Synapse SQL プールでレプリケート テーブルを使用するための設計ガイダンス
この記事では、Synapse SQL プール スキーマでレプリケート テーブルを設計するための推奨事項を紹介します。 これらの推奨事項を使用すると、データの移動が少なくなり、クエリの複雑さが軽減されることでクエリ パフォーマンスが向上します。
前提条件
この記事では、SQL プールのデータ分散とデータ移動の概念を理解していることを前提としています。 詳細については、アーキテクチャに関する記事を参照してください。
テーブル設計の一環として、ご利用のデータと、そのデータを照会する方法についてできる限り理解してください。 たとえば、次のような質問を考えてみます。
- テーブルの大きさはどの程度か。
- どの程度の頻度でテーブルが更新されるか。
- SQL プール内にファクトおよびディメンションのテーブルがあるか。
レプリケート テーブルとは
レプリケート テーブルには、各コンピューティング ノード上でアクセスできるテーブルの完全なコピーがあります。 テーブルをレプリケートすると、結合または集計の前に、コンピューティング ノード内のデータを転送する必要がなくなります。 テーブルには複数のコピーが含まれているため、テーブルのサイズが 2 GB 未満に圧縮されている場合にレプリケート テーブルが最も効果的に機能します。 2 GB はハード制限ではありません。 データが静的で変化しない場合は、さらに大きなテーブルをレプリケートできます。
次の図は、各コンピューティング ノード上でアクセスできるレプリケート テーブルを示したものです。 SQL プールでは、レプリケート テーブルは各コンピューティング ノード上のディストリビューション データベースに完全にコピーされます。

レプリケート テーブルは、スター スキーマのディメンションのテーブルに適しています。 通常、ディメンション テーブルが結合されるファクト テーブルは、ディメンション テーブルとは異なる方法で分散されます。 ディメンションは、通常、複数のコピーの格納および保持を可能にするサイズです。 ディメンションは、顧客名、住所、製品の詳細など、変更頻度の低い説明的なデータを格納します。 変更頻度が低いというデータの性質により、レプリケート テーブルのメンテナンス回数は少なくなります。
次の場合は、レプリケート テーブルの使用を検討してください。
- ディスク上のテーブル サイズが、行数には関係なく、2 GB 未満である。 テーブルのサイズを調べるには、次のように DBCC PDW_SHOWSPACEUSED コマンドを使用することができます。
DBCC PDW_SHOWSPACEUSED('ReplTableCandidate') - データ移動を必要とする結合でテーブルが使用されている。 ハッシュ分散テーブルなど同じ列で分散されていないテーブルを結合して、1 つのラウンドロビン テーブルにする場合、クエリを完了するにはデータの移動が必要です。 テーブルの 1 つが小さい場合は、レプリケート テーブルを検討してください。 ほとんどの場合、ラウンド ロビン テーブルの代わりにレプリケート テーブルを使用することをお勧めします。 クエリ プランでのデータ移動操作を表示するには、sys.dm_pdw_request_steps を使用してください。 BroadcastMoveOperation は、レプリケート テーブルを使用することで不要にできる代表的なデータ移動操作です。
次の場合、レプリケート テーブルでは最適なクエリ パフォーマンスが得られない可能性があります。
- テーブルで、頻繁な挿入、更新、削除操作が行われる。 これらのデータ操作言語 (DML) 操作では、レプリケート テーブルを再構築する必要があります。 頻繁に再構築すると、パフォーマンスが低下する場合があります。
- SQL プールは頻繁にスケーリングされます。 SQL プールをスケーリングすると、コンピューティング ノードの数が変わるため、レプリケート テーブルの再構築が発生します。
- テーブルに多数の列があっても、通常、データ操作でアクセスする列はごく少数である。 このシナリオでは、テーブル全体をレプリケートするのではなく、テーブルを分散し、頻繁にアクセスする列にインデックスを作成する方が効果的であると考えられます。 クエリでデータ移動が必要な場合、SQL プールでは、要求された列のデータのみが移動されます。
ヒント
インデックス作成とレプリケートされたテーブルの詳細については、Azure Synapse Analytics の専用 SQL プール (旧称 SQL DW) のチート シートに関するページを参照してください。
単純なクエリ述語でレプリケート テーブルを使用する
テーブルを分散するかレプリケートするかを選択する前に、そのテーブルに対して実行を計画するクエリの種類について考えてみます。 できる限り、次のようにしてください。
- 等値や非等値など、単純なクエリ述語を使用したクエリには、レプリケート テーブルを使用します。
- LIKE や NOT LIKE など、複雑なクエリ述語を使用したクエリには、分散テーブルを使用します。
CPU を集中的に使用するクエリでは、作業がすべてのコンピューティング ノードに分散されたときに、最高のパフォーマンスが得られます。 たとえば、テーブルの各行の計算を実行するクエリのパフォーマンスは、レプリケート テーブルよりも分散テーブルの方が高くなります。 レプリケート テーブル全体が各コンピューティング ノードに格納されるため、CPU を集中的に使用する、レプリケート テーブルに対するクエリは、各コンピューティング ノード上のテーブル全体に対して実行されます。 余分な計算により、クエリのパフォーマンスが低下する場合があります。
たとえば、次のクエリには、複雑な述語が使用されています。 データがレプリケート テーブルではなく分散テーブルにある場合、処理速度が速くなります。 この例では、データをラウンド ロビン方式で分散できます。
