Computer Vision モデルをトレーニングするために AutoML を設定する
適用対象: Azure CLI ml extension v2 (現行)Python SDK azure-ai-ml v2 (現行)
Azure CLI ml extension v2 (現行)Python SDK azure-ai-ml v2 (現行)
この記事では、自動 ML を使用して、画像データで Computer Vision モデルをトレーニングする方法を説明します。 モデルのトレーニングには、Azure Machine Learning CLI 拡張機能 v2 または Azure Machine Learning Python SDK v2 を使用してトレーニングできます。
自動 ML では、画像分類、物体検出、インスタンス セグメント化などの Computer Vision タスク用のモデル トレーニングがサポートされています。 現在、Computer Vision タスク用の AutoML モデルの作成は、Azure Machine Learning Python SDK を介してサポートされています。 結果として得られる実験の試行、モデル、出力には、Azure Machine Learning スタジオ UI からアクセスできます。 画像データに対する Computer Vision タスク用の自動 ML の詳細を確認します。
前提条件
適用対象: Azure CLI ML 拡張機能 v2 (現行)
- Azure Machine Learning ワークスペース。 ワークスペースを作成するには、「ワークスペース リソースの作成」を参照してください。
- CLI (v2) をインストールして設定します。必ず、
ml拡張機能をインストールしてください。
タスクの種類の選択
画像の自動 ML では、次のタスクの種類がサポートされています。
| タスクの種類 | AutoML ジョブの構文 |
|---|---|
| 画像の分類 | CLI v2: image_classification SDK v2: image_classification() |
| 画像分類の複数ラベル | CLI v2: image_classification_multilabel SDK v2: image_classification_multilabel() |
| 画像の物体検出 | CLI v2: image_object_detection SDK v2: image_object_detection() |
| 画像インスタンスのセグメント化 | CLI v2: image_instance_segmentation SDK v2: image_instance_segmentation() |
適用対象: Azure CLI ML 拡張機能 v2 (現行)
このタスクの種類は必須のパラメーターであり、task キーを使用して設定できます。
例:
task: image_object_detection
データをトレーニングして検証する
Computer Vision モデルを生成するには、ラベル付き画像データを MLTable の形式でモデル トレーニングの入力として取り込む必要があります。 MLTable は JSONL 形式のトレーニング データから作成できます。
トレーニング データの形式が異なる (pascal VOC や COCO など) 場合は、サンプル ノートブックに含まれるヘルパー スクリプトを適用して、データを JSONL に変換できます。 自動 ML で Computer Vision タスク用にデータを準備する方法の詳細を確認してください。
注意
AutoML ジョブを送信できるようにするには、トレーニング データに少なくとも 10 個の画像が含まれている必要があります。
警告
JSONL 形式のデータからの MLTable の作成は、この機能用の SDK と CLI を使用した場合にのみサポートされます。 現時点では、UI による MLTable の作成はサポートされていません。
JSONL スキーマのサンプル
TabularDataset の構造は、手元のタスクによって異なります。 Computer Vision タスクの種類の場合、次のフィールドで構成されます。
| フィールド | 説明 |
|---|---|
image_url |
StreamInfo オブジェクトとしてファイルパスが含まれます |
image_details |
画像メタデータ情報は、高さ、幅、および形式で構成されます。 このフィールドは省略可能であるため、存在する場合と存在しない場合があります。 |
label |
タスクの種類に基づく画像ラベルの JSON 表現。 |
画像分類のサンプル JSONL ファイルを次に示します:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
次のコードは、物体検出のサンプル JSONL ファイルです。
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
データの使用
データが JSONL 形式になったら、下に示すようにトレーニングと検証の MLTable を作成できます。
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
自動 ML では、Computer Vision タスク用のトレーニングまたは検証データのサイズに制約はありません。 データセットの最大サイズは、データセットの背後にあるストレージ レイヤー (例: BLOB ストア) によってのみ制限されます。 画像またはラベルの最小数はありません。 ただし、出力モデルが十分にトレーニングされるように、ラベルあたり少なくとも 10 から 15 のサンプルから開始することをお勧めします。 ラベルやクラスの合計数が多いほど、ラベルごとに必要なサンプルが多くなります。
適用対象: Azure CLI ML 拡張機能 v2 (現行)
トレーニング データは必須のパラメーターであり、training_data キーを使って渡します。 必要に応じて、validation_data キーを使用して検証データとして別の MLtable を指定できます。 検証データを指定しない場合、別の値で validation_data_size 引数を渡さない限り、既定ではトレーニング データの 20% が検証に使用されます。
ターゲット列名は必須パラメーターであり、教師あり ML タスクのターゲットとして使用されます。 target_column_name キーを使って渡されます。 次のような例があります。
target_column_name: label
training_data:
path: data/training-mltable-folder
type: mltable
validation_data:
path: data/validation-mltable-folder
type: mltable
実験を実行するために計算する
モデル トレーニングを実施する自動 ML のコンピューティング ターゲットを指定します。 Computer Vision タスク用の自動 ML モデルでは、GPU SKU が必要であり、NC ファミリと ND ファミリがサポートされています。 トレーニングを高速化するには NCsv3 シリーズ (v100 GPU 搭載) が推奨されます。 マルチ GPU VM SKU を使用するコンピューティング ターゲットで、複数の GPU を利用することでもトレーニングが高速化されます。 さらに、複数のノードでコンピューティング ターゲットを設定する場合に、モデルのハイパーパラメーターを調整するときに、並列処理を使用してモデルのトレーニングを高速化できます。
注意
コンピューティング先としてコンピューティング インスタンスを使っている場合は、複数の AutoML ジョブが同時に実行されていないことを確認してください。 また、ジョブの制限で max_concurrent_trials が 1 に設定されていることを確認してください。
