Microsoft Purview で Teradata に接続して管理する
この記事では、Teradata を登録する方法と、Microsoft Purview で Teradata を認証して操作する方法について説明します。 Microsoft Purview の詳細については、 入門記事を参照してください。
サポートされている機能
| メタデータ抽出 | フル スキャン | 増分スキャン | スコープスキャン | 分類 | ラベル付け | アクセス ポリシー | 系統 | データ共有 | ライブ ビュー |
|---|---|---|---|---|---|---|---|---|---|
| ○ | はい | いいえ | ○ | はい | いいえ | 不要 | はい* | 不要 | 不要 |
* データ ソース内の資産の系列に加えて、データセットが Data Factory または Synapse パイプラインのソース/シンクとして使用されている場合は、系列もサポートされます。
サポートされている Teradata データベースのバージョンは、12.x から 17.x です。
Teradata ソースをスキャンする場合、Microsoft Purview では次の処理がサポートされます。
以下を含む技術的なメタデータの抽出:
- サーバー
- Databases
- 列、外部キー、インデックス、制約を含むテーブル
- 列を含むビュー
- パラメーター データセットと結果セットを含むストアド プロシージャ
- パラメーター データセットを含む関数
テーブルとビュー間の資産リレーションシップに対する静的系列のフェッチ。
スキャンを設定するときに、Teradata サーバー全体をスキャンするか、指定された名前または名前パターンに一致するデータベースのサブセットにスキャンのスコープを設定できます。
既知の制限
オブジェクトがデータ ソースから削除された場合、現在、後続のスキャンでは、Microsoft Purview の対応する資産は自動的に削除されません。
スキャンに必要なアクセス許可
Microsoft Purview では、Teradata をスキャンするための基本認証 (ユーザー名とパスワード) がサポートされています。 ユーザーには、以下に示す個々のシステム テーブルごとに SELECT アクセス許可が付与されている必要があります。
grant select on dbc.tvm to [user];
grant select on dbc.dbase to [user];
grant select on dbc.tvfields to [user];
grant select on dbc.udtinfo to [user];
grant select on dbc.idcol to [user];
grant select on dbc.udfinfo to [user];
ビュー列のデータ型を取得するために、Microsoft Purview はビュー クエリごとに prepare ステートメント select * from <view> を発行し、データ型の詳細を含むメタデータを解析してパフォーマンスを向上させます。 ビューに対する SELECT データアクセス許可が必要です。 アクセス許可がない場合、ビュー列のデータ型はスキップされます。
