Azure Machine Learning を使用したモデルのハイパーパラメーター調整 (v1)
適用対象: Azure CLI ML 拡張機能 v1
Azure CLI ML 拡張機能 v1
重要
この記事の Azure CLI コマンドの一部では、Azure Machine Learning 用に azure-cli-ml、つまり v1 の拡張機能を使用しています。 v1 拡張機能のサポートは、2025 年 9 月 30 日に終了します。 その日付まで、v1 拡張機能をインストールして使用できます。
2025 年 9 月 30 日より前に、ml (v2) 拡張機能に移行することをお勧めします。 v2 拡張機能の詳細については、Azure ML CLI 拡張機能と Python SDK v2 に関するページを参照してください。
Azure Machine Learning (v1) の HyperDrive パッケージを使用して、効率的なハイパーパラメーター調整を自動化します。 Azure Machine Learning SDK を使用してハイパーパラメーターを調整するために必要な手順を実行する方法について説明します。
- パラメーター検索空間を定義する
- 最適化する主要メトリックを指定する
- パフォーマンスの低い実行に早期終了ポリシーを指定する
- リソースの作成と割り当て
- 定義済みの構成で実験を開始する
- トレーニングの実行を視覚化する
- モデルに最適な構成を選択する
ハイパーパラメーター調整とは
ハイパーパラメーターは、モデルのトレーニング プロセスを制御できるようにする調整可能なパラメーターです。 たとえば、ニューラル ネットワークでは、隠れ層の数と各層内のノードの数を決定します。 モデルのパフォーマンスは、ハイパーパラメーターに大きく依存します。
ハイパーパラメーター調整 (別名、ハイパーパラメーターの最適化) は、最適なパフォーマンスを得られるハイパーパラメーターの構成を見つけるプロセスです。 通常、このプロセスは計算負荷が高く、手動で行われます。
Azure Machine Learning を使用すると、ハイパーパラメーターの調整を自動化し、実験を並行して行ってハイパーパラメーターを効率的に最適化できます。
検索空間を定義する
各ハイパーパラメーターに対して定義された値の範囲を調べることで、ハイパーパラメーターを調整します。
ハイパーパラメーターは、不連続値でも連続値でもよく、パラメーター式で記述された値の分布になります。
不連続ハイパーパラメーター
不連続ハイパーパラメーターは、不連続値の中の choice として指定します。 choice には次のものを指定できます。
- 1 つまたは複数のコンマ区切りの値
rangeオブジェクト- 任意の
listオブジェクト
{
"batch_size": choice(16, 32, 64, 128)
"number_of_hidden_layers": choice(range(1,5))
}
この場合、batch_size は値 [16, 32, 64, 128] のいずれかになり、number_of_hidden_layers は値 [1, 2, 3, 4] のいずれかになります。
次の高度な不連続ハイパーパラメーターは、分布を使用して指定することもできます。
quniform(low, high, q): round(uniform(low, high) / q) * q などの値を返しますqloguniform(low, high, q): round(exp(uniform(low, high)) / q) * q などの値を返しますqnormal(mu, sigma, q): round(normal(mu, sigma) / q) * q などの値を返しますqlognormal(mu, sigma, q): round(exp(normal(mu, sigma)) / q) * q などの値を返します
連続ハイパーパラメーター
連続ハイパーパラメーターは、連続した範囲の値にわたる分布として指定します。
