Azure Machine Learning のアルゴリズムの選択方法
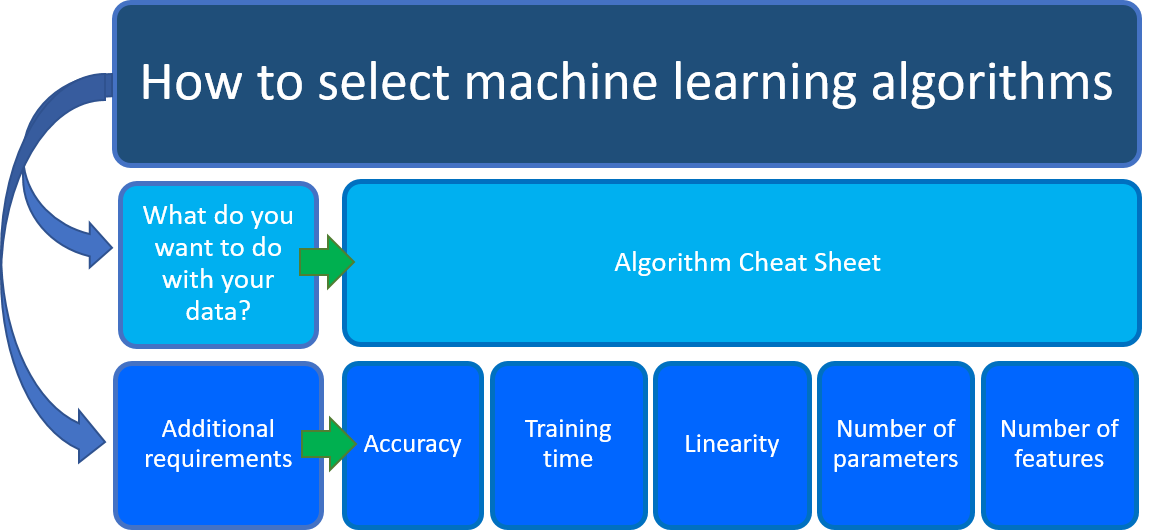
よくある質問は、「どの機械学習アルゴリズムを使用すればよいか」ということです。 選択するアルゴリズムは、主として、データ サイエンス シナリオの次の 2 つの異なる側面によって決まります。
データを使って何をしたいか? 具体的には、過去のデータから学習することによって回答を得たいビジネス上の質問は何かということです。
データ サイエンス シナリオの要件は何か? 具体的には、ソリューションでサポートする精度、トレーニング時間、線形性、パラメーターの数、特徴の数はどのくらいかということです。
Note
デザイナーは、従来の事前構築済みコンポーネント (v1) とカスタム コンポーネント (v2) の 2 種類のコンポーネントをサポートします。 これら 2 種類のコンポーネントには互換性がありません。
従来の事前構築済みコンポーネントは、主にデータ処理や、回帰や分類などの従来の機械学習タスク向けの事前構築済みのコンポーネントを提供します。 この種類のコンポーネントは引き続きサポートされますが、新しいコンポーネントは追加されません。
カスタム コンポーネントを使用すると、独自のコードをコンポーネントとしてラップすることができます。 これは、ワークスペース間での共有と、Studio、CLI v2、SDK v2 インターフェイス間でのシームレスなオーサリングをサポートします。
新しいプロジェクトでは、AzureML V2 と互換性があり、新しく更新され続けるカスタム コンポーネントを使用することを強くお勧めします。
この記事は、CLI v2 および SDK v2 と互換性のない、従来の事前構築済みコンポーネントに適用されます。
ビジネス シナリオと機械学習アルゴリズム チート シート
Azure Machine Learning アルゴリズム チート シートは、最初の考慮事項である、「データを使って何をしたいか」について検討するのに役立ちます。 Machine Learning アルゴリズム チート シートで、目的のタスクを探して、予測分析ソリューション用の Azure Machine Learning デザイナーのアルゴリズムを見つけます。
Machine Learning デザイナーは、多クラス デシジョン フォレスト、レコメンデーション システム、ニューラル ネットワーク回帰、多クラス ニューラル ネットワーク、K-Means クラスタリングなどのアルゴリズムの包括的なポートフォリオを提供します。 各アルゴリズムは、機械学習の異なる種類の問題に対処するように設計されています。 完全な一覧、各アルゴリズムのしくみとパラメーターを調整してアルゴリズムを最適化する方法に関するドキュメントについては、Machine Learning デザイナーのアルゴリズムとコンポーネントのリファレンスに関するページを参照してください。
注意
チート シートをダウンロードする: Machine Learning アルゴリズム チート シート (11 x 17 インチ)
ソリューションの機械学習アルゴリズムを選択する際には、Azure Machine Learning アルゴリズム チート シートのガイダンスと合わせて、他の要件にも留意してください。 精度、トレーニング時間、線形性、パラメーターの数、特徴の数など、考慮する必要がある追加の要素を次に示します。
機械学習アルゴリズムの比較
一部の学習アルゴリズムは、データの構造や目的の結果について特定の想定をします。 ニーズに合うものが見つかれば、より役に立つ結果や正確な予測が得られたり、トレーニングが短時間で済みます。
次の表に、分類、回帰、クラスタリングの各ファミリから、アルゴリズムの最も重要な特性をまとめています。
| アルゴリズム | 精度 | トレーニング時間 | 線形性 | パラメーター | メモ |
|---|---|---|---|---|---|
| 分類ファミリ | |||||
| 2 クラス ロジスティック回帰 | [良い] | 速い | はい | 4 | |
| 2 クラス デシジョン フォレスト | [非常に良い] | 中 | いいえ | 5 | スコア付け時間が遅いことを示します。 スコア付け時間が遅くなるのは、蓄積されたツリー予測でスレッドがロックされることに起因するため、One-vs-All Multiclass を使用しないことをお勧めします。 |
