Azure AI Search でインデクサーを作成する
Azure AI Search でデータ インポートとインデックス付けを自動化するには、インデクサーを使用します。 インデクサーは、外部の Azure データ ソースに接続し、データを読み取り、インデックス作成のために検索エンジンに渡される、検索サービス上の名前付きオブジェクトです。 インデクサーを使用すると、サポート対象のデータ ソースを使用している場合に記述する必要のあるコードの量と複雑さが大幅に減少します。
インデクサーでは、次の 2 つのワークフローがサポートされています。
テキストベースのインデックス作成。フル テキスト検索のシナリオ用に文字列とメタデータをテキスト コンテンツから抽出します。
スキルベースのインデックス作成。画像や大規模な未分化コンテンツを分析するための統合機械学習を追加する組み込みスキルまたはカスタム スキルを使用して、テキストと構造を抽出または推論します。 スキルベースのインデックス作成を使用すると、他の方法では簡単にフルテキスト検索できないコンテンツを検索できます。 詳細については、Azure AI Search における AI エンリッチメントに関する記事を参照してください。
この記事は、インデクサーの作成の基本手順に焦点を合わせています。 データ ソースとワークフローによっては、その他の構成が必要な場合があります。
前提条件
取り込むコンテンツが含まれている、サポート対象のデータソース。
外部データへの接続を設定するインデクサー データ ソース。
受信データを受け入れることができる検索インデックス。
サービス レベルの上限を超えていない。 Free レベルでは、各種類のオブジェクトを 3 つと、1 分から 3 分のインデクサー処理、またはスキルセットがある場合は 3 分から 10 分を使用できます。
インデクサー パターン
インデクサーの作成時に、定義は、テキストベースのインデックス作成、またはスキルによる AI エンリッチメントという 2 つのパターンのいずれかです。 スキルベースのインデックス作成に定義が多い点を除き、パターンは同じです。
テキストベースのインデックス作成のためのインデクサーの例
フルテキスト検索のためのテキストベースのインデックス作成は、インデクサーの主なユースケースであり、このワークフローでは、インデクサーは次の例のようになります。
{
"name": (required) String that uniquely identifies the indexer,
"description": (optional),
"dataSourceName": (required) String indicating which existing data source to use,
"targetIndexName": (required) String indicating which existing index to use,
"parameters": {
"batchSize": null,
"maxFailedItems": 0,
"maxFailedItemsPerBatch": 0,
"base64EncodeKeys": false,
"configuration": {}
},
"fieldMappings": (optional) unless field discrepancies need resolution,
"disabled": null,
"schedule": null,
"encryptionKey": null
}
インデクサーの要件は次のとおりです。
- インデクサー コレクション内のインデクサーを一意に識別する
"name"プロパティ。 - データ ソース オブジェクトを指す
"dataSourceName"プロパティ。 外部データへの接続を指定します。 - ターゲットの検索インデックスを指す
"targetIndexName"プロパティ。
その他のパラメーターは省略可能ですが、ジョブ全体が失敗する前にいくつのエラーを許容するかなど、実行時の動作を変更できます。 必須のパラメーターは、すべてのインデクサーに指定され、REST API リファレンスに文書化されています。
BLOB、SQL、および Azure Cosmos DB 用のデータ ソース固有のインデクサーには、ソース固有の動作のために、追加の "configuration" パラメーターが用意されています。 たとえば、ソースが Blob Storage である場合、ファイル拡張子でフィルター処理を行うパラメーター、"parameters" : { "configuration" : { "indexedFileNameExtensions" : ".pdf,.docx" } } を設定できます。 ソースが Azure SQL の場合、クエリ タイムアウト パラメーターを設定できます。