uniform(low, high): 低い値と高い値の間の均等に分布される値を返しますloguniform(low, high): 戻り値の対数が均等に分布されるように exp(uniform(low, high)) に従って収束された値を返しますnormal(mu, sigma): 平均ミューと標準偏差シグマを使用して正規分布された実際の値を返しますlognormal(mu, sigma): 戻り値の対数が正規分布されるように exp(normal(mu, sigma)) に従って収束された値を返します
パラメーター空間定義の例を次に示します。
{
"learning_rate": normal(10, 3),
"keep_probability": uniform(0.05, 0.1)
}
このコードでは、2 つのパラメーター learning_rate と keep_probability で検索空間を定義します。 learning_rate は、平均値 10 と標準偏差 3 の正規分布になります。 keep_probability は、最小値 0.05 と最大値 0.1 の一様分布になります。
ハイパーパラメーター空間のサンプリング
ハイパーパラメーター空間に対して使用するパラメーター サンプリング方法を指定します。 Azure Machine Learning では次の方法がサポートされます。
- ランダム サンプリング
- グリッド サンプリング
- ベイジアン サンプリング
ランダム サンプリング
ランダム サンプリングでは、不連続および連続のハイパーパラメーターがサポートされます。 これは、パフォーマンスの低い実行の早期終了に対応しています。 一部のユーザーは、ランダム サンプリングを使用して最初の検索を行った後、検索空間を絞り込んで、結果を改善します。
ランダム サンプリングでは、定義済みの探索空間からハイパーパラメーター値がランダムに選択されます。
from azureml.train.hyperdrive import RandomParameterSampling
from azureml.train.hyperdrive import normal, uniform, choice
param_sampling = RandomParameterSampling( {
"learning_rate": normal(10, 3),
"keep_probability": uniform(0.05, 0.1),
"batch_size": choice(16, 32, 64, 128)
}
)
グリッド サンプリング
グリッド サンプリングでは、不連続ハイパーパラメーターがサポートされます。 検索空間を徹底的に検索する予算を確保できる場合は、グリッド サンプリングを使用します。 パフォーマンスの低い実行の早期終了に対応しています。
グリッド サンプリングでは、考えられるすべての値に対して単純なグリッド検索を実行します。 グリッド サンプリングは choice ハイパーパラメーターでのみ使用できます。 たとえば、次の空間には 6 個のサンプルがあります。
from azureml.train.hyperdrive import GridParameterSampling
from azureml.train.hyperdrive import choice
param_sampling = GridParameterSampling( {
"num_hidden_layers": choice(1, 2, 3),
"batch_size": choice(16, 32)
}
)
ベイジアン サンプリング
ベイジアン サンプリングは、ベイジアン最適化アルゴリズムに基づいています。 新しいサンプルによって主要メトリックが改善されるように、前のサンプルの実行結果に基づいてサンプルを選択します。
ベイジアン サンプリングは、ハイパーパラメーター空間を探索するための十分な予算がある場合に推奨されます。 最適な結果を得るために、実行の最大数は、調整するハイパーパラメーターの数の 20 倍以上にすることをお勧めします。
同時実行数は調整プロセスの有効性に影響を与えます。 同時実行数が少ないほど、サンプリングの収束が向上します。これは、並列処理の次数が小さいほど、以前に完了した実行の恩恵を受ける実行数が増えるためです。
ベイジアン サンプリングでは、検索空間に対して choice、uniform、quniform 分布のみがサポートされています。
