。 整数を乗算した数値はソース層内のノード数と一致している必要がありますが、それ以外はソース層で宣言されたディメンショナリティと一致する必要はありません。 このタプルの長さは、畳み込みバンドルのアリティ値になります 通常、アリティとは、関数が取ることができる引数またはオペランドの数を指します。
カーネルの形状と場所を定義するには、以下のように、属性 KernelShape、Stride、Padding、LowerPad、UpperPad を使用します。
KernelShape: (必須) 畳み込みバンドルのカーネルごとにディメンショナリティを定義します。 値は、長さ、バンドルのアリティに相当する正の整数のタプルにする必要があります。 このタプルの各要素の値は、InputShape の対応する要素の値以下とする必要があります。
Stride: (オプション) 畳み込みのスライディング ステップ サイズ (次元ごとに 1 つのステップ サイズ) を定義します。これは、中央ノード間の距離です。 値は、長さ、バンドルのアリティに相当する正の整数のタプルにする必要があります。 このタプルの各要素の値は、KernelShape の対応する要素の値以下とする必要があります。 既定値は、すべての要素が 1 に等しいタプルです。
Sharing: (オプション) 畳み込みの各次元で共有する重みを定義します。 値としては、単一のブール値、またはバンドルのアリティを長さとするブール値のタプルが可能です。 単一のブール値は、すべての要素が指定された値に等しい、正しい長さのタプルに拡張されます。 既定値は、すべての値が True であるタプルです。
MapCount: (オプション) 畳み込みバンドルの機能マップの数を定義します。 値としては、単一の正の整数、またはバンドルのアリティを長さとする正の整数のタプルが可能です。 単一の整数値は、最初の要素が指定された値に等しく、残りのすべての要素が 1 に等しい、正しい長さのタプルに拡張されます。 既定値は 1 です。 機能マップの合計数は、タプルの要素を乗算した数です。 この合計数を要素ごとに因数分解することにより、宛先ノードでの機能マップ値のグループ化の方法が決定されます。
Weights: (オプション) バンドルの最初の重みを定義します。 値は、下記の定義のように、カーネル数にカーネルあたりの重みの数を乗算した結果を長さとする、浮動小数点値のタプルです。 既定の重みは無作為に生成されます。
埋め込みを制御するプロパティ セットは 2 つあり、これらは相互に排他的です。
Padding: (オプション) 既定の埋め込みスキームを使用して入力を埋め込む必要があるかどうかを判別します。 値は、単一のブール値、またはバンドルのアリティを長さとするブール値のタプルにすることができます。
単一のブール値は、すべての要素が指定された値に等しい、正しい長さのタプルに拡張されます。
次元の値が True の場合、ソースはその次元に、ゼロ値のセルを使用して論理的に埋め込まれます。これは、その次元の最初と最後のカーネルの中央ノードがソース層のその次元の最初と最後のノードであるような、追加のカーネル アプリケーションをサポートするためです。 したがって、埋め込まれるソース レイヤーに
(InputShape[d] - 1) / Stride[d] + 1個のカーネルがちょうど収まるように、各次元の "ダミー" のノードの数が自動的に決定されます。次元の値が False の場合は、各側で残されるノードの数が等しくなるように (誤差は最大で 1)、カーネルが定義されます。 この属性の既定値は、すべての要素が False に等しいタプルです。
UpperPad および LowerPad: (オプション) 使用する埋め込みの量をさらに詳細に管理します。 重要: これらの属性は、上記の Padding プロパティが定義されていない場合にのみ定義できます。 値は、整数値のタプルで、長さがバンドルのアリティである必要があります。 これらの属性が指定されると、入力層の各次元の最上部と最下部に、"ダミー" のノードが追加されます。 次元の最上部と最下部に追加されるノードの数は、LowerPad[i] と UpperPad[i] で決定されます。
カーネルが "ダミー" ではない "実際" のノードのみに対応するようにするには、以下の条件を満たす必要があります。
LowerPad の各要素が厳密に
KernelShape[d]/2未満である。UpperPad の各要素が
KernelShape[d]/2を超過しない。これらの属性の既定値は、すべての要素が 0 に等しいタプルです。
Padding = true に設定すると、「実際」の入力内のカーネルの「中央」を維持するのに必要なだけ埋め込みを行えるようになります。 これにより、出力サイズを計算するための演算が若干変更されます。 通常、出力サイズ D は
D = (I - K) / S + 1で計算されます。ここで、Iは入力サイズ、Kはカーネル サイズ、Sは Stride、/は整数除算 (ゼロへ丸め) を示します。 UpperPad = [1, 1] に設定すると、入力サイズIは事実上 29 になるため、D = (29 - 5) / 2 + 1 = 13になります。 しかし、Padding = true に設定すると、基本的にIはK - 1によって引き上げられるため、D = ((28 + 4) - 5) / 2 + 1 = 27 / 2 + 1 = 13 + 1 = 14になります。 UpperPad と LowerPad の値を指定することで、単に Padding = true を設定したときよりも埋め込みをさらに詳細に管理できます。
