テーブルの設計パターン
この記事では、Table service ソリューションで使用するのに適したパターンをいくつか紹介します。 また、他のテーブル ストレージ設計の記事で説明されている問題やトレードオフの一部に実際に対処する方法についても説明します。 次の図は、さまざまなパターンの関係をまとめたものです。
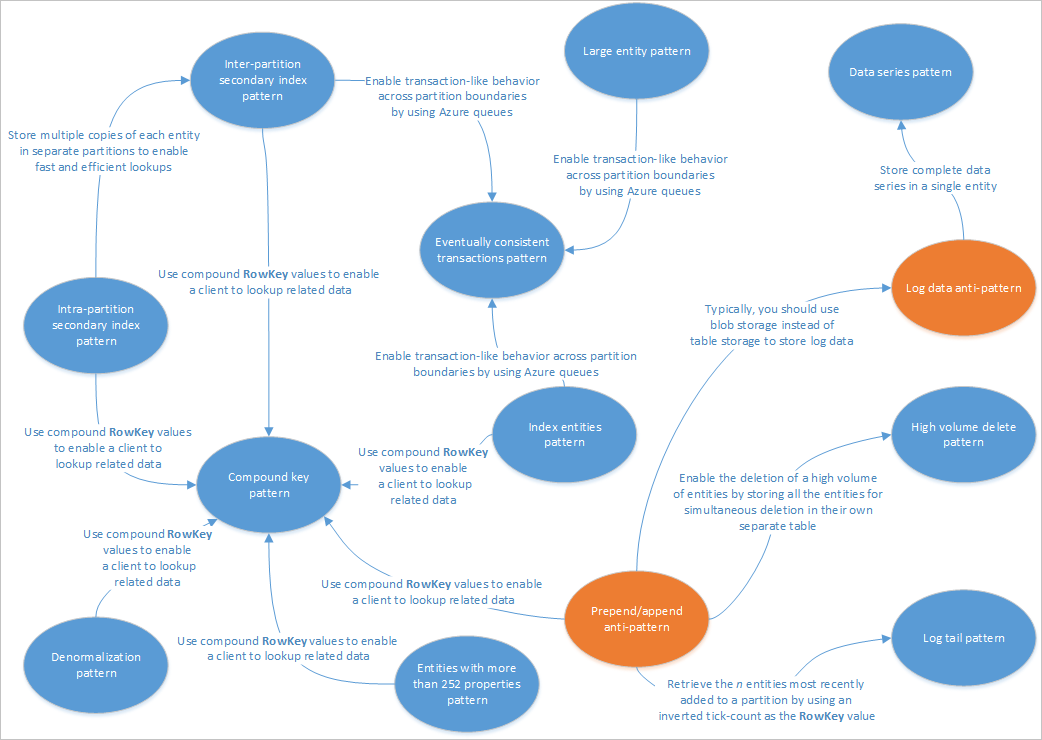
上記のパターン マップには、このガイドに記載されているパターン (青) とアンチパターン (オレンジ) の関係の一部が示されています。 検討する価値があるパターンは他にもたくさんあります。 たとえば、Table サービス向けの主なシナリオの 1 つに、コマンド クエリ責務分離 (CQRS) パターンからのマテリアライズドビュー パターンの使用があります。
パーティション内のセカンダリ インデックス パターン
異なる RowKey 値 (同じパーティション内) を使用して各エンティティの複数のコピーを格納し、異なる RowKey 値を使用した高速で効率的な参照と代替の並べ替え順序を可能にします。 コピー間の更新は、エンティティ グループ トランザクション (EGT) を使用して一貫性を維持できます。
コンテキストと問題
Table service は PartitionKey と RowKey 値を使用して自動的にインデックスを作成します。 そのため、クライアント アプリケーションでは、これらの値を使用してエンティティを効率的に取得できます。 たとえば、次のようなテーブル構造を使用することにより、クライアント アプリケーションでは、ポイント クエリを使用して部署名と従業員 ID (PartitionKey と RowKey 値) から、個々の従業員エンティティを取得できます。 また、各部署内の従業員 ID で並べ替えたエンティティを取得することも可能です。
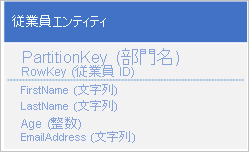
また、電子メール アドレスなど、他のプロパティの値に基づいて従業員エンティティを検索できるようにする場合は、効率の劣るパーティション スキャンを使用して、一致するエンティティを検索する必要があります。 これは、Table サービスではセカンダリ インデックスが提供されないためです。 さらに、 RowKey 順以外の順序で並べ替えられた従業員の一覧を要求するオプションはありません。
解決策
セカンダリ インデックスの不足を回避するには、異なる RowKey 値を使用して各コピーの複数コピーを格納します 。 次のような構造体を持つエンティティを格納する場合は、電子メール アドレスや従業員 ID に基づく複数の従業員エンティティを効率的に取得できます。 RowKey のプレフィックス値 ("empid_" と "email_") によって、電子メール アドレスまたは従業員 ID の範囲を使用することで、1 人の従業員をクエリするかある特定の範囲の従業員をクエリできます。

次の 2 つのフィルター条件 (従業員 ID で検索するフィルター条件とメール アドレスで検索するフィルター条件) ではどちらもポイント クエリを指定しています。
- $filter = (PartitionKey eq 'Sales') と (RowKey eq 'empid_000223')
- $filter=(PartitionKey eq 'Sales') と (RowKey eq 'email_jonesj@contoso.com')
一連の複数の従業員エンティティの範囲をクエリする場合は、従業員 ID の順に並べ替えられた範囲を指定するか、適切なプレフィックスを持つエンティティのクエリを実行して、RowKeyでメール アドレスの順序で格納されている範囲を指定できます。
Sales 部署において、従業員 ID、000100 から 000199 を指定して、すべての従業員を検索するには: $filter=(PartitionKey eq 'Sales') and (RowKey ge 'empid_000100') and (RowKey le 'empid_000199') を使用します。
Sales 部署において、'a' で始まる電子メール アドレスを持つすべての従業員を検索するには:$filter=(PartitionKey eq 'Sales') and (RowKey ge 'email_a') and (RowKey lt 'email_b') を使用します。
上記の例で使用しているフィルター構文は、Table service REST API の構文です。詳細については、エンティティのクエリに関するページを参照してください。
問題と注意事項
このパターンの実装方法を決めるときには、以下の点に注意してください。
テーブル ストレージは比較的低コストで利用できるため、重複するデータを格納してもコストは大きな問題になりません。 ただし、必ず、予想されるストレージ要件に基づいて設計のコストを見積もり、クライアント アプリケーションが実行するクエリで使用するエンティティのみを複製する必要があります。
セカンダリ インデックス エンティティは元のエンティティと同じパーティションに格納されるため、個々のパーティションのスケーラビリティ ターゲットを超えないようにする必要があります。
EGT を使用してエンティティの 2 つのコピーをアトミックに更新することで、重複するエンティティどうしの一貫性を保つことができます。 そのためには、エンティティのすべてのコピーを同じパーティションに格納する必要があります。 詳細については、 エンティティ グループ トランザクションを使用するセクションを参照してください。
RowKey に使用される値は 各エンティティに対して一意である必要があります。 複合キー値の使用を検討してください。
数値を RowKey (たとえば、従業員 ID 000223) にパディングすると、上限と下限に基づき正確な並べ替えとフィルタリングが可能になります。
必ずしもエンティティのすべてのプロパティを複製する必要はありません。 たとえば、電子メールアドレスを使用してエンティティを RowKey で検索するクエリの場合、従業員の年齢は不要です。このようなエンティティは、次のような構造になっている可能性があります。
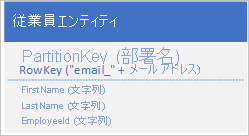
通常は、エンティティの検索と必要なデータの検索にそれぞれ異なるクエリを使用するよりも、重複するデータを格納し、必要なすべてのデータを単一のクエリで取得できるようにすることをお勧めします。
このパターンを使用する状況
クライアント アプリケーションで異なるさまざまなキーを使用してエンティティを取得する必要がある場合、クライアントで異なる順序で並べ替えたエンティティを取得する必要がある場合、さまざまな一意の値を使用して各エンティティを識別できる場合に、このパターンを使用します。 ただし、異なる RowKey 値を使用してエンティティ参照を実行している場合は、パーティションのスケーラビリティの制限を超えていないことを確認してください。
関連のあるパターンとガイダンス
このパターンを実装する場合は、次のパターンとガイダンスも関連している可能性があります。
- パーティション内セカンダリ インデックス パターン
- 複合キー パターン
- エンティティ グループ トランザクション
- 異種のエンティティ種類の使用
パーティション内のセカンダリ インデックス パターン
別個のテーブルの別個のパーティションの異なるRowKey 値 (同じパーティション内) を使用して各エンティティの複数のコピーを格納し、異なる RowKey 値を使用した高速で効率的な参照と代替の並べ替え順序を可能にします。
コンテキストと問題
Table service は PartitionKey と RowKey 値を使用して自動的にインデックスを作成します。 そのため、クライアント アプリケーションでは、これらの値を使用してエンティティを効率的に取得できます。 たとえば、次のようなテーブル構造を使用することにより、クライアント アプリケーションでは、ポイント クエリを使用して部署名と従業員 ID (PartitionKey と RowKey 値) から、個々の従業員エンティティを取得できます。 また、各部署内の従業員 ID で並べ替えたエンティティを取得することも可能です。
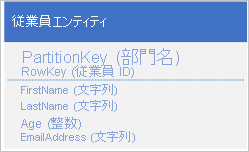
また、電子メール アドレスなど、他のプロパティの値に基づいて従業員エンティティを検索できるようにする場合は、効率の劣るパーティション スキャンを使用して、一致するエンティティを検索する必要があります。 これは、Table サービスではセカンダリ インデックスが提供されないためです。 さらに、 RowKey 順以外の順序で並べ替えられた従業員の一覧を要求するオプションはありません。
これらのエンティティに対するトランザクションが大量になることが予想される場合は、Table service によってクライアントが調整されるリスクを最小限に抑える必要があります。
解決策
セカンダリ インデックスの不足を回避するには、異なるPartitionKey と RowKey 値を使用して各コピーの複数コピーを格納します。 次のような構造体を持つエンティティを格納する場合は、電子メール アドレスや従業員 ID に基づく複数の従業員エンティティを効率的に取得できます。 PartitionKey のプレフィックスの値、"empid_" と "email_" で、クエリに使用するインデックスを特定することができます。

次の 2 つのフィルター条件 (従業員 ID で検索するフィルター条件とメール アドレスで検索するフィルター条件) ではどちらもポイント クエリを指定しています。
- $filter=(PartitionKey eq 'empid_Sales') and (RowKey eq '000223')
