レプリカとインスタンス
この記事では、ステートフル サービスのレプリカとステートレス サービスのインスタンスのライフサイクルの概要を示します。
ステートレス サービスのインスタンス
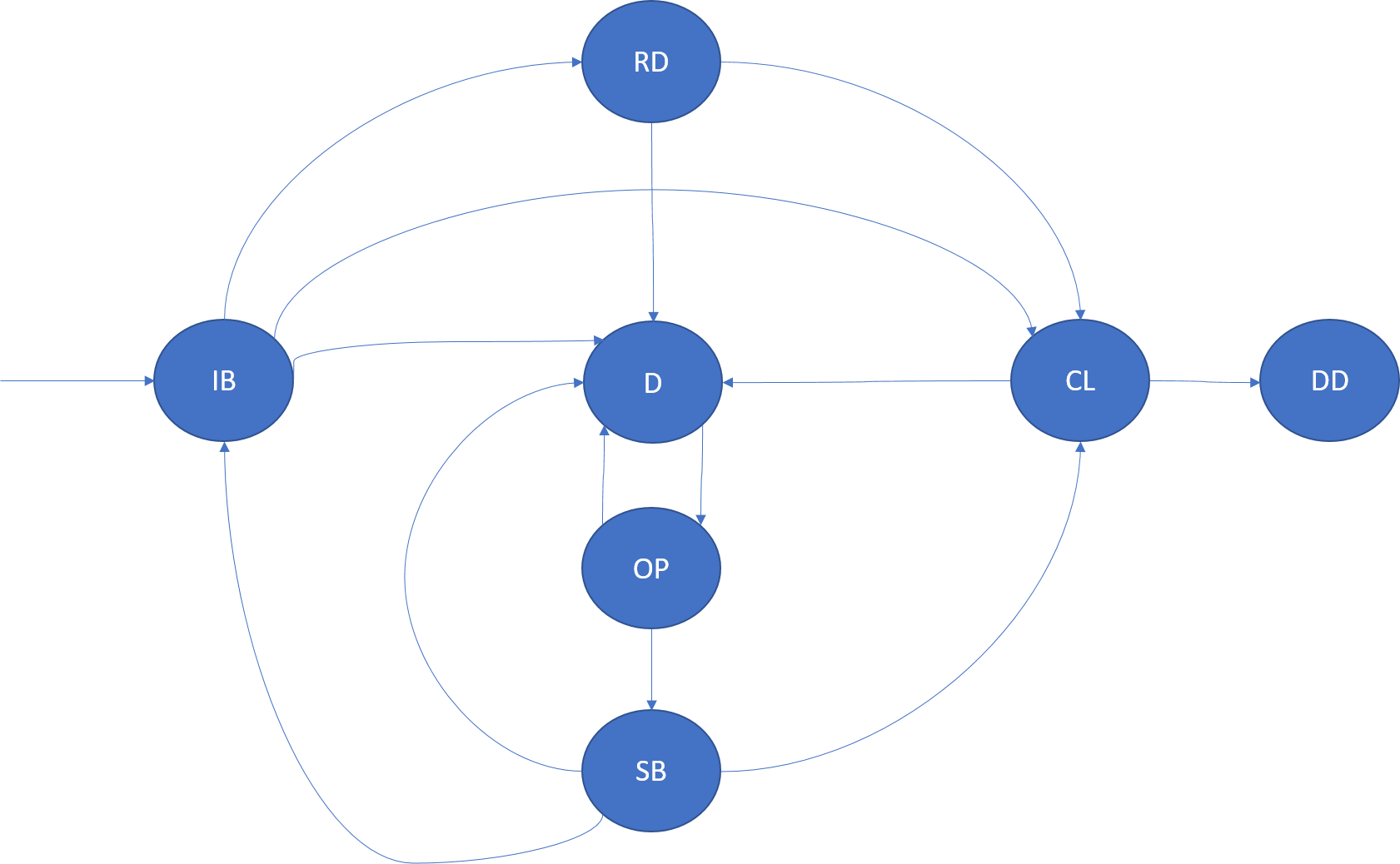
ステートレス サービスのインスタンスとは、クラスターのいずれかのノードで実行されるサービスのロジックのコピーのことです。 パーティション内のインスタンスは、その InstanceId によって一意に識別されます。 インスタンスのライフサイクルは、次の図のようにモデル化されます。
InBuild (IB)
クラスター リソース マネージャーでインスタンスの配置が認識されると、このライフサイクルの状態に入ります。 インスタンスがノードで起動します。 アプリケーション ホストが起動し、インスタンスが作成されて開かれます。 起動が完了すると、インスタンスは準備完了状態に遷移します。
アプリケーション ホストまたはこのインスタンスのノードがクラッシュした場合は、ドロップ状態に遷移します。
Ready (RD)
準備完了 (Ready) 状態では、インスタンスはノード上で稼働中です。 このインスタンスが信頼性の高いサービスであれば、RunAsync が呼び出されています。
アプリケーション ホストまたはこのインスタンスのノードがクラッシュした場合は、ドロップ状態に遷移します。
Closing (CL)
クローズ中 (Closing) 状態では、Azure Service Fabric はこのノード上のインスタンスをシャットダウン処理中です。 このシャットダウンは、アプリケーションのアップグレード、負荷分散、またはサービスの削除など、多くの理由により発生します。 シャットダウンが完了すると、ドロップ状態に遷移します。
Dropped (DD)
ドロップ (Dropped) 状態では、既にインスタンスはノード上で実行されていません。 この時点では、Service Fabric はこのインスタンスに関するメタデータを保持していますが、最終的にはそれも削除されます。
Note
Remove-ServiceFabricReplica で ForceRemove オプションを使用して、いずれかの状態からドロップ状態に遷移することが可能です。
ステートフル サービスのレプリカ
ステートフル サービスのレプリカとは、クラスターのノードのいずれかで実行されているサービスのロジックのコピーのことです。 さらに、レプリカは、そのサービスの状態のコピーを保持します。 ステートフル レプリカのライフサイクルと動作は、2 つの関連する概念で説明できます。
- レプリカのライフサイクル
- レプリカのロール
