セッション スコープのパッケージを管理する
プール レベルのパッケージに加えて、セッション スコープのライブラリをノートブック セッションの開始時に指定することもできます。 セッション スコープのライブラリを使うと、ノートブック セッション内で Python、jar、R パッケージを指定して使用できます。
セッション スコープのライブラリを使用する場合は、以下の点に留意することが重要です。
- セッション スコープのライブラリをインストールすると、現在のノートブックだけが、指定されたライブラリにアクセスできます。
- これらのライブラリは、同じ Spark プールを使用する他のセッションまたはジョブには影響しません。
- これらのライブラリは、基本ランタイムおよびプール レベルのライブラリの上にインストールされ、最も優先されます。
- セッション スコープのライブラリは、セッション間で保持されません。
セッションスコープの Python パッケージ
environment.yml ファイルを使用してセッション スコープの Python パッケージを管理する
セッションスコープの Python パッケージを指定するには:
- 選択した Spark プールに移動し、セッション レベルのライブラリが有効になっていることを確認します。 この設定を有効にするには、[管理]>[Apache Spark プール]>[パッケージ] タブに移動します。

- 設定が適用されたら、ノートブックを開いて [セッションの構成]>[パッケージ] を選択できます。

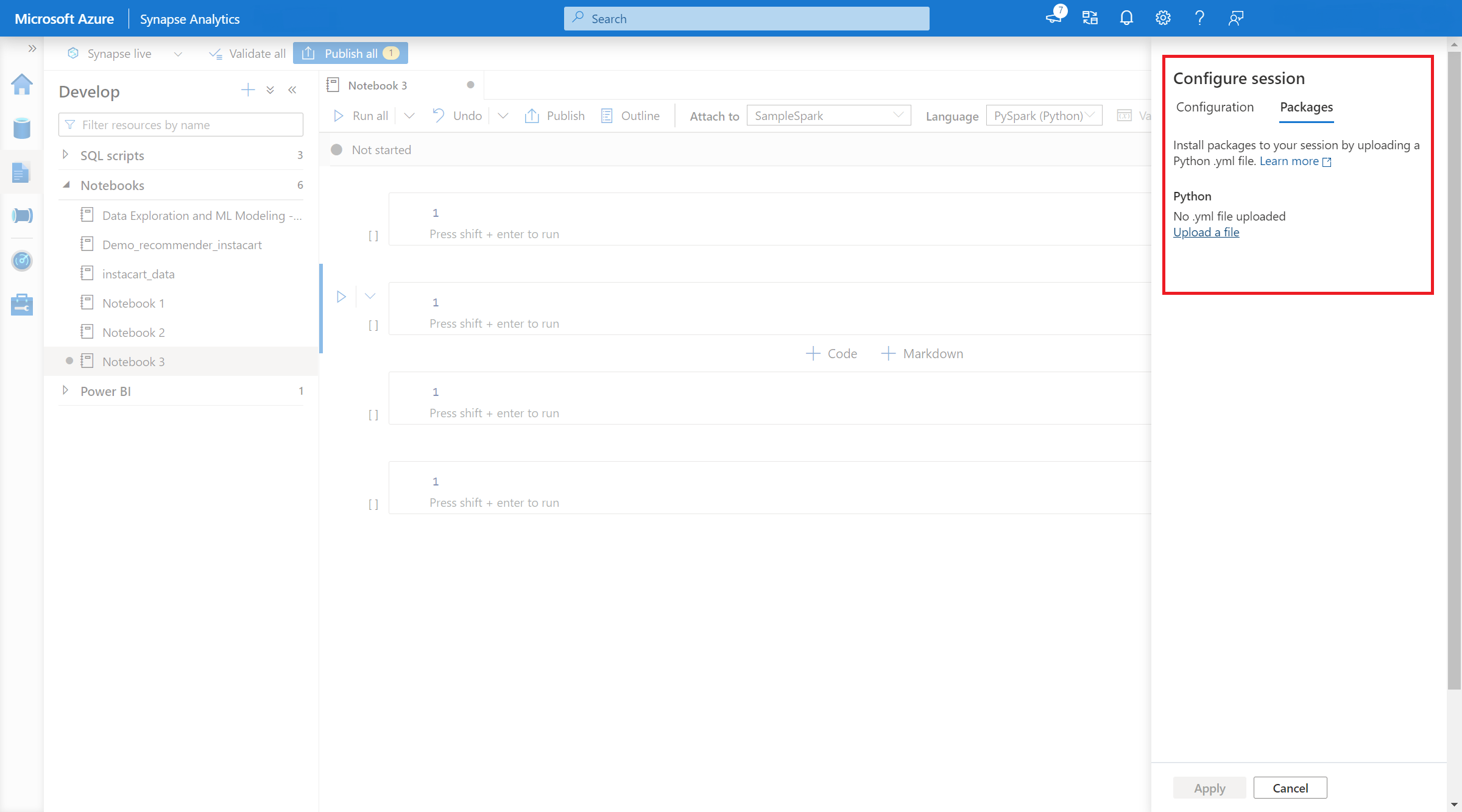
- ここでは、Conda environment.yml ファイルをアップロードして、セッション内でパッケージをインストールまたはアップグレードできます。指定したライブラリは、セッション開始後に利用できるようになります。 セッション終了後はこれらのライブラリを利用できなくなります。

%pip コマンドと %conda コマンドを使用してセッション スコープの Python パッケージを管理する
一般的な %pip コマンドと %conda コマンドを使用して、Apache Spark ノートブック セッション中に追加のサード パーティ製ライブラリまたはカスタム ライブラリをインストールできます。 このセクションでは、%pip コマンドを使用して、いくつかの一般的なシナリオを示します。
Note
- 新しいライブラリをインストールする場合は、ノートブックの最初のセルに %pip および %conda コマンドを配置することをお勧めします。 変更を有効にするために、セッション レベルのライブラリが管理された後、Python インタープリターが再起動されます。
- Python ライブラリを管理するこれらのコマンドは、パイプライン ジョブの実行時に無効になります。 パイプライン内でパッケージをインストールしたい場合は、プール レベルでライブラリ管理機能を利用する必要があります。