- $filter=(PartitionKey eq 'email_Sales') と (RowKey eq 'jonesj@contoso.com')
一連の複数の従業員エンティティの範囲をクエリする場合は、従業員 ID の順に並べ替えられた範囲を指定するか、適切なプレフィックスを持つエンティティのクエリを実行して、RowKeyでメール アドレスの順序で格納されている範囲を指定できます。
- 従業員 ID 順で格納された、従業員 ID が 000100 から 000199 の範囲の Sales 部署のすべての従業員を検索するには、$filter=(PartitionKey eq 'empid_Sales') と (RowKey ge '000100') および (RowKey le '000199') を使用します。
- Sales 部署において、電子メール アドレス順で格納された電子メール アドレスで、'a' で始まる電子メール アドレスを持つすべての従業員を検索するには: $filter=(PartitionKey eq 'email_Sales') and (RowKey ge 'a') and (RowKey lt 'b') を使用します。
上記の例で使用しているフィルター構文は、Table service REST API の構文です。詳細については、エンティティのクエリに関するページを参照してください。
問題と注意事項
このパターンの実装方法を決めるときには、以下の点に注意してください。
プライマリとセカンダリ インデックスのエンティティを維持するため、重複するエンティティを保持して、 最終的に一貫性のあるトランザクション パターン を使用し、互いに最終的に一貫性を持たせます。
テーブル ストレージは比較的低コストで利用できるため、重複するデータを格納してもコストは大きな問題になりません。 ただし、必ず、予想されるストレージ要件に基づいて設計のコストを見積もり、クライアント アプリケーションが実行するクエリで使用するエンティティのみを複製する必要があります。
RowKey に使用される値は 各エンティティに対して一意である必要があります。 複合キー値の使用を検討してください。
数値を RowKey (たとえば、従業員 ID 000223) にパディングすると、上限と下限に基づき正確な並べ替えとフィルタリングが可能になります。
必ずしもエンティティのすべてのプロパティを複製する必要はありません。 たとえば、電子メールアドレスを使用してエンティティを RowKey で検索するクエリの場合、従業員の年齢は不要です。このようなエンティティは、次のような構造になっている可能性があります。

通常は、セカンダリ インデックスを使用したエンティティの検索とプライマリ インデックス内の必要なデータの検索にそれぞれ異なるクエリを使用するよりも、重複するデータを格納し、必要なすべてのデータを単一のクエリで取得できるようにすることをお勧めします。
このパターンを使用する状況
クライアント アプリケーションで異なるさまざまなキーを使用してエンティティを取得する必要がある場合、クライアントで異なる順序で並べ替えたエンティティを取得する必要がある場合、さまざまな一意の値を使用して各エンティティを識別できる場合に、このパターンを使用します。 異なる RowKey 値を使用してエンティティ参照を実行しており、パーティションのスケーラビリティの制限を超えないようにしたい場合、このパターンを使用します 。
関連のあるパターンとガイダンス
このパターンを実装する場合は、次のパターンとガイダンスも関連している可能性があります。
- 最終的に一貫性のあるトランザクション パターン
- パーティション内のセカンダリ インデックス パターン
- 複合キー パターン
- エンティティ グループ トランザクション
- 異種のエンティティ種類の使用
最終的に一貫性のあるトランザクション パターン
Azure Queue を使用して、パーティションやストレージ システムの境界を越えて、最終的に一貫した動作を実現します。
コンテキストと問題
EGT を使用すると、同じパーティション キーを共有する複数のエンティティに対してアトミックなトランザクションを実行できます。 パフォーマンスやスケーラビリティの関係で、一貫性が必要なエンティティを別々のパーティションや別のストレージ システムに格納する場合があります。そのような場合は、EGT を使用して一貫性を保つことはできません。 たとえば、次の一貫性を最終的に確保する必要があるとします。
- 同じテーブル内の 2 つの異なるパーティション、異なるテーブル、異なるストレージ アカウントに格納されているエンティティ。
- Table service に格納されているエンティティと Blob service に格納されている BLOB。
- Table service に格納されているエンティティとファイル システム内のファイル。
- Table service に格納されているにもかかわらず、Azure Cognitive Search サービスを使用してインデックスが作成されているエンティティ。
解決策
Azure キューを使用すると、2 つ以上のパーティションまたはストレージ システム間で最終的に一貫性を確保するソリューションを実装できます。 この方法を説明するために、退職した従業員エンティティをアーカイブできるようにする必要があるという場合を考えてみましょう。 退職した従業員エンティティはめったに照会されず、現在の従業員を対象にしたすべてのアクティビティから除外する必要があります。 この要件を実装するには、現在テーブルにいる現在の従業員と、アーカイブ テーブルにいる退職した従業員を格納します。 従業員をアーカイブするには、現在テーブルからのエンティティを削除し、アーカイブ テーブルにエンティティを追加する必要がありますが、これら 2 つの操作を実行する EGT は使用できません。 エンティティが両方のテーブルに表示されることや、どちらのテーブルにも表示されないことがないように、アーカイブ操作は最終的に一貫性が確保される必要があります。 次のシーケンス図は、この操作の大まかな手順を示しています。 その下のテキストには、例外パスの詳細が示されています。
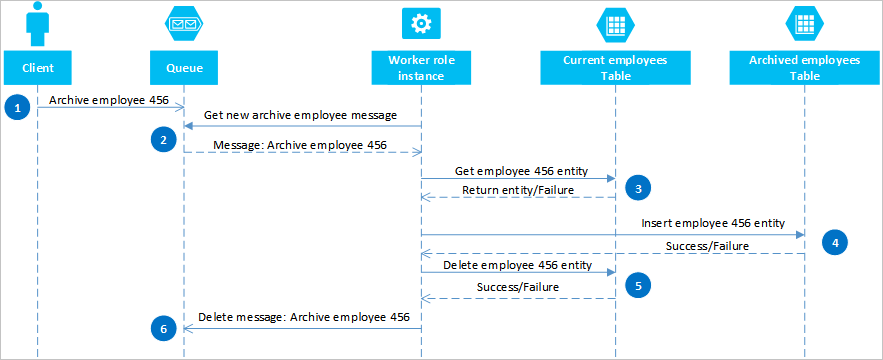
クライアントは、Azure キューにメッセージを配置することによって、アーカイブ操作を開始します。この例では、ID が 456 の従業員をアーカイブします。 worker ロールは、キューをポーリングして新しいメッセージの有無を確認します。メッセージを見つけると、そのメッセージを読み取り、隠しコピーをキューに残します。 worker ロールは、次に、現在テーブルからコピーをフェッチし、アーカイブ テーブルにコピーを挿入し、その後、元のデータを現在テーブルから削除します。 最後に、前の手順でエラーが発生しなければ、worker ロールはキューから隠しメッセージを削除します。
この例では、ステップ 4 で従業員を アーカイブ テーブルに挿入しています。 Blob service の BLOB またはファイル システム内のファイルに従業員を加えることもできます。
エラーからの回復
worker ロールがアーカイブ操作を再開する必要がある場合、手順 4 と 5 の操作がべき等になっていることが重要です。 Table service を使用している場合、手順 4 で「挿入または置換」操作を使用する必要があります。手順 5 では、使用しているクライアント ライブラリ で "存在する場合は削除" 操作を使用する必要があります。 他のストレージ システムを使用する場合は、適切なべき等操作を使用する必要があります。
worker ロールが手順 6を完了しない場合は、タイムアウトの後、メッセージが worker ロール準備完了のキューに表示され再処理を試みます。 worker ロールは、キュー上のメッセージを読み取った回数を確認し、必要に応じて、別のキューに送信することで、調査のために "有害" メッセージとしてフラグを設定できます。 キュー メッセージの読み取りとデキューカウントのチェックに関する詳細については、 メッセージを取得を参照してください。
Table サービスと Queue サービスのエラーには一時的なエラーもあります。クライアント アプリケーションには、そうしたエラーに対処する適切な再試行ロジックを組み込む必要があります。
問題と注意事項
このパターンの実装方法を決めるときには、以下の点に注意してください。
- このソリューションは、トランザクションを分離するためのソリューションではありません。 たとえば、worker ロールが手順 4 と 5 の間で、クライアントは現在とアーカイブ テーブルを読み込むことができます。また、データの非一貫性表示を参照できます。 データは最終的に一貫性が確保されます。
- 最終的に一貫性を確保するために、手順 4 と 5 がべき等になっていることを確認する必要があります。
- 複数のキューと worker ロール インスタンスを使用して、ソリューションを拡張できます。
このパターンを使用する状況
別のパーティションまたはテーブルに存在するエンティティ間の一貫性を最終的に確保する必要がある場合に、このパターンを使用します。 このパターンを拡張して、Table service と Blob service のほかにも、データベースやファイル システムなどの Azure 以外のストレージ データ ソース間の操作で最終的な一貫性を確保できます。
関連のあるパターンとガイダンス
このパターンを実装する場合は、次のパターンとガイダンスも関連している可能性があります。
- エンティティ グループ トランザクション
- マージまたは置換
注意
ソリューションにとってトランザクションの分離が重要な場合は、EGT を使用できるようにテーブルを再設計することを検討する必要があります。