フィールド マッピングは、データ ソースのフィールドと検索インデックスのフィールドの間に名前または型の不一致がある場合に、ソースと宛先のフィールドを明示的にマップするために使用されます。
既定では、検索サービスに対してインデクサーを作成するとすぐにインデクサーが実行されます。 インデクサーの実行を望まない場合は、インデクサーの作成時に "disabled" を true に設定します。
スケジュールを指定したり、インデクサー定義の補足的暗号化のために暗号化キーを設定したりすることもできます。
スキルベースのインデックス作成のためのインデクサーの例
インデクサーを使用すると、AI エンリッチメントも高速化されます。 上記のプロパティとパラメーターはすべて適用されますが、追加のプロパティ "skillSetName"、"cache"、"outputFieldMappings" は AI エンリッチメントに固有です。
{
"name": (required) String that uniquely identifies the indexer,
"dataSourceName": (required) String, provides raw content that will be enriched,
"targetIndexName": (required) String, name of an existing index,
"skillsetName" : (required for AI enrichment) String, name of an existing skillset,
"cache": {
"storageConnectionString" : (required if you enable the cache) Connection string to a blob container,
"enableReprocessing": true
},
"parameters": { },
"fieldMappings": (optional) Maps fields in the underlying data source to fields in an index,
"outputFieldMappings" : (required) Maps skill outputs to fields in an index,
}
AI エンリッチメントは独自の主題領域であり、この記事の範囲には含まれません。 詳細については、最初に「AI エンリッチメント」、「Azure AI Search のスキルセット」、「スキルセットを作成する」、「エンリッチメント出力フィールドをマップする」、「AI エンリッチメントのキャッシュを有効にする」を参照してください。
外部データを準備する
インデクサーで扱うのはデータ セットです。 インデクサーは、実行するとデータ ソースに接続し、コンテナーまたはフォルダーからデータを取得して、それを必要に応じて JSON にシリアル化してから、インデックス作成のために検索エンジンに渡します。 このセクションでは、テキスト ベースのインデックス作成のための、受信データの要件について説明します。
| ソース データ | タスク |
|---|---|
| JSON ドキュメント | 受信データの構造または形状が、検索インデックスのスキーマに対応していることを確認します。 ほとんどの検索インデックスはかなりフラットで、フィールド コレクションは同じレベルのフィールドから構成されます。 ただし、階層構造または入れ子構造体は、複雑なフィールドやコレクションを使用することで可能です。 |
| 関係 | フラット化された行セットとして提供されます。インデックス内では各行が全文検索ドキュメントまたは部分検索ドキュメントになります。 リレーショナル データを行セットにフラット化するには、SQL ビューを作成するか、親レコードと子レコードが同じ行で返されるクエリを作成する必要があります。 たとえば、組み込まれているホテル サンプルのデータセットは 50 レコード (ホテルごとに 1 つ) の SQL データベースであり、関連テーブル内の部屋レコードにリンクされています。 集合データを行セットにフラット化するクエリにより、すべての部屋情報が各ホテル レコードの JSON ドキュメントに埋め込まれます。 埋め込まれる部屋情報は、FOR JSON AUTO 句を使用するクエリによって生成されます。 この手法の詳細については、「埋め込みの JSON を返すクエリを定義する」を参照してください。 これは 1 つの例にすぎません。同じ結果を得られる他の方法を見つけることができます。 |
