チュートリアル:デバッグ セッションを使用してスキルセットをデバッグする
スキルセットは、検索可能なコンテンツを分析、変換、または作成するスキルのアクションを調整します。 多くの場合、あるスキルの出力が別のスキルの入力になります。 入力が出力に依存している場合にスキルセットの定義およびフィールドの関連付けに誤りがあると、操作とデータが失われる可能性があります。
デバッグ セッションは、スキルセットの包括的な視覚化を提供する Azure portal ツールです。 このツールを使用することで、特定の手順にドリルダウンし、アクションが失敗していると考えられる場所が簡単にわかります。
この記事では、デバッグ セッションを使って、不足している入力と出力を見つけて修正します。 必要なものはチュートリアルにすべて含まれています。 サンプル データ、オブジェクトを作成する REST ファイル、スキルセットの問題をデバッグするための手順が用意されています。
Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
前提条件
Azure AI Search。 サービスを作成するか、現在のサブスクリプションから既存のサービスを検索します。 このチュートリアル用には、無料のサービスを使用できます。
サンプル データのホスト、およびデバッグ セッション中に作成されるキャッシュ データの保持に使用する BLOB ストレージ付き Azure Storage アカウント。
エンリッチメント パイプラインの作成に使用されるサンプル debug-sessions.rest ファイル。
Note
また、このチュートリアルでは、言語検出、エンティティ認識、キー フレーズ抽出に Azure Cognitive Services も使います。 ワークロードは非常に小さいので、最大 20 トランザクションの処理を無料で使用するために Azure AI サービスを内部で利用しています。 つまり、課金対象の Azure AI サービスリソースを作成しなくても、この演習を完了できるということです。
サンプル データを設定する
このセクションでは、Azure Blob Storage にサンプル データ セットを作成し、インデクサーとスキルセットに作業用コンテンツを用意します。
19 個のファイルから成るサンプル データ (clinical-trials-pdf-19) をダウンロードしてください。
Azure Storage アカウントを作成するか、既存のアカウントを検索してください。
帯域幅の料金を避けるため、リージョンは、Azure AI Search と同じものを選択してください。