インデックス エンティティのパターン
エンティティ一覧を返す、効率的な検索を有効にするインデックスのエンティティを管理します。
コンテキストと問題
Table service は PartitionKey と RowKey 値を使用して自動的にインデックスを作成します。 そうすると、クライアント アプリケーションでポイント クエリを使用してエンティティを効率的に取得できます。 たとえば、次のようなテーブル構造を使用することにより、クライアント アプリケーションでは、部署名と従業員 ID (PartitionKey と RowKey 値) から、個々の従業員エンティティを効率的に取得できます。

また、姓など、一意ではない他のプロパティの値に基づいて従業員エンティティの一覧を取得できるようにする場合は、インデックスを使用して直接一致するエンティティを検索せずに、効率の劣るパーティション スキャンを使用して検索する必要があります。 これは、Table サービスではセカンダリ インデックスが提供されないためです。
解決策
上のエンティティ構造の場合、姓で検索できるようにするには、従業員 ID の一覧を保持する必要があります。 Jones など、特定の姓を持つ従業員エンティティを取得するには、まず姓が Jones である従業員の従業員 ID の一覧を検索してから、それらの従業員エンティティを取得する必要があります。 従業員 ID の一覧を格納する方法は主に次の 3 つがあります。
- BLOB ストレージを使用する。
- 従業員エンティティと同じパーティションにインデックス エンティティを作成する。
- 別のパーティションまたはテーブルにインデックス エンティティを作成する。
オプション 1:Blob ストレージを使用する
最初のオプションでは、すべての一意の姓について Blob を作成し、その姓の従業員用の各 Blob には PartitionKey (部署) と RowKey (従業員 ID) 値が格納されます。 従業員を追加または削除した場合は、関連する BLOB の内容と従業員エンティティの一貫性が最終的に確保されていることを確認する必要があります。
オプション 2: 同じパーティション内でインデックス エンティティを作成する
2 番目の方法では、以下のデータを格納するインデックス エンティティを使用します。

EmployeeIDs プロパティには、RowKey に格納されている姓を持つ従業員の従業員 ID リストが含まれています。
次の手順は、2 番目の方法を使用した場合に、新しい従業員を追加するときに従う必要がある手順の概要を示しています。 この例では、ID が 000152、姓が Jones の従業員を Sales 部署に追加します。
- PartitionKey 値 "Sales" と RowKey 値 "Jones"を持つインデックスのエンティティを取得します。このエンティティの ETag を、手順 2. で使用するために保存します。
- 新しい従業員エンティティを挿入するエンティティ グループ トランザクション、つまり、バッチ操作 (PartitionKey 値 "Sales" と RowKey 値 "000152") を作成し、新しい従業員 ID を従業員 ID フィールドに追加することでインデックス エンティティ (PartitionKey 値 "Sales" と RowKey 値 "Jones") を更新します。 エンティティ グループ トランザクションの詳細については、「エンティティ グループ トランザクション」をご覧ください。
- オプティミスティック コンカレンシー エラー (他のユーザーがインデックス エンティティを変更したこと) が原因でエンティティ グループ トランザクションが失敗した場合は、手順 1. からまたやり直す必要があります。
2 番目の方法を使用する場合は、同じような方法で従業員を削除できます。 従業員の姓を変更するのは、3 つのエンティティ (従業員エンティティ、元の姓のインデックス エンティティ、新しい姓のインデックス エンティティ) を更新するエンティティ グループ トランザクションを実行する必要があるため、少し複雑です。 変更を加える前に、各エンティティを取得して、ETag 値を取得する必要があります。その ETag 値を使用して、オプティミスティック コンカレンシーで更新を実行できます。
次の手順は、2 番目の方法を使用した場合に、ある部署で特定の姓を持つすべての従業員を検索する必要があるときに従う必要がある手順の概要を示しています。 この例では、Sales 部署で姓が Jones のすべての従業員を検索します。
- PartitionKey 値 "Sales" と RowKey 値 "Jones"を持つインデックスのエンティティを取得します。
- EmployeeIDs フィールドで従業員 ID の一覧を解析します。
- 各従業員に関する追加情報 (電子メール アドレスなど) が必要な場合は、手順 2 で取得した従業員リストから PartitionKey 値 "Sales" と RowKey 値を使用して各従業員のエンティティを取得します。
オプション 3:別のパーティションまたはテーブルにインデックス エンティティを作成する
3 番目の方法では、以下のデータを格納するインデックス エンティティを使用します。

EmployeeDetails プロパティには、RowKey に格納されている姓を持つ従業員の従業員 ID と部署名のペアのリストが含まれています。
3 番目の方法では、インデックス エンティティが従業員エンティティとは別のパーティションにあるため、EGT を使用して一貫性を保つことはできません。 インデックス エンティティが従業員エンティティと最終的に一貫していることを確認してください。
問題と注意事項
このパターンの実装方法を決めるときには、以下の点に注意してください。
- このソリューションでは、一致するエンティティを取得するために、少なくとも 2 つのクエリが必要です。1 つはインデックス エンティティを照会して RowKey 値の一覧を取得するクエリです。もう 1 つはその一覧内の各エンティティを取得するクエリです。
- 個々のエンティティの最大サイズは 1 MB であるため、ソリューションの方法 2 と方法 3 では、特定の姓の従業員 ID の一覧が 1 MB を超えることがないと仮定しています。 従業員 ID の一覧のサイズが 1 MB を超える可能性がある場合は、方法 1 を使用して、BLOB ストレージにインデックス データを格納します。
- 方法 2 を使用する (EGT を使用して、従業員の追加と削除、従業員の姓の変更を処理する) 場合は、トランザクションの量が特定のパーティションのスケーラビリティの限界に近づくかどうかを確認する必要があります。 限界に近づく場合は、キューを使用して更新要求を処理し、従業員エンティティとは別のパーティションにインデックス エンティティを格納でき、最終的に一貫性が確保されるソリューション (方法 1 または方法 3) を検討する必要があります。
- このソリューションの方法 2 では、部署内を姓で検索する (たとえば、Sales 部署で姓が Jones の従業員の一覧を取得する) 必要があると想定しています。 組織全体で姓が Jones のすべての従業員を検索できる必要がある場合は、方法 1 と方法 3 のどちらかを使用します。
- 最終的に一貫性が確保されるキューベースのソリューションを実装できます (詳細については、「 最終的に一貫性のあるトランザクション パターン 」を参照してください)。
このパターンを使用する状況
姓が Jones のすべての従業員など、特定のプロパティ値がすべて共通している一連のエンティティを検索する場合に、このパターンを使用します。
関連のあるパターンとガイダンス
このパターンを実装する場合は、次のパターンとガイダンスも関連している可能性があります。
- 複合キー パターン
- 最終的に一貫性のあるトランザクション パターン
- エンティティ グループ トランザクション
- 異種のエンティティ種類の使用
非正規化パターン
関連するデータを 1 つのエンティティに結合し、1 回のポイント クエリで必要なデータをすべて取得できるようにします。
コンテキストと問題
リレーショナル データベースでは、通常、重複を排除するためにデータを正規化します。その結果、クエリで複数のテーブルからデータを取得することになります。 Azure テーブルのデータを正規化した場合、関連するデータを取得するには、クライアント アプリケーションとサーバー間のラウンド トリップを複数回行う必要があります。 たとえば、以下のテーブル構造を使用した場合、部署の詳細を取得するためには、2 回ラウンド トリップを行う必要があります。1 回目のラウンド トリップでマネージャーの ID を含む部署エンティティをフェッチし、2 回目に従業員エンティティからマネージャーの詳細をフェッチします。

解決策
データを 2 つのエンティティに格納する代わりに、データを非正規化し、部署エンティティにマネージャーの詳細のコピーを保持します。 次に例を示します。
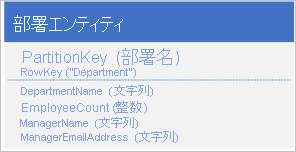
格納されている部署エンティティにはこれらのプロパティがあるため、ポイント クエリを使用して、部署に関して必要なすべての詳細を取得できます。
問題と注意事項
このパターンの実装方法を決めるときには、以下の点に注意してください。
- 一部のデータを重複して格納するため、多少コストがかかります。 通常、ストレージ コストの増加はわずかなため、(ストレージ サービスへの要求が減少することによる) パフォーマンス上のメリットが勝ります (このコストの一部は、部署の詳細をフェッチするために必要なトランザクションの数が減少することで相殺されます)。