| ファイル | インデクサーでは通常、ファイルごとに 1 つの検索ドキュメントが作成されます。検索ドキュメントは、コンテンツとメタデータのフィールドから構成されます。 ファイルの種類によっては、インデクサーは 1 つのファイルを複数の検索ドキュメントに解析する場合があります。 たとえば、CSV ファイルでは、各行がスタンドアロンの検索ドキュメントになり得ます。 |
検索可能でフィルター可能な次のデータのみをプルする必要があります。
- 検索可能なデータは、テキストです。
- フィルター可能なデータは、英数字です。
Azure AI Search では、どのような形式でもバイナリ データを検索できませんが、画像ファイル内のテキスト記述を抽出して推測し (「AI エンリッチメント」を参照)、検索可能なコンテンツを作成することはできます。 同様に、サイズが大きいテキストを細分化し、自然言語モデルによって分析して構造や関連情報を見つけて、検索ドキュメントに追加できる新しいコンテンツを生成できます。
インデクサーによってデータの問題が解決されない場合は、他の形式のデータ クレンジングや操作が必要になることがあります。 詳細については、お使いの Azure データベース製品の製品ドキュメントを参照してください。
データ ソースを準備する
インデクサーには、型、コンテナー、および接続を指定するデータ ソースが必要です。
サポートされているデータ ソースの種類を使用していることを確認します。
データ ソースの定義を作成します。 次に、より頻繁に使用されるいくつかのデータ ソースのリストを示します。
データ ソースが Azure SQLや Cosmos DB などのデータベースの場合、変更の追跡を有効にします。 Azure Storage には、すべての BLOB、ファイル、テーブルの
LastModifiedプロパティによる変更追跡機能が組み込まれています。 さまざまなデータ ソースの上記のリンクには、インデクサーでサポートされている変更追跡の方法についての説明があります。
インデックスを準備する
インデクサーには検索インデックスも必要です。 インデクサーはインデックス作成のために検索エンジンにデータを渡すことを思い出してください。 実行動作を決定するプロパティがインデクサーにあるのと同様に、インデックス スキーマには、文字列にインデックスを付ける方法に大きく影響するプロパティがあります (文字列のみが分析およびトークン化されます)。
まず、検索インデックスを作成します。
フィールド コレクションとフィールド属性を設定します。
フィールドは、外部コンテンツの receptors のみです。 スキーマでどのような属性がフィールドに設定されているかによって、各フィールドの値はフィルター、あいまい検索、および先行入力クエリの逐語的文字列として分析、トークン化または保存されます。
インデクサーは、名前と型が等しい場合に、ソース フィールドをターゲット インデックス フィールドに自動的にマップできます。 フィールドを暗黙的にマップできない場合は、インデクサーにコンテンツをルーティングする方法を示す明示的なフィールド マッピングを定義できることに注意してください。
各フィールドのアナライザーの割り当てを確認します。 アナライザーは文字列を変換できます。 そのため、インデックス付けされる文字列が渡されたものと異なる場合があります。 テキストの分析 (REST) を使用して、アナライザーの影響を評価することができます。 アナライザーの詳細については、テキスト処理のためのアナライザーに関するページを参照してください。
インデックス作成中は、インデクサーはフィールド名と型のみをチェックします。 受信したコンテンツがインデックス内の対応する検索フィールドについて正しいことを確認する検証手順はありません。
インデクサーの作成
リモート検索サービスでインデクサーを作成する準備ができたら、検索クライアントが必要になります。 検索クライアントは、Azure portal、REST クライアント、あるいはインデクサー クライアントをインスタンス化するコードにすることができます。 早期の開発と概念実証のテストには、Azure portal または REST API をお勧めします。
Azure portal にサインインします。
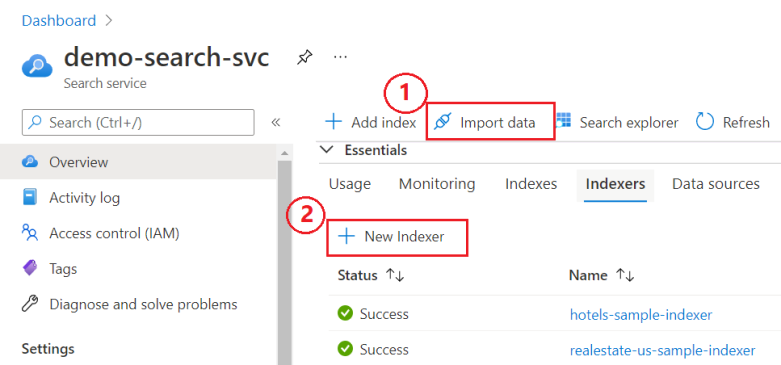
検索サービスの [概要] ページで、次の 2 つのオプションから選択します。
データのインポート ウィザード。 ウィザードは、必要な要素がすべて作成される点が他とは異なります。 他の方法を使用する場合は、データ ソースとインデックスを事前に定義しておく必要があります。
新規のインデクサー。インデクサー定義を指定するためのビジュアル エディターです。