畳み込みネットワークとそのアプリケーションの詳細については、以下の記事を参照してください。
- http://d2l.ai/chapter_convolutional-neural-networks/lenet.html
- https://research.microsoft.com/pubs/68920/icdar03.pdf
プーリング バンドル
プーリング バンドルは、畳み込みの結合性と同様の幾何学構造を適用しながら、ソース ノード値に事前定義された関数を使用して、宛先ノード値が派生するようにします。 このため、プーリング バンドルにはトレーニング可能な状態 (重みまたはバイアス) はありません。 プーリング バンドルは、Sharing、MapCount、Weights を除くすべての畳み込み属性をサポートします。
一般に、隣接するプーリング ユニットでまとめられたカーネルが重複することはありません。 各次元で Stride[d] が KernelShape[d] に等しい場合、取得される層は、畳み込みニューラル ネットワークで一般に採用される、従来型のローカル プーリング層です。 各宛先ノードで、ソース層のカーネルのアクティビティの最大値または平均値を計算します。
以下にプーリング バンドルの例を示します。
hidden P1 [5, 12, 12]
from C1 max pool {
InputShape = [ 5, 24, 24];
KernelShape = [ 1, 2, 2];
Stride = [ 1, 2, 2];
}
- バンドルのアリティは 3 (
InputShape、KernelShape、Strideから成るタプルの長さ) です。 - ソース レイヤーのノード数は、
5 * 24 * 24 = 2880です。 - KernelShape と Stride が等しいことから、これは従来型のローカル プーリング層です。
- 宛先レイヤーのノード数は
5 * 12 * 12 = 1440です。
プーリング層の詳細については、以下の記事を参照してください。
- https://www.cs.toronto.edu/~hinton/absps/imagenet.pdf (セクション 3.4)
- https://cs.nyu.edu/~koray/publis/lecun-iscas-10.pdf
- https://cs.nyu.edu/~koray/publis/jarrett-iccv-09.pdf
応答正規化バンドル
応答正規化は、Geoffrey Hinton らが「ImageNet Classification with Deep Convolutional Neural Networks」(ディープ畳み込みニューラル ネットワークを使用した ImageNet 分類) という論文で最初に発表した、ローカル正規化スキームです。
応答正規化は、ニューラル ネットの一般化を支援するために使用します。 あるニューロンが高度な活性レベルで発火しているときに、ローカルな応答正規化層によって周囲のニューロンの活性レベルを抑えます。 これは、α、β、k の 3 つのパラメーターと、畳み込み構造体 (または隣接する形状) で行います。 宛先層 y のすべてのニューロンは、ソース層のニューロン x に対応しています。 y のアクティブ化レベルは、次の公式で得られます。次の畳み込み構造体で定義されているように、f はニューロンのアクティブ化レベルで、Nx はカーネル (x に隣接するニューロンを含むセット) です。
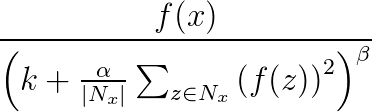
応答正規化バンドルは、Sharing、MapCount、Weights を除くすべての畳み込み属性をサポートします。
x と同じマップのニューロンがカーネルに含まれる場合、その正規化スキームを同一マップ正規化と呼びます。 同一マップ正規化を定義するには、InputShape の第 1 座標の値が 1 である必要があります。
x と同じ空間位置のニューロンがカーネルに含まれますが、そのニューロンが他のマップ内にある場合、その正規化スキームをマップ間正規化と呼びます。 このタイプの応答正規化では、側方抑制の形式が実装されます。これは、実際のニューロンで検出されたタイプから着想されたもので、異なるマップで計算されたニューロン出力間で大きな活性レベルに対する競合が発生します。 マップ間での正規化を定義するには、第 1 座標が 1 を超える整数で、マップの数以下である必要があります。残りの座標は値 1 を持つ必要があります。
応答正規化バンドルは、事前定義関数をソース ノード値に適用して宛先ノード値を決定するため、トレーニング可能状態 (重みまたはバイアス) はありません。
Note
宛先レイヤーのノードは、カーネルの中央ノードであるニューロンに対応します。 たとえば、KernelShape[d] が奇数の場合は、KernelShape[d]/2 が中央カーネル ノードに対応します。 KernelShape[d] が偶数の場合、中央ノードは KernelShape[d]/2 - 1 にあります。 このため、Padding[d] が False の場合、最初と最後の KernelShape[d]/2 のノードには、宛先レイヤー内に対応するノードがありません。 この状況を回避するために、Padding を、[true, true, …, true] に定義します。
応答正規化バンドルは、先に説明した 4 つの属性に加え、以下の属性もサポートします。
- Alpha: (必須) 前の公式の