[StorageV2 (汎用 v2)] のアカウントの種類を選択します。
ポータルの Azure Storage サービス ページに移動して、BLOB コンテナーを作成します。 アクセス レベルとして "プライベート" を指定することをお勧めします。 コンテナーの名前は
clinicaltrialdatasetにします。コンテナーの [アップロード] を選択して、最初の手順でダウンロードして解凍したサンプル ファイルをアップロードします。
ポータルで、Azure Storage の接続文字列をコピーします。 接続文字列は、ポータルの [設定]>[アクセス キー] から取得できます。
キーと URL をコピーする
REST 呼び出しでは、すべての要求で検索サービス エンドポイントと API キーが必要です。 これらの値は Azure portal から取得できます。
Azure portal にサインインし、[概要] ページに移動して URL をコピーします。 たとえば、エンドポイントは
https://mydemo.search.windows.netのようになります。[設定]>[キー] で管理者キーをコピーします。 管理者キーは、オブジェクトの追加、変更、削除で使用します。 2 つの交換可能な管理者キーがあります。 どちらかをコピーします。
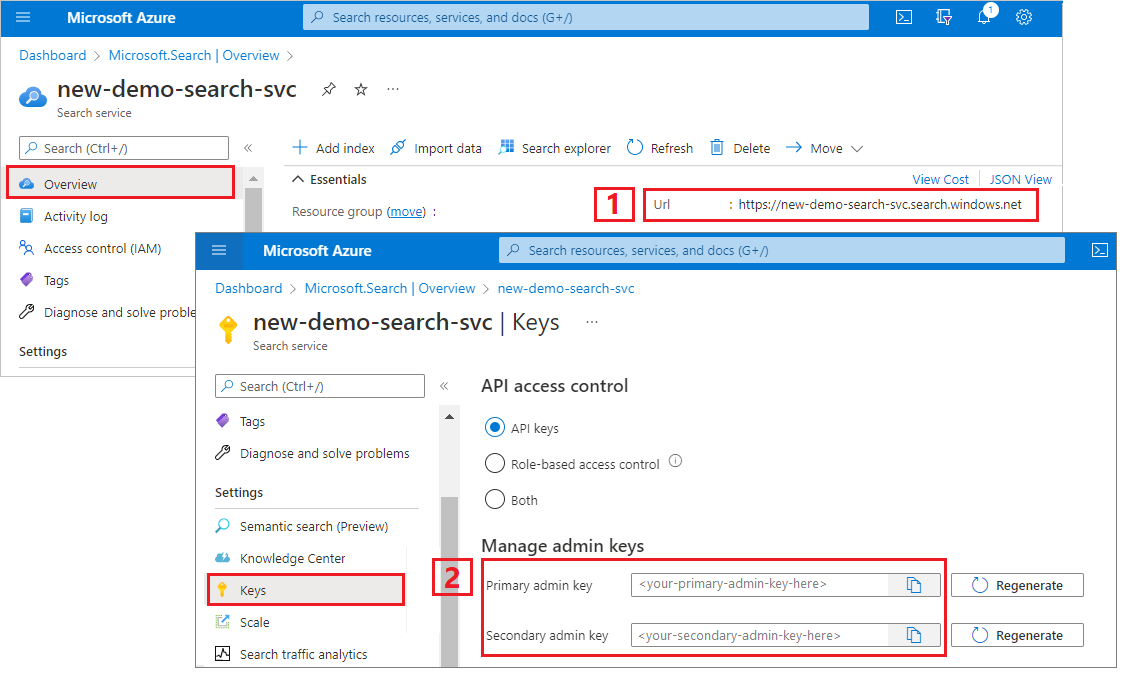
有効な API キーにより、要求を送信するアプリケーションとそれを処理する検索サービスとの間で、要求ごとに信頼が確立されます。
データ ソース、スキルセット、インデックス、およびインデクサーを作成する
このセクションでは、このチュートリアルで修正できる "バグのある" ワークフローを作成します。
Visual Studio Code を起動し、
debug-sessions.restファイルを開きます。次の変数を指定します。検索サービス URL、検索サービス管理 API キー、ストレージ接続文字列、PDF を格納する BLOB コンテナーの名前。
各要求を順番に送信します。 インデクサーの作成が完了するまでに数分かかります。
ファイルを閉じます。
ポータルで結果を確認する
このサンプル コードでは意図的に、スキルセットの実行中に発生した問題の結果としてバグのあるインデックスが作成されます。 問題は、インデックスのデータの欠落することです。
Azure portal の検索サービスの [概要] ページで、[インデックス] タブを選択します。
clinical-trials を選びます。
検索エクスプローラーの JSON ビューに、この JSON クエリ文字列を入力します。 特定のドキュメントのフィールドを返します (一意の