次のスクリーンショットは、ポータルでこれらの機能が見つかる場所を示したものです。
インデクサーを実行する
既定では、検索サービスに対してインデクサーを作成するとすぐにインデクサーが実行されます。 インデクサー定義で "disabled" を true に設定すると、この動作をオーバーライドできます。 インデクサーの実行は、接続、フィールド マッピング、またはスキルセットの構築に問題があるかどうかを確認できる正念場です。
インデクサーを実行するには、いくつかの方法があります。
インデクサーの作成時または更新時に実行します (既定)。
定義に変更がない場合はオンデマンドで実行し、完全インデックス作成の場合はリセットから開始します。 詳細については、「インデクサーの実行またはリセット」を参照してください。
定期的に実行を呼び出すようにインデクサーの処理をスケジュールします。
通常、スケジュールされた実行を実装するのは、最新の変更を取得するために増分インデックスのニーズがある場合です。 そのため、スケジュールは変更の検出に依存します。
インデクサーは、他の Azure リソースへの公開の送信呼び出しを行う数少ないサブシステムの 1 つです。 Azure ロールに関しては、インデクサーには個別の ID がありません。検索エンジンから別の Azure リソースへの接続は、検索サービスのシステムまたはユーザー割り当てマネージド ID を使用して行われます。 インデクサーが仮想ネットワーク上の Azure リソースに接続する場合は、その接続用に共有プライベート リンクを作成する必要があります。 セキュリティで保護された接続の詳細については、Azure AI 検索のセキュリティに関するページを参照してください。
結果をチェックする
インデクサーの状態を監視して状態を調べます。 正常に実行されても、警告や通知が含まれている場合があります。 ジョブの詳細については、成功と失敗の両方の状態通知を確認するようにしてください。
コンテンツの検証のために、設定されたインデックスに対して、ドキュメント全体または選択したフィールドを返すクエリを実行できます。
変更検出と内部状態
データ ソースで変更検出がサポートされている場合、インデクサーでは、データの基になる変更を検出し、インデクサーの実行ごとに、新規または更新されたドキュメントのみを処理し、変更のないコンテンツはそのままにすることができます。 インデクサーの実行履歴に、ある実行において 0/0 個のドキュメントの処理が成功したと記録されている場合、インデクサーでは、基になるデータ ソースで新規または変更された行や BLOB が見つからなかったことになります。
データ プラットフォームには、変更検出ロジックが組み込まれています。 インデクサーが変更の検出をサポートする方法は、データ ソースによって異なります。
Azure Storage に変更検出が組み込まれているため、インデクサーによって新規および更新されたドキュメントを自動的に認識できます。 Blob Storage、Azure Table Storage、および Azure Data Lake Storage Gen2 は、各 BLOB または行の更新を日付と時刻でスタンプします。 インデクサーはこの情報を自動的に使用して、インデックス内で更新するドキュメントを決定します。 削除検出の詳細については、Azure AI Search の Azure Storage のインデクサーを使用した削除検出に関する記事を参照してください。
クラウド データベース テクノロジでは、プラットフォームに省略可能な変更検出機能が備わっています。 これらのデータ ソースでは、変更検出は自動ではありません。 次で使用されるポリシーを、データ ソース定義で指定する必要があります。
インデクサーは、内部の高基準値を使用して、データ ソースから最後に処理したドキュメントを追跡します。 このマーカーは API では公開されませんが、内部的には、インデクサーは停止した場所を追跡します。 スケジュールされた実行またはオンデマンド呼び出しによってインデックス作成が再開されると、インデクサーは、中断された場所を取得できるように高基準値を参照します。
高基準値をクリアしてインデックスをすべて再作成する必要がある場合は、インデクサーのリセットを行います。 より選択的にインデックスを再作成する場合は、スキルのリセットまたはドキュメントのリセットを行います。 リセット API を使用して内部状態をクリアできます。また、インクリメンタル エンリッチメントを有効にした場合は、キャッシュもフラッシュできます。 各リセット オプションの背景情報と比較の詳細については、インデクサー、スキル、ドキュメントの実行またはリセットに関するページを参照してください。