クイック スタート: Azure portal でナレッジ ストアを作成する
このクイック スタートでは、Azure AI Search で、AI エンリッチメント パイプラインから生成された出力用のリポジトリとして機能するナレッジ ストアを作成します。 ナレッジ ストアは、生成されたコンテンツを検索以外のワークロードのために Azure Storage で利用できるようにします。
まず、Azure Storage にいくつかのサンプル データを設定します。 次に、[データのインポート] ウィザードを実行して、ナレッジ ストアも生成するエンリッチメント パイプラインを作成します。 このナレッジ ストアには、データ ソース (ホテルの顧客レビュー) からプルされた元のソース コンテンツに加えて、AI によって生成されたコンテンツ (センチメント ラベル、キー フレーズ抽出、非英語圏の顧客のコメントのテキスト翻訳など) が含まれます。
前提条件
作業を開始する前に、次の前提条件を満たしておく必要があります。
アクティブなサブスクリプションが含まれる Azure アカウント。 無料でアカウントを作成できます。
Azure AI Search。 サービスを作成するか、アカウントで既存のサービスを検索します。 このクイック スタート用には、無料のサービスを使用できます。
Azure Storage です。 アカウントを作成するか、既存のアカウントを検索します。 アカウントの種類は、 [StorageV2 (general purpose V2)](StorageV2 (汎用 V2)) であることが必要です。
Azure Storage でホストされているサンプル データ:
HotelReviews_Free.csv をダウンロードします。 この CSV には、1 つのホテルに関する 19 個のお客様のフィードバックが含まれています (ソースは Kaggle.com)。 このファイルは、他のサンプル データを含むリポジトリにあります。 リポジトリ全体が不要な場合は、生のコンテンツをコピーし、デバイス上のスプレッドシート アプリに貼り付けます。
Azure Storage の BLOB コンテナーにファイルをアップロードします。
また、このクイックスタートでは Azure AI サービスを AI エンリッチメントに使用します。 ワークロードは非常に小さいので、最大 20 トランザクションの処理を無料で使用するために Azure AI サービスを内部で利用しています。 つまり、追加の Azure AI マルチサービス リソースを作成しなくても、この演習を完了できます。
ウィザードを起動する
Azure アカウントで Azure Portal にサインインします。
検索サービスを見つけ、[概要] ページで、コマンド バーの [データのインポート] を選び、4 つのステップでナレッジ ストアを作成します。

手順 1:データ ソースを作成する
データは、1 つの CSV ファイル内の複数行であるため、行ごとに 1 つの検索ドキュメントを取得するように解析モードを設定します。
[データへの接続] で、 [Azure Blob Storage] を選択します。
[名前] には、「hotel-reviews-ds」と入力します。
