Azure Machine Learning スタジオを使用してデータに接続する
この記事では、Azure Machine Learning スタジオを使用してデータにアクセスする方法について説明します。 Azure Machine Learning データストアを使用して Azure 上のストレージ サービス内のデータに接続し、Azure Machine Learning データセットを使用して、ML ワークフローのタスク用にそのデータをパッケージ化します。
次の表では、データストアとデータセットを定義し、そのメリットの概要を説明しています。
| Object | 説明 | メリット |
|---|---|---|
| データストア | サブスクリプション ID やトークン認証などの接続情報を、ワークスペースに関連付けられた Key Vault に格納することにより、Azure 上のストレージ サービスに安全に接続します。 | 情報は安全に保存されるため: |
| データセット | データセットを作成することにより、データ ソースの場所への参照とそのメタデータのコピーを作成します。 データセットを使用することで、次が可能となります。 |
データセットは遅延評価され、データは既存の場所に残るため: |
Azure Machine Learning のデータ アクセス ワークフロー全体におけるデータストアとデータセットの位置付けの詳細については、データへの安全なアクセスに関する記事を参照してください。
コード ファーストでのエクスペリエンスについては、次の記事を参照して、Azure Machine Learning Python SDK を使用してください。
前提条件
Azure サブスクリプション。 Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。 無料版または有料版の Azure Machine Learning をお試しください。
Azure Machine Learning スタジオへのアクセス。
Azure Machine Learning ワークスペース。 ワークスペース リソースを作成します。
- ワークスペースを作成すると、ワークスペースに Azure BLOB コンテナーと Azure ファイル共有がデータストアとして自動的に登録されます。 これらの名前は、それぞれ
