Azure Machine Learning 推論 HTTP サーバーを使用したスコアリング スクリプトのデバッグ
Azure Machine Learning 推論 HTTP サーバーは、スコアリング関数を HTTP エンドポイントとして公開し、Flask サーバー コードと依存関係を単一のパッケージにラップしている Python パッケージです。 これは、Azure Machine Learning でモデルをデプロイする際に使用する推論用の事前構築済み Docker イメージに含まれています。 このパッケージのみを使用すると、運用環境用にローカルにモデルをデプロイできます。また、ローカル開発環境でスコアリング (エントリ) スクリプトを簡単に検証することもできます。 スコアリング スクリプトに問題がある場合、サーバーからエラーとそのエラーが発生した場所が返されます。
サーバーを使用して、継続的インテグレーションとデプロイのパイプラインで検証ゲートを作成することもできます。 たとえば、候補のスクリプトでサーバーを起動し、ローカル エンドポイントに対してテスト スイートを実行することができます。
この記事は主に、推論サーバーを使用してローカルでデバッグするユーザーを対象としていますが、推論サーバーとオンライン エンドポイントを併用する方法を理解するのにも役立ちます。
オンライン エンドポイントのローカル デバッグ
エンドポイントをクラウドにデプロイする前にローカルでデバッグすることで、コードと構成のエラーを早期に発見することができます。 エンドポイントをローカルでデバッグするには、次のものを使用できます。
- Azure Machine Learning 推論 HTTP サーバー
- ローカル エンドポイント
この記事では、Azure Machine Learning 推論 HTTP サーバーを重点的に取り上げます。
次の表に、目的に適した方法を選択するのに役立つシナリオの概要を示しています。
| シナリオ | 推論 HTTP サーバー | ローカル エンドポイント |
|---|---|---|
| Docker イメージをリビルドすることなく、ローカルの Python 環境を更新する | はい | いいえ |
| スコアリング スクリプトを更新する | はい | はい |
| デプロイ構成を更新する (デプロイ、環境、コード、モデル) | いいえ | はい |
| VS Code デバッガーを統合する | はい | はい |
推論 HTTP サーバーをローカルで実行すると、デプロイ コンテナーの構成の影響を受けずにスコアリング スクリプトのデバッグに集中できます。
前提条件
- 必須: Python >=3.8
- Anaconda
ヒント
Azure Machine Learning 推論 HTTP サーバーは、Windows と Linux をベースとするオペレーティングシステム上で動作します。
インストール
注意
パッケージの競合を回避するには、仮想環境にサーバーをインストールします。
azureml-inference-server-http package をインストールするには、cmd/terminal で次のコマンドを実行します。
python -m pip install azureml-inference-server-http
スコアリング スクリプトをローカルでデバッグする
スコアリング スクリプトをローカルでデバッグするには、ダミーのスコアリング スクリプトを使用してサーバーがどのように動作するかをテストするか、VS Code を使用し、azureml-inference-server-http パッケージを使ってデバッグするか、サンプル リポジトリ内の実際のスコアリング スクリプト、モデル ファイル、環境ファイルを使用してサーバーをテストすることができます。
ダミーのスコアリング スクリプトを使用してサーバーのビヘイビアーをテストする
ファイルを保持するディレクトリを作成します。
mkdir server_quickstart cd server_quickstartパッケージの競合を回避するには、仮想環境を作成してアクティブにします。
python -m venv myenv source myenv/bin/activateヒント
テストの後に、
deactivateを実行して Python 仮想環境を非アクティブ化します。Pypi フィードから
azureml-inference-server-httpパッケージをインストールします。python -m pip install azureml-inference-server-httpエントリ スクリプトを作成します (
score.py)。 次の例では、基本的なエントリ スクリプトを作成します。echo ' import time def init(): time.sleep(1) def run(input_data): return {"message":"Hello, World!"} ' > score.pyサーバー (azmlinfsrv) を起動し、エントリ スクリプトとして
score.pyを設定します。azmlinfsrv --entry_script score.py注意
サーバーは 0.0.0.0 でホストされます。つまり、ホスト コンピューターのすべての IP アドレスをリッスンします。
curlを使用して、スコアリング要求をサーバーに送信します。curl -p 127.0.0.1:5001/scoreサーバーでは、このように応答する必要があります。
{"message": "Hello, World!"}