| 2 クラスの増幅デシジョン ツリー | [非常に良い] | 中 | いいえ | 6 | メモリ フットプリントが大きい |
| 2 クラス ニューラル ネットワーク | [良い] | 中 | いいえ | 8 | |
| 2 クラス平均化パーセプトロン | [良い] | 中 | はい | 4 | |
| 2 クラス サポート ベクター マシン | [良い] | 速い | はい | 5 | 大きい特徴セットに好適 |
| 多クラスのロジスティック回帰 | [良い] | 速い | はい | 4 | |
| 多クラス デシジョン フォレスト | [非常に良い] | 中 | いいえ | 5 | スコア付け時間が遅いことを示します |
| 多クラスの増幅デシジョン ツリー | [非常に良い] | 中 | いいえ | 6 | 適用範囲が狭いという小さなリスクがありますが、精度を上げる傾向があります |
| 多クラス ニューラル ネットワーク | [良い] | 中 | いいえ | 8 | |
| One-vs-All Multiclass | - | - | - | - | 選択した 2 クラス法のプロパティを参照してください |
| 回帰ファミリ | |||||
| 線形回帰 | [良い] | 速い | はい | 4 | |
| デシジョン フォレスト回帰 | [非常に良い] | 中 | いいえ | 5 | |
| 増幅デシジョン ツリーの回帰 | [非常に良い] | 中 | いいえ | 6 | メモリ フットプリントが大きい |
| ニューラル ネットワーク回帰 | [良い] | 中 | いいえ | 8 | |
| クラスタリング ファミリ | |||||
| K-Means クラスタリング | [非常に良い] | 中 | はい | 8 | クラスタリング アルゴリズム |
データ サイエンス シナリオの要件
データを使って何をやりたいかがわかったら、ソリューションの追加要件を決定する必要があります。
次の要件を選択します。これらの間にはトレードオフが生じる可能性があります。
- 精度
- トレーニング時間
- 線形性
- パラメーターの数
- 特徴の数
精度
機械学習の精度では、すべてのケースに対する真の結果の割合として、モデルの有効性を測定します。 Machine Learning デザイナーでは、モデルの評価コンポーネントで業界標準の一連の評価メトリックを計算します。 トレーニング済みのモデルの精度は、このコンポーネントで測定できます。
可能な限り最も正確な回答を得ることが常に必要であるとは限りません。 使用目的によっては、近似で十分な場合があります。 その場合は、より近似的な方法を使用することで、処理時間を大幅に短縮できる場合があります。 さらに、近似的な方法には、当然ながらオーバーフィットを回避する傾向があります。
モデルの評価コンポーネントは、次の 3 つの用途に使用できます。
- モデルを評価するために、トレーニング データのスコアを生成する
- モデルでスコアを生成するが、これらのスコアを予約済みのテスト セットでのスコアと比較する
- 同じデータ セットを使用して、2 つの異なるが関連するモデルのスコアを比較する
機械学習モデルの精度を評価するために使用できるメトリックとアプローチの完全な一覧については、モデルの評価コンポーネントに関するページを参照してください。
トレーニング時間
教師あり学習の場合、トレーニングは、履歴データを使用してエラーを最小限に抑える機械学習モデルを構築することを意味します。 モデルのトレーニングに必要な分数または時間数は、アルゴリズムによって大きく異なります。 多くの場合、トレーニング時間は精度と密接に関係しており、通常、片方があれば他方も伴います。
さらに、一部のアルゴリズムは他よりデータ ポイントの数に大きく影響を受けます。 時間に制限があるため、特にデータ セットが大きい場合、特定のアルゴリズムを選択することもできます。
Machine Learning デザイナーでは、機械学習モデルの作成と使用は、通常、3 つのステップから成るプロセスです。
特定の種類のアルゴリズムを選択し、そのパラメーターまたはハイパーパラメーターを定義してモデルを構成します。
ラベル付けされていて、かつアルゴリズムに適合したデータを含んだデータセットを指定します。 データとモデルの両方をモデルのトレーニング コンポーネントに接続します。