コンピューティング ターゲットは compute パラメーターを使用して渡されます。 次に例を示します。
適用対象: Azure CLI ML 拡張機能 v2 (現行)
compute: azureml:gpu-cluster
実験を構成する
Computer Vision タスクの場合、個々の試行、手動スイープまたは自動スイープのいずれかを起動できます。 最初のベースライン モデルを取得するには、最初に自動スイープを実施することをお勧めします。 その後、特定のモデルとハイパーパラメーター構成で個々の試行を試すことができます。 最後に、手動スイープを使用すると、より有望なモデルとハイパーパラメーター構成に近い複数のハイパーパラメーター値を試すことができます。 この 3 つのステップ ワークフロー (自動スイープ、個々の試行、手動スイープ) により、ハイパーパラメーターの数が指数関数的に増加するハイパーパラメーター空間全体の検索を回避できます。
自動スイープを使用すると、多くのデータセットで競争力のある結果が得られます。 また、モデル アーキテクチャに関する高度な知識は必要ありません。ハイパーパラメーターの相関関係を考慮し、異なるハードウェア セットアップ間でシームレスに動作します。 これらすべての理由により、実験プロセスの初期段階で強力なオプションになります。
主要メトリック
AutoML トレーニング ジョブは、モデルの最適化とハイパーパラメーターのチューニングにプライマリ メトリックを使用します。 プライマリ メトリックは、次に示すようにタスクの種類によって異なります。その他のプライマリ メトリック値は現在サポートされません。
ジョブの制限
次の例で説明するように、制限の設定でジョブの timeout_minutes、max_trials、max_concurrent_trials を指定することにより、AutoML の画像トレーニング ジョブに使われるリソースを制御できます。
| パラメーター | 詳細 |
|---|---|
max_trials |
スイープする試行の最大数のパラメーター。 1 ~ 1000 の整数にする必要があります。 特定のモデル アーキテクチャで既定のハイパーパラメーターだけを探索する場合は、このパラメーターを 1 に設定します。 既定値は 1 です。 |
max_concurrent_trials |
同時に実行できる試行の最大数。 指定する場合は、1 ~ 100 の整数にする必要があります。 既定値は 1 です。 注: max_concurrent_trials は内部的に max_trials に制限されます。 たとえば、ユーザーが max_concurrent_trials=4、max_trials=2 を設定した場合、値は内部的に max_concurrent_trials=2、max_trials=2 に更新されます。 |
timeout_minutes |
実験が終了するまでの時間 (分単位)。 何も指定しない場合、既定の実験の timeout_minutes は 7 日です (最大 60 日) |
適用対象: Azure CLI ML 拡張機能 v2 (現行)
limits:
timeout_minutes: 60
max_trials: 10
max_concurrent_trials: 2
モデルのハイパーパラメーターの自動スイープ (AutoMode)
重要
現在、この機能はパブリック プレビュー段階にあります。 このプレビュー バージョンは、サービス レベル アグリーメントなしに提供されます。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
データセットに最適なモデル アーキテクチャとハイパーパラメーターを予測するのは困難です。 また、場合によっては、ハイパーパラメーターのチューニングに割り当てられる要員の作業時間が制限される場合があります。 コンピュータビジョン タスクの場合、試行回数を指定すると、スイープするハイパーパラメーター空間の領域がシステムによって自動的に決定されます。 ハイパーパラメーター検索スペース、サンプリング方法、早期終了ポリシーを定義する必要はありません。
AutoMode のトリガー
limits で max_trials を 1 より大きい値に設定し、検索スペース、サンプリング方法、終了ポリシーを指定しないことで、自動スイープを実行できます。 この機能を AutoMode と呼びます。次の例を参照してください。
適用対象: Azure CLI ML 拡張機能 v2 (現行)
limits:
max_trials: 10
max_concurrent_trials: 2
多くのデータセットでは、10 回から 20 回の間の試行回数が適している可能性があります。 AutoML ジョブの時間予算は引き続き設定できますが、これは実行に長い時間がかかる場合にのみ設定することをお勧めします。
警告
現在、UI を介した自動スイープの起動はサポートされません。
個々の試行
個々の試行では、モデル アーキテクチャとハイパーパラメーターを直接制御します。 モデル アーキテクチャは model_name パラメーター経由で渡されます。
サポートされているモデル アーキテクチャ
次の表は、各 Computer Vision タスクでサポートされているレガシ モデルをまとめたものです。 これらのレガシ モデルのみを使用すると、レガシ ランタイムを使用して実行がトリガーされます (個々の実行または試用がコマンド ジョブとして送信されます)。 HuggingFace と MMDetection のサポートについては以下を参照してください。
| タスク | モデル アーキテクチャ | 文字列リテラル構文default_model* を * で示す |
|---|---|---|
| 画像の分類 (複数クラスおよび複数ラベル) |
MobileNet: モバイル アプリケーション用の軽量モデル ResNet: 残差ネットワーク ResNeSt: スプリット アテンション ネットワーク SE-ResNeXt50: スクイーズおよび励起ネットワーク ViT: Vision Transformer ネットワーク |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (小) vitb16r224* (基本) vitl16r224 (大) |
| オブジェクトの検出 | YOLOv5: 1 ステージ オブジェクト検出モデル Faster RCNN ResNet FPN: 2 ステージ オブジェクト検出モデル RetinaNet ResNet FPN: Focal Loss によってクラスの不均衡に対処する 注: YOLOv5 モデルのサイズについては、 model_sizeハイパーパラメーターを参照してください。 |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| インスタンスのセグメント化 | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn |
サポートされているモデル アーキテクチャ - HuggingFace と MMDetection (プレビュー)
Azure Machine Learning パイプラインで実行される新しいバックエンドにより、トランスフォーマー ライブラリ (microsoft/beit-base-patch16-224 など) の一部である HuggingFace Hub の画像分類モデルや、MMDetection バージョン 3.1.0 モデル Zoo (atss_r50_fpn_1x_coco など) の物体検出またはインスタンス セグメント化モデルを追加で使用できます。