テストの後に、Ctrl + C を押してサーバーを終了できます。
これで、サーバーを再度実行して (azmlinfsrv --entry_script score.py)、スコアリング スクリプト (score.py) を変更し、変更をテストできます。
Visual Studio Code と統合する方法
Visual Studio Code (VS Code) と Python Extension を使用し、azureml-inference-server-http パッケージを使用してデバッグするには 2 つの方法があります (起動モードとアタッチ モード)。
起動モード: VS Code で
launch.jsonを設定し、VS Code で Azure Machine Learning 推論 HTTP サーバーを起動します。VS Code を開始し、スクリプト (
score.py) を含むフォルダーを開きます。VS Code のこのワークスペースで、次の構成を
launch.jsonに追加します。launch.json
{ "version": "0.2.0", "configurations": [ { "name": "Debug score.py", "type": "python", "request": "launch", "module": "azureml_inference_server_http.amlserver", "args": [ "--entry_script", "score.py" ] } ] }VS Code でデバッグ セッションを開始します。 [実行] -> [デバッグの開始] (または
F5) を選択します。
アタッチ モード: コマンド ラインで Azure Machine Learning 推論 HTTP サーバーを起動し、VS Code + Python Extension を使用してプロセスにアタッチします。
注意
Linux 環境を使用している場合は、まず
sudo apt-get install -y gdbを実行してgdbパッケージをインストールします。VS Code のこのワークスペースで、次の構成を
launch.jsonに追加します。launch.json
{ "version": "0.2.0", "configurations": [ { "name": "Python: Attach using Process Id", "type": "python", "request": "attach", "processId": "${command:pickProcess}", "justMyCode": true }, ] }CLI (
azmlinfsrv --entry_script score.py) を使用して推論サーバーを開始します。VS Code でデバッグ セッションを開始します。
- VS Code で、[実行] -> [デバッグの開始] (または
F5) を選択します。 - CLI で表示される (推論サーバーからの) ログを使用して、(
gunicornではなく)azmlinfsrvのプロセス ID を入力します。
注意
プロセス ピッカーが表示されない場合は、プロセス ID を
launch.jsonのprocessIdフィールドに手動で入力します。- VS Code で、[実行] -> [デバッグの開始] (または
どちらの方法でも、ブレークポイントを設定し、ステップごとにデバッグすることができます。
エンド ツー エンドの例
このセクションでは、サンプル リポジトリ内のサンプル ファイル (スコアリング スクリプト、モデル ファイル、環境) を使用して、サーバーをローカルで実行します。 このサンプル ファイルは、「オンライン エンドポイントを使用して機械学習モデルをデプロイおよびスコア付けする」の記事でも使用されています
リポジトリを複製します。
git clone --depth 1 https://github.com/Azure/azureml-examples cd azureml-examples/cli/endpoints/online/model-1/conda を使用して仮想環境を作成してアクティブにします。 この例では次のように、
azureml-inference-server-httpパッケージがconda.yml内のazureml-defaultsパッケージの依存ライブラリとして含まれているので自動的にインストールされます。# Create the environment from the YAML file conda env create --name model-env -f ./environment/conda.yml # Activate the new environment conda activate model-envスコアリング スクリプトをレビューします。
onlinescoring/score.py