分類の場合、ユーザーはサンプル データを取得するために、テーブル/ビューに対する読み取りアクセス許可も必要です。
前提条件
アクティブなサブスクリプションを持つ Azure アカウント。 無料でアカウントを作成します。
アクティブな Microsoft Purview アカウント。
ソースを登録し、Microsoft Purview ガバナンス ポータルで管理するには、データ ソース管理者とデータ 閲覧者のアクセス許可が必要です。 アクセス許可の詳細については、「 Microsoft Purview でのアクセス制御」を参照してください。
最新の セルフホステッド統合ランタイムを設定します。 詳細については、 セルフホステッド統合ランタイムの作成と構成に関するガイドを参照してください。
セルフホステッド統合ランタイムがインストールされているマシンに JDK 11 がインストールされていることを確認します。 JDK を新しくインストールして有効にした後、マシンを再起動します。
Visual C++ 再頒布可能パッケージ (バージョン Visual Studio 2012 Update 4 以降) がセルフホステッド統合ランタイム コンピューターにインストールされていることを確認します。 この更新プログラムがインストールされていない場合は、 こちらからダウンロードできます。
セルフホステッド統合ランタイムが実行されているコンピューターに Teradata JDBC ドライバー をダウンロードします。 スキャンの設定に使用するフォルダー パスをメモします。
注:
ドライバーには、セルフホステッド統合ランタイムからアクセスできる必要があります。 既定では、セルフホステッド統合ランタイムは ローカル サービス アカウント "NT SERVICE\DIAHostService" を使用します。 ドライバー フォルダーに対する "読み取りと実行" および "フォルダーの内容の一覧表示" アクセス許可があることを確認します。
登録
このセクションでは、 Microsoft Purview ガバナンス ポータルを使用して、Microsoft Purview に Teradata を登録する方法について説明します。
登録手順
次の方法で Microsoft Purview ガバナンス ポータルを開きます。
- Microsoft Purview アカウントに https://web.purview.azure.com 直接移動して選択します。
- Azure portalを開き、Microsoft Purview アカウントを検索して選択します。 [Microsoft Purview ガバナンス ポータル] ボタンを選択します。
左側のナビゲーションで [ データ マップ ] を選択します。
[ 登録] を選択します
[ソースの登録] で、[ Teradata] を選択します。 [ 続行] を選択します

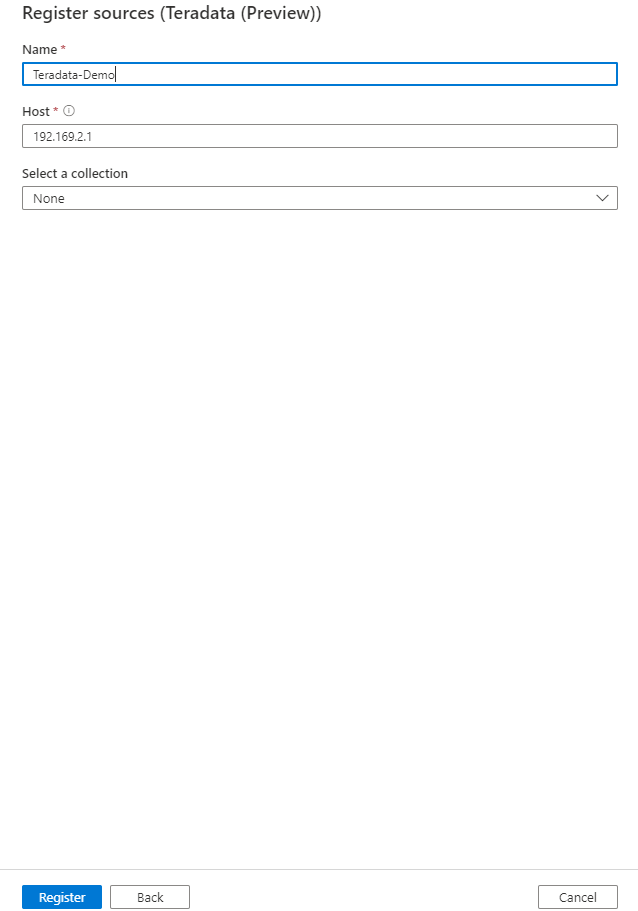
[ ソースの登録 (Teradata)] 画面で 、次の操作を行います。
カタログにデータ ソースが一覧表示される 名前 を入力します。