workspaceblobstoreおよびworkspacefilestoreとなります。 ニーズに対して BLOB ストレージで十分な場合は、workspaceblobstoreが既定のデータストアとして設定されます。これは既に使用できるように構成されています。 それ以外の場合は、サポートされているストレージの種類のストレージ アカウントが Azure 上で必要です。
- ワークスペースを作成すると、ワークスペースに Azure BLOB コンテナーと Azure ファイル共有がデータストアとして自動的に登録されます。 これらの名前は、それぞれ
データストアの作成
データストアは、これらの Azure Storage ソリューションから作成できます。 サポートされていないストレージ ソリューションの場合、および ML 実験中のデータ エグレス コストを節約するためには、サポートされている Azure Storage ソリューションにデータを移行する必要があります。 データストアに関する詳細を参照してください。
資格情報ベースのアクセスまたは ID ベースのアクセスを使用したデータストアを作成できます。
Azure Machine Learning Studio を使用して、少ない手順で新しいデータストアを作成します。
重要
データ ストレージ アカウントが仮想ネットワーク内にある場合は、Studio がデータにアクセスできるようにするために、追加の構成手順が必要になります。 適切な構成手順を適用するため、ネットワーク分離とプライバシーに関する記事を参照してください。
- Azure Machine Learning Studio にサインインします。
- [アセット] の下の左側のペインで [データ] を選択します。
- 上部の [データストア] を選択します。
- [+作成] を選択します。
- フォームに入力し、新しいデータストアを作成して登録します。 このフォームは、選択した Azure Storage の種類と認証の種類に基づいて、インテリジェントに自動更新されます。 このフォームを設定するために必要な認証資格情報の場所については、ストレージ アクセスとアクセス許可に関するセクションを参照してください。
次の例は、Azure BLOB データストアを作成するときにフォームがどのように表示されるかを示しています。
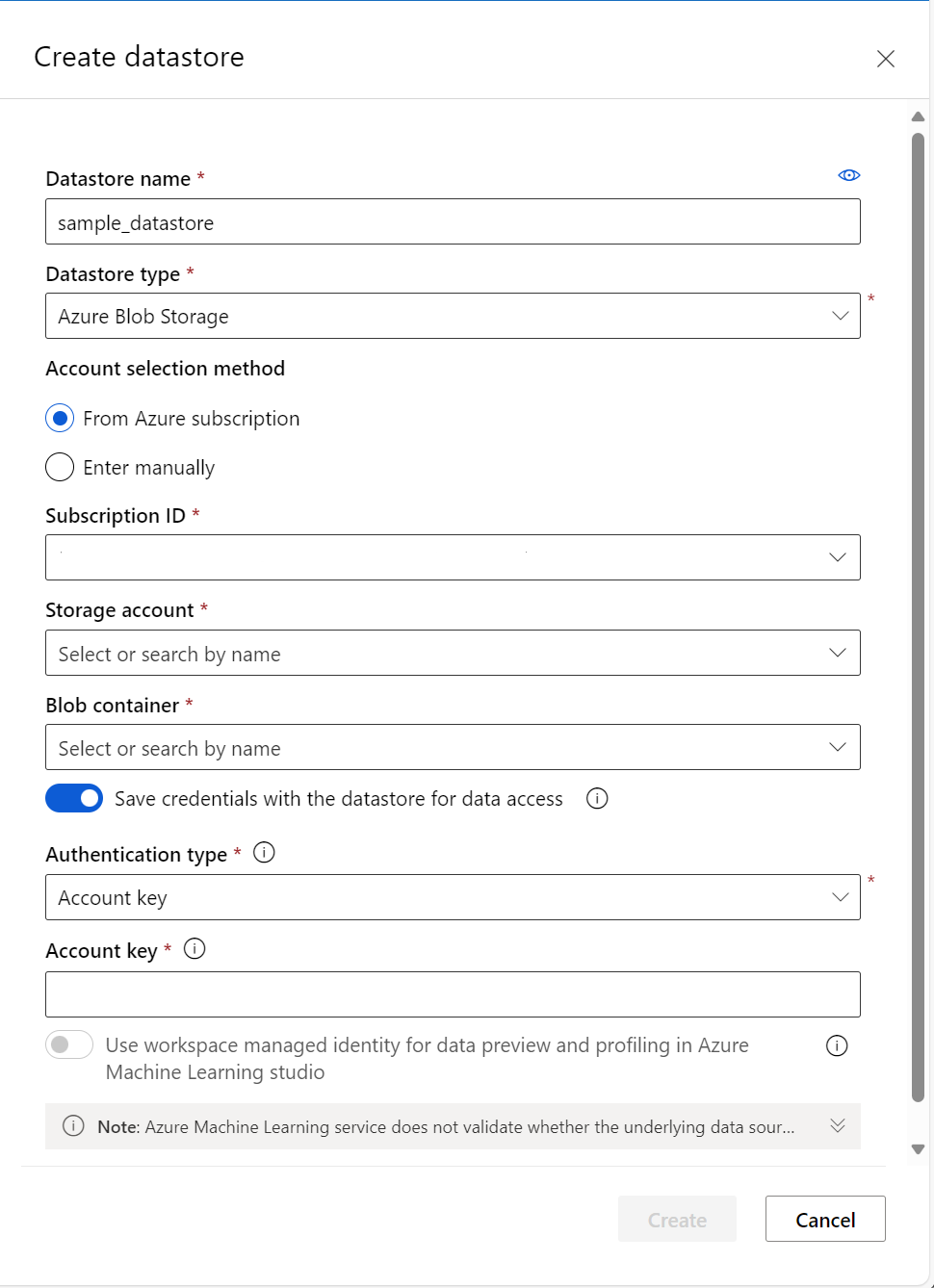
データ資産を作成する
データストアを作成したら、データを操作するためのデータセットを作成します。 データセットを使用すると、データを機械学習タスク (トレーニングなど) 用に遅延評価された使用可能なオブジェクトにパッケージ化できます。 データセットの詳細情報.