- セッション スコープの Python ライブラリは、ドライバーおよびワーカーの両方のノードに自動的にインストールされます。
- %conda コマンド create、clean、compare、activate、deactivate、run、package はサポートされていません。
- コマンドの完全な一覧については、%pip コマンドと %conda コマンドに関するページを参照してください。
サード パーティ製パッケージをインストールする
PyPI から Python ライブラリを簡単にインストールできます。
# Install vega_datasets
%pip install altair vega_datasets
インストール結果を確認するには、次のコードを実行して、vega_datasets を視覚化します。
# Create a scatter plot
# Plot Miles per gallon against the horsepower across different region
import altair as alt
from vega_datasets import data
cars = data.cars()
alt.Chart(cars).mark_point().encode(
x='Horsepower',
y='Miles_per_Gallon',
color='Origin',
).interactive()
ストレージ アカウントからホイール パッケージをインストールする
ストレージからライブラリをインストールするには、次のコマンドを実行してストレージ アカウントにマウントする必要があります。
from notebookutils import mssparkutils
mssparkutils.fs.mount(
"abfss://<<file system>>@<<storage account>.dfs.core.windows.net",
"/<<path to wheel file>>",
{"linkedService":"<<storage name>>"}
)
次に、%pip install コマンドを使用して、必要なホイール パッケージをインストールできます
%pip install /<<path to wheel file>>/<<wheel package name>>.whl
別のバージョンの組み込みライブラリをインストールする
次のコマンドを使用して、特定のパッケージの組み込みバージョンを確認できます。 例として pandas を使用します
%pip show pandas
結果は以下のようなログになります。
Name: pandas
Version: **1.2.3**
Summary: Powerful data structures for data analysis, time series, and statistics
Home-page: https://pandas.pydata.org
... ...