[抽出されるデータ] には、[コンテンツとメタデータ] を選びます。
[解析モード] で [Delimited text](区切りテキスト) を選択し、 [最初の行にヘッダーが含まれています] チェック ボックスをオンにします。 [区切り記号文字] がコンマ (,) になっていることを確認します。
ストレージ アカウントが同じサブスクリプションにある場合は、[接続文字列] で既存の接続を選びます。 それ以外の場合は、接続文字列を Azure Storage アカウントに貼り付けます。
接続文字列は、次の形式でフル アクセスできます:
DefaultEndpointsProtocol=https;AccountName=<YOUR-ACCOUNT-NAME>;AccountKey=<YOUR-ACCOUNT-KEY>;EndpointSuffix=core.windows.netまたは、Azure Storage でロールが構成および割り当てられていると想定して、接続文字列を使用してマネージド ID を参照できます:
ResourceId=/subscriptions/{YOUR-SUBSCRIPTION-ID}/resourceGroups/{YOUR-RESOURCE-GROUP-NAME}/providers/Microsoft.Storage/storageAccounts/{YOUR-ACCOUNT-NAME};[コンテナー] で、データを保持している BLOB コンテナーの名前 (「hotel-reviews」) を入力します。
実際のページは次のスクリーンショットのようになります。
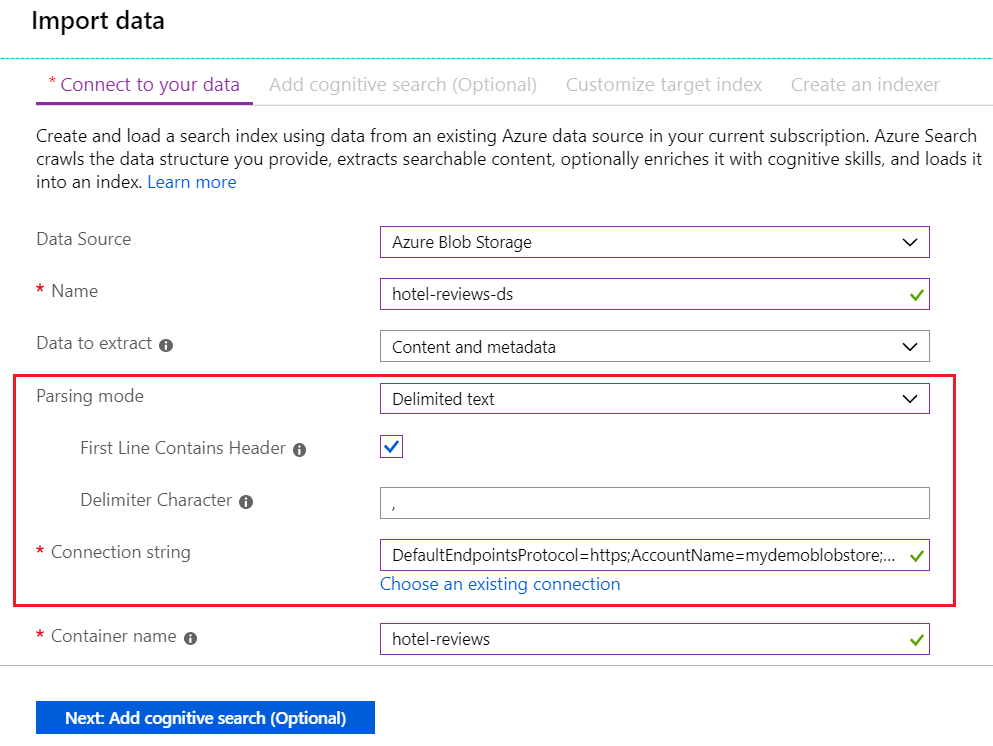
次のページに進みます。
手順 2: スキルを追加する
ウィザードのこの手順では、AI エンリッチメントのスキルを追加します。 ソース データは、英語とフランス語の顧客レビューで構成されています。 このデータ セットに関連するスキルには、キー フレーズ抽出、センチメント検出、テキスト翻訳などがあります。 これらのエンリッチメントは、後の手順でナレッジ ストアに Azure テーブルとして "投影" されます。
[Azure AI サービスのアタッチ] を展開します。 既定では [無料 (制限付きのエンリッチメント)] が選択されます。 この無料リソースで許容されるトランザクションは 1 日あたり最大 20 件です。HotelReviews-Free.csv のレコード数は 19 件なので、このリソースを使用することができます。
[エンリッチメントの追加] を展開します。
[スキルセット名] には、「hotel-reviews-ss」と入力します。
[ソース データ] フィールドには reviews_text を選択します。
[エンリッチメントの粒度レベル] で [ページ (5,000 文字チャンク)] を選択します。
[テキストの認知技術] に、次のスキルを選択します。
- キー フレーズを抽出する
- テキストを翻訳する
- 言語検出
- センチメントを検出する
ページは次のスクリーンショットのようになります。

下にスクロールして [Save enrichments to knowledge store](ナレッジ ストアにエンリッチメントを保存する) を展開します。