データセットには、FileDataset と TabularDataset の 2 種類があります。 FileDatasets は、1 つまたは複数のファイルまたはパブリック URL への参照を作成します。 一方、TabularDatasets は、データを表形式で表現します。 TabularDatasets は、.csv ファイル、.tsv ファイル、.parquet ファイル、.jsonl ファイル、SQL クエリ結果から作成できます。
次の手順では、Azure Machine Learning Studio でデータセットを作成する方法を示します。
注意
Azure Machine Learning Studio を介して作成されたデータセットは、自動的にワークスペースに登録されます。
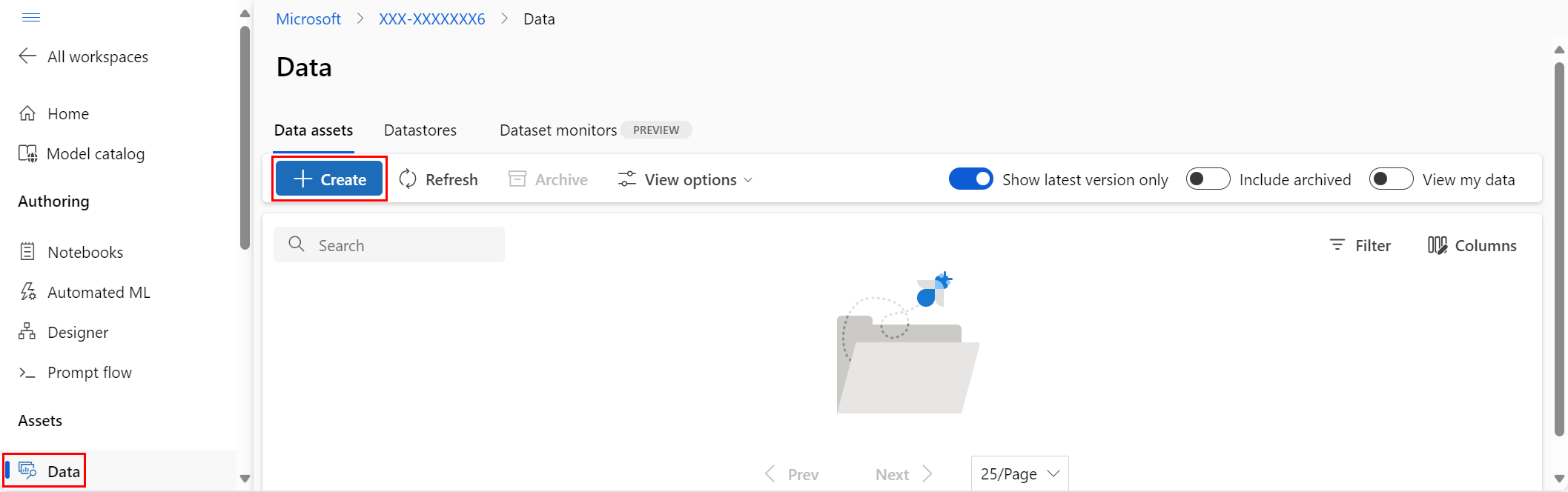
左側のナビゲーションの [資産] で [データ] を選択します。 [データ アセット] タブで [作成] を選びます
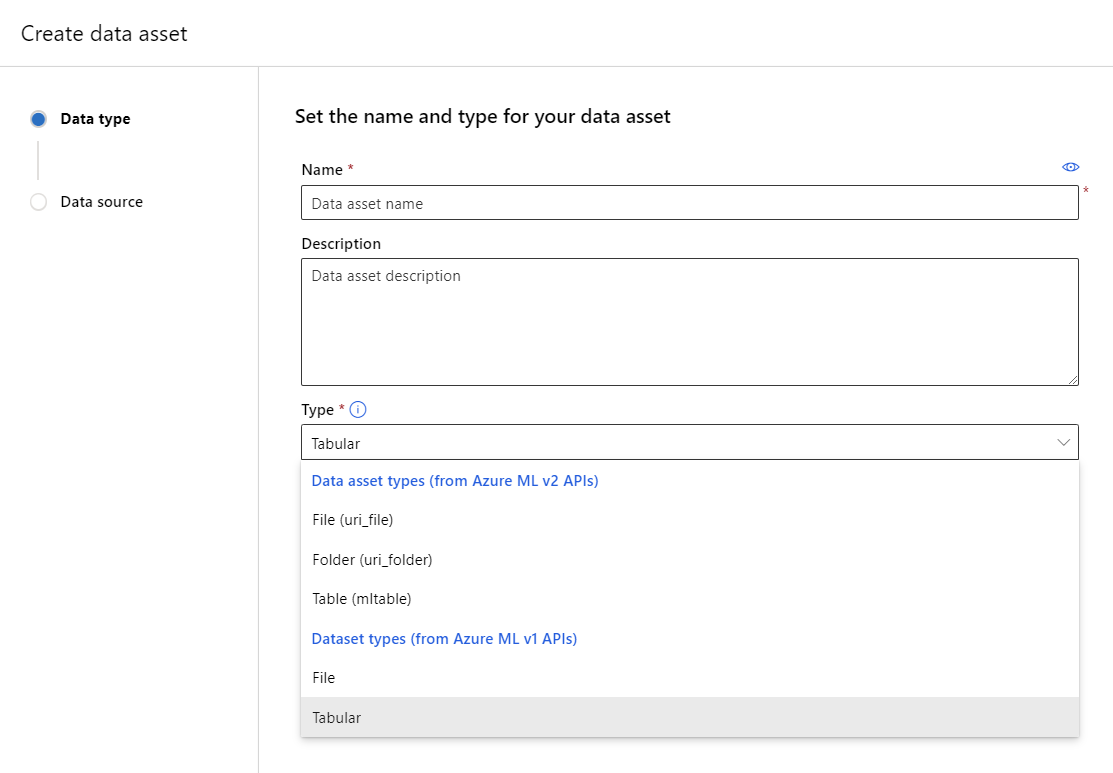
データ資産に名前と説明 (省略可能) を指定します。 次に、[種類] で、[ファイル] または [表形式] のいずれかのデータセットの種類を選択します。
データ ソースにはいくつかのオプションがあります。 データが既に Azure に格納されている場合は、[Azure ストレージから] を選択します。 ローカル ドライブからデータをアップロードする場合は、[ローカル ファイルから] を選択します。 データがパブリックな Web の場所に格納されている場合は、[Web ファイルから] を選択します。 SQL データベースから、または Azure Open Datasets からデータ資産を作成することもできます。
ファイルの選択の手順では、データを Azure に格納する場所と、使用するデータ ファイルを選択します。
- データが仮想ネットワーク内にある場合は、検証のスキップを有効にします。 仮想ネットワークの分離とプライバシーについて理解を深める。
