Azure AI Search のサービス レベルを選択する
検索サービスの作成の部分では、サービスの有効期間にわたって固定される価格レベル (SKU) を選択します。 レベルは、サービスの作成時に、ポータルの [価格レベルの選択] ページで指定します。 PowerShell または Azure CLI でプロビジョニングを行う場合は、-Sku パラメーターを使用してレベルを指定します。
選択したレベルによって以下が決まります。
- サービスで許可されるインデックスおよびその他のオブジェクトの最大数
- パーティション (物理ストレージ) のサイズと速度
- 月単位の固定コストとしての課金対象のレート (ただし、容量を追加した場合は増分のコスト)
いくつかのインスタンスでは、選択したレベルによってプレミアム機能の使用の可否が決まります。
価格 (サービスの実行にかかる推定月間コスト) は、ポータルの [Select Pricing Tier]\(価格レベルの選択\) ページに表示されます。 推定コストについては、サービスの価格に関するページを参照してください。
Note
2024 年 4 月 3 日より後に作成された検索サービスでは、ほとんどすべてのレベルでパーティションが大きくなり、ベクトル クォータが高くなっています。 詳細については、「サービスの制限」を参照してください。
サービス レベルの説明
レベルには、Free、Basic、Standard、Storage Optimized があります。 Standard と Storage Optimized は、いくつかの構成および容量で利用できます。 次の Azure portal のスクリーンショットは、使用可能なレベルを示しています。価格は除外されていますが、ポータルと価格に関するページで確認できます。
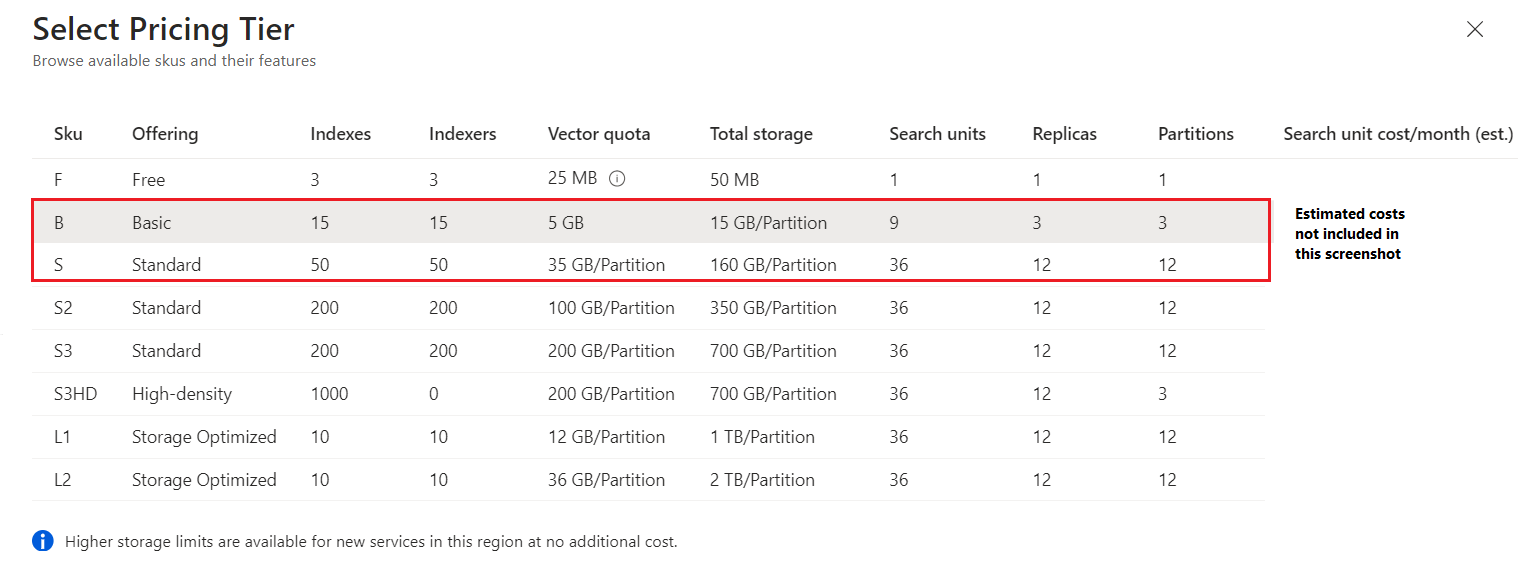
Free では、チュートリアルやサンプルの実行など、小規模なプロジェクト用の限定された検索サービスが作成されます。 内部的には、複数のサブスクライバー間でシステム リソースが共有されます。 無料のサービスをスケーリングしたり、重要なワークロードを実行したりすることはできません。 Azure サブスクリプションごとに 1 つの無料検索サービスのみを使用できます。
最も一般的に使用される課金対象レベルは次のとおりです。
Basic には、3 つのレプリカをサポートして SLA を満たす機能があります。
Standard (S1、S2、S3) が既定値です。 ワークロードに応じてより柔軟にスケーリングできます。 パーティションとレプリカの両方をスケーリングできます。 自分の制御下の専用リソースを使用して、より大規模なプロジェクトのデプロイ、パフォーマンスの最適化、および容量の増加を行うことができます。
一部のレベルは、特定の種類の作業向けに設計されています。
Standard 3 High Density (S3 HD) は、S3 用の "ホスティング モード" で、基になるハードウェアが多数の小さいインデックス用に最適化されており、マルチテナント シナリオ向けです。 S3 HD のユニットあたりの料金は S3 と同じですが、ハードウェアは数多くの小さいインデックスでの高速ファイル読み取り用に最適化されています。
Storage Optimized (L1, L2) レベルでは、Standard レベルより安い TB あたりの価格で、大容量のストレージが提供されます。 これらのレベルは、あまり頻繁に変更されない大規模なインデックス用に設計されています。 主なトレードオフとしてクエリの待ち時間が長くなるので、特定のアプリケーションの要件に対して妥当かどうかを確認する必要があります。
さまざまなレベルの詳細については、 価格ページの、Azure AI Searchの サービスの制限に関するアーティクル、およびサービスをプロビジョニングする際のポータル ページのさまざまなレベルの詳細を参照してください。
階層による機能の使用の可否
ほとんどの機能は Free レベルを含むすべてのレベルで使用できます。 レベルによって機能の使用の可否が決まる場合があります。 次の表で、各制約について説明します。
| 機能 | 制限事項 |
|---|---|
| インデクサー | インデクサーは S3 HD では使用できません。 インデクサーには、Free レベルに対するより多くの制限があります。 |
| AI エンリッチメント | Free レベルで実行されますが、推奨されていません。 |
| 送信 (インデクサー) アクセス用のマネージド (信頼できる) ID | Free レベルでは使用できません。 |
| カスタマー マネージド暗号化キー | Free レベルでは使用できません。 |