from azureml.train.hyperdrive import BayesianParameterSampling
from azureml.train.hyperdrive import uniform, choice
param_sampling = BayesianParameterSampling( {
"learning_rate": uniform(0.05, 0.1),
"batch_size": choice(16, 32, 64, 128)
}
)
主要メトリックを指定する
ハイパーパラメーターの調整で最適化する主要メトリックを指定します。 トレーニングの各実行は、この主要メトリックに対して評価されます。 早期終了ポリシーでは、主要メトリックを使用してパフォーマンスの低い実行を識別します。
主要メトリックでは次の属性を指定します。
primary_metric_name:主要メトリックの名前は、トレーニング スクリプトによってログされているメトリック名と完全に一致する必要があります。primary_metric_goal:PrimaryMetricGoal.MAXIMIZEまたはPrimaryMetricGoal.MINIMIZEのいずれかを指定できます。実行を評価する際に主要メトリックを最大化するか最小化するかを決定します。
primary_metric_name="accuracy",
primary_metric_goal=PrimaryMetricGoal.MAXIMIZE
このサンプルでは "accuracy" を最大化します。
ハイパーパラメーターの調整のためのログ メトリック
モデルのトレーニング スクリプトでは、モデルのトレーニング中に主要メトリックをログして、ハイパーパラメーターの調整用に HyperDrive からアクセスできるようにする必要があります。
次のサンプル スニペットで、トレーニング スクリプトの主要メトリックをログします。
from azureml.core.run import Run
run_logger = Run.get_context()
run_logger.log("accuracy", float(val_accuracy))
トレーニング スクリプトでは val_accuracy が計算され、主要メトリック "accuracy" としてログされます。 メトリックがログされるたびに、これをハイパーパラメーター調整サービスが受信します。 レポートの頻度は、ご自身で決定してください。
モデル トレーニング実行の値のログに関する詳細については、「Azure Machine Learning のトレーニングの実行でログ記録を有効にする」をご覧ください。
早期終了ポリシーを指定する
早期終了ポリシーによって、パフォーマンスの低い実行は自動的に終了されます。 早期終了によって、計算効率が向上します。
次のパラメーターを構成して、ポリシーを適用するタイミングを制御できます。
evaluation_interval: ポリシーを適用する頻度。 トレーニング スクリプトによってログに記録されるたびに、主要メトリックは 1 間隔としてカウントされます。evaluation_intervalに 1 を指定すると、トレーニング スクリプトが主要メトリックを報告するたびにポリシーが適用されます。evaluation_intervalに 2 を指定すると、ポリシーは 1 回おきに適用されます。 指定しないと、evaluation_intervalは既定で 1 に設定されます。delay_evaluation: 指定した間隔数の期間、最初のポリシー評価を遅延させます。 これは省略可能なパラメーターです。すべての構成を最小間隔で実行できるようにして、トレーニング実行の早期終了を回避します。 指定すると、このポリシーは delay_evaluation 以上の evaluation_interval の倍数ごとに適用されます。
Azure Machine Learning では、以下の早期終了ポリシーがサポートされています。
バンディット ポリシー