データ資産のデータ解析設定とスキーマを設定する手順に従います。 設定はファイルの種類に基づいて事前設定され、データ資産を作成する前に設定をさらに構成できます。
[レビュー] のステップに到達したら、最後のページで [作成] をクリックします。
データのプレビューとプロファイル
データセットを作成した後、次の手順に従ってスタジオでプレビューとプロファイルを表示できることを確認します。
- Azure Machine Learning スタジオにサインインします。
- 左側のナビゲーションの [資産] で [データ] を選択します。

- 表示するデータセットの名前を選択します。
- [Explore (探索)] タブをクリックします。
- [プレビュー] タブを選択します。
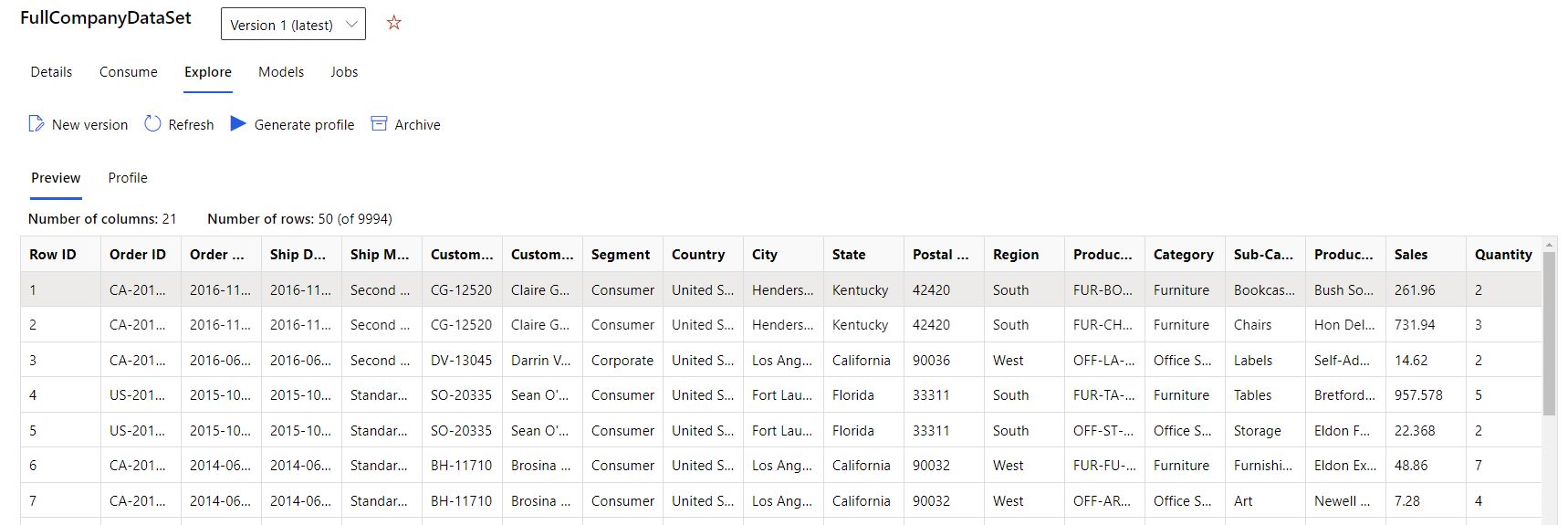
- [プロファイル] タブを選択します。
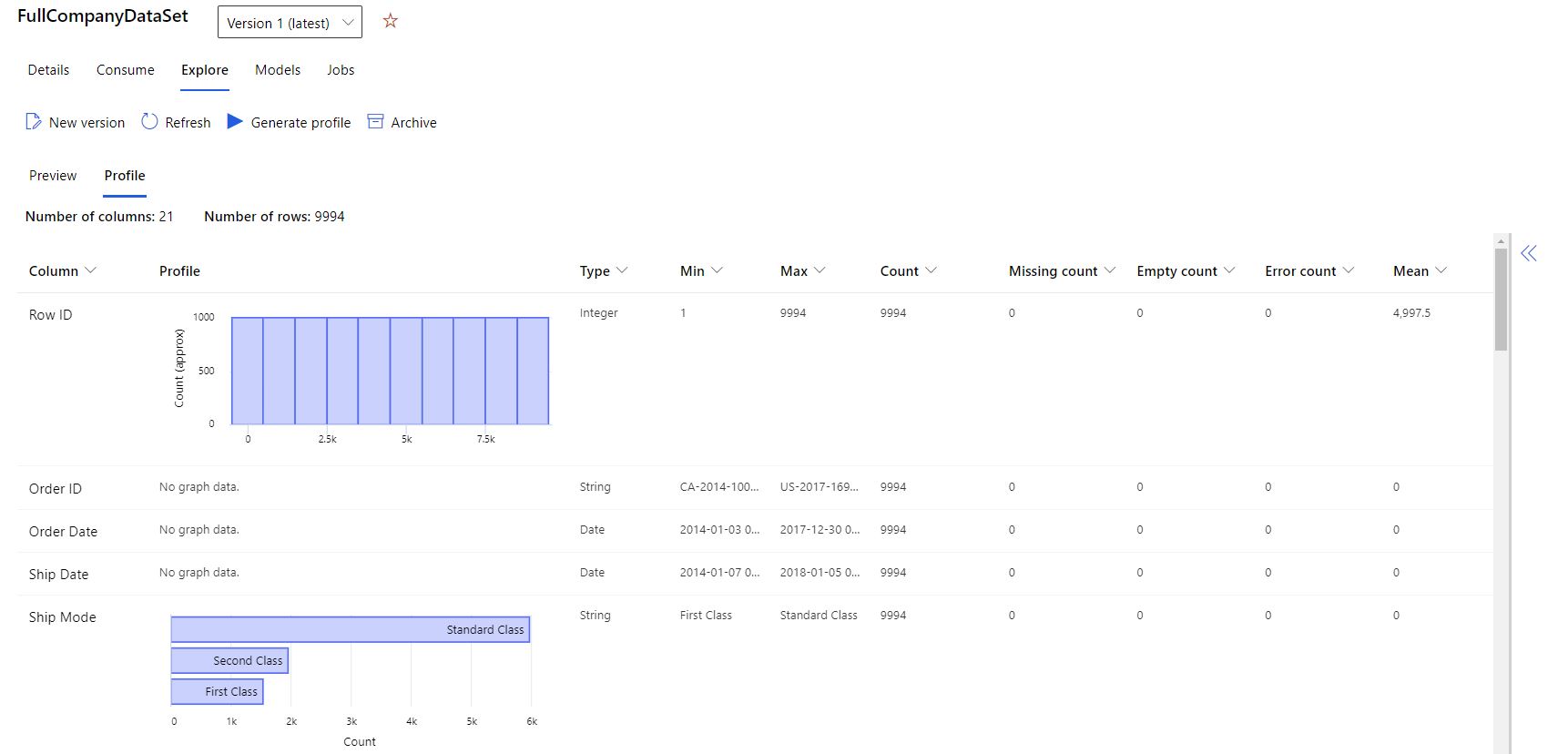
データ セットが ML 対応であるかどうかを確認するために、データ セット全体で幅広い概要統計情報を取得できます。 数値以外の列の場合、最小、最大、エラー数などの基本的な統計情報だけが含まれます。 数値列の場合は、その統計学的モーメントと、推定される分位点も確認できます。
具体的には、Azure Machine Learning データセットのデータ プロファイルには次のものが含まれます。
注意
無関係な型を持つ特徴には空白のエントリが表示されます。
| 統計 | 説明 |
|---|---|
| 特徴量 | 集約されている列の名前。 |
| プロファイル | 推論された型に基づくインライン視覚化。 たとえば、文字列、ブール値、日付には値の数が示される一方、10 進数 (数値) は近似されたヒストグラムが示されます。 これにより、データの分布を簡単に把握できます。 |
| 型の分布 | 列内の型のインライン値カウント。 Null は独自の型であるため、この視覚化は変則値または欠損値を検出するために便利です。 |
