Kubernetes コンピューティングのトラブルシューティング
この記事では、Kubernetes コンピューティングでの一般的なワークロード エラーのトラブルシューティングを行う方法について説明します。 一般的なエラーには、トレーニング ジョブとエンドポイント エラーが含まれます。
推論ガイド
Kubernetes コンピューティングでの一般的な Kubernetes エンドポイントのエラーは、コンピューティング スコープとクラスター スコープの 2 つのスコープに分類されます。 コンピューティング スコープのエラーは、コンピューティング先が見つからない、コンピューティング先にアクセスできないなど、コンピューティング先に関連しています。 クラスター スコープのエラーは、クラスター自体に到達できない、クラスターが見つからないなど、基になる Kubernetes クラスターに関連しています。
Kubernetes コンピューティング エラー
Kubernetes コンピューティングを使用してリアルタイム モデル推論用のオンライン エンドポイントとオンライン デプロイを作成するときに発生する可能性がある、コンピューティング スコープの一般的なエラーの種類を以下に示します。 トラブルシューティングを行うには、ガイドラインのリンクされたセクションに従います。
- エラー: GenericComputeError
- エラー: ComputeNotFound
- エラー: ComputeNotAccessible
- エラー: InvalidComputeInformation
- エラー: InvalidComputeNoKubernetesConfiguration
エラー: GenericComputeError
エラー メッセージは次のとおりです。
Failed to get compute information.
このエラーは、システムが Kubernetes クラスターからコンピューティング情報を取得できなかったときに発生します。 次の項目を確認して、問題をトラブルシューティングできます。
- Kubernetes クラスターの状態を確認します。 クラスターが実行されていない場合は、まずクラスターを起動する必要があります。
- Kubernetes クラスターの正常性を確認します。
- クラスターの正常性チェック レポートで、クラスターに到達できない場合などの問題を確認できます。
- ワークスペース ポータルに移動して、コンピューティングの状態を確認できます。
- インスタンスの種類情報が正しいかどうかを確認します。 サポートされているインスタンスの種類は、Kubernetes コンピューティングのドキュメントで確認できます。
- 可能な場合は、コンピューティングをデタッチしてワークスペースに再アタッチしてみてください。
注意
再アタッチしてエラーをトラブルシューティングするには、必ず前にデタッチしたコンピューティングと厳密に同じ構成 (同じコンピューティング名や名前空間など) を使用して再アタッチしてください。そうしないと、他のエラーが発生する場合があります。
エラー: ComputeNotFound
エラー メッセージは次のとおりです。
Cannot find Kubernetes compute.
このエラーが発生するのは、次のときです。
- 新しいオンライン エンドポイント/デプロイを作成/更新するときに、システムでコンピューティングが見つからない。
- 既存のオンライン エンドポイント/デプロイのコンピューティングが削除された。
次の項目を確認して、問題をトラブルシューティングできます。
- エンドポイントとデプロイを再作成してみてください。
- コンピューティングをデタッチしてワークスペースに再アタッチしてみてください。 再アタッチに関する追加の注記に注意してください。
エラー: ComputeNotAccessible
エラー メッセージは次のとおりです。
The Kubernetes compute is not accessible.
このエラーは、ワークスペース MSI (マネージド ID) に AKS クラスターへのアクセス権がないときに発生します。 ワークスペース MSI に AKS へのアクセス権があるかどうかを確認できます。ない場合は、このドキュメントに従って、アクセス権と ID を管理できます。
エラー: InvalidComputeInformation
エラー メッセージは次のとおりです。
The compute information is invalid.
Kubernetes クラスターにモデルをデプロイするときに、コンピューティング先の検証プロセスがあります。 このエラーは、コンピューティング情報が無効な場合に発生します。 たとえば、コンピューティング先が見つからないか、Kubernetes クラスターで Azure Machine Learning 拡張機能の構成が更新された場合です。
次の項目を確認して、問題をトラブルシューティングできます。
- 使用したコンピューティング先が正しいかどうかと、ワークスペースに存在かどうかを確認してください。
- コンピューティングをデタッチしてワークスペースに再アタッチしてみてください。 再アタッチに関する追加の注記に注意してください。
エラー: InvalidComputeNoKubernetesConfiguration
エラー メッセージは次のとおりです。
The compute kubeconfig is invalid.
