Azure Stream Analytics での異常検出
クラウドと Azure IoT Edge の両方で利用できます。Azure Stream Analytics には、機械学習をベースにした異常検出機能が組み込まれています。これを使用して、最も多く発生する 2 種類の異常 (一時的な異常と永続的な異常) を監視できます。 AnomalyDetection_SpikeAndDip と AnomalyDetection_ChangePoint 関数を使用して、異常検出を Stream Analytics ジョブ内で直接実行することができます。
機械学習モデルでは、均等にサンプリングされたタイム シリーズを想定しています。 時系列が一様でない場合は、異常検出を呼び出す前にタンブリング ウィンドウを含む集計ステップを挿入できます。
現時点で、機械学習の処理は、季節性の傾向や多変量の相関関係には対応していません。
Azure Stream Analytics で機械学習を使用した異常検出
次の動画では、Azure Stream Analytics の機械学習機能を使ってリアルタイムで異常を検出する方法を示します。
モデルの動作
一般に、スライディング ウィンドウ内のデータが多いほどモデルの精度が向上します。 指定したスライディング ウィンドウ内のデータは、その期間の正常範囲の値の一部として扱われます。 モデルで現在のイベントの異常性を調べるときは、スライディング ウィンドウ内のイベント履歴のみが考慮されます。 スライディング ウィンドウが動くと、モデルのトレーニングから古い値が削除されます。
この機能は、これまでの履歴を基に一定の標準を確立することによって動作します。 外れ値は、信頼度レベル内で、確立された標準と比較することで識別されます。 異常が発生したときに認識できるように、ウィンドウのサイズは、正常な動作でモデルをトレーニングするのに必要な最小イベント数を基準にしてください。
履歴のサイズが大きくなると、比較対象となる過去のイベント数も増えるため、モデルの応答時間が増えます。 パフォーマンスを向上させるために必要なイベントの数のみを含めるのをお勧めします。
タイム シリーズにギャップがある場合、モデルが特定の時点のイベントを受け取っていないことが原因である可能性があります。 このような状況は、Stream Analytics の補完ロジックによって処理されます。 同じスライディング ウィンドウの履歴サイズと期間の両方を使用して、イベントの平均出現率が計算されます。
ここで公開されている異常ジェネレーターは、IoT Hub にさまざまな異常パターン データをフィードするために使用できます。 これらの異常検出関数を使用して Azure Stream Analytics ジョブを設定して、この IoT Hub から読み取り、異常を検出できます。
スパイクとディップ
タイム シリーズ イベント ストリーム内の一時的な異常は、スパイクとディップと呼ばれます。 スパイクとディップは、機械学習をベースにした演算子 AnomalyDetection_SpikeAndDip を使って監視できます。
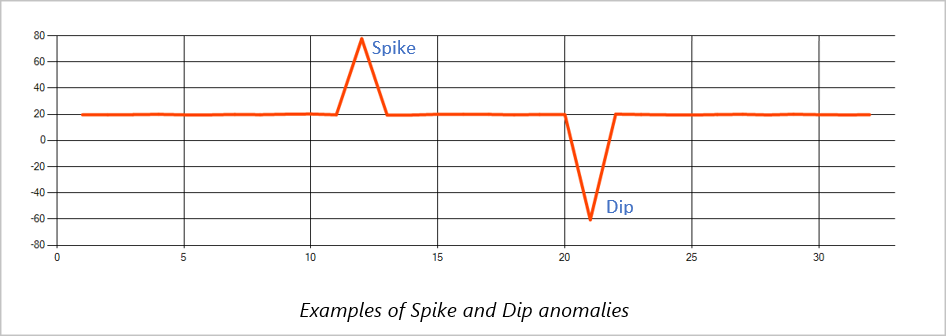
同じスライディング ウィンドウ内の 2 番目のスパイクが 1 番目のものよりも小さい場合、小さい方のスパイクに対して計算されるスコアが、指定した信頼度レベル内の最初のスパイクのスコアに比べて十分な大きさにならないことがあります。 このような異常を検知するには、モデルの信頼度レベルの設定を低くしてみてください。 ただし、それによってアラートの数が増えすぎてしまう場合は、より高い信頼区間を使用できます。
次のサンプル クエリでは、120 件のイベント履歴を持つ 2 分間のスライディング ウィンドウで、1 秒あたり 1 件という一定の割合でイベントの入力があるものとします。 最後の SELECT ステートメントで、95% の信頼度レベルでスコアと異常状態を抽出して出力します。