- マネージャーに関する情報を格納する 2 つのエンティティの一貫性を維持する必要があります。 一貫性の問題は、EGT を使用して単一のアトミックなトランザクションで複数のエンティティを更新することで対処できます。この例では、部署エンティティと、部署マネージャーの従業員エンティティが同じパーティションに格納されています。
このパターンを使用する状況
関連情報を頻繁に検索する必要がある場合に、このパターンを使用します。 このパターンを使用すると、クライアントが必要なデータを取得するために実行する必要があるクエリの数が減少します。
関連のあるパターンとガイダンス
このパターンを実装する場合は、次のパターンとガイダンスも関連している可能性があります。
- 複合キー パターン
- エンティティ グループ トランザクション
- 異種のエンティティ種類の使用
複合キー パターン
クライアントで単一のポイント クエリを使用して関連するデータを検索できるようにするには、複合 RowKey 値を使用します。
コンテキストと問題
リレーショナル データベースでは、単一のクエリで関連するデータをクライアントに返すために、クエリでよく結合を使用します。 たとえば、従業員 ID を使用して、その従業員の業績と評価データが含まれている関連エンティティの一覧を検索する場合があります。
次の構造を使用し、Table service に従業員エンティティを格納しているとします。
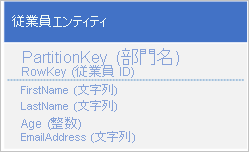
また、各年度の従業員の評価と業績に関する履歴データを格納し、この情報に年度別でアクセスできる必要もあります。 それには、次の構造でエンティティを格納する別のテーブルを作成するという方法があります。
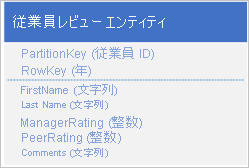
この方法では、単一の要求でデータを取得できるようにするには、一部の情報 (姓や名など) を新しいエンティティに複製する必要があります。 ただし、EGT を使用しても 2 つのエンティティをアトミックには更新できないため、強力な整合性を保つことはできません。
解決策
次の構造のエンティティを使用して、元のテーブルに新しい種類のエンティティを格納します。
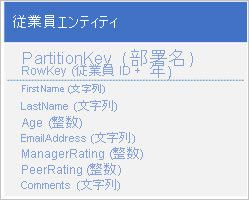
RowKey が従業員 ID と評価データの年度から構成された複合キーとなり、1 つのエンティティに対する 1 つのリクエストで、従業員の業績と評価データを取得できるようになっていることにご注意ください。
次の例では、Sales 部署の従業員 000123 など、特定の従業員のすべての評価データを取得する方法を示しています。
$filter=(PartitionKey eq 'Sales') and (RowKey ge 'empid_000123') and (RowKey lt '000123_2012')&$select=RowKey,Manager Rating,Peer Rating,Comments
問題と注意事項
このパターンの実装方法を決めるときには、以下の点に注意してください。
- 000123_2012 のような、RowKey 値の解析を容易にする適切な区切り文字を使用する必要があります。
- また、このエンティティは、同じ従業員の関連データを含む他のエンティティと同じパーティションに格納します。そうすると、EGT を使用して、強い整合性を維持できます。
- このパターンが適切であるかどうかを判断するには、データを照会する頻度を考慮する必要があります。 たとえば、評価データにはあまり頻度にアクセスせず、メインの従業員データには頻度にアクセスする場合は、それらのデータを別々のエンティティとして保持する必要があります。
このパターンを使用する状況
頻繁に照会する関連エンティティを 1 つ以上格納する必要がある場合に、このパターンを使用します。
関連のあるパターンとガイダンス
このパターンを実装する場合は、次のパターンとガイダンスも関連している可能性があります。
- エンティティ グループ トランザクション
- 異種のエンティティ種類の使用
- 最終的に一貫性のあるトランザクション パターン
ログ テール パターン
逆の日付と時間順でソートする RowKey 値を 使用して最も最近追加された n を取得します。
コンテキストと問題
一般的な要件は、最近作成されたエンティティ (たとえば、従業員から最近提出された 10 件の経費請求) を取得できるようにすることです。 Table クエリは $top クエリ操作をサポートして、最初の n 件のエンティティをセットから返します。セットの最終 n 件のエンティティを返す同等のクエリの操作はありません。
解決策
最新のエントリを逆の日付と時刻の順で自然に並べ替える RowKey を使用したエンティティを保存することで、表の一番上に直近のエントリが表示されます。
たとえば、従業員から最近提出された10 件の経費請求を取得できるようにするには、現在の日時から算出された逆順のティック値を使用できます。 次の c# のコード サンプルは、最新から最古の順で並べ替える RowKey 用の適切な「逆タイマー刻み」値を作成する方法の 1 つを示しています。
string invertedTicks = string.Format("{0:D19}", DateTime.MaxValue.Ticks - DateTime.UtcNow.Ticks);
次のコードを使用すると、日時値に戻すことができます。
DateTime dt = new DateTime(DateTime.MaxValue.Ticks - Int64.Parse(invertedTicks));
テーブル クエリは次のようになります。
https://myaccount.table.core.windows.net/EmployeeExpense(PartitionKey='empid')?$top=10
問題と注意事項
このパターンの実装方法を決めるときには、以下の点に注意してください。
- 文字列値が正しく並び替わるように、逆順のティック値の先頭にゼロをパディングする必要があります。
- パーティション レベルのスケーラビリティ ターゲットに注意する必要があります。 ホット スポット パーティションが発生しないように注意してください。
このパターンを使用する状況
日時の逆順でエンティティにアクセスする必要がある場合、または追加日時の新しい順にエンティティにアクセスする必要がある場合に、このパターンを使用します。
関連のあるパターンとガイダンス
このパターンを実装する場合は、次のパターンとガイダンスも関連している可能性があります。
大量削除パターン
すべてのエンティティを同時削除用に独立したテーブルに格納することで、大量のエンティティを削除できるようにします。エンティティを削除するときは、テーブル自体を削除することになります。
コンテキストと問題
多くのアプリケーションでは、クライアント アプリケーションで使用する必要がなくなった古いデータや、他の記憶域メディアにアーカイブした古いデータを削除します。 通常は、日付でそうしたデータを特定します。たとえば、60 日以上前のすべてのログイン要求のレコードを削除する必要があるとします。
利用可能な設計の 1 つは、 RowKeyでのログイン リクエストの日付と時刻の使用です:
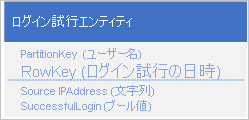
この方法では、アプリケーションが別のパーティションで各ユーザーのログイン エンティティを挿入したり削除したりできるため、パーティションのホット スポットを回避できます。 ただし、まず削除するすべてのエンティティを特定するためにテーブル スキャンを実行し、その後、古い各エンティティを削除する必要があるため、エンティティの数が多い場合、この方法ではコストと時間がかかる可能性があります。 複数の削除要求をバッチ処理として EGT にまとめることで、古いエンティティを削除するのに必要なサーバーへのラウンド トリップの回数を減らすことができます。
解決策
ログイン試行の日付ごとに異なるテーブルを使用します。 上のエンティティのデザインを使用すると、エンティティを挿入する際にホットスポットを回避できます。毎日数百や数千もの個々のログイン エンティティを検索して削除する代わりに、毎日テーブルを 1 つ削除する (単一のストレージ操作) だけで古いエンティティを削除できます。
問題と注意事項
このパターンの実装方法を決めるときには、以下の点に注意してください。
- 特定のエンティティの検索、他のデータとのリンク、集計情報の生成など、データの他の用途もサポートするように設計していますか。
- 新しいエンティティを挿入する際にホットスポットを回避するように設計していますか。
- テーブル名を削除した後に同じテーブル名を再利用する場合に待ち時間が必要になります。 常に一意のテーブル名を使用することをお勧めします。
- Table service ではアクセス パターンを学習して、ノード全体にパーティションを分散しますが、最初に新しいテーブルを使用するときは何らかの調整が行われます。 新しいテーブルを作成する必要がある頻度を検討する必要があります。
このパターンを使用する状況
同時に削除する必要があるエンティティが大量にある場合に、このパターンを使用します。
関連のあるパターンとガイダンス
このパターンを実装する場合は、次のパターンとガイダンスも関連している可能性があります。
- エンティティ グループ トランザクション
- エンティティの変更
データ系列のパターン
データ系列全体を単一のエンティティに格納し、要求の数を最小限に抑えます。
コンテキストと問題
一般的なシナリオとして、通常、アプリケーションで一度にすべて取得する必要があるデータ系列を格納するというものがあります。 たとえば、アプリケーションで 1 時間ごとに各従業員が送信した IM メッセージの数を記録し、後でその情報を使用して、各ユーザーが過去 24 時間以内に送信したメッセージの数をプロットするとします。 設計の 1 つとして、従業員ごとに 24 個のエンティティを格納します。