| Type | 推論される列の型。 使用可能な値には、文字列、ブール値、日付、10 進数が含まれます。 |
| Min | 列の最小値。 型に固有の順序がない特徴の場合 (ブール値など)、空白のエントリが表示されます。 |
| Max | 列の最大値。 |
| Count | 列内の欠落しているエントリと欠落していないエントリの合計数。 |
| Not Missing Count | 列内の欠落していないエントリの数。 空の文字列とエラーは値として扱われるため、"欠落していないカウント" には含まれません。 |
| 分位点 | データの分布感を提供する、各分位点での近似値。 |
| 平均 | 列の算術平均。 |
| 標準偏差 | この列のデータの分散または変動の尺度。 |
| Variance | この列のデータが平均値からどのくらい離れているかを示す尺度。 |
| 傾斜 | この列のデータが正規分布とどのくらい異なるかを示す尺度。 |
| 尖度 | この列のデータが正規分布と比較してどのくらい裾の重い分布になっているかを示す尺度。 |
ストレージへのアクセスとアクセス許可
Azure ストレージ サービスに安全に接続できるように、Azure Machine Learning では、対応するデータ ストレージにアクセスするためのアクセス許可が必要です。 このアクセスは、データストアの登録に使用される認証資格情報に依存します。
仮想ネットワーク
データ ストレージ アカウントが仮想ネットワーク内にある場合、Azure Machine Learning がデータにアクセスできるようにするためには、追加の構成手順が必要になります。 データストアを作成して登録する際に適切な構成手順が適用されるようにするには、仮想ネットワークで Azure Machine Learning Studio を使用する方法に関するページを参照してください。
アクセス検証
警告
ストレージ アカウントへのクロス テナント アクセスはサポートされていません。 シナリオでクロス テナント アクセスが必要な場合、Azure Machine Learning データ サポート チームにメール amldatasupport@microsoft.com で連絡し、カスタム コード解決を要請してください。