metadata_storage_pathフィールドで識別されます)。"select": "metadata_storage_path, organizations, locations", "count"=true`クエリを実行します。
organizationsとlocationsの空の値が表示されます。これらのフィールドには、(BLOB のコンテンツ内のあらゆる組織と場所を検出するために使用される) スキルセットのエンティティ認識スキルを通じて値が設定されているはずでした。 次の演習では、スキルセットをデバッグして問題の原因を特定します。
エラーと警告を調査する別の方法は、Azure portal を使用することです。
[インデクサー] タブを開き、clinical-trials-idxr を選びます。
全体としてはインデクサー ジョブが成功したものの、警告が発生したことに注目してください。
[成功] を選んで警告を表示します (大部分がエラーの場合、詳細リンクは [失敗] になります)。 インデックスによって出力されたすべての警告が記載された長いリストが表示されます。

デバッグ セッションを開始する
検索サービスの左側のナビゲーション ウィンドウの [検索管理] で、[セッションのデバッグ] を選択します。
+ デバッグ セッションの追加 を選択します。
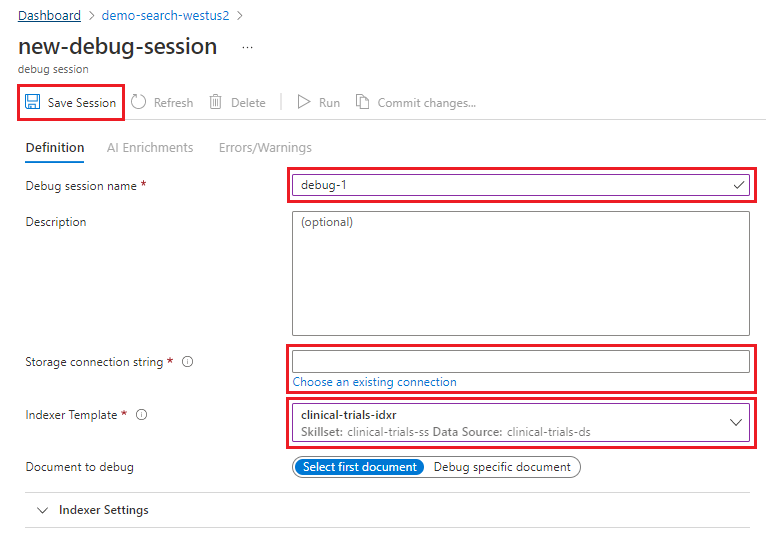
セッションに名前を指定します。
セッションをストレージ アカウントに接続します。 「デバッグ セッション」という名前のコンテナーを作成します。 このコンテナーを繰り返し使用して、すべてのデバッグ セッション データを格納できます。
検索とストレージの間の信頼された接続を構成した場合は、接続のユーザーマネージド ID またはシステム ID を選択します。 それ以外の場合は、既定値 (None) を使用します。
インデクサー テンプレートで、インデクサー名を指定します。 インデクサーには、データ ソース、スキルセット、およびインデックスへの参照があります。
コレクション内の最初のドキュメントとして、既定のドキュメント選択を受け入れます。 デバッグ セッションは、1 つのドキュメントでのみ機能します。 デバッグするドキュメントを選択することも、単純に最初の 1 つを使用することもできます。
セッションを保存します。 セッションを保存すると、選んだドキュメントのスキルセットでの定義に従ってエンリッチメント パイプラインが開始されます。
