Apache Spark を使用して Azure Managed Instance for Apache Cassandra に移行する
可能な限り、Apache Cassandra のネイティブ レプリケーションを使用し、ハイブリッド クラスターを構成することで、既存のクラスターから Azure Managed Instance for Apache Cassandra にデータを移行することをお勧めします。 このアプローチでは、Apache Cassandra のゴシップ プロトコルを使用して、ソース データセンターから新しいマネージド インスタンス データセンターにデータをレプリケートします。 ただし、ソース データベースのバージョンに互換性がない場合や、ハイブリッド クラスターのセットアップが実行できない場合があります。
このチュートリアルでは、Cassandra Spark コネクタと Apache Spark 向けの Azure Databricks を使用して、オフラインで Azure Managed Instance for Apache Cassandra に移行するためにデータを移行する方法について説明します。
前提条件
Azure portal または Azure CLI を使用して Azure Managed Instance for Apache Cassandra クラスターをプロビジョニングし、CQLSH を使用してクラスターに接続できることを確認します。
マネージド Cassandra VNet 内に Azure Databricks アカウントをプロビジョニングします。 また、ソース Cassandra クラスターへのネットワーク アクセスがあることも確認します。
キースペースまたはテーブル スキームをソース Cassandra データベースからターゲット Cassandra Managed Instance データベースに既に移行していることを確認します。
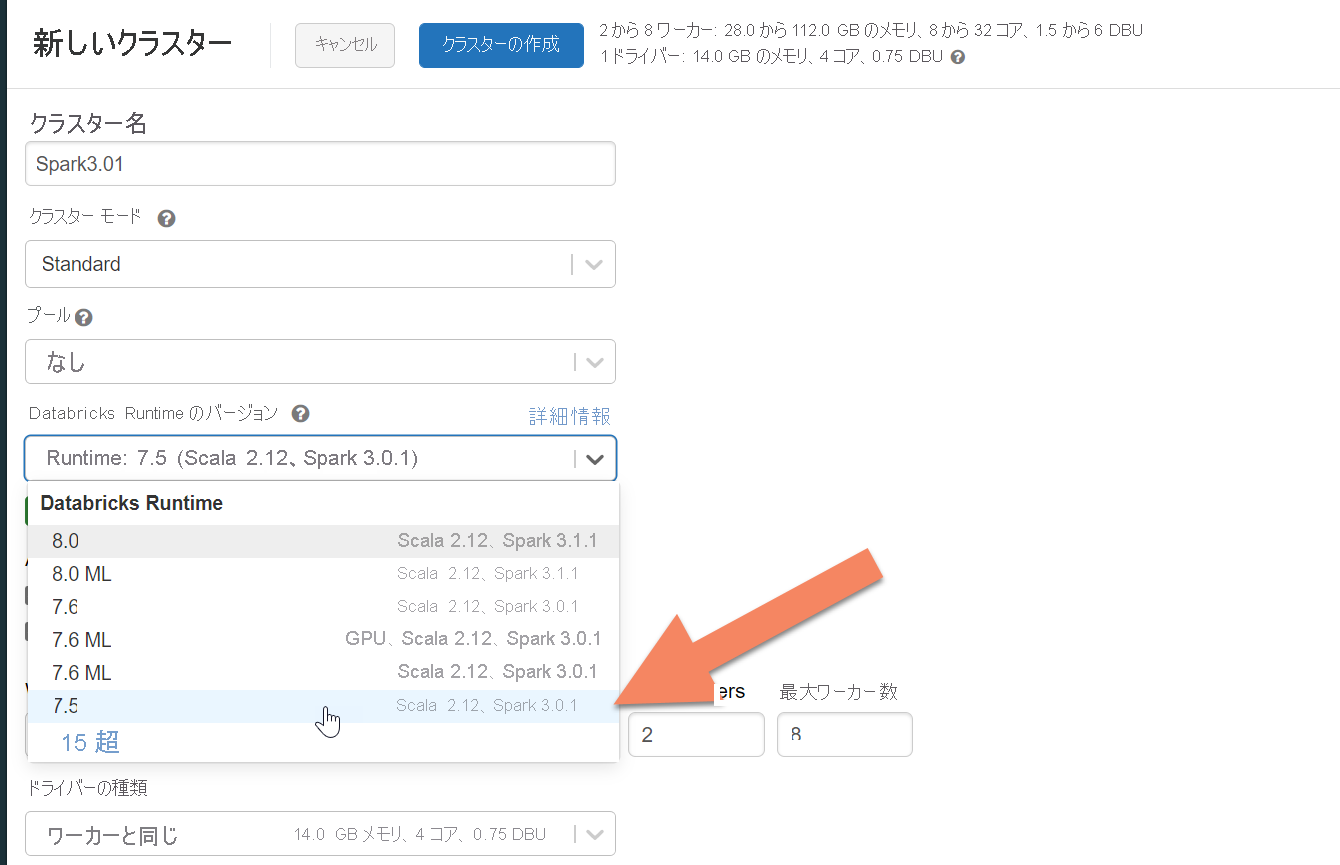
Azure Databricks クラスターのプロビジョニング
Spark 3.0 をサポートする Databricks ランタイム バージョン 7.5 を選択することをお勧めします。
依存関係を追加する