バンディット ポリシーは、Slack 要素/Slack 量と評価間隔に基づきます。 バンディットでは、最も成功した実行の指定 Slack 要素/Slack 量の範囲内に主要メトリックがないとき、実行が終了します。
注意
ベイジアン サンプリングでは早期終了はサポートされません。 ベイジアン サンプリングを使用する場合は early_termination_policy = None を設定します。
次の構成パラメーターを指定します。
slack_factorまたはslack_amount: パフォーマンスが最高のトレーニング実行に関して許可される Slack。slack_factorは、許可される Slack を比率として指定します。slack_amountは、許可される Slack を比率ではなく絶対量として指定します。たとえば、間隔 10 で適用されるバンディット ポリシーについて考えてみます。 主要メトリックを最大化するという目標があり、間隔 10 で最高のパフォーマンスになる実行で主要メトリックが 0.8 であると報告されたとします。 ポリシーで 0.2 の
slack_factorが指定された場合、間隔 10 で最高のメトリックを持つトレーニング実行のうち、0.66 (0.8/(1+slack_factor)) 未満のものが終了されます。evaluation_interval: (省略可能) ポリシーを適用する頻度delay_evaluation: (省略可能) 指定した間隔数の期間、最初のポリシー評価を遅延します
from azureml.train.hyperdrive import BanditPolicy
early_termination_policy = BanditPolicy(slack_factor = 0.1, evaluation_interval=1, delay_evaluation=5)
この例では、評価間隔 5 から始めて、メトリックが報告される間隔ごとに早期終了ポリシーが適用されます。 最高のメトリックが (1/(1 + 0.1) 未満、または最高のパフォーマンスの実行のうち 91% 未満の実行はすべて終了されます。
中央値の停止ポリシー
中央値の停止は、実行によって報告された主要メトリックの現在の平均に基づく早期終了ポリシーです。 このポリシーは、すべてのトレーニング実行を対象に移動平均を計算し、主要メトリック値が平均の中央値よりも低い実行を終了します。
このポリシーでは、次の構成パラメーターを指定できます。
evaluation_interval: ポリシーを適用する頻度 (省略可能なパラメーター)。delay_evaluation: 指定した間隔数の期間、最初のポリシー評価を遅延させます (省略可能なパラメーター)。
from azureml.train.hyperdrive import MedianStoppingPolicy
early_termination_policy = MedianStoppingPolicy(evaluation_interval=1, delay_evaluation=5)
この例では、評価間隔 5 から始めて、間隔ごとに早期終了ポリシーが適用されます。 トレーニング実行全体で、最高の主要メトリックが間隔 1:5 に対して移動平均の中央値未満の場合、実行は間隔 5 で終了されます。
切り捨て選択ポリシー
切り捨て選択では、各評価間隔で、最も低いパフォーマンスの実行のうち、ある割合が取り消されます。 実行は、主要メトリックを使用して比較されます。
このポリシーでは、次の構成パラメーターを指定できます。
truncation_percentage: 各評価間隔で終了する最も低いパフォーマンスの割合 (%)。 1 ~ 99 の整数値。evaluation_interval: (省略可能) ポリシーを適用する頻度delay_evaluation: (省略可能) 指定した間隔数の期間、最初のポリシー評価を遅延しますexclude_finished_jobs: ポリシーを適用するときに、完了したジョブを除外するかどうかを指定します
from azureml.train.hyperdrive import TruncationSelectionPolicy