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_SpikeAndDip(CAST(temperature AS float), 95, 120, 'spikesanddips')
OVER(LIMIT DURATION(second, 120)) AS SpikeAndDipScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'Score') AS float) AS
SpikeAndDipScore,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'IsAnomaly') AS bigint) AS
IsSpikeAndDipAnomaly
INTO output
FROM AnomalyDetectionStep
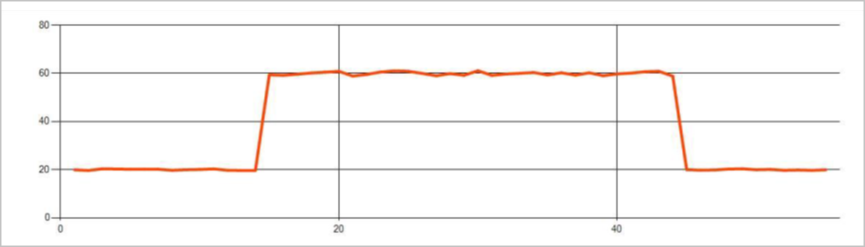
変化点
タイム シリーズ イベント ストリーム内の永続的な異常は、レベルの変化や傾向の変化などのような、イベント ストリーム内の値の分布内で起きる変化です。 Stream Analytics では、このような異常を機械学習をベースにした AnomalyDetection_ChangePoint 演算子を使って検出します。
永続的な変更はスパイクや急落よりもはるかに長く続き、致命的なイベントを示す可能性があります。 永続的な変化は、肉眼では確認できないことがほとんどですが、AnomalyDetection_ChangePoint 演算子を使用して検出できます。
次の画像はレベルの変化の例です。
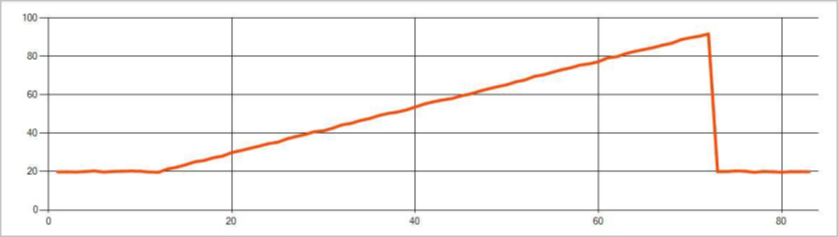
次の画像は傾向の変化の例です。
次のクエリ例では、履歴サイズが 1,200 イベントの 20 分間のスライディング ウィンドウで、1 秒あたり 1 イベントの均一な入力レートを想定しています。 最後の SELECT ステートメントで、80% の信頼度レベルでスコアと異常状態を抽出して出力します。
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_ChangePoint(CAST(temperature AS float), 80, 1200)
OVER(LIMIT DURATION(minute, 20)) AS ChangePointScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(ChangePointScores, 'Score') AS float) AS
ChangePointScore,
CAST(GetRecordPropertyValue(ChangePointScores, 'IsAnomaly') AS bigint) AS
IsChangePointAnomaly
INTO output
FROM AnomalyDetectionStep
パフォーマンス特性
これらのモデルのパフォーマンスは、履歴のサイズ、ウィンドウ期間、イベントの負荷、関数レベルのパーティション分割を使用しているかどうかによります。 このセクションでは、これらの構成について説明し、1 K、5 K、10K のイベントを 1 秒あたりに保持する方法のサンプルを示します。
- 履歴のサイズ - これらのモデルは、履歴のサイズに対して直線性を有します。 履歴のサイズが大きくなるほど、モデルが新しいイベントをスコア付けするためにかかる時間が長くなります。 これは、モデルが新しいイベントを履歴バッファー内の過去の各イベントと比較するためです。
- ウィンドウ期間 - ウィンドウ期間は、履歴のサイズで指定された数のイベントの受信にかかる時間を反映する必要があります。 ウィンドウ内に多くのイベントがない場合、Azure Stream Analytics は欠損値を補完します。 そのため、CPU 使用量は履歴のサイズの関数となります。