Apache Spark Cassandra コネクタ ライブラリをクラスターに追加して、ネイティブと Azure Cosmos DB Cassandra 両方のエンドポイントに接続します。 自分のクラスターで、 [ライブラリ]>[新規インストール]>[Maven] の順に選択し、Maven 座標に com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 を追加します。
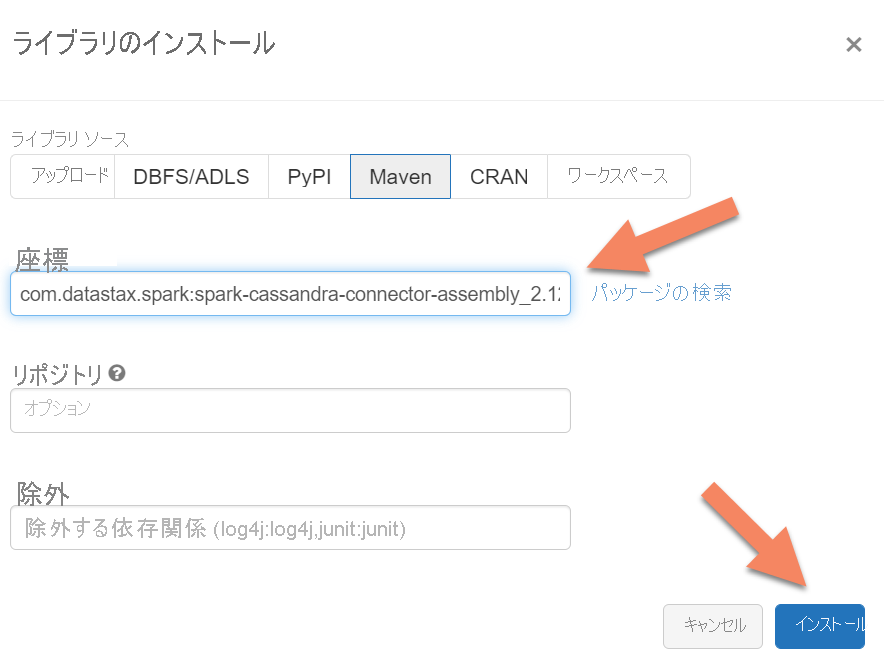
[インストール] を選択し、インストールが完了したらクラスターを再起動します。
Note
Cassandra コネクタ ライブラリがインストールされたら、必ず Databricks クラスターを再起動してください。
移行用の Scala ノートブックを作成する
Databricks で Scala ノートブックを作成します。 ソースとターゲットの Cassandra 構成を、対応する資格情報、ソースとターゲットのキースペースおよびテーブルで置き換えます。 次に、下のコードを実行します。
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val sourceCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "false",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val targetCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "10",
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//Read from source Cassandra
val DFfromSourceCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(sourceCassandra)
.load
//Write to target Cassandra
DFfromSourceCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(targetCassandra)
.mode(SaveMode.Append) // only required for Spark 3.x
.save
Note
各行の元の writetime を保持する必要がある場合は、cassandra migrator のサンプルを参照してください。