early_termination_policy = TruncationSelectionPolicy(evaluation_interval=1, truncation_percentage=20, delay_evaluation=5, exclude_finished_jobs=true)
この例では、評価間隔 5 から始めて、間隔ごとに早期終了ポリシーが適用されます。 間隔 5 のパフォーマンスが、間隔 5 のすべての実行の下位 20% に含まれる場合、その実行は間隔 5 で終了され、ポリシーを適用したときに、完了したジョブが除外されます。
終了なしポリシー (既定)
ポリシーを指定しないと、ハイパーパラメーター調整サービスでは、すべてのトレーニング実行が完了まで実行されます。
policy=None
早期終了ポリシーを選択する
- 先のジョブまで終了せずに節約する保守的なポリシーでは、
evaluation_interval1 およびdelay_evaluation5 で中央値の停止ポリシーを検討します。 これらは保守的な設定であり、(評価データに基づいて) 主要メトリックに関する損失なしで約 25% から 35% の節約を実現できます。 - より積極的な節約では、バンディット ポリシーをより小さい許容される Slack で使用するか、切り捨て選択ポリシーをより大きな切り捨て率で使用します。
リソースの作成と割り当て
トレーニング実行の最大数を指定して、リソースの割り当てを制御します。
max_total_runs:トレーニング実行の最大数。 1 ~ 1000 の整数にする必要があります。max_duration_minutes: (省略可能) ハイパーパラメーター調整実験の最大期間 (分単位)。 この期間が取り消されると実行されます。
Note
max_total_runs と max_duration_minutes の両方を指定した場合は、これら 2 つのしきい値のうちの最初のしきい値に達するとハイパーパラメーター調整実験は終了します。
さらに、ハイパーパラメーター調整の検索時に同時に実行できるトレーニング実行の最大回数を指定します。
max_concurrent_runs: (省略可能) 同時に実行できる実行の最大数。 指定しない場合、すべての実行が並列で起動されます。 指定する場合は、1 ~ 100 の整数にする必要があります。
Note
並列実行の数は、指定された計算ターゲットで使用できるリソースに基づいて制御されます。 目的の同時実行可能性のために、使用可能なリソースをコンピューティング先に確保する必要があります。
max_total_runs=20,
max_concurrent_runs=4
このコードでは、ハイパーパラメーター調整実験は、一度に 4 つの構成を実行して合計で最大 20 回の実行を使用するように構成されます。
ハイパーパラメーター調整実験を構成する
ハイパーパラメーター調整実験を構成するには、以下を指定します。
- 定義済みのハイパーパラメーター検索空間
- 早期終了ポリシー
- 主要メトリック
- リソース割り当て設定
- ScriptRunConfig
script_run_config
ScriptRunConfig は、サンプリングされるハイパーパラメーターで実行されるトレーニング スクリプトです。 これは、ジョブごとのリソース (単一または複数のノード) と、使用するコンピューティング先を定義します。
Note
script_run_config で使用するコンピューティング先には、同時実行レベルを満たすのに十分なリソースが必要です。 ScriptRunConfig の詳細については、トレーニング実行の構成に関する記事をご覧ください。
ハイパーパラメーター調整実験を構成します。
from azureml.train.hyperdrive import HyperDriveConfig
from azureml.train.hyperdrive import RandomParameterSampling, BanditPolicy, uniform, PrimaryMetricGoal
param_sampling = RandomParameterSampling( {
'learning_rate': uniform(0.0005, 0.005),
'momentum': uniform(0.9, 0.99)