SELECT EnglishProductName
FROM DimProduct
WHERE EnglishDescription LIKE '%frame%comfortable%';
既存のラウンド ロビン テーブルをレプリケート テーブルに変換する
既にラウンド ロビン テーブルがある場合、この記事に記載されている条件を満たしているのであれば、レプリケート テーブルに変換することをお勧めします。 レプリケート テーブルは、データ移動の必要がなくなるため、ラウンド ロビン テーブルよりもパフォーマンスが高くなります。 ラウンド ロビン テーブルでは、常に、結合のためにデータ移動が必要になります。
この例では CTAS を使用して、DimSalesTerritory テーブルをレプリケート テーブルに変更します。 この例は、DimSalesTerritory がハッシュ分散かラウンド ロビンかに関係なく動作します。
CREATE TABLE [dbo].[DimSalesTerritory_REPLICATE]
WITH
(
HEAP,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory]
OPTION (LABEL = 'CTAS : DimSalesTerritory_REPLICATE')
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[DimSalesTerritory_REPLICATE] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
ラウンド ロビンとレプリケートのクエリ パフォーマンスの例
レプリケート テーブルでは、結合のためのデータ移動は必要ありません。これは、テーブル全体が既に各コンピューティング ノード上に存在するためです。 ディメンション テーブルがラウンド ロビン分散の場合、結合によって、ディメンション テーブル全体が各コンピューティング ノードにコピーされます。 データを移動するために、クエリ プランには BroadcastMoveOperation と呼ばれる操作が含まれています。 この種類のデータ移動操作では、クエリのパフォーマンスが低下します。レプリケート テーブルを使用すると、この操作は使用されなくなります。 クエリ プランのステップを表示するには、sys.dm_pdw_request_steps システム カタログ ビューを使用します。
たとえば、AdventureWorks スキーマに対する次のクエリでは、FactInternetSales テーブルがハッシュ分散です。 DimDate テーブルと DimSalesTerritory テーブルは、小さいディメンション テーブルです。 このクエリでは、会計年度 2004 年の北米における売上合計が返されます。
SELECT [TotalSalesAmount] = SUM(SalesAmount)
FROM dbo.FactInternetSales s
INNER JOIN dbo.DimDate d
ON d.DateKey = s.OrderDateKey
INNER JOIN dbo.DimSalesTerritory t
ON t.SalesTerritoryKey = s.SalesTerritoryKey
WHERE d.FiscalYear = 2004
AND t.SalesTerritoryGroup = 'North America'
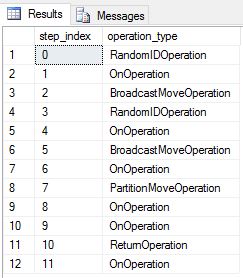
DimDate と DimSalesTerritory をラウンドロビン テーブルとして作成し直しました。 結果として、このクエリでは次のクエリ プランが示されました。これには、複数のブロードキャスト移動操作が含まれています。
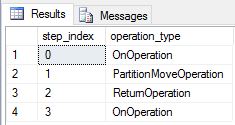
DimDate と DimSalesTerritory をレプリケート テーブルとして作成し直し、もう一度このクエリを実行しました。 その結果のクエリ プランは非常に短くなり、ブロードキャスト移動は含まれていません。
レプリケート テーブルを変更する場合のパフォーマンスに関する考慮事項
SQL プールでは、テーブルのマスター バージョンを保持することによってレプリケート テーブルが実装されます。 そのマスター バージョンは、各コンピューティング ノード上の最初のディストリビューション データベースにコピーされます。 変更がある場合、最初にマスター バージョンが更新され、次に各コンピューティング ノードのテーブルが再構築されます。 レプリケート テーブルの再構築では、すべての Compute ノードにテーブルがコピーされ、インデックスが再構築されます。 たとえば、DW2000c 上のレプリケート テーブルには、データのコピーが 5 つあります。 各 Compute ノードにマスター コピー 1 部と完全コピー 1 部 すべてのデータは分散データベースに格納されます。 SQL プールでは、このモデルを使用して、データ変更ステートメントの高速処理と柔軟なスケーリング操作がサポートされます。
非同期の再構築は、次の後のレプリケート テーブルに対する最初のクエリによってトリガーされます。
- データが読み込まれるまたは変更される
- Synapse SQL インスタンスが別のレベルにスケーリングされる
- テーブル定義が更新される
次の操作の後は、再構築は不要です。
- 一時停止操作
- 再開操作
再構築は、データが変更された直後には行われるわけではありません。 再構築は、初めてクエリがテーブルから選択するときにトリガーされます。 各 Compute ノードにデータが非同期にコピーされる間、再構築をトリガーしたクエリはマスター バージョンのテーブルからただちにデータを読み取ります。 データのコピーが完了するまで、以降のクエリはマスター バージョンのテーブルを使い続けます。 別の再構築を強制するレプリケート テーブルに対するアクティビティが発生すると、データ コピーは無効になり、次の select ステートメントによって再びデータ コピーがトリガーされます。