デバッグ セッションの初期化が完了すると、セッションでは既定で [AI Enrichments](AI エンリッチメント) タブが表示され、スキル グラフが強調表示されます。 スキル グラフには、スキルセットの視覚的な階層とその実行順序が順番に並べて表示されます。
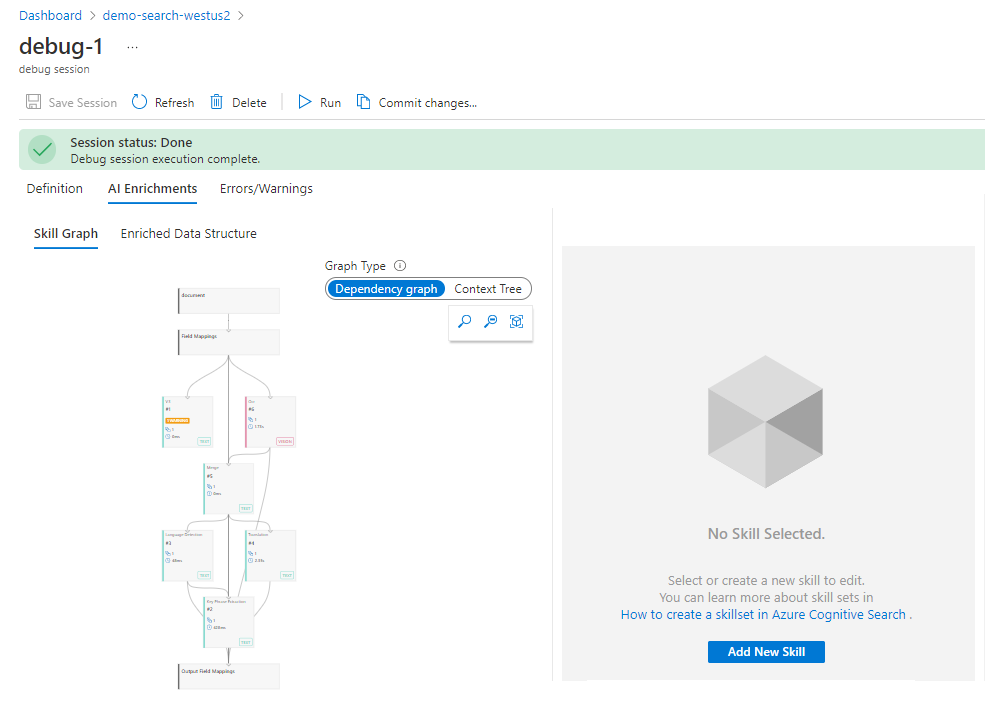
スキルセットに関する問題を検出する
インデクサーによってレポートされた問題はすべて、隣接する [エラー/警告] タブで確認できます。
![[エラーと警告] タブのスクリーンショット。](media/cognitive-search-debug/debug-session-errors-warnings.png)
[エラー/警告] タブには、前に表示された一覧よりもはるかに細かい一覧が表示されることに注意してください。この一覧には、1 つのドキュメントのエラーの詳細のみが表示されるためです。 インデクサーによって表示される一覧と同様に、警告メッセージを選択して、その警告の詳細を確認できます。
[エラー/警告] を選択して通知を確認します。 次の 4 つが表示されます。
「1 つ以上のスキルの入力が無効だったため、スキルを実行できませんでした。 Required skill input is missing. (必須のスキルの入力がありません。) 名前: 'text'、ソース: '/document/content'。"
"出力フィールド "locations" を検索インデックスにマップできませんでした。 インデクサーの "outputFieldMappings" プロパティを確認してください。 "/document/merged_content/locations" の値がありません。"
"出力フィールド "organizations" を検索インデックスにマップできませんでした。 インデクサーの "outputFieldMappings" プロパティを確認してください。 "/document/merged_content/organizations" の値がありません。"
「スキルは実行されましたが、1 つ以上のスキルの入力が無効だったため、予期しない結果が生じる可能性があります。 省略可能なスキルの入力がありません。 名前: "languageCode"、ソース: "/document/languageCode"。 式言語が問題を解析中:"/document/languageCode" の値がありません。"
多くのスキルには "languageCode" パラメーターがあります。 操作を検査することで、EntityRecognitionSkill.#1 からこの言語コード入力が不足していることがわかります。これは、"locations" と "organizations" の出力に問題を抱える同じエンティティ認識スキルです。
