Azure Traffic Manager の信頼性
この記事では、Azure Traffic Manager の具体的な信頼性に関する推奨事項と Azure Traffic Manager のリージョン間ディザスター リカバリーと事業継続のサポートについて説明します。
Azure における信頼性の原則の詳細については、Azure の信頼性に関するページを参照してください。
信頼性に関する推奨事項
このセクションには、Azure Virtual Machines の回復性と可用性を実現するためのレコメンデーションが含まれています。 各レコメンデーションは、次の 2 つのカテゴリのいずれかに分類されます:
正常性項目には、構成項目などの領域と、Azure リソースの構成設定、他のサービスへの依存関係など、Azure ワークロードを構成する主要コンポーネントの適切な機能をカバーします。
リスク項目は、可用性と回復の要件、テスト、監視、デプロイ、その他の項目など、未解決のままである場合に環境で問題が発生する可能性が高まる領域をカバーします。
信頼性に関する推奨事項の優先順位マトリックス
各推奨事項は、次の優先順位マトリックスに従ってマークされます。
| Image | 優先度 | 説明 |
|---|---|---|
| 高 | 直ちに修正が必要です。 | |
| Medium | 3 から 6 か月以内に修正してください。 | |
| 低 | 確認が必要です。 |
信頼性に関する推奨事項の概要
可用性
 Traffic Manager の監視状態はオンラインである必要があります
Traffic Manager の監視状態はオンラインである必要があります
アプリケーション ワークロードのフェールオーバーを提供するには、監視状態がオンラインである必要があります。 Traffic Manager の正常性が機能低下状態と表示されている場合は、1 つ以上のエンドポイントの状態も機能低下となっている可能性があります。
Traffic Manager のエンドポイント監視の詳細については、「Traffic Manager のエンドポイント監視」を参照してください。
Azure Traffic Manager の機能低下状態のトラブルシューティングを行うには、「Azure Traffic Manager の機能低下状態のトラブルシューティング」を参照してください。
Traffic Manager プロファイルには複数のエンドポイントが必要です
Azure Traffic Manager を構成する際には、ワークロードを別のインスタンスにフェールオーバーするために、少なくとも 2 つのエンドポイントをプロビジョニングする必要があります。
Traffic Manager エンドポイントの種類については、「Traffic Manager エンドポイント」を参照してください。
システムの効率
 ユーザー プロファイルの TTL 値は 60 秒にする必要があります
ユーザー プロファイルの TTL 値は 60 秒にする必要があります
Time to Live (TTL) は、クライアントが Azure Traffic Manager に要求を送った場合に応答が返されるまでの早さに影響を与えます。 TTL 値を小さくすると、フェールオーバーの発生時に、機能しているエンドポイントにクライアントがルーティングされるまでの時間が早くなります。 できるだけ早くトラフィックを正常性エンドポイントにルーティングするには、TTL を 60 秒に設定します。
DNS TTL の構成の詳細については、「DNS Time to Live の構成」を参照してください。
障害復旧
別のリージョン内に少なくとも 1 つのエンドポイントを構成してください
プロファイルには、エンドポイントの 1 つで障害が発生した場合に可用性を確保するために、複数のエンドポイントを設定する必要があります。 それらのエンドポイントは、異なるリージョンに置くことをお勧めします。