Teradata ソースに接続する ホスト 名を入力します。 サーバーの IP アドレスを指定することもできます。
コレクションを選択するか、新しいコレクションを作成します (省略可能)
完了してデータ ソースを登録します。
スキャン
Teradata をスキャンして資産を自動的に識別するには、次の手順に従います。 スキャン全般の詳細については、スキャン とインジェストの概要に関するページを参照してください。
スキャンの作成と実行
管理センターで、[ 統合ランタイム] を選択します。 セルフホステッド統合ランタイムが設定されていることを確認します。 設定されていない場合は、 ここで 説明する手順を使用してセルフホステッド統合ランタイムを設定します
Microsoft Purview ガバナンス ポータルの左側のウィンドウで [データ マップ] タブを選択します。
登録済みの Teradata ソースを選択します。
[新しいスキャン] を選択します
以下の詳細を指定します。
名前: スキャンの名前
統合ランタイム経由で接続する: 構成済みのセルフホステッド統合ランタイムを選択します。
資格情報: データ ソースに接続する資格情報を選択します。 次のことを確認してください。
- 資格情報の作成時に [基本認証] を選択します。
- [ユーザー名] 入力フィールドに、データベース サーバーに接続するユーザー名を指定します
- データベース サーバーのパスワードを秘密キーに格納します。
資格情報の詳細については、こちらのリンクを参照してください
スキーマ: インポートするデータベースのサブセットをセミコロン区切りリストとして一覧表示します。 例:
schema1; schema2。 そのリストが空の場合、すべてのユーザー データベースがインポートされます。 既定では、すべてのシステム データベース (SysAdmin など) とオブジェクトは無視されます。SQL LIKE 式構文を使用する許容されるデータベース名パターンには、%. を使用するものが含まれます。 例:
A%; %B; %C%; D- A または から始める
- B または で終わる
- C または を含む
- 等しい D
NOT 文字と特殊文字の使用は受け入れられません
ドライバーの場所: セルフホスト統合ランタイムが実行されているコンピューター内の JDBC ドライバーの場所へのパスを指定します (例:
D:\Drivers\Teradata)。 これは、有効な JAR フォルダーの場所へのパスです。 セルフホステッド統合ランタイムがドライバーにアクセスできることを確認します。前提条件 に関するセクションの詳細を参照してください。ストアド プロシージャの詳細: ストアド プロシージャからインポートされる詳細の数を制御します。
- 署名: ストアド プロシージャの名前とパラメーター。
- コード、署名: ストアド プロシージャの名前、パラメーター、コード。
- 系列、コード、署名: ストアド プロシージャの名前、パラメーター、コード、およびコードから派生したデータ系列。
- なし: ストアド プロシージャの詳細は含まれません。