4 つの通知はすべてこのスキルに関するものなので、次のステップでは、このスキルをデバッグします。 可能であれば、先に入力の問題を解決してから、出力の問題に進んでください。
不足しているスキル入力値を修正する
[エラー/警告] タブでは、EntityRecognitionSkill.#1 というラベルが付いた操作の入力値が 2 つ不足しています。 1 つ目のエラーの詳細は、'テキスト' の必須の入力が不足していることの説明です。 2 つ目は、入力値 "/document/languageCode" に問題があることを示しています。
[AI Enrichments](AI エンリッチメント)>[Skill Graph](スキル グラフ) で #1 というラベルが付いたスキルを選ぶと、右ペインにその詳細が表示されます。
[実行] タブを選び、"text" の入力を確認します。
</> 記号を選ぶと、式エバリュエーターが開きます。 この入力に表示される結果は、テキスト入力のようには見えません。 テキストではなく、一連の改行文字
\n \n\n\n\nのように見えます。 テキストがないということは、エンティティが特定できないことを意味するので、このドキュメントはスキルの前提条件を満たしていないか、代わりに使う必要がある別の入力があります。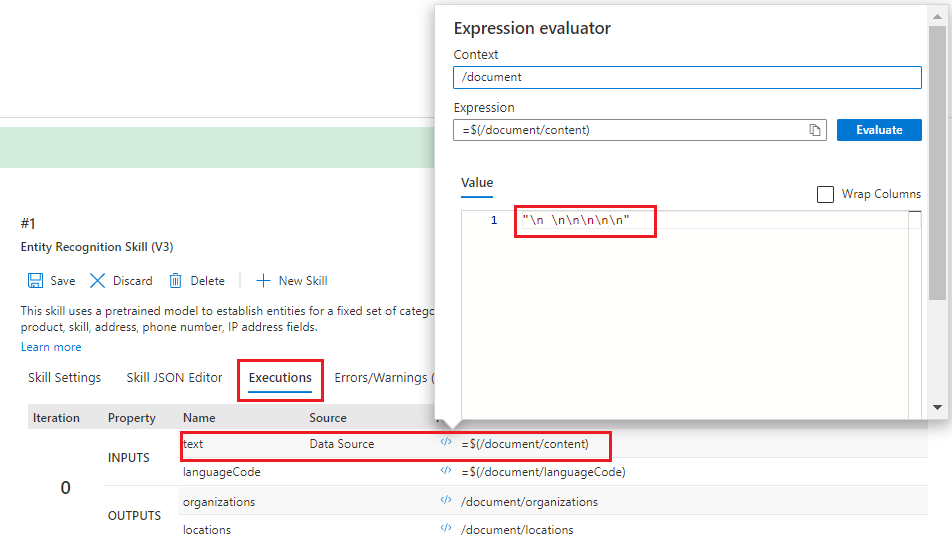
左側のペインを [Enriched Data Structure](エンリッチされたデータ構造) に切り替え、このドキュメントのエンリッチメント ノードの一覧を下にスクロールします。 "content" の
\n \n\n\n\nには送信元がありませんが、"merged_content" の別の値には OCR 出力があることに注目してください。 表示はありませんが、抽出され、処理されたテキストが "merged_content" にはあることから、この PDF のコンテンツは JPEG ファイルであると思われます。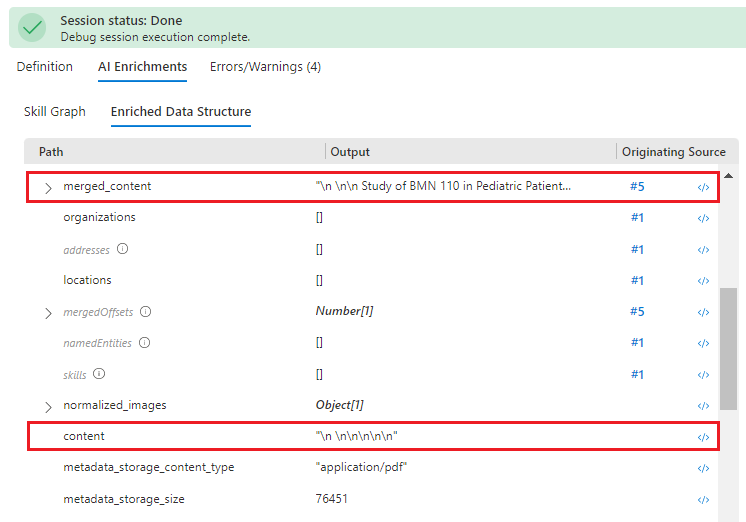
右側のペインで、#1 スキルの [実行] を選び、入力 "text" の 式エバリュエーター </> を開きます。
式を
/document/contentから/document/merged_contentに変更し、[Evaluate](評価) を選びます。 コンテンツがテキストのチャンクになり、エンティティ認識に利用できることに注目してください。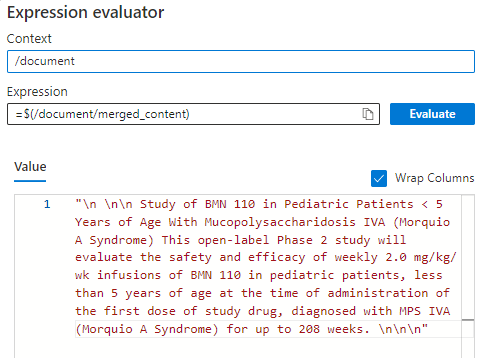