次の解説では、永続化ステートフル サービスについて説明します。 揮発性 (メモリ内) のステートフル サービスでは、ダウン状態とドロップ状態は同等です。
InBuild (IB)
InBuild レプリカは、レプリカ セットに加えるために作成または準備されるレプリカです。 レプリカのロールによっては、IB は異なるセマンティクスを持ちます。
アプリケーション ホストまたは InBuild レプリカのノードがクラッシュした場合には、ダウン状態に遷移します。
Primary InBuild レプリカ: Primary InBuild は、パーティションの最初のレプリカです。 このレプリカは通常、パーティションの作成中に発生します。 Primary InBuild レプリカは、パーティションのすべてのレプリカが再起動またはドロップされるときにも発生します。
IdleSecondary InBuild レプリカ: これらは、クラスター リソース マネージャーによって作成される新しいレプリカか、またはダウンし、セットに戻す必要のある既存のレプリカです。 それらのレプリカが ActiveSecondary としてレプリカ セットに加わり、操作のクォーラム確認に参加するためには、まずプライマリによってそれらをシード生成またはビルドする必要があります。
ActiveSecondary InBuild レプリカ: この状態は一部のクエリで見られます。 これは、レプリカ セットに変化がないものの、レプリカをビルドする必要のある最適化です。 レプリカ自体は、通常状態のマシンの遷移に従います (レプリカのロールのセクションで説明されているとおり)。
Ready (RD)
準備完了 (Ready) のレプリカは、レプリケーションに参加し、操作のクォーラム確認に参加しているレプリカです。 準備完了状態は、プライマリ レプリカと、アクティブなセカンダリ レプリカに当てはまります。
アプリケーション ホストまたは準備完了レプリカのノードがクラッシュした場合には、ダウン状態に遷移します。
Closing (CL)
レプリカは、次のシナリオでクローズ中 (Closing) 状態に入ります。
レプリカのコードをシャットダウンする: Service Fabric で、レプリカの実行中のコードをシャットダウンすることが必要な場合があります。 このシャットダウンにはさまざまな理由が考えられます。 たとえば、アプリケーション、ファブリック、インフラストラクチャのアップグレードや、レプリカによって報告された障害などによって発生する可能性があります。 レプリカのクローズが完了すると、ダウン状態に遷移します。 ディスクに格納されているこのレプリカに関連付けられた永続的な状態は、クリーンアップされません。