αに対応する浮動小数点の値を指定します。 - Beta: (必須) 前の公式の
βに対応する浮動小数点の値を指定します。 - Offset: (オプション) 前の公式の
kに対応する浮動小数点の値を指定します。 既定値は 1 です。
次に、これらの属性を使用して応答正規化バンドルを定義する例を示します。
hidden RN1 [5, 10, 10]
from P1 response norm {
InputShape = [ 5, 12, 12];
KernelShape = [ 1, 3, 3];
Alpha = 0.001;
Beta = 0.75;
}
- ソース層には、5 つのマップが含まれ、12 x 12 の各次元に、合計 1,440 ノードがあります。
- KernelShape の値は、これが、3 × 3 の四角形を隣接とする、同じマップ正規化層であることを示しています。
- Padding の既定値は false のため、宛先層には次元あたり 10 ノードのみ含まれています。 ソース層のどのノードにも宛先層の 1 つのノードが対応するようにするには、Padding = [true, true, true]; を追加し、RN1 のサイズを [5, 12, 12] に変更します。
共有の宣言
Net# では、オプションで、共有の重みを持つ複数のバンドルの定義をサポートしています。 構造が同じであれば、任意の 2 つのバンドルの重みを共有することができます。 次の構文には共有の重みのバンドルを定義します。
share-declaration:
share { layer-list }
share { bundle-list }
share { bias-list }
layer-list:
layer-name , layer-name
layer-list , layer-name
bundle-list:
bundle-spec , bundle-spec
bundle-list , bundle-spec
bundle-spec:
layer-name => layer-name
bias-list:
bias-spec , bias-spec
bias-list , bias-spec
bias-spec:
1 => layer-name
layer-name:
identifier
たとえば、次の share 宣言では、層の名前を指定し、重みとバイアスの両方を共有するように指示しています。
Const {
InputSize = 37;
HiddenSize = 50;
}
input {
Data1 [InputSize];
Data2 [InputSize];
}
hidden {
H1 [HiddenSize] from Data1 all;
H2 [HiddenSize] from Data2 all;
}
output Result [2] {
from H1 all;
from H2 all;
}
share { H1, H2 } // share both weights and biases
- 入力機能は、2 つの同じサイズの入力層に分割されます。
- 次に、隠れ層が 2 つの入力層の高い方のレベルの機能を計算します。
- 共有宣言では、H1 と H2 をそれぞれの入力から同じ方法で計算するように指定します。
または、次のように、これを 2 つの個別の共有宣言で指定することもできます。
share { Data1 => H1, Data2 => H2 } // share weights
<!-- -->
share { 1 => H1, 1 => H2 } // share biases
この簡易方法は、層に単一バンドルが含まれている場合のみ使用できます。 一般に、共有が可能なのは、該当する構造が同一の場合に限られます。つまり、サイズ、畳み込みの構造などが同一である場合です。
Net# の使用例
このセクションでは、隠れ層の追加、隠れ層の他の層との対話方法の定義、および畳み込みネットワークの構築のための Net# の使用方法の例を示します。
シンプルなカスタム ニューラル ネットワークの定義:"Hello World" の例
単一の隠れ層を持つニューラル ネットワーク モデルの作成方法をこのシンプルな例で示します。
input Data auto;
hidden H [200] from Data all;
output Out [10] sigmoid from H all;
例では、次のようにいくつかの基本的なコマンドを示しています。
- 最初の行により入力レイヤーが定義されます (
Dataという名前)。autoキーワードを使用すると、ニューラル ネットワークに入力例のすべての機能列が自動的に追加されます。 - 2 行目で隠れ層が作成されます。 200 個のノードを持つこの非表示レイヤーに
Hという名前が割り当てられます。 この層は入力層に完全結合されます。 - 3 行目は、出力レイヤーを定義します。このレイヤーは
Outという名前で、10 個の出力ノードが含まれています。 ニューラル ネットワークが分類に使用される場合、クラスあたり 1 つの出力ノードがあります。 キーワード sigmoid は、出力層に適用される出力関数を示します。
複数の隠れ層の定義: コンピューター ビジョンの例
次に、複数のカスタム隠れ層を持つ、もう少し複雑なニューラル ネットワークを定義する例を示します。
// Define the input layers
input Pixels [10, 20];
input MetaData [7];
// Define the first two hidden layers, using data only from the Pixels input