}
)
early_termination_policy = BanditPolicy(slack_factor=0.15, evaluation_interval=1, delay_evaluation=10)
hd_config = HyperDriveConfig(run_config=script_run_config,
hyperparameter_sampling=param_sampling,
policy=early_termination_policy,
primary_metric_name="accuracy",
primary_metric_goal=PrimaryMetricGoal.MAXIMIZE,
max_total_runs=100,
max_concurrent_runs=4)
ScriptRunConfig script_run_config に渡されるパラメーターが HyperDriveConfig によって設定されます。 引き続き script_run_config によってパラメーターがトレーニング スクリプトに渡されます。 上のコード スニペットは、サンプル ノートブック Train, hyperparameter tune, and deploy with PyTorch から抜粋されたものです。 このサンプルでは、learning_rate パラメーターと momentum パラメーターが調整されます。 実行を早い段階で停止するかどうかは、主要メトリックが slack_factor の範囲外にあるときに実行を停止する BanditPolicy によって決定されます (BanditPolicy クラスのリファレンス ページを参照してください)。
サンプルからの次のコードからは、調整された値が受け取られ、解析され、トレーニング スクリプトの fine_tune_model 関数に渡されるしくみがわかります。
# from pytorch_train.py
def main():
print("Torch version:", torch.__version__)
# get command-line arguments
parser = argparse.ArgumentParser()
parser.add_argument('--num_epochs', type=int, default=25,
help='number of epochs to train')
parser.add_argument('--output_dir', type=str, help='output directory')
parser.add_argument('--learning_rate', type=float,
default=0.001, help='learning rate')
parser.add_argument('--momentum', type=float, default=0.9, help='momentum')
args = parser.parse_args()
data_dir = download_data()
print("data directory is: " + data_dir)
model = fine_tune_model(args.num_epochs, data_dir,
args.learning_rate, args.momentum)
os.makedirs(args.output_dir, exist_ok=True)
torch.save(model, os.path.join(args.output_dir, 'model.pt'))
重要
ハイパーパラメーター実行はすべて、モデルと "すべてのデータ ローダー" の再構築を含め、トレーニングをゼロから再開するものです。 このコストは、Azure Machine Learning パイプラインまたは手動プロセスを利用し、トレーニング実行前に可能な限りたくさんのデータを準備することで最小限に抑えることができます。
ハイパーパラメーター調整実験を送信する
ハイパーパラメーター調整構成を定義したら、実験を送信します。
from azureml.core.experiment import Experiment