HuggingFace Transfomers と MMDetection 3.1.0 のモデルのサポートに加えて、これらのライブラリのキュレーションされたモデルの一覧も azureml レジストリで提供されています。 これらのキュレート済みモデルは徹底的にテストされており、トレーニングを効果的にするため、広範なベンチマークから選択された既定のハイパーパラメーターが使用されます。 そのキュレート済みモデルをまとめたものが次の表です。
| タスク | モデル アーキテクチャ | 文字列リテラル構文 |
|---|---|---|
| 画像の分類 (複数クラスおよび複数ラベル) |
BEiT ViT DeiT SwinV2 |
microsoft/beit-base-patch16-224-pt22k-ft22kgoogle/vit-base-patch16-224facebook/deit-base-patch16-224microsoft/swinv2-base-patch4-window12-192-22k |
| オブジェクトの検出 | Sparse R-CNN Deformable DETR VFNet YOLOF Swin |
mmd-3x-sparse-rcnn_r50_fpn_300-proposals_crop-ms-480-800-3x_cocommd-3x-sparse-rcnn_r101_fpn_300-proposals_crop-ms-480-800-3x_coco mmd-3x-deformable-detr_refine_twostage_r50_16xb2-50e_coco mmd-3x-vfnet_r50-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-vfnet_x101-64x4d-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-yolof_r50_c5_8x8_1x_coco |
| インスタンス セグメント化 | Swin | mmd-3x-mask-rcnn_swin-t-p4-w7_fpn_1x_coco |
キュレート済みモデルの一覧はたびたび更新しています。 Python SDK を使用し、特定のタスクのキュレート済みモデルの最新一覧を取得できます。
credential = DefaultAzureCredential()
ml_client = MLClient(credential, registry_name="azureml")
models = ml_client.models.list()
classification_models = []
for model in models:
model = ml_client.models.get(model.name, label="latest")
if model.tags['task'] == 'image-classification': # choose an image task
classification_models.append(model.name)
classification_models
出力:
['google-vit-base-patch16-224',
'microsoft-swinv2-base-patch4-window12-192-22k',
'facebook-deit-base-patch16-224',
'microsoft-beit-base-patch16-224-pt22k-ft22k']
HuggingFace または MMDetection モデルを使用すると、パイプライン コンポーネントを使用して実行がトリガーされます。 レガシ モデルと HuggingFace/MMdetection モデルの両方を使用すると、すべての実行/試験がコンポーネントを使用してトリガーされます。
モデル アーキテクチャの制御に加えて、モデルのトレーニングに使用されるハイパーパラメーターも調整できます。 公開されているハイパーパラメーターの多くはモデルに依存しませんが、ハイパーパラメーターがタスク固有またはモデル固有である場合があります。 これらのインスタンスで使用できるハイパーパラメーターの詳細について確認してください。
適用対象: Azure CLI ML 拡張機能 v2 (現行)
特定のアーキテクチャ (yolov5 など) で既定のハイパーパラメーター値を使用する場合は、training_parameters セクションの model_name キーを使って指定できます。 次のような例があります。
training_parameters:
model_name: yolov5
モデル ハイパーパラメーターの手動スイープ
Computer Vision モデルをトレーニングする際のモデルのパフォーマンスは、選択したハイパーパラメーターの値に大きく依存します。 最適なパフォーマンスを得るために、ハイパーパラメーターを調整する必要がある場合がよくあります。 Computer Vision タスクの場合、ハイパーパラメーターをスイープして、モデルに最適な設定を見つけることができます。 この機能は、Azure Machine Learning のハイパーパラメーター調整機能に該当します。 ハイパーパラメーターを調整する方法を確認してください。
適用対象: Azure CLI ML 拡張機能 v2 (現行)
search_space:
- model_name:
type: choice
values: [yolov5]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.01
model_size:
type: choice
values: [small, medium]
- model_name:
type: choice
values: [fasterrcnn_resnet50_fpn]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.001
optimizer:
type: choice
values: [sgd, adam, adamw]
min_size:
type: choice
values: [600, 800]
パラメーター検索空間を定義する
パラメーター空間でスイープするモデル アーキテクチャとハイパーパラメーターを定義できます。 1 つまたは複数のモデル アーキテクチャを指定できます。
- タスクの種類ごとにサポートされるモデル アーキテクチャのリストについては、「個々の試行」を参照してください。
- 各コンピューター ビジョン タスクの種類のハイパーパラメーターについては、コンピューター ビジョン タスク用のハイパーパラメーターに関する記事を参照してください。
- 不連続および連続のハイパーパラメーターでサポートされているディストリビューションの詳細を参照してください。
スイープのサンプリング方法
ハイパーパラメーターをスイープする場合は、定義されたパラメーター空間のスイープに使用するサンプリング方法を指定する必要があります。 現在のところ、sampling_algorithm パラメーターで次のサンプリング方法がサポートされています。
| サンプリングの種類 | AutoML ジョブの構文 |
|---|---|
| ランダム サンプリング | random |
| グリッド サンプリング | grid |
| ベイジアン サンプリング: | bayesian |
注意
現在、ランダム サンプリングとグリッド サンプリングのみが条件付きハイパーパラメーター空間をサポートしています。
早期終了ポリシー
早期終了ポリシーによって、パフォーマンスの低い試行を自動的に終了できます。 早期終了によって、コンピューティング効率が向上し、そうでなければ、あまり見込みのない試行で費やされてしまうコンピューティング リソースを節約できます。 画像の自動 ML では、early_termination パラメーターを使用した次の早期終了ポリシーがサポートされています。 終了ポリシーが指定されていない場合は、すべての試行が完了するまで実行されます。
| 早期終了ポリシー | AutoML ジョブの構文 |