Traffic Manager エンドポイントの種類については、「Traffic Manager エンドポイント」を参照してください。
エンドポイントの地理的プロファイルが “(All World)” に構成されていることを確認してください
地理的なルーティングの場合、トラフィックは、定義されているリージョンに基づいてエンドポイントにルーティングされます。 リージョンで障害が発生した場合、定義済みのフェールオーバーはありません。 リージョンのグループ化で地理的プロファイルが “All (World)” に構成されているエンドポイントを使用すると、トラフィック ブラック ホーリングを回避し、サービスの可用性を保証できます。
エンドポイントを追加して構成する方法については、「エンドポイントの追加、無効化、有効化、削除、または移動」を参照してください。
リージョン間のディザスター リカバリーおよび事業継続
ディザスター リカバリー (DR) とは、ダウンタイムやデータ損失につながるような、影響の大きいイベント (自然災害やデプロイの失敗など) から復旧することです。 原因に関係なく、災害に対する最善の解決策は、明確に定義されテストされた DR プランと、DR を積極的にサポートするアプリケーション設計です。 ディザスター リカバリー計画の作成を検討する前に、「ディザスター リカバリー戦略の設計に関する推奨事項」を参照してください。
DR に関しては、Microsoft は共有責任モデルを使用します。 共有責任モデルでは、ベースライン インフラストラクチャとプラットフォーム サービスの可用性が Microsoft によって保証されます。 同時に、多くの Azure サービスでは、データのレプリケート、または障害が発生したリージョンから別の有効なリージョンにクロスレプリケートするフォールバックは、自動的には行われません。 それらのサービスについては、お客様がワークロードに適したディザスター リカバリー計画を設定する必要があります。 Azure PaaS (サービスとしてのプラットフォーム) オファリング上で実行されるほとんどのサービスには、DR をサポートするための機能とガイダンスが用意されており、お客様はサービス固有の機能を使って迅速な復旧をサポートでき、DR 計画の開発に役立ちます。
Azure Traffic Manager は DNS ベースのトラフィック ロード バランサーであり、パブリックに公開されているアプリケーションへのトラフィックを世界各国の Azure リージョンに分散できます。 また、Traffic Manager によって、パブリック エンドポイントには高可用性と高い応答速度が確保されます。
Traffic Manager では、DNS を使用して、トラフィック ルーティング方法に基づいて適切なサービス エンドポイントにクライアント要求が誘導されます。 さらに、Traffic Manager では、各エンドポイントの稼働状況も監視されます。 Azure の内部または外部でホストされている、インターネットに公開された任意のサービスをエンドポイントとすることができます。 Traffic Manager には、さまざまなアプリケーション ニーズと自動フェールオーバー モデルに対応する、さまざまなトラフィック ルーティング方法とエンドポイント監視オプションが用意されています。 Traffic Manager は Azure リージョン全体の障害などの障害に対応します。
複数リージョンの地域でのディザスター リカバリー
DNS は、ネットワーク トラフィックを転送する最も効率的なメカニズムの 1 つです。 DNS が効率的である理由は、DNS が多くの場合、グローバルであり、データ センターの外部にあるためです。 DNS は、リージョンや可用性ゾーン (AZ) レベルの障害からも隔離されています。
ディザスター リカバリー アーキテクチャの設定には次の 2 つの技術的な側面があります。