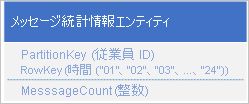
この設計では、アプリケーションでメッセージのカウント値を更新する必要があるときに、各従業員の更新するエンティティを簡単に検索して更新できます。 ただし、情報を取得して、過去 24 時間の活動のグラフをプロットするためには、24 個のエンティティを取得する必要があります。
解決策
次の設計を使用し、各時間のメッセージ数をそれぞれ別のプロパティに格納します。
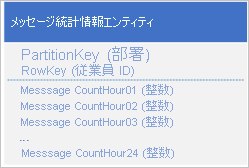
この設計では、マージ操作を使用して、特定の時間の従業員のメッセージ数を更新できます。 これで、単一のエンティティに対する単一の要求を使用して、チャートをプロットするために必要なすべての情報を取得できます。
問題と注意事項
このパターンの実装方法を決めるときには、以下の点に注意してください。
- データ系列全体が単一のエンティティに収まらない場合 (エンティティは最大 252 個のプロパティを持つことができます)、BLOB などの代わりのデータ ストアを使用します。
- 複数のクライアントが同時にエンティティを更新する場合は、 ETag を使用して、オプティミスティック コンカレンシーを実装する必要があります。 クライアントがたくさんある場合は、競合が大量に発生する可能性があります。
このパターンを使用する状況
個々のエンティティに関連付けられているデータ系列を更新したり取得したりする必要がある場合に、このパターンを使用します。
関連のあるパターンとガイダンス
このパターンを実装する場合は、次のパターンとガイダンスも関連している可能性があります。
- ラージ エンティティ パターン
- マージまたは置換
- 最終的に一貫性のあるトランザクション パターン (格納するデータ系列を Blob に格納している場合)
ワイド エンティティ パターン
複数の物理エンティティを使用して、252 を超えるプロパティを持つ論理エンティティを格納します。
コンテキストと問題
個々のエンティティが持つことができるプロパティは、(必須のシステム プロパティを除き) 252 個までです。また、格納できるデータは合計で 1 MB までです。 リレーショナル データベースでは、通常、新しいテーブルを追加し、その新しいテーブルと 1 対 1 のリレーションシップを作成することによって、行のサイズに関するさまざまな制限を回避します。
解決策
Table service を使用すると、複数のエンティティを格納して、252 を超えるプロパティを持つ単一の大きなビジネス オブジェクトを作成できます。 たとえば、過去 365 日の間に各従業員が送信した IM メッセージの数を格納する場合は、スキーマの異なる 2 つのエンティティを使用する次のデザインを使用できます。

両方のエンティティを更新しないとエンティティどうしの同期が維持されない変更を加える必要がある場合は、EGT を使用できます。 それ以外の場合は、単一のマージ操作を使用して、特定の日のメッセージ数を更新できます。 個々 の従業員のすべてのデータを取得するには、PartitionKey と RowKey 値の両方を使用する 2 つの効率的なリクエストを取得する必要があります。
問題と注意事項
このパターンの実装方法を決めるときには、以下の点に注意してください。
- 論理エンティティ全体を取得するには、少なくとも 2 つのストレージ トランザクション (各物理エンティティを取得するトランザクション) が必要です。
このパターンを使用する状況
サイズやプロパティの数が Table service の個々のエンティティの制限を超えるエンティティを格納する必要がある場合に、このパターンを使用します。
関連のあるパターンとガイダンス
このパターンを実装する場合は、次のパターンとガイダンスも関連している可能性があります。
- エンティティ グループ トランザクション
- マージまたは置換
大型エンティティ パターン
大規模なプロパティの値を格納する BLOB ストレージを使用します。
コンテキストと問題
個々のエンティティに格納できるデータは合計で 1 MB までです。 1 つまたは複数のプロパティに格納される値でエンティティの合計サイズが 1 MB を超える場合は、Table service にエンティティ全体は格納できません。
解決策
1 つ以上のプロパティに大量のデータが含まれているためにエンティティのサイズが 1 MB を超える場合は、Blob service にデータを格納し、エンティティのプロパティに BLOB のアドレスを格納できます。 たとえば、従業員の写真を Blob ストレージに格納し、写真へのリンクを従業員エンティティの フォト プロパティに格納できます。

問題と注意事項
このパターンの実装方法を決めるときには、以下の点に注意してください。
- Table service 内のエンティティと、Blob service 内のデータの間の最終的な一貫性を保つには、最終的に一貫性のあるトランザクション パターン を使用してエンティティを維持します。
- エンティティ全体を取得するには、少なくとも 2 つのストレージ トランザクション (エンティティを取得するトランザクションと BLOB データを取得するトランザクション) が必要です。
このパターンを使用する状況
サイズが Table service の個々のエンティティの制限を超えるエンティティを格納する必要がある場合に、このパターンを使用します。
関連のあるパターンとガイダンス
このパターンを実装する場合は、次のパターンとガイダンスも関連している可能性があります。
先頭または末尾に追加するアンチパターン
大量に挿入する場合に、挿入を複数のパーティションに分散させることで、スケーラビリティを向上させます。
コンテキストと問題
格納されているエンティティの先頭または末尾にエンティティを追加すると、通常は、連続するパーティションの最初または最後のパーティションに新しいエンティティが追加されます。 この場合、常に挿入はすべて同じパーティション内で行われるため、ホットスポットが発生し、Table service が複数のノードに挿入の負荷を分散できず、場合によっては、パーティションのスケーラビリティ ターゲットに達する可能性があります。 たとえば、従業員によるネットワークやリソースへのアクセスをログに記録するアプリケーションで、以下に示すエンティティ構造を使用した場合、トランザクションの量が個々のパーティションのスケーラビリティ ターゲットに達すると、現在処理が行われているパーティションがホットスポットになる可能性があります。

解決策
代わりに次のエンティティ構造を使用すると、アプリケーションでイベントをログに記録する際に特定のパーティションのホットスポットを回避できます。

次の例では 2 つのキー PartitionKey と RowKey がどのように複合キーになっているか注意してください。 PartitionKey は部署と従業員の両方の ID を使用して複数のパーティションにログを配布します。
問題と注意事項
このパターンの実装方法を決めるときには、以下の点に注意してください。
- 挿入時のホット パーティションの発生を回避する代わりのキー構造でクライアント アプリケーションが実行するクエリを効率的にサポートしていますか。
- 予想されるトランザクションの量から判断して、個々のパーティションのスケーラビリティ ターゲットに達し、ストレージ サービスによって調整される可能性がありますか。
このパターンを使用する状況
トランザクションの量により、ホット パーティションにアクセスするとストレージ サービスによって調整される可能性がある場合は、先頭または末尾に追加するアンチパターンを使用しないでください。
関連のあるパターンとガイダンス
このパターンを実装する場合は、次のパターンとガイダンスも関連している可能性があります。
ログ データのアンチパターン
ログ データの格納には通常、Table service ではなく Blob service を使用します。
コンテキストと問題
ログ データを使用する局面として最も一般的なのが、特定の日付範囲または時間範囲のログ エントリを選択して取得するというものです。たとえば、特定の日の 15:04 から 15:06 までの間にアプリケーションが記録したエラー メッセージや重要なメッセージをすべて取得するなどの局面が挙げられます。 ログ メッセージの日時を使用して、ログのエンティティを保存するパーティションを特定したくない場合は、ホット パーティションになります。任意の時点で、すべてのログ エンティティが同じ PartitionKey 値を共有します (先頭または末尾に追加するアンチ パターンのセクションをご覧ください)。 たとえば、ログ メッセージに関する以下のエンティティ スキーマでは、アプリケーションが現在の日付や時刻についてパーティションにあらゆるログ メッセージを書き込むことになるため、ホット パーティションの問題が発生します。
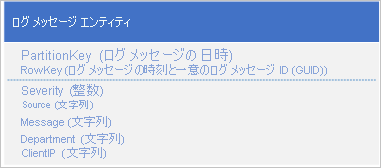
この例では、RowKey にはログ メッセージが日時順で格納されていることを確認するため、ログメッセージの日時が含まれており、複数のメッセージが同じ日時を共有する複数のログ メッセージの場合にはメッセージ ID も含まれています。
別の方法は、アプリケーションに確実に パーティション範囲にわたってメッセージを書き込ませる PartitionKey の使用です。 たとえば、ログ メッセージのソースで多数のパーティションにメッセージを配信できるようになっている場合には、以下のエンティティ スキーマを使用できます。