|---|---|
| バンディット ポリシー | CLI v2: bandit SDK v2: BanditPolicy() |
| 中央値の停止ポリシー | CLI v2: median_stopping SDK v2: MedianStoppingPolicy() |
| 切り捨て選択ポリシー | CLI v2: truncation_selection SDK v2: TruncationSelectionPolicy() |
ハイパーパラメーター スイープの早期終了ポリシーを構成する方法の詳細を確認してください。
注意
スイープ構成の完全なサンプルについては、このチュートリアルを参照してください。
下の例に示すように、スイープ関連のすべてのパラメーターを構成できます。
適用対象: Azure CLI ML 拡張機能 v2 (現行)
sweep:
sampling_algorithm: random
early_termination:
type: bandit
evaluation_interval: 2
slack_factor: 0.2
delay_evaluation: 6
固定設定
下に示すように、パラメーター空間スイープ中に変化しない固定の設定またはパラメーターを渡すことができます。
適用対象: Azure CLI ML 拡張機能 v2 (現行)
training_parameters:
early_stopping: True
evaluation_frequency: 1
データの拡張
一般に、ディープ ラーニング モデルのパフォーマンスは、多くの場合にデータが多いほど向上する可能性があります。 データの拡張は、データのサイズとデータセットの多様性を拡張するための実用的な手法であり、オーバーフィットを防ぎ、目に見えないデータに対するモデルの一般化機能を改善するのに役立ちます。 自動 ML では、入力画像をモデルにフィードする前に、Computer Vision タスクに基づいてさまざまなデータ拡張手法が適用されます。 現在、データ拡張を制御するために公開されたハイパーパラメーターはありません。
| タスク | 影響を受けるデータセット | 適用されるデータ拡張手法 |
|---|---|---|
| 画像分類 (複数クラスおよび複数ラベル) | トレーニング 検証とテスト |
ランダムなサイズ変更とトリミング、左右反転、色ジッター (輝度、コントラスト、彩度、色相)、チャネルごとの ImageNet の平均と標準偏差を使用した正規化 サイズ変更、中心のトリミング、正規化 |
| 物体検出、インスタンスのセグメント化 | トレーニング 検証とテスト |
境界ボックス周囲のランダムなトリミング、展開、左右反転、正規化、サイズ変更 正規化、サイズ変更 |
| yolov5 を使用した物体検出 | トレーニング 検証とテスト |
モザイク、ランダム アフィン (回転、平行移動、スケーリング、傾斜)、左右反転 レターボックスのサイズ変更 |
現在、上記で定義した拡張は、イメージ ジョブの自動 ML に既定で適用されます。 拡張を制御できるよう、イメージの自動 ML では以下の 2 つのフラグが公開されており、特定の拡張をオフにすることができます。 現時点では、これらのフラグは物体検出タスクとインスタンス セグメント化タスクでのみサポートされています。
- apply_mosaic_for_yolo: このフラグは、Yolo モデルに固有です。 これを False に設定すると、トレーニング時に適用されるモザイク データ拡張がオフになります。
- apply_automl_train_augmentations: このフラグを false に設定すると、物体検出モデルとインスタンス セグメント化モデルのトレーニング時に適用される拡張がオフになります。 拡張については、上の表の詳細を参照してください。
- 非 yolo 物体検出モデルとインスタンス セグメント化モデルの場合、このフラグにより最初の 3 つの拡張のみがオフになります。 例: 境界ボックスの周囲をランダムにトリミングし、拡大し、水平方向に反転します。 正規化とサイズ変更の拡張は、このフラグに関係なく適用されます。
- Yolo モデルの場合、このフラグによりランダム アフィンと左右反転の拡張がオフになります。
これら 2 つのフラグは、training_parameters の advanced_settings でサポートされており、以下の方法で制御することができます。
適用対象: Azure CLI ML 拡張機能 v2 (現行)
training_parameters:
advanced_settings: >
{"apply_mosaic_for_yolo": false}
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false}
なお、これら 2 つのフラグは互いに独立しており、以下の設定を用いて組み合わせて使用することも可能です。
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false, "apply_mosaic_for_yolo": false}
実験では、これらの拡張がモデルをより一般化するのに役立つことがわかりました。 したがって、これらの拡張がオフの場合、より良い結果を得るために、それらを他のオフライン拡張と組み合わせることをお勧めします。
増分トレーニング (省略可能)
トレーニング ジョブが完了したら、トレーニング済みのモデルのチェックポイントを読み込むことによって、モデルをさらにトレーニングすることができます。 増分トレーニングには、同じデータセットまたは別のデータセットを使用することができます。 モデルに問題がなければ、トレーニングを停止し、現在のモデルを使用することを選択できます。
ジョブ ID を使用してチェックポイントを渡す
チェックポイントの読み込み元となるジョブ ID を渡すことができます。
適用対象: Azure CLI ML 拡張機能 v2 (現行)
training_parameters:
checkpoint_run_id : "target_checkpoint_run_id"
AutoML ジョブを送信する
適用対象: Azure CLI ML 拡張機能 v2 (現行)
AutoML ジョブを送信するには、.yml ファイルへのパス、ワークスペース名、リソース グループ、サブスクリプション ID を指定して、次の CLI v2 コマンドを実行します。
az ml job create --file ./hello-automl-job-basic.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
出力と評価のメトリック
自動 ML トレーニング ジョブによって、出力モデル ファイル、評価メトリック、ログ、およびスコアリング ファイルや環境ファイルなどのデプロイ成果物が生成されます。 これらのファイルとメトリックは、子ジョブの出力とログとメトリック タブから表示できます。
ヒント
「ジョブ結果の表示」セクションからジョブ結果に移動する方法を確認してください。
ジョブごとに提供されるパフォーマンス グラフおよびメトリックの定義と例については、「自動化機械学習実験の結果を評価する」を参照してください。
モデルを登録して展開する
ジョブが完了したら、最適な試行 (最適な主要メトリックになった構成) から作成されたモデルを登録できます。 モデルは、ダウンロード後に登録するか、対応する jobid で azureml パスを指定することで登録できます。 注: 以下で説明する推論設定を変更する場合は、モデルをダウンロードして settings.json を変更し、更新されたモデル フォルダーを使用して登録する必要があります。
最適な試行を取得する
適用対象: Azure CLI ML 拡張機能 v2 (現行)
CLI example not available, please use Python SDK.