[Skill JSON Editor](スキル JSON エディター) に切り替えます。
16 行目の「入力」で
/document/contentを/document/merged_contentに変更します。{ "name": "text", "source": "/document/merged_content" },[Skill Details](スキルの詳細) ペインで [保存] を選びます。
![スキルセットの詳細の [保存] コマンドのスクリーンショット。](media/cognitive-search-debug/skill-details-save.png)
セッションのウィンドウ メニューで [実行] を選びます。 これにより、ドキュメントを使用してスキルセットの別の実行が開始されます。
デバッグ セッションの実行が完了したら、[エラー/警告] タブを確認すると、テキスト入力のエラーはなくなっていますが、その他の警告は残っています。 次の手順は、"languageCode" に関する警告に対処することです。

[実行] タブを選び、"languageCode" の入力を確認します。
</> 記号を選ぶと、式エバリュエーターが開きます。 「languageCode」プロパティが有効な入力ではないことを確認します。
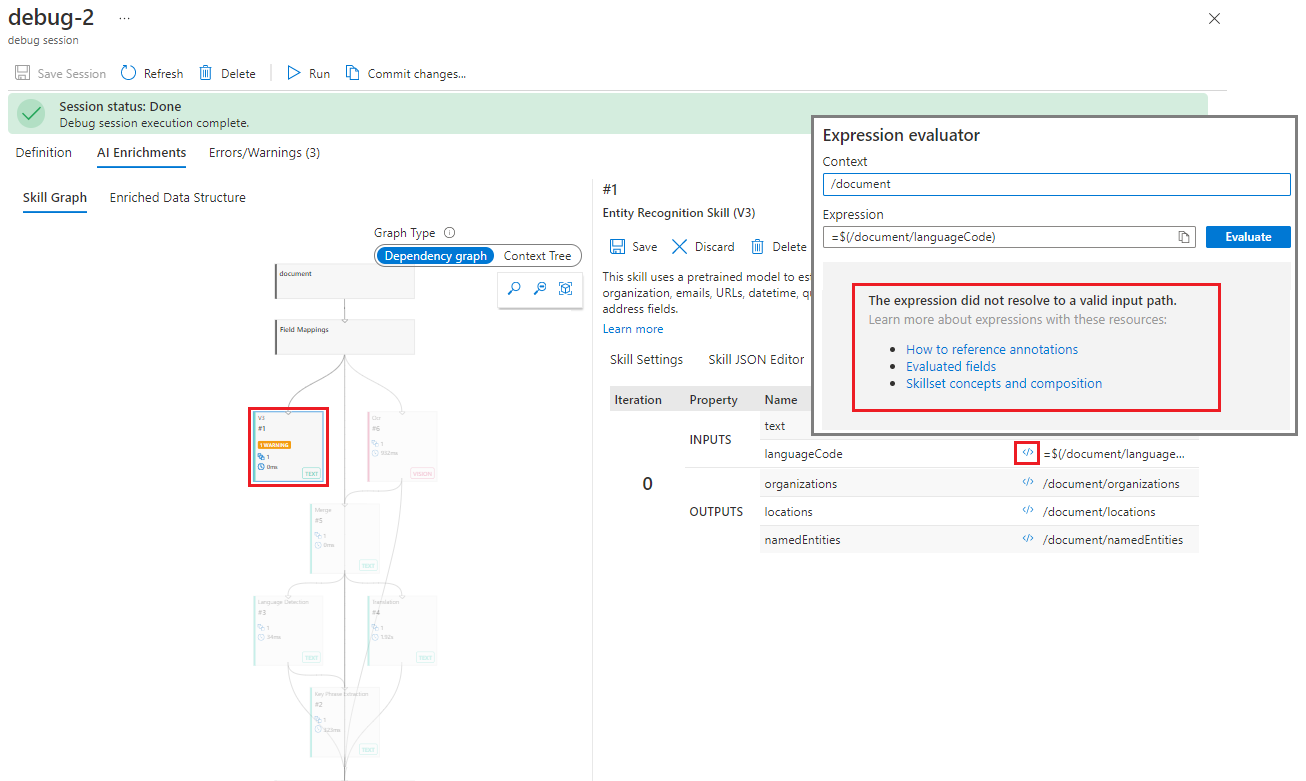
このエラーを調査するには、2 つの方法があります。 1 つ目は、入力がどこから来ているかを調べることです。この結果を生成すると考えられるのは、階層内のどのスキルでしょうか。 スキルの詳細ペインの [実行] タブに、入力のソースが表示されるはずです。 ソースが存在しない場合は、フィールド マッピング エラーであることを意味します。
[実行] タブの [INPUTS](入力) を確認し、"languageCode" を見つけます。 この入力のソースが一覧に表示されていません。
左側のペインを [Enriched Data Structure](エンリッチされたデータ構造) に切り替えます。 このドキュメントのエンリッチメント ノードの一覧を下にスクロールします。 "languageCode" ノードはありませんが、"language" にはあることに注目してください。 つまり、スキルの設定に入力ミスがあります。
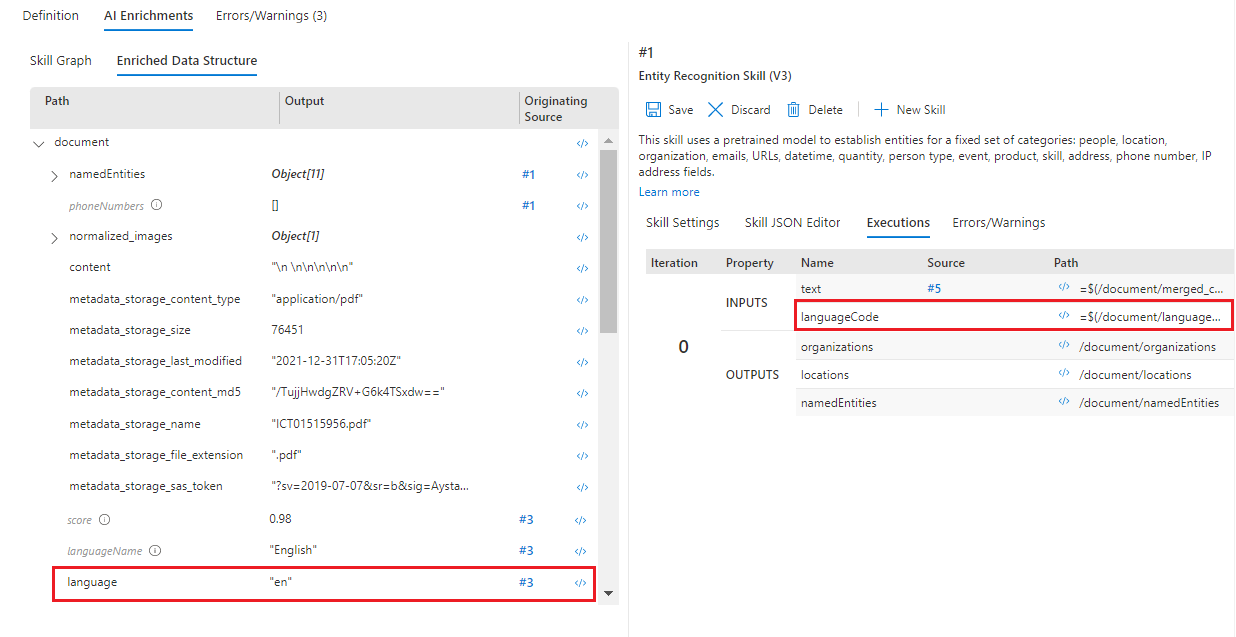
[Enriched Data Structure](エンリッチされたデータ構造) で、"language" ノードの 式エバリュエーター </> を開き、式