import os import logging import json import numpy import joblib def init(): """ This function is called when the container is initialized/started, typically after create/update of the deployment. You can write the logic here to perform init operations like caching the model in memory """ global model # AZUREML_MODEL_DIR is an environment variable created during deployment. # It is the path to the model folder (./azureml-models/$MODEL_NAME/$VERSION) # Please provide your model's folder name if there is one model_path = os.path.join( os.getenv("AZUREML_MODEL_DIR"), "model/sklearn_regression_model.pkl" ) # deserialize the model file back into a sklearn model model = joblib.load(model_path) logging.info("Init complete") def run(raw_data): """ This function is called for every invocation of the endpoint to perform the actual scoring/prediction. In the example we extract the data from the json input and call the scikit-learn model's predict() method and return the result back """ logging.info("model 1: request received") data = json.loads(raw_data)["data"] data = numpy.array(data) result = model.predict(data) logging.info("Request processed") return result.tolist()スコアリング スクリプトとモデル ファイルを指定して、推論サーバーを実行します。 指定したモデル ディレクトリ (
model_dirパラメーター) は、スコアリング スクリプト内でAZUREML_MODEL_DIR変数として定義されて取得されます。 ここでは、現在のディレクトリを指定しています (./)。スコアリング スクリプト内でサブディレクトリがmodel/sklearn_regression_model.pklとして指定されているからです。azmlinfsrv --entry_script ./onlinescoring/score.py --model_dir ./正常にサーバーが起動してスコアリング スクリプトが呼び出された場合、サンプルの起動ログが表示されます。 正常に実行されなかった場合、ログにエラー メッセージが表示されます。
サンプル データを使用してスコアリング スクリプトをテストします。 別のターミナルを開き、同じ作業ディレクトリに移動してコマンドを実行します。
curlコマンドを使用して、サンプルの要求をサーバーに送信し、スコアリング結果を受け取ります。curl --request POST "127.0.0.1:5001/score" --header "Content-Type:application/json" --data @sample-request.jsonスコアリング スクリプトに問題がない場合は、スコアリング結果が返されます。 問題が見つかった場合は、スコアリング スクリプトを更新し、サーバーをもう一度起動して、更新したスクリプトをテストしてみることができます。
サーバー ルート
サーバーは、これらのルートでポート 5001 (既定値) でリッスンしています。
| Name | ルート |
|---|---|
| Liveness Probe | 127.0.0.1:5001/ |
| Score | 127.0.0.1:5001/score |
| OpenAPI (swagger) | 127.0.0.1:5001/swagger.json |
サーバー パラメーター
次の表に、サーバーで受け入れられるパラメーターを示します。
| パラメーター | 必須 | Default | 説明 |
|---|---|---|---|
| entry_script | True | 該当なし | スコアリング スクリプトへの相対または絶対パス。 |
| model_dir | × | 該当なし | 推論に使用されるモデルを保持するディレクトリへの相対または絶対パス。 |
| port | False | 5001 | サーバーのサービス ポート。 |
| worker_count | False | 1 | 同時要求を処理するワーカー スレッドの数。 |
| appinsights_instrumentation_key | × | 該当なし | ログが発行されるアプリケーション分析情報へのインストルメンテーション キー。 |
| access_control_allow_origins | False | 該当なし | 指定したオリジンについて CORS を有効にします。 "," で複数のオリジンを区切ります。 例: "microsoft.com, bing.com" |
要求フロー
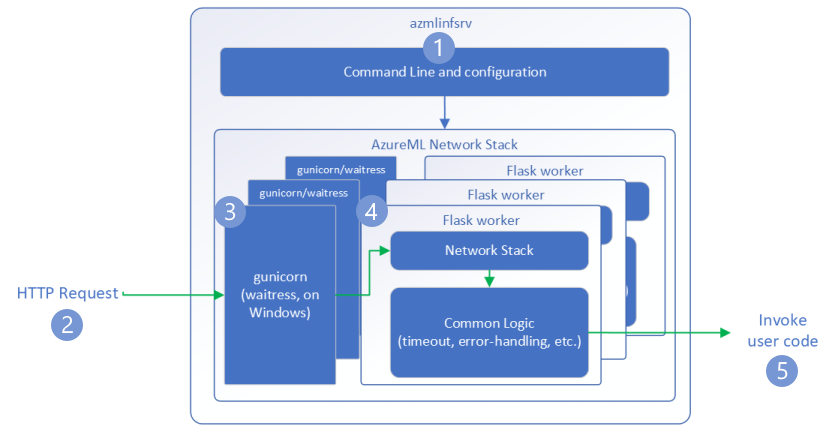
次のステップでは、Azure Machine Learning 推論 HTTP サーバー (azmlinfsrv) で受信要求を処理する方法について説明します。
- Python CLI ラッパーは、サーバーのネットワーク スタックの周囲に置かれ、サーバーを起動するために使用されます。