インデックスは控えめに使用する
標準的なインデックス作成方法は、レプリケート テーブルにも当てはまります。 SQL プールでは、再構築の一環として、各レプリケート テーブル インデックスが再構築されます。 インデックスを使用するのは、インデックスの再構築にかかるコストよりもパフォーマンスの向上が重要な場合のみにしてください。
データの読み込みをバッチ処理する
レプリケート テーブルにデータを読み込む場合、複数の読み込みをバッチ処理することで、再構築を最小限に抑えるようにします。 select ステートメントを実行する前に、バッチ処理された読み込みすべてを実行します。
たとえば、次の読み込みパターンでは、4 つのソースからデータを読み込み、4 つの再構築を呼び出します。
- ソース 1 から読み込む。
- Select ステートメントで再構築 1 をトリガーする。
- ソース 2 から読み込む。
- Select ステートメントで再構築 2 をトリガーする。
- ソース 3 から読み込む。
- Select ステートメントで再構築 3 をトリガーする。
- ソース 4 から読み込む。
- Select ステートメントで再構築 4 をトリガーする。
たとえば、次の読み込みパターンでは、4 つのソースからデータを読み込みますが、呼び出す再構築は 1 つだけです。
- ソース 1 から読み込む。
- ソース 2 から読み込む。
- ソース 3 から読み込む。
- ソース 4 から読み込む。
- Select ステートメントで再構築をトリガーする。
バッチ読み込み後にレプリケート テーブルを再構築する
クエリの実行時間に一貫性を持たせるため、バッチ読み込み後に強制的にレプリケート テーブルを構築することを検討してください。 構築しない場合、最初のクエリは引き続きデータ移動を使用してクエリを完了します。
'レプリケートされた テーブル キャッシュのビルド' 操作では、最大 2 つの操作を同時に実行できます。 たとえば、5 つのテーブルのキャッシュを再構築しようとすると、システムは staticrc20 (変更不可) を利用して、その時点で 2 つのテーブルを同時に構築します。 そのため、ノード間のキャッシュの再構築が遅くなり、全体的な時間が長くなる可能性があるため、2 GB を超える大きなレプリケートテーブルの使用は避けることをおすすめします。
次のクエリでは、sys.pdw_replicated_table_cache_state DMV を使用して、変更されたものの再構築されていないレプリケート テーブルの一覧を表示します。
SELECT SchemaName = SCHEMA_NAME(t.schema_id)
, [ReplicatedTable] = t.[name]
, [RebuildStatement] = 'SELECT TOP 1 * FROM ' + '[' + SCHEMA_NAME(t.schema_id) + '].[' + t.[name] +']'
FROM sys.tables t
JOIN sys.pdw_replicated_table_cache_state c
ON c.object_id = t.object_id
JOIN sys.pdw_table_distribution_properties p
ON p.object_id = t.object_id
WHERE c.[state] = 'NotReady'
AND p.[distribution_policy_desc] = 'REPLICATE'
再構築をトリガーするには、前の出力に含まれる各テーブルに対して次のステートメントを実行します。
SELECT TOP 1 * FROM [ReplicatedTable]
Note
キャッシュされていないレプリケート テーブルの統計を再構築する予定がある場合は、キャッシュをトリガーする前に統計を更新してください。 統計を更新するとキャッシュが無効になるため、シーケンスが重要です。
例: UPDATE STATISTICS から始めて、キャッシュのリビルドをトリガーします。 次の例では、正しいサンプルによって統計が更新され、キャッシュの再構築がトリガーされます。
-- Incorrect sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
SELECT TOP 1 * FROM [ReplicatedTable]
UPDATE STATISTICS [ReplicatedTable]
END
-- Correct sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
UPDATE STATISTICS [ReplicatedTable]
SELECT TOP 1 * FROM [ReplicatedTable]
END
再構築プロセスを監視するには、sys.dm_pdw_exec_requests を使います。ここで、command は "BuildReplicatedTableCache" で始まります。 次に例を示します。
-- Monitor Build Replicated Cache
SELECT *
FROM sys.dm_pdw_exec_requests
WHERE command like 'BuildReplicatedTableCache%'
ヒント
テーブル サイズ クエリを使うと、どのテーブルにレプリケートされた分散ポリシーがあり、どのテーブルが 2 GB より大きいかを確認できます。
次のステップ
レプリケート テーブルを作成するには、次のいずれかのステートメントを使用します。
分散テーブルの概要については、分散テーブルに関するページを参照してください。