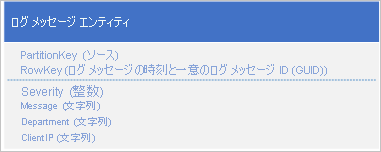
ただし、このスキーマには問題があります。特定のタイム スパンに記録されたログ メッセージをすべて取得するときには、テーブル内のパーティションを逐一検索する必要があるからです。
解決策
前のセクションでは、ログ エントリの保存先として Table service を使用した場合に生じる問題について説明し、その解決策として、完璧とは言いがたいものの 2 つの設計を紹介しました。 1 つ目に紹介した方法には、ホット パーティションが発生し、ログ メッセージの書き込みのパフォーマンスが低下するリスクがあります。これに対して 2 つ目の方法は、特定のタイム スパンについてログ メッセージを取得しようとした場合に、テーブル内のパーティションを逐一スキャンしなければならないため、クエリのパフォーマンスが低下するという問題がありました。 BLOB ストレージなら、ここで取り上げたシナリオについて前の 2 つよりも優れたソリューションとなることができます。このため、Azure Storage Analytics が収集したログ データを保存するときにも、この BLOB ストレージが使用されています。
このセクションでは、Storage Analytics が BLOB ストレージにログ データを格納する流れの概要を説明し、範囲を指定してクエリを実行することが多いデータを保存する際にこのアプローチがどのように役立つかを見ていきます。
Storage Analytics では、ログ メッセージを一定の形式で区切ったものを、複数の BLOB に格納します。 区切りに使用する形式は、クライアント アプリケーション側でログ メッセージのデータ解析を円滑に完了できるものになっています。
Storage Analytics が BLOB に対して使用している名前付け規則は、検索対象のログ メッセージが含まれる BLOB の場所を特定できるようなものになっています。 たとえば、"queue/2014/07/31/1800/000001.log" という名前の BLOB であれば、2014 年 7 月 31 日の 18:00 から始まる時間の Queue サービスと関係があるログ メッセージが格納されています。 "000001" という部分は、この期間の最初のログ ファイルであることを示しています。 このほか、Storage Analytics では BLOB のメタデータの一環として、ファイルに保存されている最初と最後のログ メッセージのタイムスタンプを記録します。 BLOB ストレージの API では、一定の名前プレフィックスに基づいてコンテナー内の BLOB の場所を特定できるようになっています。18:00 に始まる時間についてキューのログ データを格納している BLOB をすべて検索する場合には、"queue/2014/07/31/1800" というプレフィックスを使用できます。
Storage Analytics は内部のバッファーにログ メッセージを保管したうえで、ログ エントリのバッチの最新版を使って定期的に BLOB を更新したり、新しい BLOB を作成したりします。 これによって、BLOB サービスに書き込みを実行する回数が少なくなります。
アプリケーションにこれと似たソリューションを実装するときには、信頼性 (ログ エントリが発生するたびに BLOB ストレージに書き込む) と、コストとスケーラビリティ (アプリケーションに更新内容を一時的に保管し、バッチとして BLOB ストレージに書き込む) との間のトレードオフをどのようにするかについて、検討が必要になります。
問題と注意事項
ログ データの保存方法を決めるときには、以下の点に注意する必要があります。
- ホット パーティションが発生しないような設計のテーブルを作成すると、ログ データに対するアクセス効率が低下することがあります。
- ログ データを処理するときには多くの場合、クライアント側で多くのレコードを読み込む必要があります。
- ログ データは構造化されていることが多いものの、BLOB ストレージの方が優れたソリューションになることがあります。
実装時の注意事項
このセクションでは、ここまでのセクションで説明したパターンを実装する際に念頭に置く必要がある点をいくつか説明します。 このセクションのほとんどの部分で例を示しており、これは C# で書かれ、ストレージ クライアント ライブラリ (本稿執筆時点のバージョンは 4.3.0) を使用しています。
エンティティの取得
「クエリに対応した設計」で説明したように、最も効率的なクエリはポイント クエリです。 ただ、時として多数のエンティティを同時に取得することも必要になります。 このセクションでは、ストレージ クライアント ライブラリを使ってエンティティを取得するときによく使用される方法をいくつか紹介します。
ストレージ クライアント ライブラリを使ってポイント クエリを実行する
ポイント クエリを実行する最も簡単な方法は、次の c# コード スニペットに表示された、PartitionKey 値 "Sales" と RowKey 値 "212" を持つエンティティを取得する GetEntityAsync メソッドの使用です。
EmployeeEntity employee = await employeeTable.GetEntityAsync<EmployeeEntity>("Sales", "212");
この例では、 従業員エンティティ取得についてどのように予想しているかに注意してください。
LINQ を使用して複数のエンティティを取得する。
LINQ を使用すると、Microsoft Azure Cosmos DB Table Standard Library を使用するときに、Table service から複数のエンティティを取得できます。
dotnet add package Azure.Data.Tables
以下の例を機能させるには、名前空間を含める必要があります。
using System.Linq;
using Azure.Data.Tables
複数のエンティティの取得は、filter 句でクエリを指定することで実現できます。 テーブル スキャンを回避するには、filter 句の PartitionKey 値と、可能であれば RowKey 値をインクルードし、テーブルとパーティションのスキャンを避けます。 Table サービスは、filter 句で一部の比較演算子 (より大きい、以上、より小さい、以下、等しい、等しくない) のみサポートしています。
次の例では、employeeTable は TableClient オブジェクトです。 この例では、Sales という部署 (PartitionKey が部署名を格納していると仮定) の中で、姓が "B" (RowKey が姓を格納していると仮定) で始まるすべての従業員を検索します。
var employees = employeeTable.Query<EmployeeEntity>(e => (e.PartitionKey == "Sales" && e.RowKey.CompareTo("B") >= 0 && e.RowKey.CompareTo("C") < 0));
パフォーマンスを確保するため、クエリで RowKey と PartitionKey の両方をどのように指定するか注意してください。
次のコード サンプルは、LINQ 構文を使用しない同等の機能を示しています。
var employees = employeeTable.Query<EmployeeEntity>(filter: $"PartitionKey eq 'Sales' and RowKey ge 'B' and RowKey lt 'C'");
注意
サンプルの Query メソッドでは、3 つの filter 条件を使用しています。
1 件のクエリで大量のエンティティを取得する
最適なクエリは PartitionKey 値と RowKey 値に基づいて個別のエンティティを返します。 ところが、場合によっては同じパーティション、ときには多数のパーティションから、多数のエンティティを返すことが必要になります。
そのようなときには必ず、アプリケーションのパフォーマンスを綿密にテストする必要があります。
Table サービスに対してクエリを実行した場合、一度に返されるエンティティの数は最大 1,000 件、クエリの実行時間は最大 5 秒間です。 結果として返されるエンティティが 1,000 件を超える場合、クエリが 5 秒以内に完了しなかった場合、またはクエリがパーティションの境界をまたいで実行される場合には、Table service によって継続トークンが返されます。クライアント アプリケーションはこのトークンを使って、続きとなるエンティティを要求します。 継続トークンの詳細については、「クエリのタイムアウトと改ページ」をご覧ください。
Azure テーブル クライアント ライブラリを使用している場合には、Table service からエンティティが返されるたびに継続トークンが自動で処理されます。 以下の C# コード サンプルではクライアント ライブラリを使用しているため、Table service が応答で継続トークンを返すと自動的に処理されます。
var employees = employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'")
foreach (var emp in employees)
{
// ...
}
ページごとに返されるエンティティの最大数を指定することもできます。 次の例は、maxPerPage を使用してエンティティをクエリする方法を示しています。
var employees = employeeTable.Query<EmployeeEntity>(maxPerPage: 10);