このエラーは、次のようなクラスターに接続する構成がシステムで見つからなかった場合に発生します。
- Arc-Kubernetes クラスターの場合、Azure Relay 構成が見つかりません。
- AKS クラスターの場合、AKS 構成が見つかりません。
クラスター内のコンピューティング接続の構成を再構築するために、ワークスペースに対してコンピューティングのデタッチと再アタッチを試みることができます。 再アタッチに関する追加の注記に注意してください。
Kubernetes クラスター エラー
Kubernetes コンピューティングを使用してリアルタイム モデル推論用のオンライン エンドポイントとオンライン デプロイを作成するときに発生する可能性があるクラスター スコープのエラーの種類の一覧を以下に示します。これは、ガイドラインに従うことでトラブルシューティングできます。
エラー: GenericClusterError
エラー メッセージは次のとおりです。
Failed to connect to Kubernetes cluster: <message>
このエラーは、不明な理由でシステムが Kubernetes クラスターに接続できなかったときに発生します。 次の項目を確認して、問題をトラブルシューティングできます。
AKS クラスターの場合
- AKS クラスターがシャットダウンされているかどうかを確認します。
- クラスターが実行されていない場合は、まずクラスターを起動する必要があります。
- AKS クラスターで、承認された IP 範囲を使用して選択したネットワークが有効になっているかどうかを確認します。
- AKS クラスターで承認された IP 範囲が有効になっている場合は、AKS クラスターに対してすべての Azure Machine Learning コントロール プレーンの IP 範囲が有効になっていることを確認してください。 詳しくは、こちらのドキュメントをご覧ください。
AKS クラスターまたは Azure Arc 対応 Kubernetes クラスターの場合
- クラスターで
kubectlコマンドを実行して、Kubernetes API サーバーにアクセスできるかどうかを確認します。
エラー: ClusterNotReachable
エラー メッセージは次のとおりです。
The Kubernetes cluster is not reachable.
このエラーは、システムがクラスターに接続できないときに発生します。 次の項目を確認して、問題をトラブルシューティングできます。
AKS クラスターの場合
- AKS クラスターがシャットダウンされているかどうかを確認します。
- クラスターが実行されていない場合は、まずクラスターを起動する必要があります。
AKS クラスターまたは Azure Arc 対応 Kubernetes クラスターの場合
- クラスターで
kubectlコマンドを実行して、Kubernetes API サーバーにアクセスできるかどうかを確認します。
エラー: ClusterNotFound
エラー メッセージは次のとおりです。
Cannot found Kubernetes cluster.
このエラーは、システムで AKS/Arc-Kubernetes クラスターが見つからない場合に発生します。
次の項目を確認して、問題をトラブルシューティングできます。
- まず、Azure portal のクラスター リソース ID を確認して、Kubernetes クラスター リソースが引き続き存在し、正常に実行されているかどうかを確認します。
- クラスターが存在し、実行されている場合は、ワークスペースに対してコンピューティングのデタッチと再アタッチを試みることができます。 再アタッチに関する追加の注記に注意してください。
ヒント