モデルを登録する
azureml パスまたはローカルでダウンロードしたパスを使用してモデルを登録します。
適用対象: Azure CLI ML 拡張機能 v2 (現行)
az ml model create --name od-fridge-items-mlflow-model --version 1 --path azureml://jobs/$best_run/outputs/artifacts/outputs/mlflow-model/ --type mlflow_model --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
使用するモデルを登録したら、マネージド オンライン エンドポイント deploy-managed-online-endpoint を使用してモデルをデプロイできます。
オンライン エンドポイントを構成する
適用対象: Azure CLI ML 拡張機能 v2 (現行)
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: od-fridge-items-endpoint
auth_mode: key
エンドポイントを作成する
先ほど作成した MLClient を使用して、今度はワークスペースにエンドポイントを作成します。 このコマンドでは、エンドポイントの作成を開始し、エンドポイントの作成が続行されている間に確認応答を返します。
適用対象: Azure CLI ML 拡張機能 v2 (現行)
az ml online-endpoint create --file .\create_endpoint.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
オンライン デプロイを構成する
デプロイは、実際の推論を実行するモデルをホストするのに必要なリソースのセットです。 ManagedOnlineDeployment クラスを使用してエンドポイントのデプロイを作成します。 デプロイ クラスターには、GPU または CPU VM SKU のいずれかを使用できます。
適用対象: Azure CLI ML 拡張機能 v2 (現行)
name: od-fridge-items-mlflow-deploy
endpoint_name: od-fridge-items-endpoint
model: azureml:od-fridge-items-mlflow-model@latest
instance_type: Standard_DS3_v2
instance_count: 1
liveness_probe:
failure_threshold: 30
success_threshold: 1
timeout: 2
period: 10
initial_delay: 2000
readiness_probe:
failure_threshold: 10
success_threshold: 1
timeout: 10
period: 10
initial_delay: 2000
配置を作成する
先ほど作成した MLClient を使用して、今度はワークスペースにデプロイを作成します。 このコマンドは、デプロイの作成を開始し、デプロイの作成が続行されている間に確認応答を返します。
適用対象: Azure CLI ML 拡張機能 v2 (現行)
az ml online-deployment create --file .\create_deployment.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
トラフィックを更新する:
既定では、現在のデプロイは 0% のトラフィックを受信するように設定されています。 現在のデプロイで受信するトラフィックの割合を設定できます。 1 つのエンドポイントを使用するすべてのデプロイのトラフィックの割合の合計が 100% を超えないようにする必要があります。
適用対象: Azure CLI ML 拡張機能 v2 (現行)
az ml online-endpoint update --name 'od-fridge-items-endpoint' --traffic 'od-fridge-items-mlflow-deploy=100' --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
または、Azure Machine Learning スタジオ UI からモデルをデプロイすることもできます。 自動 ML ジョブの [モデル] タブで、デプロイするモデルに移動し、[デプロイ] を選択し、[リアルタイム エンドポイントへのデプロイ] を選びます。
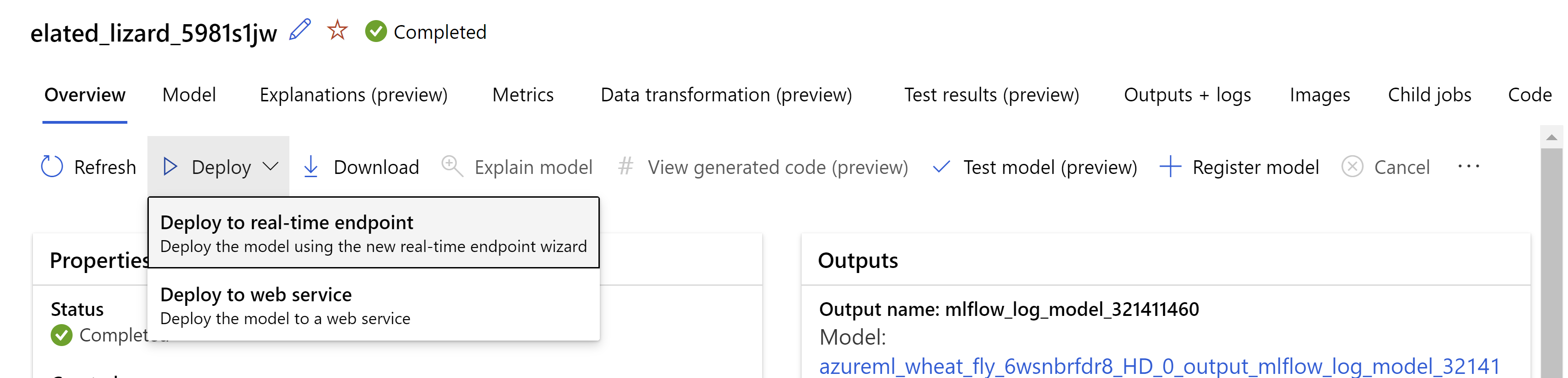 。
。
レビュー ページは次のように表示されます。 インスタンスの種類とインスタンス数を選択し、現在のデプロイのトラフィックの割合を設定できます。
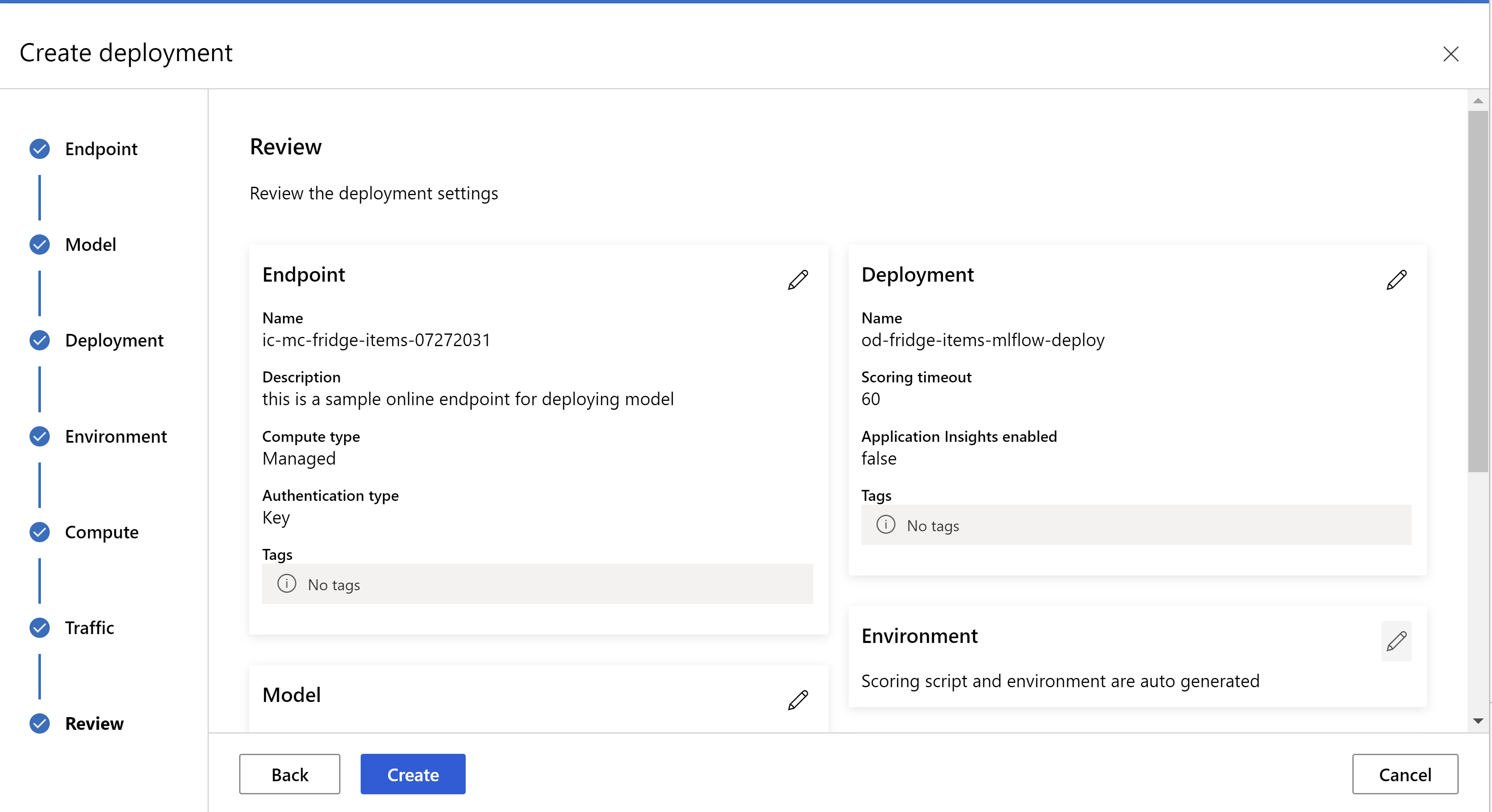 。
。
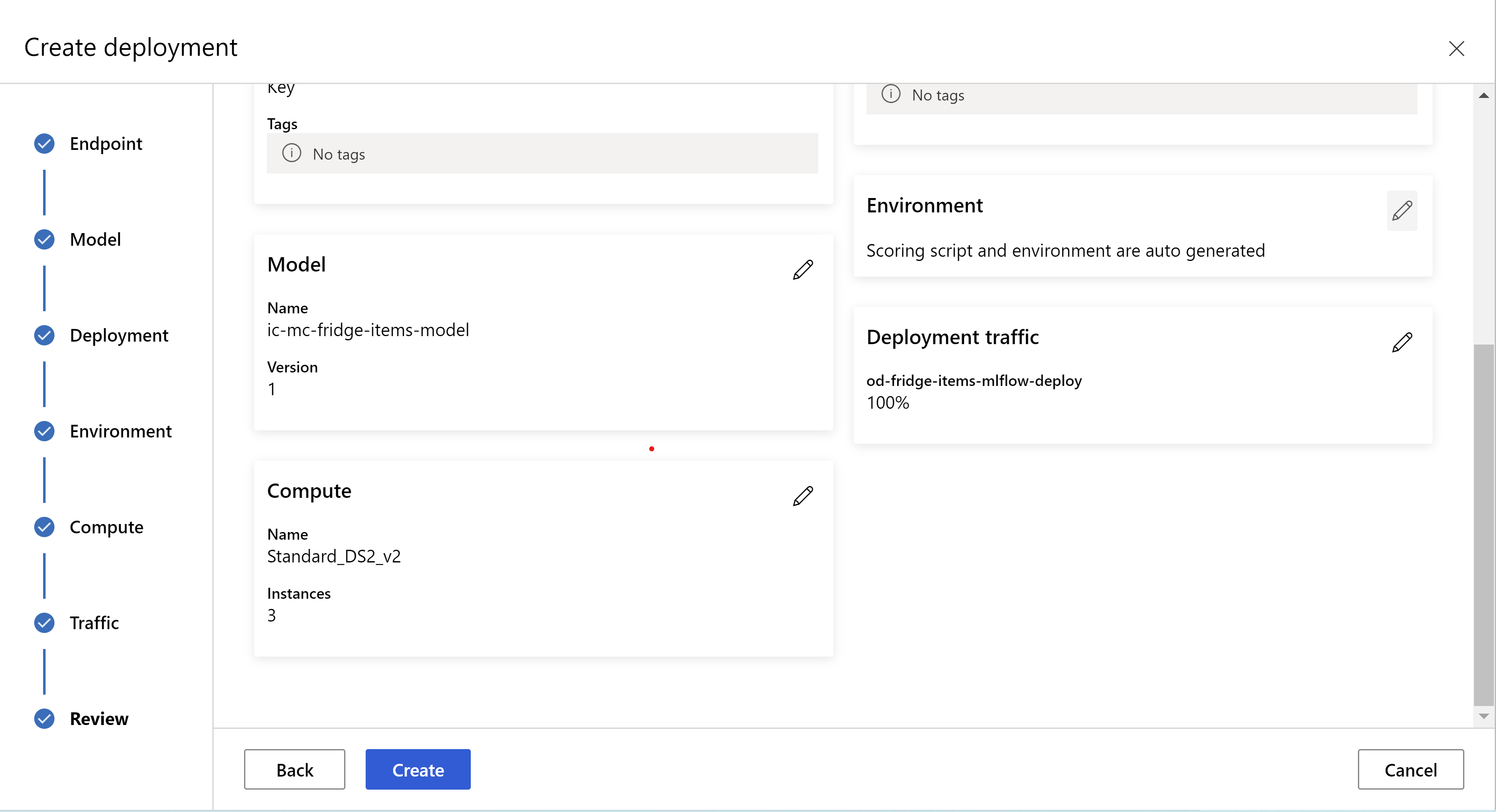 。
。
推論設定を更新する
前の手順では、最適なモデルからファイル mlflow-model/artifacts/settings.json をダウンロードしました。 これは、モデルを登録する前に推論設定を更新するために使用できます。 ただし、最適なパフォーマンスを得るには、トレーニングと同じパラメーターを使用することをお勧めします。
各タスク (および一部のモデル) では、一連のパラメーターがあります。 既定で、トレーニングおよび検証時に使用されたパラメーターに同じ値を使用します。 推論にモデルを使用するときに必要な動作に応じて、これらのパラメーターを変更できます。 各タスクの種類とモデルのパラメーターの一覧を次に示します。
| タスク | パラメーター名 | Default |
|---|---|---|
| 画像分類 (複数クラスおよび複数ラベル) | valid_resize_sizevalid_crop_size |
256 224 |
| オブジェクトの検出 | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0.3 0.5 100 |
yolov5 を使用した物体検出 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 中 0.1 0.5 |