hidden ByRow [10, 12] from Pixels where (s,d) => s[0] == d[0];
hidden ByCol [5, 20] from Pixels where (s,d) => abs(s[1] - d[1]) <= 1;
// Define the third hidden layer, which uses as source the hidden layers ByRow and ByCol
hidden Gather [100]
{
from ByRow all;
from ByCol all;
}
// Define the output layer and its sources
output Result [10]
{
from Gather all;
from MetaData all;
}
このサンプルでは、以下のニューラル ネットワーク仕様言語の複数の機能を示しています。
- 構造には、
PixelsとMetaDataという 2 つの入力レイヤーがあります。 Pixelsレイヤーは、宛先レイヤーByRowおよびByColを持つ、2 つの結合バンドルに対するソース レイヤーです。GatherレイヤーとResultレイヤーは、複数の接続バンドルにある宛先レイヤーです。- 出力レイヤー
Resultは、2 つの結合バンドルにある宛先レイヤーです。1 つは宛先レイヤーとして 2 番目の非表示レイヤーGatherを持ち、もう 1 つは宛先レイヤーとして入力レイヤーMetaDataを持ちます。 - 非表示レイヤー
ByRowとByColは、フィルター処理される結合性を述語式で指定します。 より正確には、[x, y] にあるByRowのノードが、ノードの最初の座標 x と等しい最初のインデックス座標を持つPixelsのノードに結合されます。 同様に、[x, y] にあるByColのノードが、ノードの 2 番目の座標 y のいずれかの内部に 2 番目のインデックス座標を持つPixelsのノードに結合されます。
複数クラス分類の畳み込みネットワークの定義: 数字認識の例
次のネットワークの定義は数字を認識するように設計され、ニューラル ネットワークの高度なカスタマイズ技法を表しています。
input Image [29, 29];
hidden Conv1 [5, 13, 13] from Image convolve
{
InputShape = [29, 29];
KernelShape = [ 5, 5];
Stride = [ 2, 2];
MapCount = 5;
}
hidden Conv2 [50, 5, 5]
from Conv1 convolve
{
InputShape = [ 5, 13, 13];
KernelShape = [ 1, 5, 5];
Stride = [ 1, 2, 2];
Sharing = [false, true, true];
MapCount = 10;
}
hidden Hid3 [100] from Conv2 all;
output Digit [10] from Hid3 all;
構造には単一の入力レイヤー
Imageがあります。convolveキーワードは、Conv1という名前のレイヤーとConv2という名前のレイヤーが畳み込みレイヤーであることを示しています。 これらの各層の宣言には、畳み込み属性の一覧が続きます。このネットワークには第 3 の非表示レイヤー
Hid3があり、これは第 2 の非表示レイヤーConv2に完全結合されます。出力レイヤー
Digitは、第 3 の非表示レイヤーHid3のみに結合されます。allキーワードは、出力レイヤーがHid3に完全結合されることを示しています。畳み込みのアリティは 3 (
InputShape、KernelShape、Stride、Sharingから成るタプルの長さ) です。カーネルごとの重みの数は
1 + KernelShape\[0] * KernelShape\[1] * KernelShape\[2] = 1 + 1 * 5 * 5 = 26です。 または、26 * 50 = 1300です。それぞれの隠れ層のノードは、次のように計算できます。
NodeCount\[0] = (5 - 1) / 1 + 1 = 5NodeCount\[1] = (13 - 5) / 2 + 1 = 5NodeCount\[2] = (13 - 5) / 2 + 1 = 5ノードの合計数は、レイヤーの宣言済みディメンショナリティ [50, 5, 5] を使用して、次のように計算できます:
MapCount * NodeCount\[0] * NodeCount\[1] * NodeCount\[2] = 10 * 5 * 5 * 5Sharing[d]は、d == 0の場合にのみ False であるため、カーネルの数はMapCount * NodeCount\[0] = 10 * 5 = 50です。
謝辞
ニューラル ネットワークのアーキテクチャをカスタマイズするための Net# 言語は Microsoft の Shon Katzenberger (設計者、Machine Learning) と Alexey Kamenev (ソフトウェア エンジニア、Microsoft Research) により開発されました。 機械学習と、画像検出からテキスト分析までの用途に社内利用されています。 詳細については、Machine Learning スタジオでのニューラル ネットの Net# の概要に関するページを参照してください