最初のデータストアの作成と登録のプロセスの一部として、Azure Machine Learning により、基になるストレージ サービスが存在すること、およびユーザーが指定したプリンシパル (ユーザー名、サービス プリンシパル、または SAS トークン) で指定したストレージにアクセスできることが自動的に検証されます。
データストアの作成後、この検証は、データストア オブジェクトが取得されるたびではなく、基になるストレージ コンテナーにアクセスする必要があるメソッドに対してのみ実行されます。 たとえば、データストアからファイルをダウンロードする場合は検証が行われますが、既定のデータストアを変更するだけの場合、検証は行われません。
基になるストレージ サービスへのアクセスを認証するには、作成するデータストアの種類に従って、アカウント キー、Shared Access Signature (SAS) トークン、またはサービス プリンシパルを指定します。 ストレージの種類のマトリックスには、各データストアの種類に対応する、サポートされている認証の種類が一覧表示されています。
アカウント キー、SAS トークン、およびサービス プリンシパルの情報は、Azure portal で確認できます。
認証にアカウント キーまたは SAS トークンを使用する予定の場合は、左側のウィンドウで [ストレージ アカウント] を選択し、登録するストレージ アカウントを選択します。
- [概要] ページには、アカウント名、コンテナー、ファイル共有名などの情報が表示されます。
- アカウント キーの場合、 [設定] ペインの [アクセス キー] に移動します。
- SAS トークンの場合は、 [設定] ペインの [共有アクセス署名] に移動します。
- [概要] ページには、アカウント名、コンテナー、ファイル共有名などの情報が表示されます。
認証にサービス プリンシパルを使用する予定の場合は、 [アプリの登録] に移動して、使用するアプリを選択します。