| インスタンスのセグメント化 | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0.3 0.5 100 0.5 100 False JPG |
タスク固有のハイパーパラメーターの詳細については、「自動機械学習におけるコンピューター ビジョン タスクのハイパーパラメーター」を参照してください。
タイルを使用し、タイルの動作を制御する場合は、パラメーター tile_grid_size、tile_overlap_ratio、tile_predictions_nms_thresh を使用できます。 これらのパラメーターの詳細については、「AutoML を使用した小さな物体検出モデルのトレーニング」に関するページを確認してください。
展開をテスト
この[デプロイのテスト]セクションを確認してデプロイをテストし、モデルからの検出を視覚化してください。
予測の説明を生成する
重要
これらの設定は、現在、パブリック プレビューの段階にあります。 それらは、サービス レベル アグリーメントなしで提供されます。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
警告
モデルの説明可能性は、複数クラス分類と複数ラベル分類でのみサポートされます。
AutoML for Images で Explainable AI (XAI) を使用する利点の例:
- 複雑なビジョン モデル予測の透明性を改善できます
- ユーザーがモデル予測に寄与している入力イメージの重要な特徴とピクセルを理解するのに役立ちます
- モデルのトラブルシューティングに役立ちます
- バイアスの検出に役立ちます
説明
説明は、モデル予測への寄与に基づき入力イメージ内の各ピクセルに与えられる特徴属性または重み付けです。 各重み付けは、負 (予測と負の相関) または正 (予測と正の相関) の値になります。 これらの属性は予測クラスに対し計算されます。 複数クラス分類の場合、サンプルごとにサイズ [3, valid_crop_size, valid_crop_size] の属性マトリックスが 1 つ生成されますが、複数ラベル分類の場合は、各サンプルの予測ラベルまたはクラスごとにサイズ [3, valid_crop_size, valid_crop_size] の属性マトリックスが生成されます。
デプロイされたエンドポイントの AutoML for Images で Explainable AI を使用すると、ユーザーは各イメージの説明 (入力イメージに重ねられたイメージ) や属性 (サイズ [3, valid_crop_size, valid_crop_size] の多次元配列) の視覚化を実現できます。 視覚化に加え、ユーザーは属性マトリックスを取得して説明をより詳細に制御することもできます (属性を使用したカスタム視覚化の生成や属性のセグメントの調査など)。 すべての説明アルゴリズムは、属性を生成するためにサイズ valid_crop_size のトリミングされた正方形のイメージを使用します。
説明は、オンライン エンドポイントまたはバッチ エンドポイントから生成できます。 デプロイが完了すると、このエンドポイントを使用して予測の説明を生成できます。 オンライン デプロイの場合は、ManagedOnlineDeployment に request_settings = OnlineRequestSettings(request_timeout_ms=90000) パラメーターを渡し、最大値に request_timeout_ms を設定して、説明の生成中にタイムアウトの問題を回避してください (「モデルの登録とデプロイ」に関するセクションを参照してください)。 説明可能性 (XAI) メソッドの中には、xrai のようにより多くの時間を消費するものがあります (特に、各予測ラベルに対して属性や視覚化を生成する必要がある複数ラベル分類の場合)。 そのため、より迅速な説明を生成する GPU インスタンスをお勧めします。 説明を生成するための入力スキーマと出力スキーマの詳細については、スキーマのドキュメントを参照してください。
AutoML for Images では、次の最先端の説明可能性アルゴリズムがサポートされます。
- XRAI (xrai)
- 統合グラデーション (integrated_gradients)
- ガイド付き GradCAM (guided_gradcam)
- ガイド付き BackPropagation (guided_backprop)
次の表では、XRAI および統合グラデーションの説明可能性アルゴリズム固有のチューニング パラメーターについて説明します。 ガイド付き BackPropagation とガイド付き GradCAM にはチューニング パラメーターは必要ありません。
| XAI アルゴリズム | アルゴリズム固有のパラメーター | 既定値 |
|---|---|---|
xrai |
1. n_steps: 概算法が使用するステップの数。 ステップの数が多いほど、属性 (説明) の概算が改善します。 n_steps の範囲は [2, inf) ですが、属性のパフォーマンスは 50 ステップ後に収束し始めます。 Optional, Int 2. xrai_fast: より高速なバージョンの XRAI を使用するかどうか。 True の場合、説明の計算時間は速くなりますが、正確でない説明 (属性) につながります。Optional, Bool |
n_steps = 50 xrai_fast = True |
integrated_gradients |
1. n_steps: 概算法が使用するステップの数。 ステップの数が多いほど、属性 (説明) の概算が改善します。 n_steps の範囲は [2, inf) ですが、属性のパフォーマンスは 50 ステップ後に収束し始めます。Optional, Int 2. approximation_method: 積分を概算する方法。 使用可能な概算法は riemann_middle と gausslegendre です。Optional, String |
n_steps = 50 approximation_method = riemann_middle |
内部的に XRAI アルゴリズムは統合されたグラデーションを使用します。 そのため、統合グラデーションと XRAI アルゴリズムの両方で n_steps パラメーターが必要になります。 ステップの数が多いほど説明を概算するために時間がかかるため、オンライン エンドポイントでタイムアウトの問題が発生する可能性があります。