- イベント負荷 - イベント負荷が大きいほどモデルの作業量が増え、CPU 使用量に影響を与えます。 ビジネス ロジックで入力パーティションを増やせると仮定すれば、ジョブを驚異的並列にすることでスケール アウトできます。
- 関数レベルのパーティション分割 - 関数レベルのパーティション分割は、異常検出関数呼び出し内で
PARTITION BYを使用して行われます。 この種類のパーティション分割は、同時に複数のモデルで状態を維持する必要があるため、オーバーヘッドが増加します。 関数レベルのパーティション分割は、デバイス レベルのパーティション分割などのシナリオで使用されます。
リレーションシップ
履歴のサイズ、ウィンドウ期間、およびイベント負荷の合計は、次のように関連します。
ウィンドウ期間 (ミリ秒) = 1000 * 履歴のサイズ / (1 秒あたりの入力イベントの合計 / 入力パーティション数)
関数を deviceId でパーティション分割する場合は、異常検出関数呼び出しに「PARTITION BY deviceId」を追加します。
観測値
次の表に、パーティション分割されていないケースの単一ノード (6 SU) のスループットの観測値を示します。
| 履歴のサイズ (イベント) | ウィンドウ期間 (ミリ秒) | 1 秒あたりの入力イベントの合計 |
|---|---|---|
| 60 | 55 | 2,200 |
| 600 | 728 | 1,650 |
| 6,000 | 10,910 | 1,100 |
次の表に、パーティション分割されたケースの単一ノード (6 SU) のスループットの監視を示します。
| 履歴のサイズ (イベント) | ウィンドウ期間 (ミリ秒) | 1 秒あたりの入力イベントの合計 | デバイス数 |
|---|---|---|---|
| 60 | 1,091 | 1,100 | 10 |
| 600 | 10,910 | 1,100 | 10 |
| 6,000 | 218,182 | <550 | 10 |
| 60 | 21,819 | 550 | 100 |
| 600 | 218,182 | 550 | 100 |
| 6,000 | 2,181,819 | <550 | 100 |
上記のパーティション分割されていない構成を実行するサンプル コードは、Azure サンプルの Streaming At Scale リポジトリ にあります。 このコードでは、関数レベルのパーティション分割が行われていないストリーム分析ジョブを作成し、入力および出力として Event Hubs を使用しています。 入力の負荷は、テスト クライアントを使用して生成されます。 各入力イベントは、1 KB (キロバイト) json ドキュメントです。 イベントは、JSON データを送信する IoT デバイスをシミュレートします (最大 1 K デバイス)。 履歴サイズ、ウィンドウ期間、およびイベントの合計負荷は、2 つの入力パーティションで変化します。
Note
見積もりの精度を高めるには、ご使用のシナリオに合わせてサンプルをカスタマイズしてください。
ボトルネックの特定
パイプラインのボトルネックを特定するには、Azure Stream Analytics ジョブの [メトリック] ウィンドウを使用します。 スループットについての [Input/Output Events](入出力イベント) および [透かしの遅延] または [Backlogged Events](バックログされたイベント) を確認して、ジョブが入力速度に対応しているかどうかを確認します。 Event Hubs のメトリックスについては、スロットルされた要求 を検索し、その結果に基づいてしきい値ユニットを調整します。 Azure Cosmos DB メトリックスについては、スループットの下の [パーティション キーの範囲ごとの使用された最大 RU/秒] を確認して、パーティション キーの範囲が均一に消費されていることを確認します。 Azure SQL DB については、 [ログ IO] および [CPU] を監視します。