Kubernetes オンライン エンドポイントとデプロイを作成または更新するときの一般的なエラーの詳細なトラブルシューティング ガイドについては、オンライン エンドポイントのトラブルシューティング方法に関する記事を参照してください。
ID エラー
ERROR: RefreshExtensionIdentityNotSet
このエラーは、拡張機能がインストールされていても、拡張機能 ID が正しく割り当てられない場合に発生します。 拡張機能を再インストールして修正することを試せます。
このエラーはマネージド クラスターでのみ発生することに注意してください
sslCertPemFile と sslKeyPemFile が正しいことを確認する方法
既知のエラーが表示されるようにするには、コマンドを使用して証明書とキーのベースライン チェックを実行します。 2 番目のコマンドでは、パスワードの入力を求めずに "RSA キー OK" が返されることが予期されます。
openssl x509 -in cert.pem -noout -text
openssl rsa -in key.pem -noout -check
以下のコマンドを実行して、sslCertPemFile と sslKeyPemFile が対応しているかどうかを確認します。
openssl x509 -in cert.pem -noout -modulus | md5sum
openssl rsa -in key.pem -noout -modulus | md5sum
sslCertPemFile の場合は、パブリック証明書です。 これには、次の証明書を含む証明書チェーンが含まれ、サーバー証明書、中間 CA 証明書、ルート CA 証明書のシーケンスに含まれている必要があります。
- サーバー証明書: サーバーは、TLS ハンドシェイク中にクライアントに提示します。 サーバーの公開キー、ドメイン名、およびその他の情報が含まれています。 サーバー証明書は、サーバーの ID を保証する中間証明機関 (CA) によって署名されます。
- 中間 CA 証明書: 中間 CA は、サーバー証明書に署名する権限を証明するためにクライアントに提示します。 中間 CA の公開キー、名前、およびその他の情報が含まれています。 中間 CA 証明書は、中間 CA の ID を保証するルート CA によって署名されます。
- ルート CA 証明書: ルート CA は、中間 CA 証明書に署名する権限を証明するためにクライアントに提示します。 ルート CA の公開キー、名前、およびその他の情報が含まれています。 ルート CA 証明書は自己署名され、クライアントによって信頼されます。
トレーニング ガイド
トレーニング ジョブの実行中に、ワークスペース ポータルでジョブの状態をチェックできます。 ジョブが複数回再試行されている、ジョブが初期化状態でスタックしている、ジョブが最終的に失敗したなど、異常なジョブの状態が発生した場合は、ガイドに従って問題のトラブルシューティングを行うことができます。
ジョブ再試行のデバッグ
クラスターで実行されているトレーニング ジョブ ポッドが、ノードの OOM (メモリー不足) が原因で終了した場合、ジョブは別の使用可能なノードで自動的に再試行されます。
ジョブ試行の根本原因をさらにデバッグするには、ワークスペース ポータルに移動してジョブの再試行ログを確認します。
- 各再試行ログは、"retry-<retry number>"(retry-001 など) の形式で新しいログ フォルダーに記録されます。
その後、再試行ジョブ ノード マッピング情報を取得して、再試行ジョブが実行されているノードを把握できます。
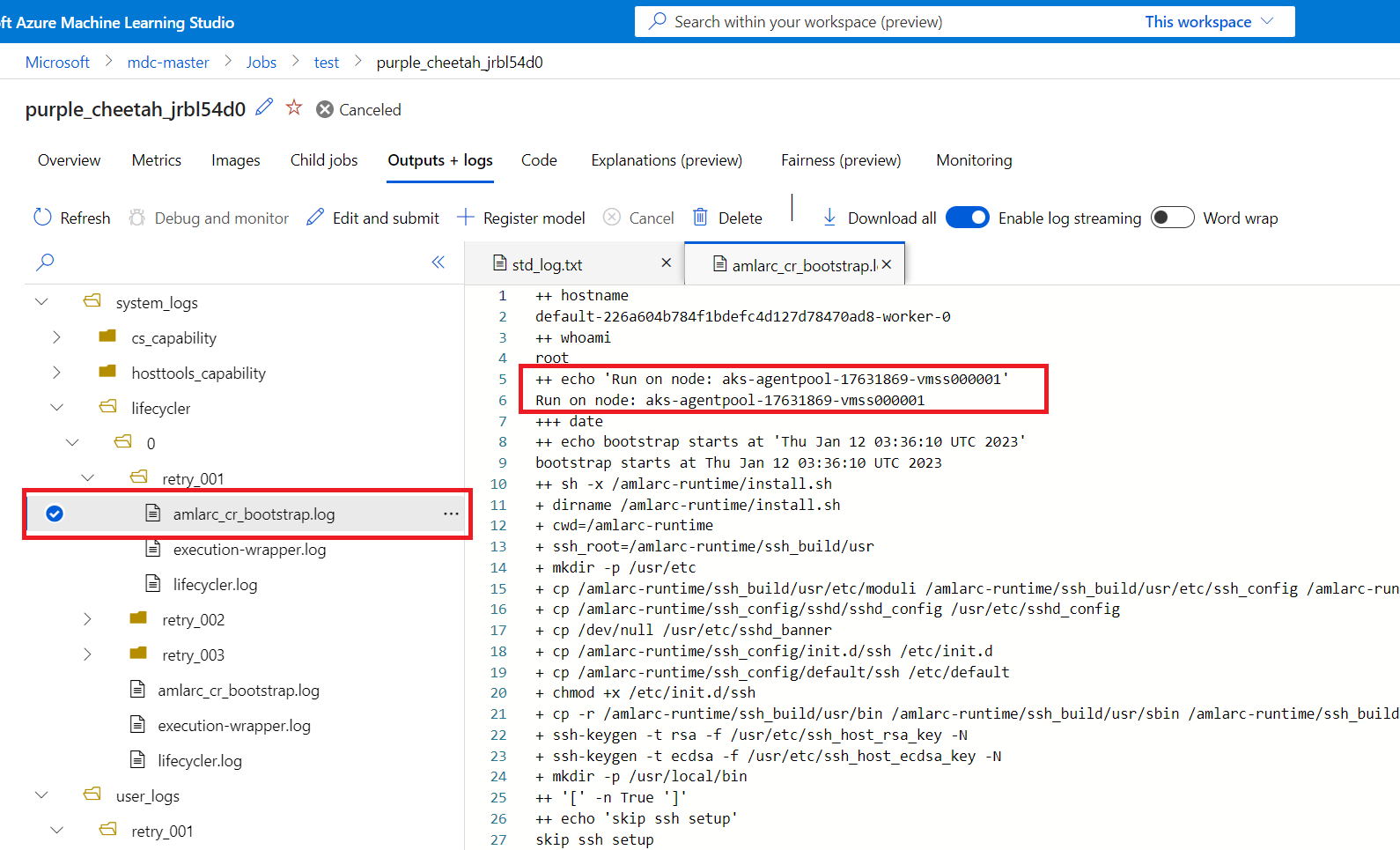
ジョブ ノード マッピング情報は、system_logs フォルダーの amlarc_cr_bootstrap.log から取得できます。