より適切な説明を生成するには、XRAI > ガイド付き GradCAM > 統合グラデーション > ガイド付き BackPropagation の順でアルゴリズムを使用することをお勧めします。一方、指定された順序で説明の生成を高速化するには、ガイド付き BackPropagation > ガイド付き GradCAM > 統合グラデーション > XRAI の順で使用することをお勧めします。
オンライン エンドポイントに対するサンプル要求は次のようになります。 model_explainability が True に設定されている場合、この要求によって説明が生成されます。 次の要求では、50 ステップの高速バージョンの XRAI アルゴリズムを使用して視覚化と属性が生成されます。
import base64
import json
def read_image(image_path):
with open(image_path, "rb") as f:
return f.read()
sample_image = "./test_image.jpg"
# Define explainability (XAI) parameters
model_explainability = True
xai_parameters = {"xai_algorithm": "xrai",
"n_steps": 50,
"xrai_fast": True,
"visualizations": True,
"attributions": True}
# Create request json
request_json = {"input_data": {"columns": ["image"],
"data": [json.dumps({"image_base64": base64.encodebytes(read_image(sample_image)).decode("utf-8"),
"model_explainability": model_explainability,
"xai_parameters": xai_parameters})],
}
}
request_file_name = "sample_request_data.json"
with open(request_file_name, "w") as request_file:
json.dump(request_json, request_file)
resp = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name=deployment.name,
request_file=request_file_name,
)
predictions = json.loads(resp)
説明の生成の詳細については、自動化された機械学習サンプルの GitHub ノートブック リポジトリに関するページを参照してください。
視覚化の解釈
model_explainability と visualizations の両方が True に設定されている場合、デプロイされたエンドポイントは base64 でエンコードされたイメージ文字列を返します。 ノートブックで説明されているように base64 文字列をデコードするか、次のコードを使用して、予測の base64 イメージ文字列をデコードして視覚化します。
import base64
from io import BytesIO
from PIL import Image
def base64_to_img(base64_img_str):
base64_img = base64_img_str.encode("utf-8")
decoded_img = base64.b64decode(base64_img)
return BytesIO(decoded_img).getvalue()
# For Multi-class classification:
# Decode and visualize base64 image string for explanations for first input image
# img_bytes = base64_to_img(predictions[0]["visualizations"])
# For Multi-label classification:
# Decode and visualize base64 image string for explanations for first input image against one of the classes
img_bytes = base64_to_img(predictions[0]["visualizations"][0])
image = Image.open(BytesIO(img_bytes))
次の図では、サンプル入力イメージの説明の視覚化について説明します。

デコードされた base64 の図には、2 x 2 のグリッド内に 4 つのイメージ セクションがあります。
- 左上のイメージ (0, 0) はトリミングされた入力イメージです。
- 右上のイメージ (0, 1) は、予測クラスの白いピクセルの寄与が最も高く、青いピクセルの寄与が最も低いカラー スケール bgyw (青緑黄白) の属性のヒートマップです。
- 左下のイメージ (1, 0) は、トリミングされた入力イメージに属性のヒートマップをブレンドしたものです。
- 右下のイメージ (1, 1) は、属性スコアに基づいてピクセルの上位 30% を含むトリミングされた入力イメージです。
属性の解釈
model_explainability と attributions の両方が True に設定されている場合、デプロイされたエンドポイントは属性を返します。 詳細については、複数クラス分類と複数ラベル分類のノートブックに関するページを参照してください。
ユーザーがこれらの属性を使用すると、カスタム視覚化を生成し、ピクセル レベルの属性スコアを詳しく調べるために、より詳細な制御を行うことができます。 次のコード スニペットは、属性マトリックスを使用してカスタム視覚化を生成する方法について説明します。 複数クラス分類と複数ラベル分類の属性のスキーマの詳細については、スキーマのドキュメントを参照してください。
選択したモデルの valid_resize_size と valid_crop_size の正確な値を使用して説明を生成します (既定値はそれぞれ 256 と 224 です)。 次のコードは Captum 視覚化機能を使用してカスタム視覚化を生成します。 ユーザーは他のライブラリを利用して視覚化を生成できます。 詳細については、Captum 視覚化ユーティリティを参照してください。