| IP ファイアウォール アクセス | Free レベルでは使用できません。 |
| プライベート エンドポイント (Azure Private Link との統合) | 検索サービスへの受信接続の場合、Free レベルでは利用できません。 インデクサーによる他の Azure リソースへの送信接続の場合は、Free または S3 HD では使用できません。 スキルセットを使用するインデクサーの場合、Free、Basic、S1、S3 HD では使用できません。 |
| 可用性ゾーン | Free および Basic レベルでは使用できません。 |
| セマンティック ランカー | Free レベルでは使用できません。 |
リソース集中型の機能は、十分な容量を与えない限り、うまくいかない場合があります。 たとえば、AI エンリッチメントには、データセットのサイズが小さい場合を除いて Free サービスではタイムアウトになってしまう、実行時間の長いスキルがあります。
上限
レベルによって、サービス自体の最大ストレージとともに、作成できるインデックス、インデクサー、データ ソース、スキルセット、シノニム マップの最大数が決まります。 すべての制限を完全に解除する方法については、Azure AI Searchのサービス の制限に関するページを参照してください。
パーティションのサイズと速度
各レベルの価格には、パーティションごとのストレージの詳細 (Basic レベルの 15 GB からストレージ最適化 (L2) レベルの 2 TB まで) が含まれます。 その他のハードウェア特性 (動作速度、待機時間、転送速度など) は公開されませんが、特定のソリューション アーキテクチャ向けに設計されたレベルは、そのシナリオをサポートする機能を備えたハードウェア上に構築されます。 パーティションの詳細については、「見積もりと管理容量とAzure AI Search での信頼性 」を参照してください。
課金レート
課金レートはレベルによって異なり、高価なハードウェア上で実行されるレベルや、より高価な機能を提供するレベルの料金は高くなります。 レベルの課金レートは、Azure AI Search の Azure の価格ページで確認できます。
サービスの作成後、課金レートはサービスの 24 時間実行に関する "固定コスト" と、容量を追加した場合の "増分コスト" の両方になります。
検索サービスには、"パーティション" (ストレージ用) と "レプリカ" (クエリ エンジンのインスタンス) の形でコンピューティング リソースが割り当てられます。 最初にそれぞれ 1 つを使用してサービスが作成され、請求レートには両方のリソースが含まれています。 ただし、容量をスケーリングした場合は、課金対象のレートの単位でコストが増減します。
具体的な例を次に示します。 請求レートが月あたり 100 ドルだとします。 検索サービスを初期容量である 1 つのパーティションと 1 つのレプリカで保持している場合、月末に支払うことが想定される金額は 100 ドルです。 しかし、高可用性を実現するために 2 つのレプリカを追加した場合、毎月の請求額は 300 ドル (最初のレプリカとパーティションのペアに対する 100 ドルに加えて、2 つのレプリカに対する 200 ドル) に増えます。
この課金モデルは、検索サービスで使用される "検索ユニット" (SU) の数に請求レートを適用するという考え方に基づいています。 すべてのサービスが最初に 1 つの SU でプロビジョニングされますが、大規模なワークロードを処理するために、パーティションまたはレプリカを追加して SU を増やすことができます。 詳細については、検索サービスのコストを見積もる方法に関するページをご覧ください。
レベルのアップグレードまたはダウングレード
レベルのアップグレードまたはダウングレードの組み込みサポートはありません。 別のレベルに切り替えたい場合、方法は次のとおりです。
新しいレベルで新しい検索サービスを作成します。
新しいサービスに検索コンテンツをデプロイします。 このチェックリストに従って、すべてのコンテンツがあることを確認します。
もう必要ないことが確信できたら、古い検索サービスを削除します。
最初から再構築したくない大規模なインデックスの場合、バックアップと復元のサンプルを使用して移動することを検討してください。
次のステップ
価格レベルを選択する最善の方法は、最低コストのレベルから開始し、その後、使用経験とテストから得られた情報に基づいて、そのサービスを維持するか、上位のレベルで新規に作成するかを決定することです。 次のステップとして、提案するテストのレベルに対応できるレベルで検索サービスを作成し、その後、次のガイダンスでコストと容量の見積もりに関する推奨事項を確認することをお勧めします。