デプロイ メカニズムを使用して、プライマリおよびスタンバイの環境間でのインスタンス、データ、および構成をレプリケートします。 この種のディザスター リカバリーは、Azure Site Recovery を介してネイティブに実行できます。Veritas や NetApp などの Microsoft Azure パートナー アプライアンス/サービスを介した Azure Site Recovery のドキュメントを参照してください。
ネットワーク トラフィックまたは Web トラフィックをプライマリ サイトからスタンバイ サイトに迂回させるソリューションを開発します。 この種のディザスター リカバリーは、Azure DNS、Azure Traffic Manager (DNS)、またはサード パーティ製のグローバル ロード バランサーを介して実現できます。
この記事では、特に Azure Traffic Manager のディザスター リカバリー計画に焦点を当てます。
停止の検出、通知、管理
障害発生時に、プライマリ エンドポイントがプローブされ、状態が [低下] に変わり、ディザスター リカバリー サイトが [オンライン] のままになります。 Traffic Manager では、既定では、すべてのトラフィックがプライマリ (優先順位が一番高い) エンドポイントに送信されます。 プライマリ エンドポイントが低下したとき、Traffic Manager は、2 番目のエンドポイントが正常である限り、トラフィックを 2 番目のエンドポイントにルーティングします。 Traffic Manager 内に追加のエンドポイントを構成して、追加のフェイル オーバーのエンドポイントとして使用したり、エンドポイント間の負荷を分散するロード バランサーとして使用したりすることもできます。
ディザスター リカバリーと障害検出を設定する
アーキテクチャが複雑で、同じ機能を実行できる複数のリソースのセットがある場合、Azure Traffic Manager を (DNS に基づいて) 構成して、リソースの正常性を確認し、正常でないリソースから正常なリソースにトラフィックをルーティングすることができます。
次の例では、プライマリ リージョンとセカンダリ リージョンの両方が完全にデプロイされています。 このデプロイには、クラウド サービスと同期化されたデータベースが含まれます。
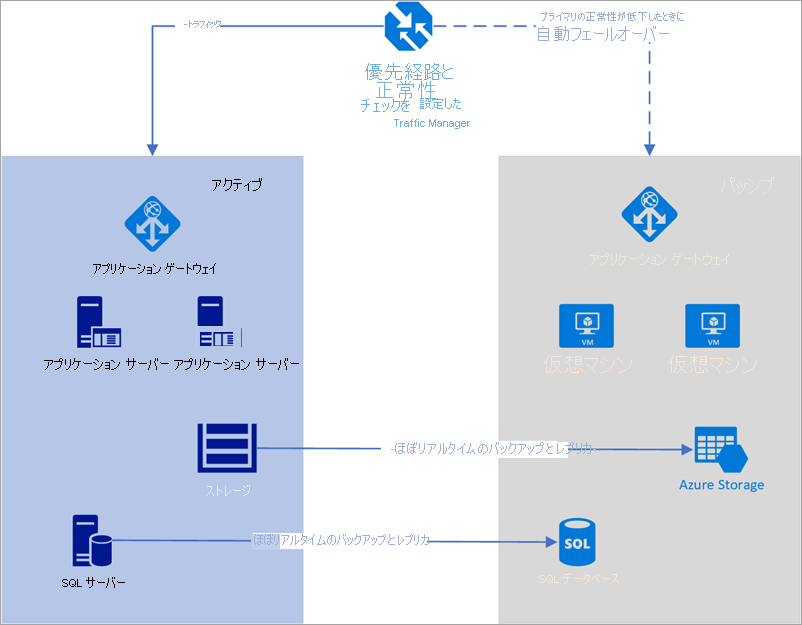
図 - Azure Traffic Manager を使用した自動フェールオーバー
ただし、プライマリ リージョンのみが、ユーザーからのネットワーク要求をアクティブに処理しています。 セカンダリ リージョンは、プライマリ リージョンでサービスの中断が発生した場合にのみアクティブになります。 その場合、新しいネットワーク要求はすべて、セカンダリ リージョンにルーティングされます。 データベースのバックアップはほぼ瞬時で行われ、両方のロード バランサーには正常性のチェックが可能な IP が存在し、インスタンスは常に動作しているため、このトポロジでは、低い RTO での実行と、手動による介入が不要なフェールオーバーのオプションが提供されます。 セカンダリ フェールオーバー リージョンは、プライマリ リージョンで障害が発生した直後に動作可能な状態になる必要があります。
このシナリオは、http、https、TCP などのさまざまな種類の正常性のチェックのための組み込みのプローブを持つ Azure Traffic Manager の使用するために最適です。 Azure Traffic Manager には、下に示すように、障害が発生したときにフェールオーバーするように構成できるルール エンジンもあります。 Traffic Manager を使用した次のソリューションについて検討してみましょう。
- お客様は、静的 IP が 100.168.124.44 であるprod.contoso.com というリージョン 1 のエンドポイントと、静的 IP が 100.168.124.43 である dr.contoso.com というリージョン 2 のエンドポイントを持っています。