クラスターからレプリカを削除する: Service Fabric で、永続的な状態を解除して、レプリカの実行中のコードをシャットダウンすることが必要な場合があります。 このシャットダウンには、負荷分散など、さまざまな理由が考えられます。
Dropped (DD)
ドロップ (Dropped) 状態では、既にインスタンスはノード上で実行されていません。 ノード上に残される状態もありません。 この時点では、Service Fabric はこのインスタンスに関するメタデータを保持していますが、最終的にはそれも削除されます。
Down (D)
ダウン (Down) 状態では、レプリカ コードは実行されていませんが、そのレプリカの永続的な状態がそのノードに存在します。 レプリカがダウンする理由はさまざまです。たとえば、ノードのダウン、レプリカ コードでのクラッシュ、アプリケーションのアップグレード、レプリカの障害などです。
ダウン レプリカは、必要に応じて、Service Fabric によって開かれます。たとえば、ノードでのアップグレードが完了したときなどです。
ダウン状態では、レプリカのロールは関係ありません。
Opening (OP)
Service Fabric がレプリカをバックアップに戻す必要がある場合に、ダウン レプリカはオープン中 (Opening) 状態に入ります。 この状態は、たとえば、ノード上でアプリケーションのコードのアップグレードが完了した後などに発生します。
アプリケーション ホストまたはオープン中のレプリカのノードがクラッシュした場合には、ダウン状態に遷移します。
オープン中 (Opening) 状態では、レプリカのロールは関係ありません。
StandBy (SB)
スタンバイ (StandBy) レプリカは、ダウン後に再び開かれた、永続的なサービスのレプリカです。 このレプリカは、レプリカ セットに別のレプリカを追加する必要がある場合に、Service Fabric によって使用されることがあります (状態の一部が既にあって、ビルド処理が高速であるため)。 StandByReplicaKeepDuration の期限が切れると、スタンバイ レプリカは破棄されます。
アプリケーション ホストまたはスタンバイ レプリカのノードがクラッシュした場合には、ダウン状態に遷移します。
スタンバイ状態では、レプリカのロールは関係ありません。
Note
ダウン状態でもドロップ状態でもないレプリカは、稼働中と見なされます。
Note
Remove-ServiceFabricReplica で ForceRemove オプションを使用して、いずれかの状態からドロップ状態に遷移することが可能です。
レプリカのロール
レプリカのロールは、レプリカ セット内での機能を決定します。
- Primary (P): レプリカ セットには、読み取りおよび書き込み操作の実行を担当する 1 つのプライマリがあります。