experiment = Experiment(workspace, experiment_name)
hyperdrive_run = experiment.submit(hd_config)
ハイパーパラメーター調整をウォーム スタートする (省略可能)
モデルに最適なハイパーパラメーター値を見つけることは、反復的なプロセスになる場合があります。 前の 5 回の実行で得た知識を再利用して、ハイパーパラメーターの調整を迅速化できます。
ウォーム スタートは、サンプリング方法によって異なる方法で処理されます。
- ベイジアン サンプリング:前の実行で行った試行を、新しいサンプルの選択と主要メトリック改善のための事前知識として利用します。
- ランダム サンプリングまたはグリッド サンプリング: 早期終了では、前の実行で得た知識を利用して、パフォーマンスの低い実行を判別します。
ウォーム スタートを開始する親実行の一覧を指定してください。
from azureml.train.hyperdrive import HyperDriveRun
warmstart_parent_1 = HyperDriveRun(experiment, "warmstart_parent_run_ID_1")
warmstart_parent_2 = HyperDriveRun(experiment, "warmstart_parent_run_ID_2")
warmstart_parents_to_resume_from = [warmstart_parent_1, warmstart_parent_2]
ハイパーパラメーター調整実験が取り消された場合は、前回のチェックポイントからトレーニングの実行を再開できます。 ただし、トレーニング スクリプトによってチェックポイントのロジックが処理される必要があります。
トレーニングの実行では、同じハイパーパラメーター構成を使用し、出力フォルダーをマウントする必要があります。 トレーニング スクリプトでは、resume-from 引数を受け入れる必要があります。これには、トレーニングの実行を再開する起点となるチェックポイントまたはモデル ファイルが格納されます。 次のスニペットを使用して、個々のトレーニングの実行を再開できます。
from azureml.core.run import Run
resume_child_run_1 = Run(experiment, "resume_child_run_ID_1")
resume_child_run_2 = Run(experiment, "resume_child_run_ID_2")
child_runs_to_resume = [resume_child_run_1, resume_child_run_2]
ハイパーパラメーター調整実験は、前回の実験からウォーム スタートするか、オプション パラメーターである resume_from と resume_child_runs を構成内で使用して個々のトレーニングの実行を再開するように構成できます。
from azureml.train.hyperdrive import HyperDriveConfig
hd_config = HyperDriveConfig(run_config=script_run_config,
hyperparameter_sampling=param_sampling,
policy=early_termination_policy,
resume_from=warmstart_parents_to_resume_from,
resume_child_runs=child_runs_to_resume,
primary_metric_name="accuracy",
primary_metric_goal=PrimaryMetricGoal.MAXIMIZE,
max_total_runs=100,
max_concurrent_runs=4)
ハイパーパラメーター調整の実行を視覚化する
Azure Machine Learning スタジオでハイパーパラメーター調整の実行を視覚化することも、ノートブック ウィジェットを使用することもできます。
スタジオ