import colorcet as cc
import numpy as np
from captum.attr import visualization as viz
from PIL import Image
from torchvision import transforms
def get_common_valid_transforms(resize_to=256, crop_size=224):
return transforms.Compose([
transforms.Resize(resize_to),
transforms.CenterCrop(crop_size)
])
# Load the image
valid_resize_size = 256
valid_crop_size = 224
sample_image = "./test_image.jpg"
image = Image.open(sample_image)
# Perform common validation transforms to get the image used to generate attributions
common_transforms = get_common_valid_transforms(resize_to=valid_resize_size,
crop_size=valid_crop_size)
input_tensor = common_transforms(image)
# Convert output attributions to numpy array
# For Multi-class classification:
# Selecting attribution matrix for first input image
# attributions = np.array(predictions[0]["attributions"])
# For Multi-label classification:
# Selecting first attribution matrix against one of the classes for first input image
attributions = np.array(predictions[0]["attributions"][0])
# visualize results
viz.visualize_image_attr_multiple(np.transpose(attributions, (1, 2, 0)),
np.array(input_tensor),
["original_image", "blended_heat_map"],
["all", "absolute_value"],
show_colorbar=True,
cmap=cc.cm.bgyw,
titles=["original_image", "heatmap"],
fig_size=(12, 12))
大規模なデータセット
AutoML を使って大きいデータセットをトレーニングしている場合は、役に立つ可能性がある実験設定がいくつかあります。
重要
これらの設定は、現在、パブリック プレビューの段階にあります。 それらは、サービス レベル アグリーメントなしで提供されます。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
マルチ GPU とマルチノードのトレーニング
既定では、各モデルは 1 つの VM でトレーニングされます。 モデルのトレーニングに時間がかかりすぎる場合は、複数の GPU を含む VM を使うと役立つ場合があります。 大きなデータセットでモデルをトレーニングする時間は、使われる GPU の数に比例してほぼ直線的に減少するはずです。 (たとえば、GPU が 1 つの VM と比較して、GPU が 2 つの VM では、モデルは約 2 倍の速さでトレーニングされるはずで)。複数の GPU を備えた VM でモデルをトレーニングしてもまだ時間がかかる場合は、各モデルのトレーニングに使われる VM の数を増やすことができます。 マルチ GPU のトレーニングと同様に、大きなデータセットでモデルをトレーニングする時間は、使われる VM の数に比例してほぼ直線的に減少するはずです。 複数の VM でモデルをトレーニングする場合は、最善の結果になるよう、InfiniBand をサポートするコンピューティング SKU を使ってください。 AutoML ジョブの node_count_per_trial プロパティを設定することで、1 つのモデルのトレーニングに使われる VM の数を構成できます。
適用対象: Azure CLI ML 拡張機能 v2 (現行)
properties:
node_count_per_trial: "2"
ストレージからの画像ファイルのストリーミング
既定では、モデルのトレーニングの前にすべての画像ファイルがディスクにダウンロードされます。 画像ファイルのサイズが使用可能なディスク領域より大きい場合、ジョブは失敗します。 すべての画像をディスクにダウンロードする代わりに、トレーニング中に必要に応じて Azure Storage から画像ファイルをストリーミングすることを選択できます。 画像ファイルは、ディスクをバイパスして、Azure Storage からシステム メモリに直接ストリーミングされます。 同時に、ストレージから可能な限り多くのファイルがディスクにキャッシュされ、ストレージへの要求の数が最小限に抑えられます。
Note
ストリーミングが有効になっている場合は、コストと待ち時間を最小限に抑えるため、Azure ストレージ アカウントがコンピューティングと同じリージョンに配置されていることを確認してください。
適用対象: Azure CLI ML 拡張機能 v2 (現行)
training_parameters:
advanced_settings: >
{"stream_image_files": true}
サンプルの Notebook
GitHub の自動機械学習サンプルのノートブック リポジトリで詳しいコード サンプルやユース ケースを確認してください。 コンピュータービジョン モデルの構築に固有のサンプルについては、「automl-image-」プレフィックスが付いたフォルダーを確認してください。
コード例
自動機械学習サンプルの azureml-examples リポジトリで詳しいコード サンプルやユース ケースを確認してください。