- 対応する [概要] ページに、テナント ID やクライアント ID などの必要な情報が記載されています。
重要
- Azure Storage アカウントのアクセス キー (アカウント キーまたは SAS トークン) を変更する必要がある場合は、新しい資格情報をワークスペースおよびそれに接続されているデータストアと同期してください。 更新された資格情報を同期する方法を参照してください。
- データストアの登録を解除し、同じ名前を使用して再登録しようとして失敗した場合は、ワークスペースの Azure キー コンテナーで、論理的な削除が有効になっていない可能性があります。 既定では、ワークスペースによって作成されたキー コンテナー インスタンスでは論理的な削除が有効になっていますが、既存のキー コンテナーを使用した場合、または 2020 年 10 月より前にワークスペースを作成した場合は、論理的な削除が有効になっていないことがあります。 論理的な削除を有効にする方法の詳細については、既存のキー コンテナーの論理的な削除を有効にするに関するセクションを参照してください。
アクセス許可
Azure BLOB コンテナーと Azure Data Lake Gen 2 ストレージの場合は、認証資格情報にストレージ BLOB データ閲覧者アクセスがあることを確認します。 ストレージ BLOB データ閲覧者の詳細については、こちらを参照してください。 アカウントの SAS トークンは、既定ではアクセス許可なしに設定されます。
データ読み取りアクセスの場合、認証資格情報には、コンテナーとオブジェクトに対するリストと読み取りのアクセス許可が少なくとも必要となります。
データ書き込みアクセスの場合は、書き込みと追加のアクセス許可も必要です。
データセットを使用したトレーニング
ML モデルのトレーニングのために、機械学習の実験でデータセットを使用します。 データセットを使ってトレーニングする方法の詳細をご覧ください。
次のステップ
データセットのトレーニングのその他の例については、サンプル ノートブックを参照してください。