Azure Machine Learning スタジオでは、すべてのハイパーパラメーター調整の実行を視覚化できます。 ポータルで実験を表示する方法について詳しくは、「Studio で実行レコードを表示する」をご覧ください。
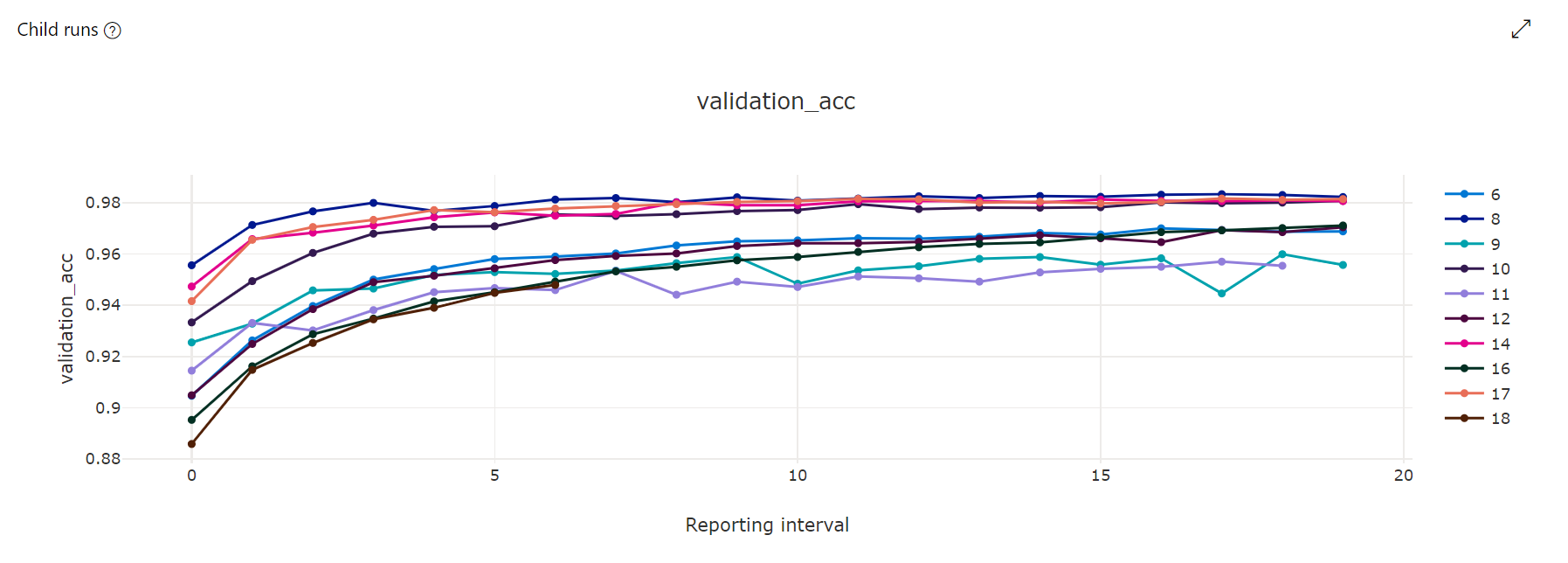
メトリック グラフ:この視覚化を使用すると、ハイパーパラメーター調整の期間中に実行された各ハイパードライブの子実行についてログに記録されたメトリックが追跡されます。 各行は 1 つの子実行を表し、各ポイントはランタイムのイテレーションで主要メトリックの値を測定します。
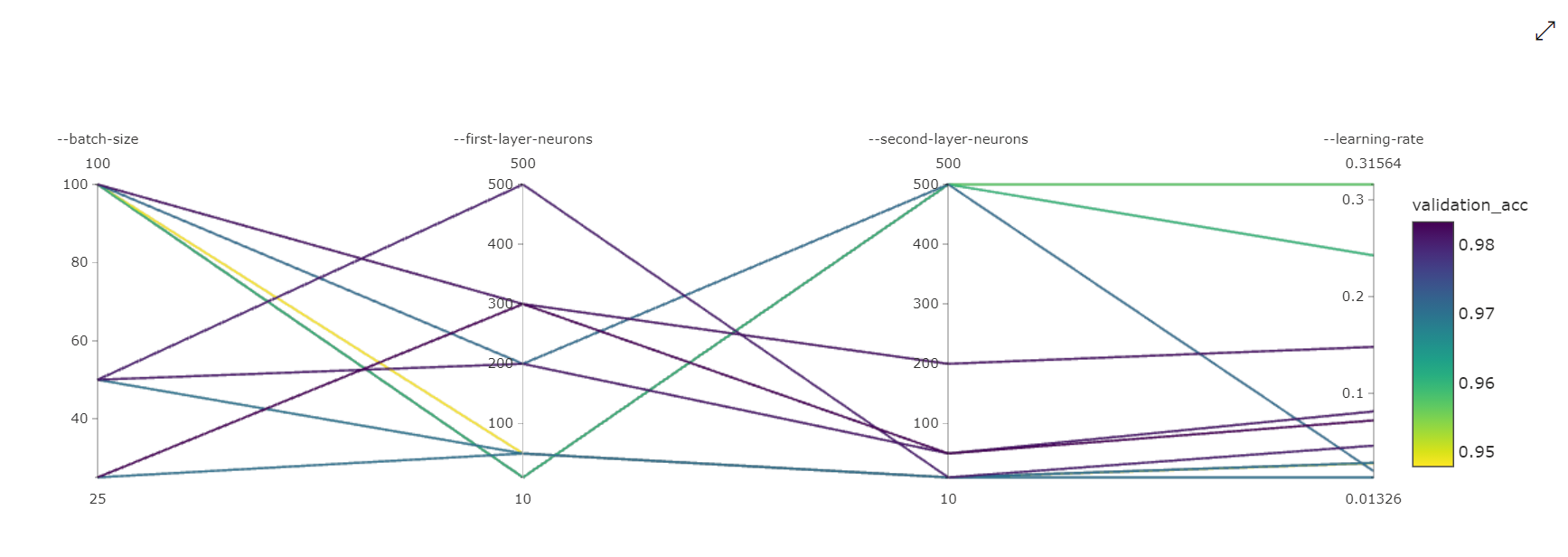
並列座標グラフ:この視覚化を使用すると、主要メトリックのパフォーマンスと個々のハイパーパラメーター値の相関関係が示されます。 グラフは、軸を移動する (軸ラベルをクリックしてドラッグする)、および 1 つの軸全体の値を強調表示する (1 つの軸をクリックし、軸に沿って垂直方向にドラッグして、目的の値の範囲を強調表示する) ことで、インタラクティブになります。 並列座標グラフには、グラフの一番右にある軸が含まれ、その実行インスタンスに設定されているハイパーパラメーターに対応する最適なメトリック値がプロットされます。 この軸は、グラフのグラデーションの凡例を、より読みやすい形式でデータに射影するために用意されています。
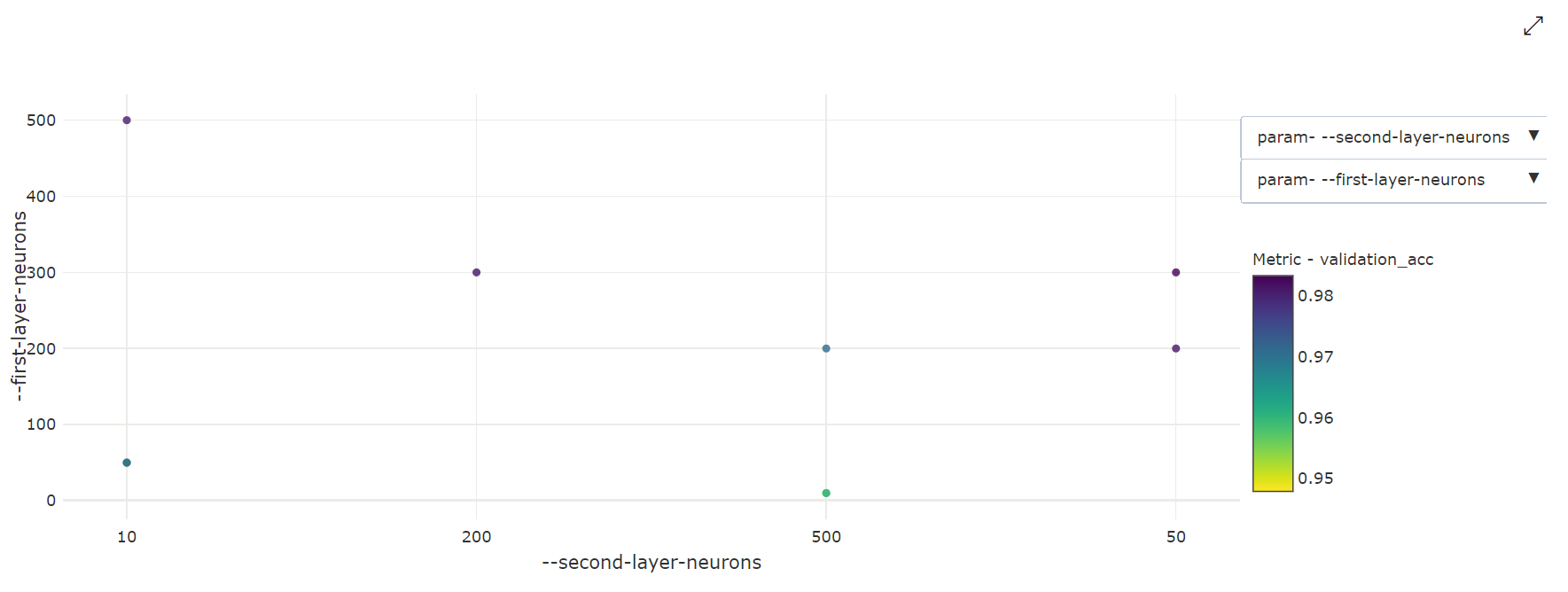
2 次元散布図:この視覚化を使用すると、2 つの個別のハイパーパラメーターの間の相関関係が、関連付けられている主要メトリック値と共に表示されます。
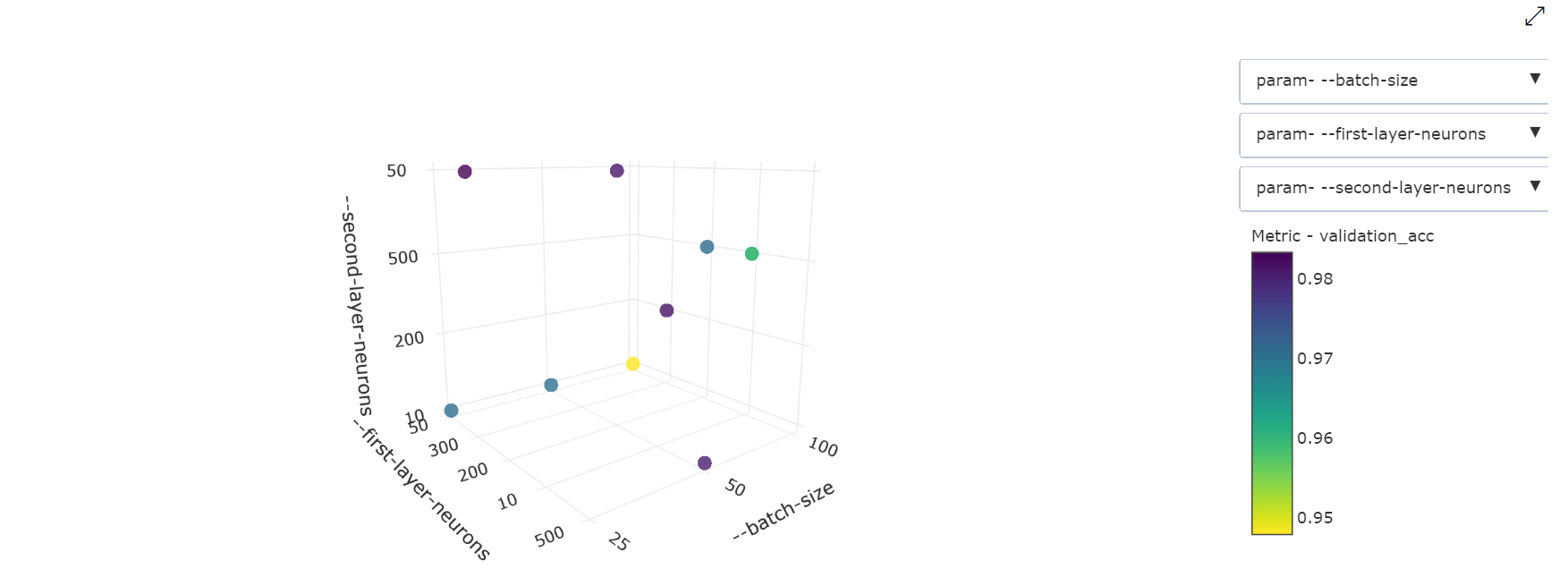
3 次元散布図:この視覚化は 2D と同じですが、主要メトリック値と相関関係にある 3 つのハイパーパラメーター ディメンションを使用できます。 グラフをクリックしてドラッグし、グラフの方向を変更し、3D 空間内のさまざまな相関関係を表示することもできます。
Notebook のウィジェット
Notebook ウイジェットを使用して、トレーニングの実行の進行状況を視覚化します。 次のスニペットを使用すると、すべてのハイパーパラメーター調整実行が Jupyter Notebook の 1 か所で視覚化されます。
from azureml.widgets import RunDetails
RunDetails(hyperdrive_run).show()
このコードにより、各ハイパーパラメーター構成のトレーニング実行に関する詳細情報が表に示されます。
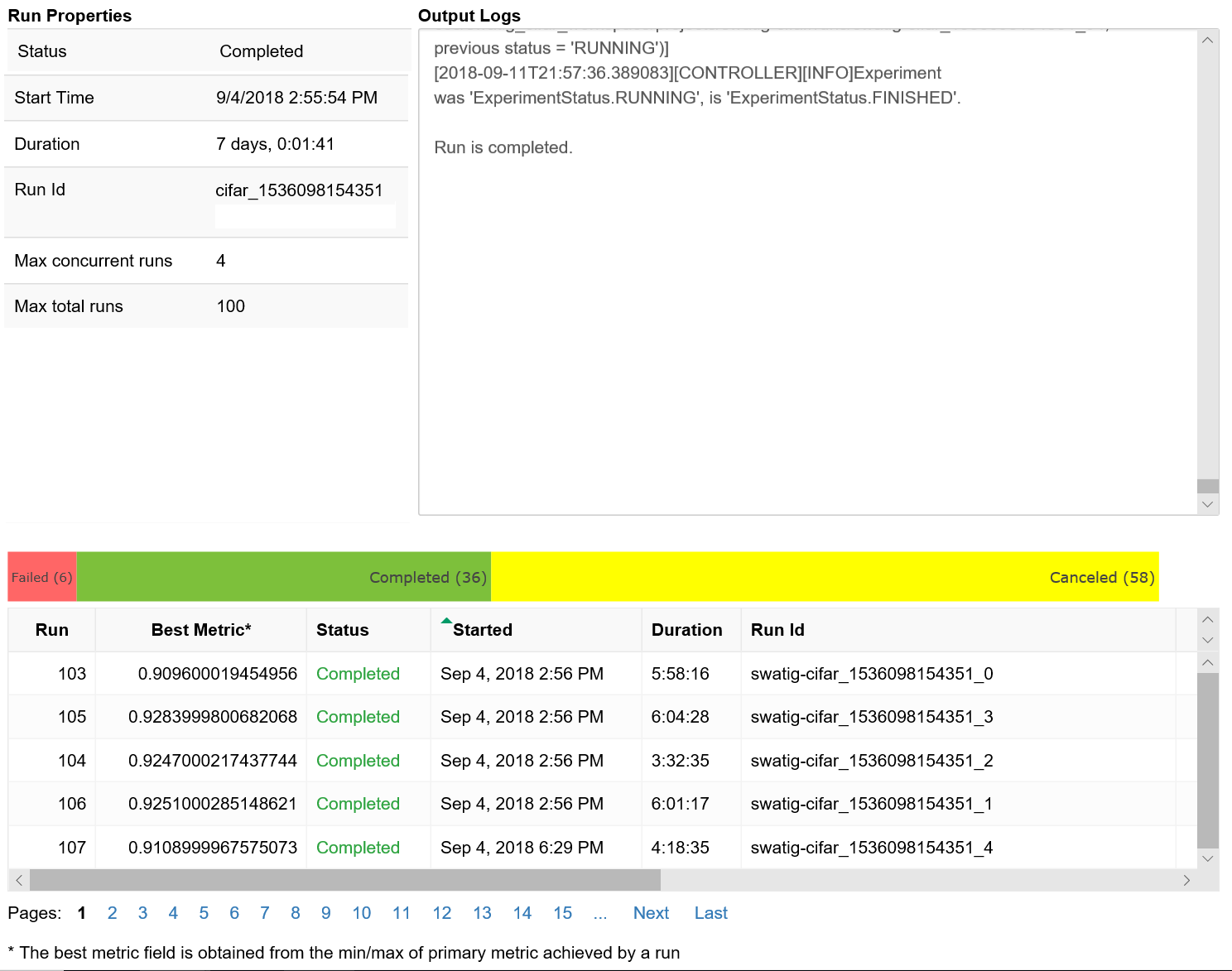
トレーニングの進行に合わせて、各実行のパフォーマンスを視覚化することもできます。
最高のモデルを見つける
すべてのハイパーパラメーター調整実行が完了したら、最高のパフォーマンスの構成とハイパーパラメーター値を特定します。
best_run = hyperdrive_run.get_best_run_by_primary_metric()
best_run_metrics = best_run.get_metrics()
parameter_values = best_run.get_details()['runDefinition']['arguments']
print('Best Run Id: ', best_run.id)
print('\n Accuracy:', best_run_metrics['accuracy'])
print('\n learning rate:',parameter_values[3])
print('\n keep probability:',parameter_values[5])
print('\n batch size:',parameter_values[7])
サンプル ノートブック
このフォルダーにある train-hyperparameter-* notebooks を参照してください。
ノートブックの実行方法については、Jupyter Notebook を使用してこのサービスを探索する方法に関するページを参照してください。