ジョブ ポッドが実行されているノードのホスト名は、たとえば次のように、このログ内に示されます。
++ echo 'Run on node: ask-agentpool-17631869-vmss0000"
"ask-agentpool-17631869-vmss0000" は、AKS クラスターでこのジョブを実行しているノード ホスト名を表します。 その後、クラスターにアクセスしてノードの状態を確認し、さらに調査を行うことができます。
ジョブ ポッドが初期化状態のままになる
ジョブの実行時間が予想よりも長く、この警告 Unable to attach or mount volumes: *** failed to get plugin from volumeSpec for volume ***-blobfuse-*** err=no volume plugin matched でジョブ ポッドが初期化状態のままになっている場合は、Azure Machine Learning 拡張機能が入力データのダウンロード モードをサポートしていないために問題が発生している可能性があります。
この問題を解決するには、入力データのマウント モードに切り替えします。
一般的なジョブ失敗のエラー
下のリストに、Kubernetes コンピューティングを使用してトレーニング ジョブを作成および実行する際に発生する可能性がある一般的なエラーの種類を示します。これらを、以下のガイドラインに従ってトラブルシューティングすることができます。
- ジョブが失敗しました。 137
- ジョブが失敗しました。 E45004
- ジョブが失敗しました。 400
- Give either an account key or SAS token (アカウント キーまたは SAS トークンを指定してください)
- AzureBlob 承認に失敗した
ジョブが失敗しました。 137
エラー メッセージが次の場合
Azure Machine Learning Kubernetes job failed. 137:PodPattern matched: {"containers":[{"name":"training-identity-sidecar","message":"Updating certificates in /etc/ssl/certs...\n1 added, 0 removed; done.\nRunning hooks in /etc/ca-certificates/update.d...\ndone.\n * Serving Flask app 'msi-endpoint-server' (lazy loading)\n * Environment: production\n WARNING: This is a development server. Do not use it in a production deployment.\n Use a production WSGI server instead.\n * Debug mode: off\n * Running on http://127.0.0.1:12342/ (Press CTRL+C to quit)\n","code":137}]}
プロキシ設定を確認し、このネットワーク構成に従って、az connectedk8s connect を使用するときに、プロキシ スキップ範囲に 127.0.0.1 が追加されたかどうかを確認します。
ジョブが失敗しました。 E45004
エラー メッセージが次の場合
Azure Machine Learning Kubernetes job failed. E45004:"Training feature is not enabled, please enable it when install the extension."