使用可能な最大メモリ: プロセスのスキャンで使用する、お客様の VM で使用可能な最大メモリ (GB 単位)。 これは、スキャンする Teradata ソースのサイズによって異なります。
注:
経験則として、1000 テーブルごとに 2 GB のメモリを提供してください

[続行] を選択します。
分類用の スキャン ルール セット を選択します。 システムの既定値、既存のカスタム ルール セット、または 新しいルール セットをインラインで作成 することができます。
スキャン トリガーを選択します。 スケジュールを設定することも、スキャンを 1 回実行することもできます。
スキャンを確認し、[ 保存して実行] を選択します。
スキャンとスキャンの実行を表示する
既存のスキャンを表示するには:
- Microsoft Purview ガバナンス ポータルに移動します。 左側のウィンドウで、[ データ マップ] を選択します。
- データ ソースを選択します。 [最近のスキャン] で、そのデータ ソースの既存の スキャンの一覧を表示したり、[ スキャン ] タブですべてのスキャンを表示したりできます。
- 表示する結果を含むスキャンを選択します。 このウィンドウには、以前のすべてのスキャン実行と、各スキャン実行の状態とメトリックが表示されます。
- 実行 ID を選択して、スキャン実行の詳細をチェックします。
スキャンを管理する
スキャンを編集、取り消し、または削除するには:
Microsoft Purview ガバナンス ポータルに移動します。 左側のウィンドウで、[ データ マップ] を選択します。
データ ソースを選択します。 [最近のスキャン] で、そのデータ ソースの既存の スキャンの一覧を表示したり、[ スキャン ] タブですべてのスキャンを表示したりできます。
管理するスキャンを選択します。 次のことを実行できます。
- [スキャンの編集] を選択して スキャンを編集します。
- [スキャンの実行の取り消し] を選択して、進行中 のスキャンを取り消します。
- [スキャンの削除] を選択して スキャンを削除します。
注:
- スキャンを削除しても、以前のスキャンから作成されたカタログ資産は削除されません。
- ソース テーブルが変更され、Microsoft Purview の [スキーマ] タブで説明を編集した後にソース テーブルを再スキャンした場合、資産は スキーマ の変更で更新されなくなります。
系統
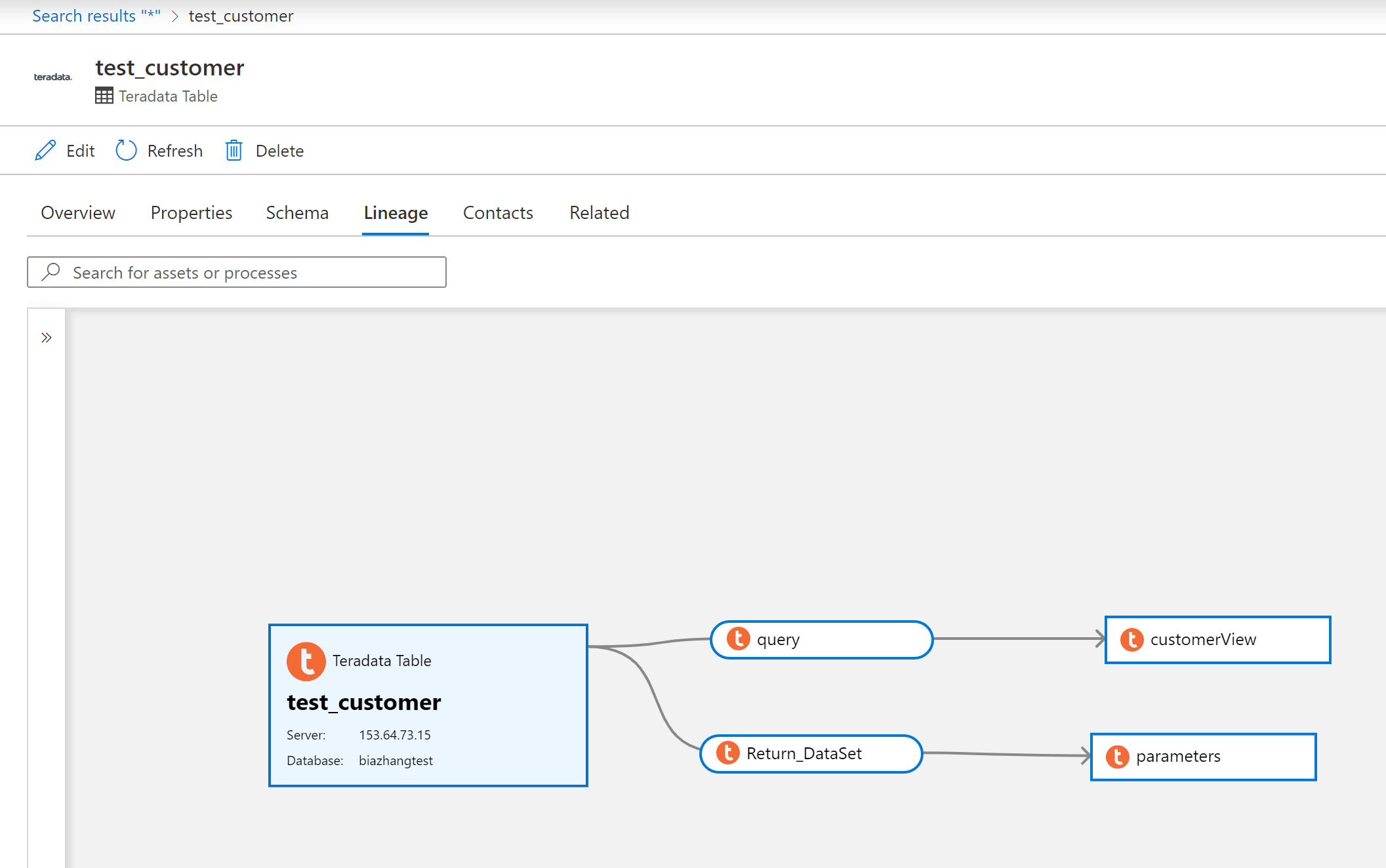
Teradata ソースをスキャンした後、 データ カタログ または 検索データ カタログ を参照して、資産の詳細を表示できます。
[資産 -> 系列] タブに移動すると、該当する場合に資産関係を確認できます。 サポートされている Teradata 系列シナリオのサポート されている機能 に関するセクションを参照してください。 系列全般の詳細については、「データ系列と系列ユーザー ガイド」を参照してください。
次の手順
ソースを登録したので、次のガイドに従って、Microsoft Purview とデータの詳細を確認してください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示