// Iterate the Pageable object by page
foreach (var page in employees.AsPages())
{
// Iterate the entities returned for this page
foreach (var emp in page.Values)
{
// ...
}
}
より高度なシナリオでは、サービスから返された継続トークンを格納して、次のページがフェッチされるタイミングをコードで正確に制御することができます。 次の例は、トークンをフェッチしてページ分割された結果に適用する方法の基本的なシナリオを示しています。
string continuationToken = null;
bool moreResultsAvailable = true;
while (moreResultsAvailable)
{
var page = employeeTable
.Query<EmployeeEntity>()
.AsPages(continuationToken, pageSizeHint: 10)
.FirstOrDefault(); // pageSizeHint limits the number of results in a single page, so we only enumerate the first page
if (page == null)
break;
// Get the continuation token from the page
// Note: This value can be stored so that the next page query can be executed later
continuationToken = page.ContinuationToken;
var pageResults = page.Values;
moreResultsAvailable = pageResults.Any() && continuationToken != null;
// Iterate the results for this page
foreach (var result in pageResults)
{
// ...
}
}
継続トークンを明示的に使用すると、アプリケーションが次のセグメントに相当するデータを取得するタイミングを制御できます。 たとえば、テーブルに格納されたエンティティをクライアント アプリケーションでページとして表示できるようにしている場合に、クエリで取得したエンティティをユーザーが最後まで見ないことがあります。そのようなとき、継続トークンを明示的に使用していれば、ユーザーが現在のセグメントのエンティティの最後のページに達した時点で、アプリケーションが継続トークンだけを使って次のセグメントを取得できます。 この方法には、いくつかの利点があります。
- Table service から取得するデータの量を制限したり、ユーザーがネットワークを移動したりできるようになります。
- .NET の非同期 IO を実行できるようになります。
- 継続トークンをシリアル化して永続記憶装置に保存できるため、アプリケーションがクラッシュした場合でも処理を継続できるようになります。
Note
継続トークンは通常、エンティティ 1,000 件を 1 つのセグメントにして返しますが、この数が少なくなることもあります。 これも、取得を使用してクエリが返すをエントリの数を制限する場合は、検索条件に一致する最初の n 件のエンティティを返します。テーブル サービスは、残りのエンティティを取得するために、継続トークンと合わせて n 件より少ないエンティティを含むセグメントを返す可能性があります。
サーバー側のプロジェクション
1 つのエンティティには最大で 255 個のプロパティを格納でき、エンティティの最大サイズは 1 MB です。 テーブルに対してクエリを実行してエンティティを取得する際、すべてのプロパティが必要ない場合は、データの不要な転送を避けることができます (遅延とコストの削減につながります)。 サーバー側のプロジェクションを使えば、必要なプロパティのみを転送できます。 次の例は、クエリによって選択されたエンティティから Email プロパティ (PartitionKey、RowKey、Timestamp、ETag と連動) を取得しています。
var subsetResults = query{
for employee in employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'") do
select employee.Email
}
foreach (var e in subsetResults)
{
Console.WriteLine("RowKey: {0}, EmployeeEmail: {1}", e.RowKey, e.Email);
}
RowKey 値が取得するプロパティのリストに含まれていなくても、どのように利用できるか注意してください。
エンティティの変更
ストレージ クライアント ライブラリを使えば、Table service に格納されたエンティティを、挿入、削除、更新の各操作によって変更できます。 また、EGT を使えば複数の挿入、更新、削除の操作をバッチ処理で行えるため、必要なラウンド トリップの回数が減り、ソリューションのパフォーマンスが高まります。
ストレージ クライアント ライブラリが EGT を実行したときにスローされる例外には、通常、バッチ処理の失敗を招いたエンティティのインデックスが含まれます。 これは EGT を使うコードをデバッグする際に役立ちます。
クライアント アプリケーションでのコンカレンシーと更新操作の処理方法に設計が及ぼす影響についても考慮が必要です。
コンカレンシーを管理する
既定では、テーブル サービスは個々 のエンティティのレベルで挿入、マージ、削除操作に対しオプティミスティック コンカレンシー チェックを実行しますが、クライアントは、テーブル サービスがこれらのチェックをバイパスするよう強制することもできます。 Table service でのコンカレンシーの管理方法については、「 Microsoft Azure Storage でのコンカレンシー制御の管理」を参照してください。
マージまたは置換
TableOperation クラスの置換のメソッドは、常に、Table service の完全なエンティティを置換します。 格納されたエンティティに存在するプロパティを要求に含めない場合、要求により、格納されたエンティティからそのプロパティが削除されます。 格納されたエンティティからプロパティを明示的に削除しない場合は、すべてのプロパティを要求に含める必要があります。
TableOperation クラスのマージ メソッドを使用して エンティティを更新するときの Table service に送信するデータの量を削減します。 マージ メソッドはプロパティ値を持った格納エンティティのプロパティをリクエストに含まれるエンティティと置換しますが、リクエストに含まれない格納エンティティ内の無傷のプロパティはそのまま残します。 ラージ エンティティがあり、要求で少数のプロパティのみを更新する必要があるときに便利な処理です。
Note
エンティティが存在しない場合、置換とマージ メソッドが失敗します。 存在しない場合は、代わりに、InsertOrReplace と InsertOrMerge メソッドを使用して新しいエンティティを作成します。
異種のエンティティ種類の使用
Table service とは、スキーマのない テーブル ストアであり、 1 つのテーブルが複数の種類のエンティティを格納できるため、非常に柔軟な設計が提供できることを意味します。 次の例は、従業員エンティティと部署エンティティの両方を格納したテーブルを示しています。
| パーティション キー | RowKey | Timestamp | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||
| |||||||||||
|
|||||||||||
|
各エンティティはなお、PartitionKey、RowKey、Timestamp 値を持つ必要がありますが、プロパティ セットを持つ場合もあります。 さらに、エンティティの種類を示すものがありません (エンティティの種類に関する情報を格納していない場合)。 エンティティの種類を識別する方法は 2 とおりあります。
- RowKey (または PartitionKey) にエンティティ型を追加。 例えば、RowKey 値としてのEMPLOYEE_000123 または DEPARTMENT_SALES。
- 以下の表に示すように、個別のプロパティを使用してエンティティの種類を記録します。
| パーティション キー | RowKey | Timestamp | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||
| |||||||||||||
|
|||||||||||||
|
最初のオプションでは、エンティティ型を RowKeyの先頭に着けると、異なる種類の 2 つのエンティティが同じキー値にある可能性がある場合に便利です。 この方法なら、パーティションに同じ種類のエンティティのグループ化もできます。
このセクションで説明した手法は、特に、本ガイドに前述のリレーションシップのモデル化に関する記事内の継承リレーションシップで説明した内容と関連があります。
Note
エンティティの種類の値にバージョン番号を追加して、クライアント アプリケーションで POCO オブジェクトを発展させ、さまざまなバージョンを操作できるようにすることを検討してください。
このセクションの残りの部分では、同じテーブル内の複数の種類のエンティティを操作しやすくするストレージ クライアント ライブラリの機能について説明します。