Azure Machine Learning 拡張機能のインストール時に enableTraining=True を設定したかどうかを確認します。 詳細については、「AKS または Arc Kubernetes クラスターに Azure Machine Learning 拡張機能をデプロイする」を参照してください
ジョブが失敗しました。 400
エラー メッセージが次の場合
Azure Machine Learning Kubernetes job failed. 400:{"Msg":"Encountered an error when attempting to connect to the Azure Machine Learning token service","Code":400}
Private Link のトラブルシューティング セクションに従って、ネットワーク設定を確認できます。
Give either an account key or SAS token (アカウント キーまたは SAS トークンを指定してください)
Docker イメージ用の Azure Container Registry (ACR) とトレーニング データ用のストレージ アカウントにアクセスする必要がある場合、コンピューティングがマネージド ID で指定されていないときにこの問題が発生します。
Docker イメージ用の Kubernetes コンピューティング クラスターから Azure Container Registry (ACR) にアクセスするか、トレーニング データ用のストレージ アカウントにアクセスするには、システム割り当てマネージド ID またはユーザー割り当てマネージド ID を有効にして Kubernetes コンピューティングをアタッチする必要があります。
上のトレーニング シナリオでは、Kubernetes コンピューティングを資格情報として使用して、ワークスペースにバインドされた ARM リソースと Kubernetes コンピューティング クラスターの間で通信するために、このコンピューティング ID が必要です。 そのため、この ID がないと、トレーニング ジョブは失敗し、アカウント キーまたは SAS トークンが見つからないと報告されます。 たとえば、ストレージ アカウントにアクセスする場合、Kubernetes コンピューティングにマネージド ID を指定しない場合、次のエラー メッセージでジョブが失敗します。
Unable to mount data store workspaceblobstore. Give either an account key or SAS token
これは、資格情報のない機械学習ワークスペースの既定のストレージ アカウントは、Kubernetes コンピューティングのトレーニング ジョブではアクセスできないためです。
この問題を軽減するために、コンピューティングのアタッチ手順でマネージド ID をコンピューティングに割り当てるか、アタッチ後にマネージド ID をコンピューティングに割り当てることができます。 詳細については、マネージド ID をコンピューティング先に割り当てる方法に関する記事を参照してください。
AzureBlob 承認に失敗した
Kubernetes コンピューティング上のトレーニング ジョブでデータのアップロードまたはダウンロードのために AzureBlob にアクセスする必要がある場合、ジョブは次のエラー メッセージで失敗します。
Unable to upload project files to working directory in AzureBlob because the authorization failed.
これは、ジョブがプロジェクト ファイルを AzureBlob にアップロードしようとしたときに承認が失敗したためです。 次の項目を確認して、問題をトラブルシューティングできます。
- ストレージ アカウントで "Allow Azure services on the trusted service list to access this storage account" (信頼されたサービス一覧の Azure サービスにこのストレージ アカウントへのアクセスを許可する) という例外が有効になっていて、ワークスペースがリソース インスタンスの一覧にあることを確認します。
- ワークスペースにシステム割り当てマネージド ID があることを確認します。
プライベート リンクの問題
メソッドを使用して、Kubernetes クラスター内の 1 つのポッドにログインすることでプライベート リンクの設定を確認してから、関連するネットワーク設定を確認できます。
Azure portal でワークスペース ID を見つけるか、コマンド ラインで
az ml workspace showを実行して、この ID を取得します。kubectl get po -n azureml -l azuremlappname=azureml-feによって、実行されたすべての azureml-fe ポッドを表示します。任意のものにサインインして
kubectl exec -it -n azureml {scorin_fe_pod_name} bashを実行します。クラスターでプロキシを使用しない場合は、
nslookup {workspace_id}.workspace.{region}.api.azureml.msを実行します。 VNet からワークスペースへのプライベート リンクを正しく設定した場合、VNet の内部 IP には "DNSLookup" ツール経由で応答が返されます。クラスターでプロキシを使用している場合は、ワークスペースに
curlを実行してみることができます
curl https://{workspace_id}.workspace.westcentralus.api.azureml.ms/metric/v2.0/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{workspace_name}/api/2.0/prometheus/post -X POST -x {proxy_address} -d {} -v -k
プロキシとワークスペースがプライベート リンクで正しく設定されている場合は、内部 IP への接続試行を観察する必要があります。 トークンが指定されていない場合、このシナリオでは HTTP 401 状態コードを含む応答が必要です。
その他の既知の問題
Kubernetes コンピューティングの更新が有効にならない
現時点では、CLI v2 と SDK v2 では、既存の Kubernetes コンピューティングの構成を更新できません。 たとえば、名前空間の変更は有効になりません。
名前が '-' で終わるワークスペースまたはリソース グループ
Kubernetes コンピューティングでデプロイ、エンドポイント、ジョブなどのワークロードを作成するときの "InternalServerError" エラーの一般的な原因は、ワークスペースまたはリソース グループ名の末尾に '-' などの特殊文字が含まれている場合です。