[既存の接続を選択します] を選択し、Azure Storage アカウントを選択します。 [コンテナー] ページが表示され、プロジェクション用のコンテナーを作成できます。 ソース コンテンツとナレッジ ストア コンテンツを区別するために、"kstore-hotel-reviews" のようなプレフィックスの名前付け規則を採用することをお勧めします。
データのインポート ウィザードに戻り、次の [Azure テーブルのプロジェクション] を選択します。 このウィザードでは、ドキュメント プロジェクションは常に提供されます。 その他のプロジェクションは、選択したスキル (キー フレーズなど)、またはエンリッチメントの粒度レベル (ページ) に応じて提供されます。
- ドキュメント
- ページ
- キー フレーズ
次のスクリーンショットは、ウィザード内のテーブルのプロジェクションの選択項目を示しています。

次のページに進みます。
手順 3:インデックスの構成
ウィザードのこの手順では、オプションのフルテキスト検索クエリ用のインデックスを構成します。 ナレッジ ストアの検索インデックスは必要ありませんが、インデクサーを実行するには検索インデックスが必要です。
この手順では、ウィザードでデータ ソースをサンプリングしてフィールドとデータ型を推測します。 必要なのは、目的の動作に対応した属性を選択することだけです。 たとえば [取得可能] 属性を選択した場合、検索サービスからフィールド値を取得することができます。これに対し、[検索可能] 属性を選択した場合、そのフィールドに対するフルテキスト検索が可能になります。
[インデックス名] には、「hotel-reviews-idx」と入力します。
以下の属性については、既定の設定をそのまま使用します。パイプラインによって作成されている新しいフィールドの [取得可能] と [検索可能] 。
インデックスは、次の画像のようになります。 一覧が長いため、この画像には一部のフィールドが表示されていません。
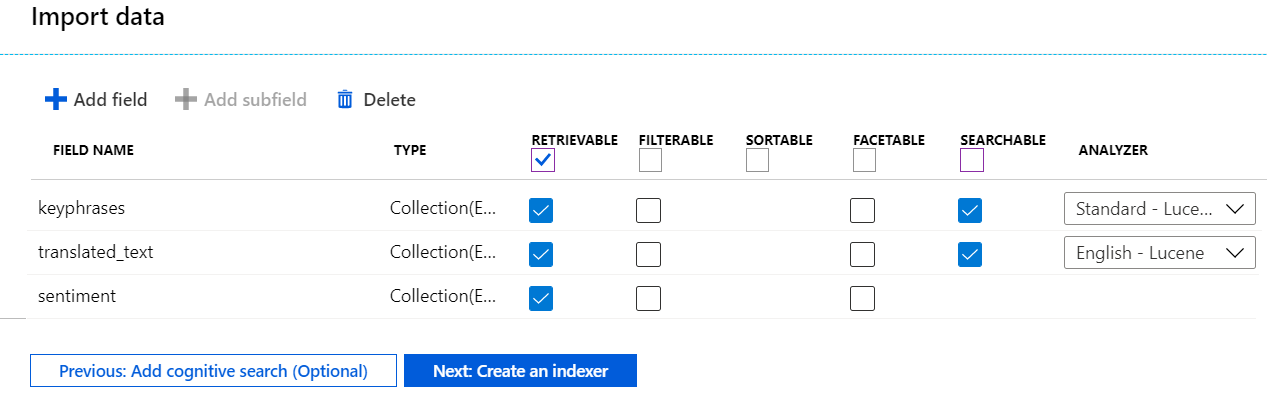
次のページに進みます。
手順 4: インデクサーを構成して実行する
ウィザードのこの手順では、ウィザードのこれまでの手順で定義したデータ ソース、スキルセット、インデックスをまとめるインデクサーを構成します。
[名前] には、「hotel-reviews-idxr」と入力します。
[スケジュール] では、既定値の [Once](1 回) のままにします。
[送信] を選択してインデクサーを実行します。 データの抽出、インデックス作成、コグニティブ スキルの適用がすべて、この手順で実行されます。
手順 5: 状態を確認する
[概要] ページで、ページの中央にある [インデクサー] タブを開き、hotels-reviews-idxr を選択します。 1、2 分以内に、状態が "進行中" から "成功" になり、エラーと警告数がゼロになります。
Azure portal でテーブルを確認する
Azure portal で、ナレッジ ストアの作成に使用した Storage アカウントを開きます。