- クライアントからサーバーに要求が送信されます。
- 要求は受信されると、WSGI サーバーを経由し、いずれかのワーカーにディスパッチされます。
- 次に、要求は Flask アプリによって処理されます。これにより、エントリ スクリプトとすべての依存関係を読み込みます。
- 最後に、要求は入力スクリプトに送信されます。 次に、エントリ スクリプトは、読み込まれたモデルへの推論の呼び出しを行い、応答を返します。
ログの理解
ここでは Azure Machine Learning 推論 HTTP サーバーのログについて説明します。 ローカルで azureml-inference-server-http を実行するときにログを取得することも、オンライン エンドポイントを使用している場合にコンテナー ログを取得することもできます。
注意
バージョン 0.8.0 以降、ログ形式が変更されています。 別のスタイルのログが見つかった場合は、azureml-inference-server-http パッケージを最新バージョンに更新してください。
ヒント
オンライン エンドポイントを使用している場合、推論サーバーからのログの先頭が Azure Machine Learning Inferencing HTTP server <version> になります。
起動ログ
サーバーを開始すると、ログでサーバー設定が最初に次のように表示されます。
Azure Machine Learning Inferencing HTTP server <version>
Server Settings
---------------
Entry Script Name: <entry_script>
Model Directory: <model_dir>
Worker Count: <worker_count>
Worker Timeout (seconds): None
Server Port: <port>
Application Insights Enabled: false
Application Insights Key: <appinsights_instrumentation_key>
Inferencing HTTP server version: azmlinfsrv/<version>
CORS for the specified origins: <access_control_allow_origins>
Server Routes
---------------
Liveness Probe: GET 127.0.0.1:<port>/
Score: POST 127.0.0.1:<port>/score
<logs>
たとえば、エンド ツー エンドの例に従ってサーバーを起動すると、次のようになります。
Azure Machine Learning Inferencing HTTP server v0.8.0
Server Settings
---------------
Entry Script Name: /home/user-name/azureml-examples/cli/endpoints/online/model-1/onlinescoring/score.py
Model Directory: ./
Worker Count: 1
Worker Timeout (seconds): None
Server Port: 5001
Application Insights Enabled: false
Application Insights Key: None
Inferencing HTTP server version: azmlinfsrv/0.8.0
CORS for the specified origins: None
Server Routes
---------------
Liveness Probe: GET 127.0.0.1:5001/
Score: POST 127.0.0.1:5001/score
2022-12-24 07:37:53,318 I [32726] gunicorn.error - Starting gunicorn 20.1.0
2022-12-24 07:37:53,319 I [32726] gunicorn.error - Listening at: http://0.0.0.0:5001 (32726)
2022-12-24 07:37:53,319 I [32726] gunicorn.error - Using worker: sync
2022-12-24 07:37:53,322 I [32756] gunicorn.error - Booting worker with pid: 32756
Initializing logger
2022-12-24 07:37:53,779 I [32756] azmlinfsrv - Starting up app insights client
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - Found user script at /home/user-name/azureml-examples/cli/endpoints/online/model-1/onlinescoring/score.py
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - run() is not decorated. Server will invoke it with the input in JSON string.