/document/languageをコピーします。右側のペインで #1 スキルの [Skill Settings](スキルの設定) を選び、入力 "languageCode" の式エバリュエーター </> を開きます。
新しい値
/document/languageを [式] ボックスに貼り付けて、[評価] を選択します。 正しい入力 "en" が表示されるはずです。[保存] を選択します。
[実行] を選択します。
デバッグ セッションの実行が完了した後、[エラー/警告] タブを確認すると、入力に関する警告がすべてなくなっていることがわかります。 ここでは、組織と場所の出力フィールドに関する 2 つの警告のみが残っています。
不足しているスキル出力値を修正する
メッセージには、インデクサーの 'outputFieldMappings' プロパティを確認するように指示されているので、そこから始めましょう。
[Skill Graph](スキル グラフ) に移動し、[Output Field Mappings](出力フィールドのマッピング) を選びます。 マッピングは実際に正しいのですが、通常はインデックスの定義を確認して、"locations" と "organizations" のフィールドが存在することを確認します。
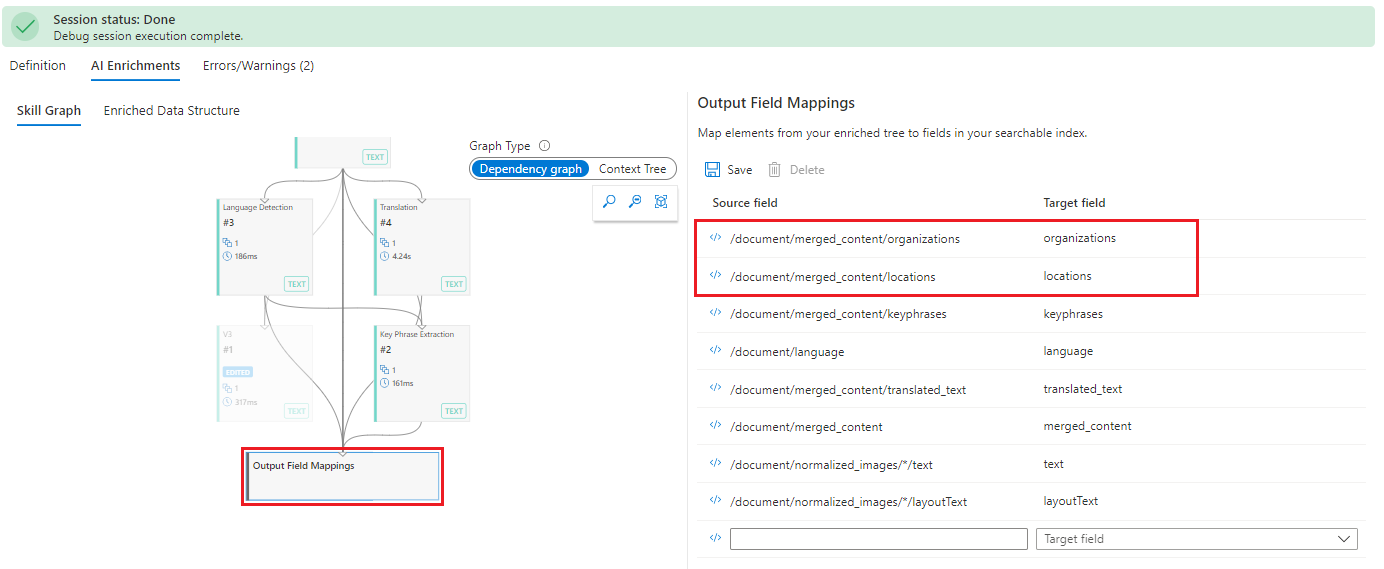
インデックスに問題がなければ、次の手順はスキルの出力を確認することです。 先ほどと同様に、[Enriched Data Structure](エンリッチされたデータ構造) を選び、ノードをスクロールして "location" と "organization" を見つけます。 親が "merged_content" ではなく "content" であることに注意してください。 コンテキストが正しくありません。
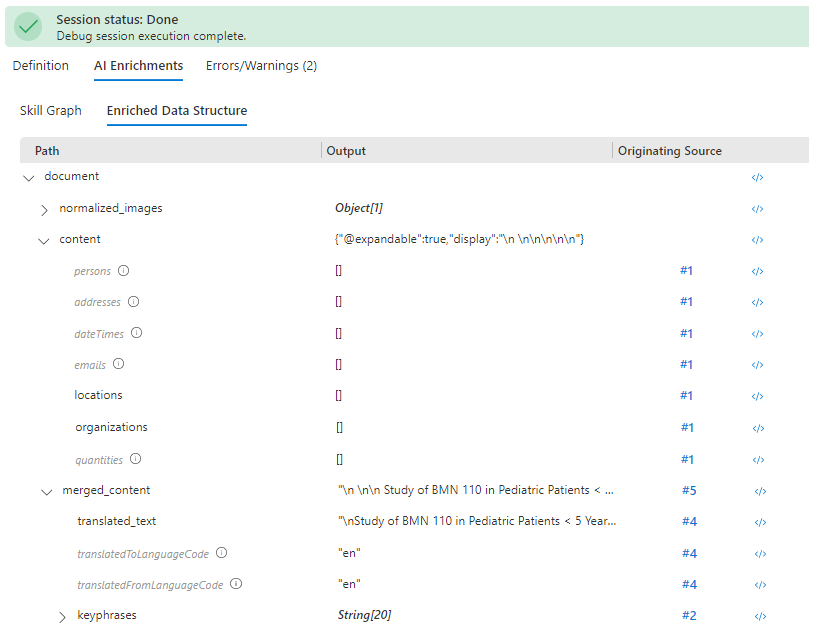
[Skill Graph](スキル グラフ) に戻り、エンティティ認識スキルを選びます。
スキルの設定内を移動して、"context" を探します。
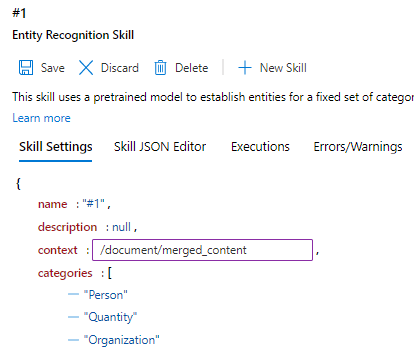
"context" の設定をダブルクリックして、"/document/merged_content" となるように編集します。
[保存] を選択します。
[実行] を選択します。
すべてのエラーが解決されました。
スキルセットに変更をコミットする
デバッグ セッションが開始されたとき、検索サービスによってスキルセットのコピーが作成されました。 これは、自分の検索サービスで元のスキルセットを保護するために行われました。 スキルセットのデバッグが完了したので、修正をコミット (元のスキルセットを上書き) できるようになりました。