ストレージ アカウントの左側のナビゲーション ウィンドウで、[ストレージ ブラウザー (プレビュー)] を選び、新しいテーブルを表示します。
[エンリッチメントの追加] ページの [Save enrichments](エンリッチメントの保存) セクションで提供されたプロジェクションごとに、3 つのテーブルが表示されます。
"hotelReviewssDocuments" には、ドキュメントのエンリッチメント ツリーの、コレクションではない、第 1 レベルのノードがすべて含まれます。
"hotelReviewssKeyPhrases" には、すべてのレビューから抽出されたキー フレーズの長いリストが含まれます。 キー フレーズやエンティティなど、コレクション (配列) を出力するスキルでは、出力はスタンドアロン テーブルに送信されます。
"hotelReviewssPages" には、ドキュメントから分割された各ページに対して作成されたエンリッチメントされたフィールドが含まれます。 このスキルセットとデータ ソースでは、センチメント ラベルと翻訳されたテキストで構成されるページレベルのエンリッチメントです。 スキルセット定義で "ページ" 粒度を選択すると、ページ テーブル (特定の粒度レベルを指定した場合は文テーブル) が作成されます。
これらのテーブルすべてに、他のツールやアプリでテーブルのリレーションシップをサポートするための ID 列が含まれています。 テーブルを開いたときに、これらのフィールドの下までスクロールして、パイプラインによって追加されたコンテンツ フィールドを表示します。
このクイックスタートでは、"hotelReviewssPages" のテーブルは次のスクリーンショットのようになります。
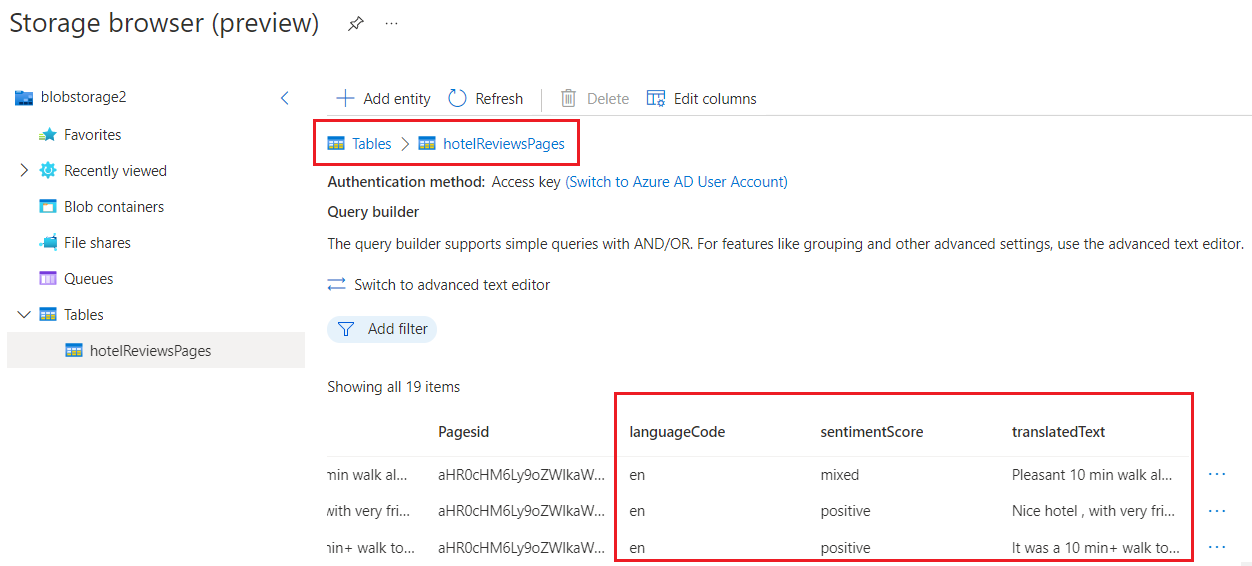
クリーンアップ
独自のサブスクリプションを使用している場合は、プロジェクトの最後に、作成したリソースがまだ必要かどうかを確認してください。 リソースを実行したままにすると、お金がかかる場合があります。 リソースは個別に削除することも、リソース グループを削除してリソースのセット全体を削除することもできます。
ポータルの左側のナビゲーション ウィンドウにある [All resources](すべてのリソース) または [Resource groups](リソース グループ) リンクを使って、リソースを検索および管理できます。
無料サービスを使っている場合は、3 つのインデックス、インデクサー、およびデータソースに制限されることに注意してください。 ポータルで個別の項目を削除して、制限を超えないようにすることができます。
ヒント
この演習を繰り返したい場合や、別の AI エンリッチメントのチュートリアルを試したい場合は、hotel-reviews-idxr インデクサーと関連オブジェクトを削除し、再作成してください。 インデクサーを削除すると、1 日あたりの無料トランザクションのカウンターがリセットされ、ゼロに戻ります。
次のステップ
ここでは、ナレッジ ストアを紹介しました。REST API のチュートリアルに進んで各手順を詳しく見ていきましょう。 ウィザードが内部的に処理したタスクについては、REST チュートリアルで説明します。