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - Invoking user's init function
2022-12-24 07:37:55,974 I [32756] azmlinfsrv.user_script - Users's init has completed successfully
2022-12-24 07:37:55,976 I [32756] azmlinfsrv.swagger - Swaggers are prepared for the following versions: [2, 3, 3.1].
2022-12-24 07:37:55,977 I [32756] azmlinfsrv - AML_FLASK_ONE_COMPATIBILITY is set, but patching is not necessary.
ログの形式
推論サーバーからのログは、次の形式で生成されます。ただしランチャー スクリプトは Python パッケージに含まれていないので除きます。
<UTC Time> | <level> [<pid>] <logger name> - <message>
<pid> はプロセス ID で、<level> はログ レベルの最初の文字です。エラーの場合は E、INFO の場合は I などです。
Python には次の 6 つのレベルのログがあり、数値が重大度に関連付けられています。
| ログ記録レベル | 数値 |
|---|---|
| 重大 | 50 |
| ERROR | 40 |
| WARNING | 30 |
| INFO | 20 |
| DEBUG | 10 |
| NOTSET | 0 |
トラブルシューティング ガイド
このセクションでは、Azure Machine Learning 推論 HTTP サーバーの基本的なトラブルシューティングのヒントについて説明します。 オンライン エンドポイントのトラブルシューティングを行う場合は、オンライン エンドポイントのデプロイのトラブルシューティングに関する記事も参照してください
基本的な手順
トラブルシューティングの基本的なステップは次のとおりです。
- Python 環境のバージョン情報を収集します。
- 環境ファイル内で指定されている Python パッケージ azureml-inference-server-http のバージョンが、起動ログに表示される AzureML 推論 HTTP サーバーのバージョンと一致していることを確認します。 PIP の依存関係リゾルバーにより、予期しないバージョンのパッケージがインストールされる場合があります。
- ご利用の環境で Flask (やその依存関係) を指定している場合は、それらを削除します。 依存関係には
Flask、Jinja2、itsdangerous、Werkzeug、MarkupSafe、clickが含まれます。 Flask はサーバー パッケージ内の依存関係としてリストされ、サーバーにインストールするよう推奨されています。 こうすると、サーバーで新しいバージョンの Flask がサポートされると自動的に取得できます。
サーバーのバージョン
サーバー パッケージ azureml-inference-server-http が PyPI に公開されています。 PyPI ページで、変更ログとすべての旧バージョンを確認できます。 以前のバージョンを使用している場合は、最新バージョンに更新します。
- 0.4.x:
20220601以下のトレーニング イメージおよぴazureml-defaults>=1.34,<=1.43にバンドルされているバージョン。0.4.13が最新の安定バージョンです。 バージョン0.4.11より前のサーバーを使用すると、名前Markupをjinja2からインポートできないなどの Flask の依存関係の問題が示される場合があります。 可能であれば、0.4.13または0.8.x(最新バージョン) にアップグレードすることをお勧めします。 - 0.6.x: 推論イメージ 20220516 以下にプレインストールされているバージョン。 最新の安定バージョンは
0.6.1です。 - 0.7.x: Flask 2 をサポートする最初のバージョン。 最新の安定バージョンは
0.7.7です。 - 0.8.x: ログ形式が変更され、Python 3.6 のサポートがドロップされました。
パッケージの依存関係
サーバー azureml-inference-server-http に最も関連のあるパッケージは、次のパッケージです。
- flask
- opencensus-ext-azure
- inference-schema
Python 環境で azureml-defaults を指定した場合、azureml-inference-server-http パッケージが依存しており、自動的にインストールされます。
ヒント
Python SDK v1 を使用していて、Python 環境で azureml-defaults を明示的に指定しない場合、SDK によりパッケージが追加される場合があります。 しかし、SDK のバージョンに固定されます。 たとえば、SDK のバージョンが1.38.0 の場合、この環境の PIP 要件に azureml-defaults==1.38.0 が追加されます。
よく寄せられる質問
1. サーバーの起動時に次のエラーが発生しました:
TypeError: register() takes 3 positional arguments but 4 were given
File "/var/azureml-server/aml_blueprint.py", line 251, in register
super(AMLBlueprint, self).register(app, options, first_registration)
TypeError: register() takes 3 positional arguments but 4 were given
Python 環境に Flask 2 がインストールされているが、Flask 2 をサポートしていないバージョンの azureml-inference-server-http が実行されています。 Flask 2 のサポートも azureml-inference-server-http>=0.7.0 に追加されています。これは azureml-defaults>=1.44 にも追加されています。
AzureML Docker イメージでこのパッケージを使用していない場合、
azureml-inference-server-httpまたはazureml-defaultsの最新バージョンを使用します。AzureML Docker イメージでこのパッケージを使用している場合は、2022 年 7 月以降にビルドされたイメージを使用していることを確認してください。イメージのバージョンは、コンテナー ログで確認できます。 次のようなログが見つかるはずです。
2022-08-22T17:05:02,147738763+00:00 | gunicorn/run | AzureML Container Runtime Information 2022-08-22T17:05:02,161963207+00:00 | gunicorn/run | ############################################### 2022-08-22T17:05:02,168970479+00:00 | gunicorn/run | 2022-08-22T17:05:02,174364834+00:00 | gunicorn/run | 2022-08-22T17:05:02,187280665+00:00 | gunicorn/run | AzureML image information: openmpi4.1.0-ubuntu20.04, Materializaton Build:20220708.v2 2022-08-22T17:05:02,188930082+00:00 | gunicorn/run | 2022-08-22T17:05:02,190557998+00:00 | gunicorn/run |イメージのビルド日は、上の例では
20220708または 2022 年 7 月 8 日と、"Materialization Build" の後に表示されます。 このイメージは Flask 2 と互換性があります。 このようなバナーがコンテナー ログに表示されない場合、イメージは古く、更新する必要があります。 CUDA イメージを使用していて、新しいイメージが見つからない場合は、AzureML-Containers でイメージが非推奨になっていないかを検査してください。 その場合は、代わりのものを見つけることができるはずです。サーバーとオンライン エンドポイントを併用している場合は、Azure Machine Learning スタジオのオンライン エンドポイント ページの [デプロイ ログ] の下にログを見つけることができます。 SDK v1 を使用してデプロイし、デプロイ構成でイメージを明示的に指定しない場合、既定ではローカル SDK ツールセットに一致するバージョンの
openmpi4.1.0-ubuntu20.04が使用されます。これは、イメージの最新バージョンではない可能性があります。 たとえば、SDK 1.43 では既定でopenmpi4.1.0-ubuntu20.04:20220616が使用され、これには互換性がありません。 デプロイに最新の SDK を使用していることを確認します。何らかの理由でイメージを更新できない場合は、
azureml-defaults==1.43またはazureml-inference-server-http~=0.4.13をピン留めして、Flask 1.0.xを備えた古いバージョンのサーバーをインストールすることで、問題を一時的に回避できます。
2. 起動時にモジュール opencensus、jinja2、MarkupSafe、または click で、次のようなメッセージを含む ImportError または ModuleNotFoundError が発生しました。
ImportError: cannot import name 'Markup' from 'jinja2'
以前のバージョン (<= 0.4.10) のサーバーでは、Flask の依存関係が互換性のあるバージョンにピン留めされませんでした。 この問題は、最新バージョンのサーバーで修正されています。
次のステップ
- 入力スクリプトの作成とモデルのデプロイの詳細については、「Azure Machine Learning を使用してモデルをデプロイする方法」に関するページを参照してください。
- 推論用の事前構築済み Docker イメージについて説明します