トレーニングが完了したら、いずれかのスコアリング コンポーネントでトレーニング済みのモデルを使用し、新しいデータの予測を行います。
線形性
統計および機械学習では、線形性は、データ セット内の変数と定数の間に線形関係があることを意味します。 たとえば、線形分類アルゴリズムは、クラスを直線 (またはその高次元版) で分離できることを想定しています。
機械学習アルゴリズムの多くは線形性を使用します。 Azure Machine Learning デザイナーでは、このようなアルゴリズムとして次のものがあります。
線形回帰アルゴリズムは、データの傾向が直線に従うことを想定しています。 問題によって、この想定が適切な場合もありますが、精度が低下することもあります。 線形回帰アルゴリズムは、欠点はあっても、最初の戦略として一般的です。 アルゴリズムが簡単で、速くトレーニングできる傾向があります。
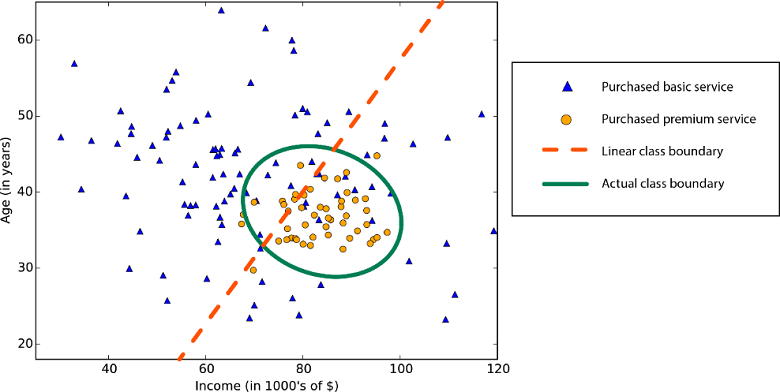
非線形クラス境界: 線形分類アルゴリズムに従うと精度が低下します。

非線形傾向のデータ: 線形回帰法を使用すると、必要以上に多くのエラーが生成されます。
パラメーターの数
パラメーターは、アルゴリズムを設定するときに使用します。 エラーの許容誤差や反復回数などのアルゴリズムの動作に影響を与える数値、またはアルゴリズムの動作方法のバリエーション間で設定するオプションです。 アルゴリズムのトレーニング時間と精度は、適切な設定を行うかどうかによって影響を受ける場合があります。 通常、パラメーター数の多いアルゴリズムは、適切な組み合わせを見つけるのに多くの試行錯誤が必要です。
または Machine Learning デザイナーにはモデルのハイパーパラメーターの調整コンポーネントがあります。このコンポーネントの目的は、機械学習モデルに最適なハイパーパラメーターを決定することです。 このコンポーネントでは、さまざまな設定の組み合わせを使用し、複数のモデルをビルドおよびテストします。 その後、すべてのモデルについてメトリックを比較し、設定の組み合わせを求めます。
これは、パラメーター空間を確実に網羅する優れた方法ですが、パラメーターの数が増えるとモデルのトレーニングに必要な時間が指数関数的に増加します。 利点として、通常、パラメーターの数の多さはアルゴリズムがより柔軟であることを示します。 適切なパラメーター設定の組み合わせを見つけられる場合に、非常に高い精度を示すことが多くあります。
特徴の数
機械学習の場合、特徴は、分析しようとしている現象の定量化可能な変数です。 特定の種類のデータでは、特徴の数がデータ ポイントの数と比較して非常に大きくなる可能性があります。 遺伝学やテキスト データの場合によくあります。
特徴の数が多いと、一部の学習アルゴリズムは処理が遅くなり、実行不可能なほどトレーニング時間が長くなります。 サポート ベクトル マシンは、特徴の数が多いシナリオに特に適しています。 このため、情報の取得からテキストおよびイメージの分類まで、数多くのアプリケーションで使用されています。 サポート ベクトル マシンは、分類タスクと回帰タスクの両方に使用できます。
特徴選択とは、指定された出力を前提として、統計的テストを入力に適用するプロセスを指します。 この目標は、出力の予測能力が高い列を特定することです。 Machine Learning デザイナーのフィルターに基づく特徴選択コンポーネントには、選択可能な複数の特徴選択アルゴリズムがあります。 このコンポーネントには、ピアソンの相関やカイ二乗値などの相関法が含まれています。
順列の特徴量の重要度コンポーネントを使用して、お使いのデータ セットの一連の特徴量の重要度スコアを計算することもできます。 これらのスコアを利用すると、モデルで使用する最適な特徴を決定するのに役立ちます。
次のステップ
- Azure Machine Learning デザイナーの詳細
- Azure Machine Learning デザイナーで使用可能なすべての機械学習アルゴリズムの詳細については、Machine Learning デザイナーのアルゴリズムとコンポーネントのリファレンスに関するページを参照してください。
- ディープ ラーニング、機械学習、AI の関係を調べるには、「ディープ ラーニングと機械学習」を参照してください