異なる種類のエンティティを取得する
テーブル クライアント ライブラリを使えば、3 とおりの方法で複数の種類のエンティティを操作できます。
特定の RowKey および PartitionKey 値とともに格納されているエンティティの種類がわかっている場合は、EmployeeEntity という種類のエンティティを取得する前述の 2 つの例 (「ストレージ クライアント ライブラリを使ってポイント クエリを実行する」および「LINQ を使って複数のエンティティを取得する」) に示すように、エンティティを取得する際にエンティティの種類を指定できます。
2 番目のオプションは、具体的な POCO エンティティ型ではなく、TableEntity 型 (プロパティ バッグ) の使用です (エンティティを .NET 型にシリアル化および非シリアル化する必要がないため、このオプションはパフォーマンスも向上させます) 。 次の c# コードは、テーブルから潜在的にさまざまな種類の複数のエンティティを取得しますが、すべてのエンティティを TableEntity インスタンスとして返します。 EntityType プロパティを使用して各エンティティの種類を決定します。
Pageable<TableEntity> entities = employeeTable.Query<TableEntity>(x =>
x.PartitionKey == "Sales" && x.RowKey.CompareTo("B") >= 0 && x.RowKey.CompareTo("F") <= 0)
foreach (var entity in entities)
{
if (entity.GetString("EntityType") == "Employee")
{
// use entityTypeProperty, RowKey, PartitionKey, Etag, and Timestamp
}
}
その他のプロパティを取得するには、TableEntity クラスの entity で GetString メソッドを使用する必要があります。
異なる種類のエンティティを変更する
エンティティの種類がわからなくても削除はできますが、挿入はできません。 ただし、エンティティの種類がわからない場合は、POCO エンティティ クラスを使用せず、TableEntity 型を使用してエンティティを更新します。 次のコード サンプルでは、1 つのエンティティを取得し、 EmployeeCount プロパティが存在するか、更新前に確認しています。
var result = employeeTable.GetEntity<TableEntity>(partitionKey, rowKey);
TableEntity department = result.Value;
if (department.GetInt32("EmployeeCount") == null)
{
throw new InvalidOperationException("Invalid entity, EmployeeCount property not found.");
}
employeeTable.UpdateEntity(department, ETag.All, TableUpdateMode.Merge);
共有アクセス署名でのアクセスを制御する
Shared Access Signature (SAS) トークンを使うと、ストレージ アカウント キーをコードに追加しなくても、クライアント アプリケーションからテーブル エンティティに対して変更を加えたり、クエリを実行したりすることができます。 通常、アプリケーションで SAS を使うと、次の 3 つのメリットが得られます。
- デバイスで Table service のエンティティにアクセスして変更できるようにするために、安全ではないプラットフォーム (モバイル デバイスなど) にストレージ アカウント キーを配布する必要がない。
- Web ロールまたは worker ロールがエンティティを管理する際に実行する処理の一部を、エンド ユーザー コンピューターやモバイル デバイスなどのクライアント デバイスにオフロードできる。
- 制約と時間制限のあるアクセス許可のセットをクライアントに割り当てることができる (読み取り専用アクセスを特定のリソースに許可するなど)。
Table service での SAS トークンの使用について詳しくは、「 Shared Access Signatures (SAS) の使用」をご覧ください。
ただし、Table サービスのエンティティへのアクセスをクライアント アプリケーションに付与する SAS トークンを生成する必要はあります。これは、ストレージ アカウント キーに安全にアクセスできる環境で行うようにしてください。 通常は、Web ロールまたは worker ロールを使って SAS トークンを生成し、エンティティへのアクセスを必要とするクライアント アプリケーションに配布します。 SAS トークンの生成とクライアントへの配布にもやはりオーバーヘッドが伴うため、特に大量に扱うシナリオでは、このオーバーヘッドを減らす最適な方法を検討する必要があります。
テーブル内のエンティティのサブセットへのアクセスを付与する SAS トークンを生成できます。 既定では、テーブル全体に対し SAS トークンを作成しますが、SAS トークンへのアクセス許可を PartitionKey 値の範囲か、PartitionKey と RowKey 値の範囲のいずれかに指定することも可能です。 システムの個々のユーザーに SAS トークンが生成されるようにすれば、各ユーザーの SAS トークンによってアクセスが許可されるのは、Table サービス内にあるユーザー独自のエンティティだけになります。
非同期と並列操作
要求を複数のパーティションに分散させている場合は、非同期または並列クエリを使ってスループットとクライアントの応答性を向上させることができます。 たとえば、テーブルに並列的にアクセスする複数の worker ロール インスタンスを使用する場合などです。 個別の worker ロールで特定のパーティション セットのみを処理することも可能であるほか、テーブル内のすべてのパーティションにアクセスできる worker ロール インスタンスを複数実装することも可能です。
クライアント インスタンスでは、ストレージ操作を非同期的に実行することでスループットを高めることができます。 ストレージ クライアント ライブラリを使えば、非同期のクエリと変更を簡単に記述できます。 たとえば、次の C# コードに示すように、パーティション内のすべてのエントリを取得する同期メソッドをベースとして利用できます。
private static void ManyEntitiesQuery(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = employeeTable.Query<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
このコードを次のように少し変更して、クエリが非同期的に実行されるようにします。
private static async Task ManyEntitiesQueryAsync(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = await employeeTable.QueryAsync<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
この非同期の例は、同期のバージョンに次の変更が加えられたものです。
- メソッドのシグネチャは async 修飾子を含み、Task インスタンスを返します。
- Query メソッドを呼び出して結果を取得する代わりに、QueryAsync メソッドを呼び出し、await 修飾子を使用して非同期的に結果を取得します。
クライアント アプリケーションが複数回このメソッドを呼び出し ( 部署 パラメーターの異なる値のため)、各クエリは個別のスレッドで実行されます。
エンティティを非同期的に挿入、更新、削除できます。 次の C# の例は、従業員エンティティを挿入または置換する単純な同期メソッドです。
private static void SimpleEmployeeUpsert(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = employeeTable.UpdateEntity(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Status);
}
このコードを次のように少し変更して、更新が非同期的に実行されるようにすることができます。
private static async Task SimpleEmployeeUpsertAsync(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = await employeeTable.UpdateEntityAsync(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Result.Status);
}
この非同期の例は、同期のバージョンに次の変更が加えられたものです。
- メソッドのシグネチャは async 修飾子を含み、Task インスタンスを返します。
- Execute メソッドを呼び出してエンティティを更新する代わりに、ExecuteAsync メソッドを呼び出し、await 修飾子を使用して非同期的に結果を取得します。
クライアント アプリケーションは、これと同じように非同期メソッドを複数回呼び出すことができます。各メソッドの呼び出しは別々のスレッドで実行されます。