または、変更をコミットする準備ができていない場合は、デバッグ セッションを保存し、後でそれを開き直すことができます。
メイン デバッグ セッション メニューの [Commit changes](変更のコミット) を選びます。
[OK] を選んで、スキルセットの更新に同意します。
デバッグ セッションを閉じ、左側のナビゲーション ウィンドウから [インデクサー] を開きます。
'clinical-trials-idxr' を選択します。
[リセット] を選択します。
[実行] を選択します。
[更新] を選択して、リセットコマンドと実行コマンドの状態を表示します。
インデクサーの実行が完了すると、 [実行履歴] タブに緑色のチェックマークが表示され、最新の実行のタイム スタンプの横に "成功" という単語が表示されるはずです。変更が適用されたことを確認するには、次のようにします。
左側のナビゲーション ウィンドウで、[インデックス] を開きます。
'clinical-trials' インデックスを開き、[検索エクスプローラー] タブで、(一意の
metadata_storage_pathフィールドで識別される) 特定のドキュメントのフィールドを返すクエリ文字列:$select=metadata_storage_path, organizations, locations&$count=trueを入力します。[Search] を選択します。
結果として、組織と場所に想定される値が設定されるようになったことがわかるはずです。
リソースをクリーンアップする
独自のサブスクリプションを使用している場合は、プロジェクトの最後に、作成したリソースがまだ必要かどうかを確認してください。 リソースを実行したままにすると、お金がかかる場合があります。 リソースは個別に削除することも、リソース グループを削除してリソースのセット全体を削除することもできます。
ポータルの左側のナビゲーション ウィンドウにある [All resources](すべてのリソース) または [Resource groups](リソース グループ) リンクを使って、リソースを検索および管理できます。
無料サービスでは、3 つのインデックス、インデクサー、データ ソースに制限されます。 ポータルで個別の項目を削除して、制限を超えないようにすることができます。
次のステップ
このチュートリアルでは、スキルセットの定義および処理のさまざまな側面について紹介しました。 概念とワークフローの詳細については、次の記事を参照してください。