- 各環境は、ロード バランサーのようにパブリックに公開されたプロパティを使用してアクセスされます。 ロード バランサーは、上記のように、DNS ベース エンドポイントまたは完全修飾ドメイン名 (FQDN) の設定を構成できます。
- リージョン 2 のすべてのインスタンスは、リージョン 1 とほぼリアルタイムでレプリケーションされます。 さらに、マシンのイメージは最新状態で、すべてのソフトウェアおよび構成データはパッチが適用され、リージョン 1 に合致しています。
- 自動スケーリングが事前に構成済みです。
Azure Traffic Manager を使用したフェールオーバーを構成するには:
新しい Azure Traffic Manager プロファイルの作成。contoso123 という名前で新しい Azure Traffic Manager を作成し、ルーティング方法として Priority を選択します。 関連付けを行う既存のリソース グループがある場合は既存のリソース グループを選択でき、それ以外の場合は新しいリソース グループを作成します。
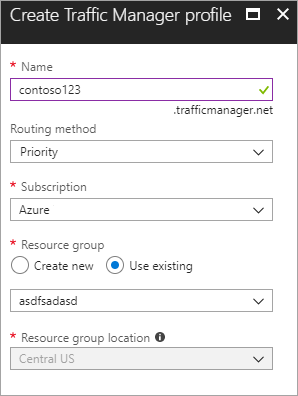
図 - Traffic Manager プロファイルの作成
Traffic Manager プロファイル内のエンドポイントの作成
この手順では、実稼働サイトとディザスター リカバリー サイトを指すエンドポイントを作成します。 ここでは、[Type]\(タイプ) を外部エンドポイントとして選択しますが、リソースが Azure でホストされている場合は、[Azure エンドポイント] も選択できます。 [Azure エンドポイント] を選択した場合、Azure によって割り当てられた [App Service] または [パブリック IP] のいずれかである [ターゲット リソース] を選択します。 これはリージョン 1 のプライマリ サービスであるため、優先順位は 1 に設定されます。 同様に、Traffic Manager 内でディザスター リカバリーエンド ポイントを作成します。
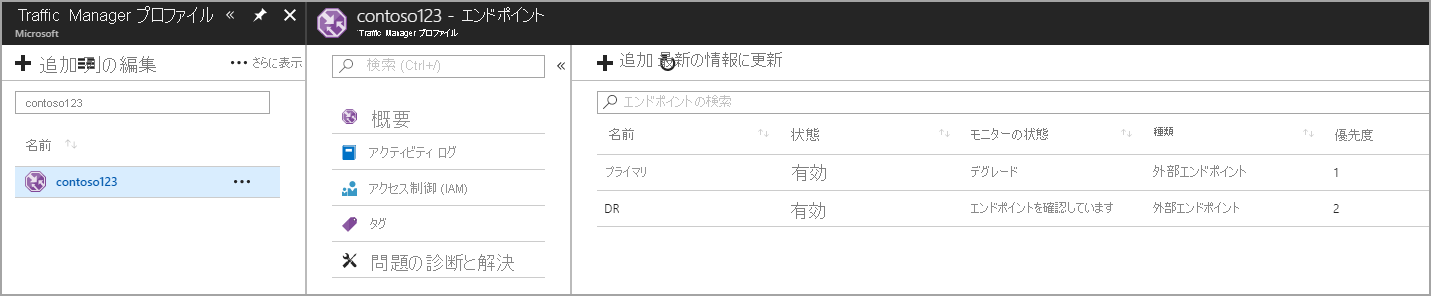
図 - ディザスター リカバリー エンドポイントの作成
正常性チェックとフェールオーバー構成の設定
この手順では、DNS の TTL を 10 秒に設定します。この時間はインターネットに接続されたほとんどの再帰的なリゾルバーで受け入れられる設定です。 この構成は、DNS リゾルバーが情報を 10 秒以上キャッシュしないことを意味します。 エンドポイント監視設定については、パスは現在 / すなわちルートに設定されていますが、たとえば prod.contoso.com/index などのパスを評価するためにエンドポイントの設定をカスタマイズできます。 以下の例ではプローブ プロトコルとして https が示されています。 ただし、http または tcp を選択することもできます。 プロトコルの選択は、目的のアプリケーションによって異なります。 プローブの間隔は、高速な調査を可能にする 10 秒に設定され、再試行回数は 3 に設定されます。 その結果、連続する 3 回の間隔でエラーが登録された場合、Traffic Manager は 2 番目のエンドポイントにフェールオーバーします。 自動フェールオーバーの合計時間は次の数式で定義されます。フェールオーバーの時間 = TTL + 再試行回数 * プローブ間隔。この場合、値は 10 + 3 * 10 = 40 秒 (最大) です。 再試行回数が 1 に設定され、TTL が 10 秒に設定された場合、フェールオーバーの時間は 10 + 1 * 10 = 20 秒になります。 偽陽性または ネットワークの軽微な一時的悪化によるフェールオーバーの可能性を排除するために、再試行回数を 1 より大きい値に設定してください。
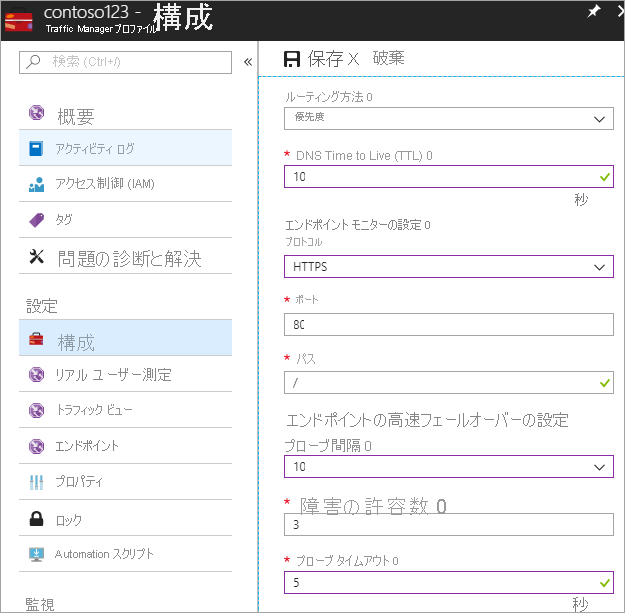
図 - 正常性チェックとフェールオーバー構成の設定