- ActiveSecondary (S): これらは、状態の更新をプライマリから受け取り、それらを適用し、確認を戻すレプリカです。 レプリカ セットには複数のアクティブなセカンダリがあります。 それらのアクティブなセカンダリの数によって、サービスで処理できるエラーの数が決まります。
- IdleSecondary (I): これらのレプリカはプライマリによってビルドされているもので、 アクティブなセカンダリに昇格する前に、プライマリから状態を受信します。
- None (N): これらのレプリカは、レプリカ セットで何も担当しません。
- Unknown (U): Service Fabric から何らかの ChangeRole API 呼び出しを受け取る前の、レプリカの初期ロールです。
次の図は、レプリカのロールの遷移と、それらが発生するいくつかのシナリオの例を示しています。
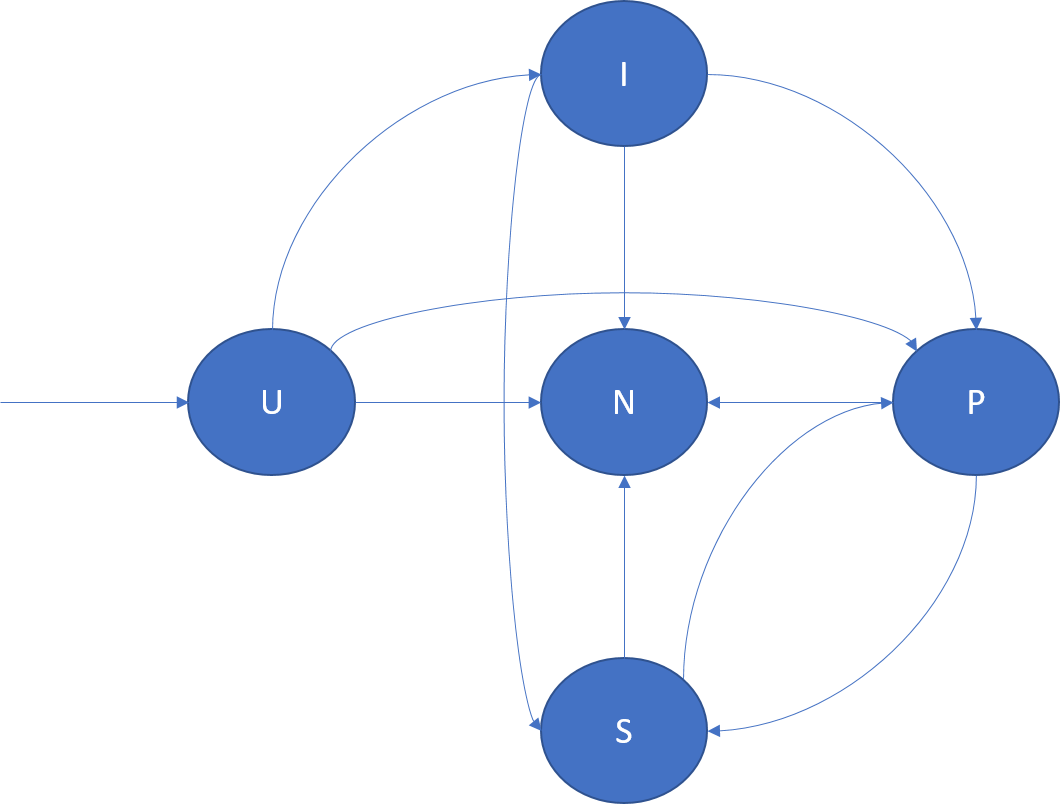
- U -> P: 新しいプライマリ レプリカの作成。
- U -> I: 新しいアイドル レプリカの作成。
- U -> N: スタンバイ レプリカの削除。
- I -> S: アイドル状態のセカンダリをアクティブなセカンダリに昇格して、その確認がクォーラムに貢献するようにします。
- I -> P: アイドル状態のセカンダリからプライマリへの昇格。 アイドル セカンダリがプライマリの適切な候補になる、特別な再構成のもとで発生する可能性があります。
- I -> N: アイドル状態のセカンダリ レプリカの削除。
- S -> P: アクティブなセカンダリからプライマリへの昇格。 これは、クラスター リソース マネージャーによって開始されたプライマリのフェールオーバーまたはプライマリの動きが理由で発生します。 たとえば、アプリケーションのアップグレードまたは負荷分散への応答で発生します。
- S -> N: アクティブなセカンダリ レプリカの削除。
- P -> S: プライマリ レプリカの降格。 これは、クラスター リソース マネージャーによって開始されたプライマリの動きが理由で発生します。 たとえば、アプリケーションのアップグレードまたは負荷分散への応答で発生します。
- P -> N: プライマリ レプリカの削除。
Note
Reliable Actors や Reliable Services など、抽象度の高いプログラミング モデルの場合、レプリカ ロールの概念は開発者には隠されています。 Actors では、ロールの概念は不要です。 Services では、ほとんどのシナリオで大幅に簡略化されます。
次のステップ
Service Fabric の概念について詳しくは、次の記事をご覧ください。