次のコマンドを使用して、pandas を別のバージョン (たとえば 1.2.4) に切り替えることができます。
%pip install pandas==1.2.4
セッション スコープのライブラリをアンインストールする
このノートブック セッションでインストールされたパッケージをアンインストールする場合は、以下のコマンドを参照してください。 ただし、組み込みパッケージをアンインストールすることはできません。
%pip uninstall altair vega_datasets --yes
%pip コマンドを使用して requirement.txt ファイルからライブラリをインストールする
%pip install -r /<<path to requirement file>>/requirements.txt
セッションスコープの Java または Scala パッケージ
セッション スコープの Java または Scala パッケージは、%%configure オプションを使用して指定できます。
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<file system>>@<<storage account>.dfs.core.windows.net/<<path to JAR file>>",
}
}
Note
- %%configure はノートブックの先頭で実行することをお勧めします。 すべての有効なパラメーターの一覧については、このドキュメントを参照してください。
セッション スコープの R パッケージ (プレビュー)
Azure Synapse Analytics プールには、すぐに使える多くの一般的な R ライブラリが用意されています。 Apache Spark ノートブック セッション中に、サード パーティ製ライブラリをさらにインストールすることもできます。
Note
- R ライブラリを管理するこれらのコマンドは、パイプライン ジョブの実行時に無効になります。 パイプライン内でパッケージをインストールしたい場合は、プール レベルでライブラリ管理機能を利用する必要があります。
- セッション スコープの R ライブラリは、ドライバーおよびワーカーの両方のノードに自動的にインストールされます。
パッケージをインストールする
CRAN から R ライブラリを簡単にインストールできます。
# Install a package from CRAN
install.packages(c("nycflights13", "Lahman"))
また、CRAN スナップショットをリポジトリとして利用して、毎回同じパッケージ バージョンが確実にダウンロードされるようにすることもできます。
install.packages("highcharter", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
devtools を使用してパッケージをインストールする
devtools ライブラリを使うと、パッケージの開発が簡単になり、一般的なタスクが効率化されます。 このライブラリは、既定の Azure Synapse Analytics ランタイム内にインストールされます。
devtools を使うと、特定のバージョンのライブラリを指定してインストールできます。 これらのライブラリは、クラスター内のすべてのノードにインストールされます。
# Install a specific version.
install_version("caesar", version = "1.0.0")
同様に、GitHub からライブラリを直接インストールすることもできます。
# Install a GitHub library.
install_github("jtilly/matchingR")
現在、Azure Synapse Analytics 内では次の devtools 関数がサポートされています。
| コマンド | 説明 |
|---|---|
| install_github() | GitHub から R パッケージをインストールします |
| install_gitlab() | GitLab から R パッケージをインストールします |
| install_bitbucket() | BitBucket から R パッケージをインストールします |
| install_url() | 任意の URL から R パッケージをインストールします |
| install_git() | 任意の Git リポジトリからインストールします |
| install_local() | ディスク上のローカル ファイルからインストールします |
| install_version() | CRAN の特定のバージョンからインストールします |
インストールされているライブラリを表示する
library コマンドを使って、セッション内にインストールされているすべてのライブラリを照会できます。
library()
packageVersion 関数を使うと、ライブラリのバージョンを確認できます。
packageVersion("caesar")
セッションから R パッケージを削除する
detach 関数を使って、名前空間からライブラリを削除できます。 これらのライブラリは、再び読み込まれるまでディスク上に残ります。
# detach a library
detach("package: caesar")
ノートブックからセッション スコープのパッケージを削除するには、remove.packages() コマンドを使います。 このライブラリの変更は、同じクラスター上の他のセッションには影響しません。 ユーザーは、既定の Azure Synapse Analytics ランタイムの組み込みライブラリをアンインストールまたは削除することはできません。
remove.packages("caesar")
Note
SparkR、SparklyR、R などのコア パッケージを削除することはできません。
セッション スコープの R ライブラリと SparkR
ノートブック スコープのライブラリは、SparkR ワーカーで利用できます。
install.packages("stringr")
library(SparkR)
str_length_function <- function(x) {
library(stringr)
str_length(x)
}
docs <- c("Wow, I really like the new light sabers!",
"That book was excellent.",
"R is a fantastic language.",
"The service in this restaurant was miserable.",
"This is neither positive or negative.")
spark.lapply(docs, str_length_function)
セッション スコープの R ライブラリと SparklyR
SparklyR の spark_apply() では、Spark 内の任意の R パッケージを使用できます。 既定の sparklyr::spark_apply() では、packages 引数は FALSE に設定されます。 これにより現在の libPaths 内のライブラリがワーカーにコピーされ、それをワーカーにインポートして使用できます。 たとえば、次を実行すると、シーザーで暗号化されたメッセージを sparklyr::spark_apply() で生成できます。
install.packages("caesar", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
spark_version <- "3.2"
config <- spark_config()
sc <- spark_connect(master = "yarn", version = spark_version, spark_home = "/opt/spark", config = config)
apply_cases <- function(x) {
library(caesar)
caesar("hello world")
}
sdf_len(sc, 5) %>%
spark_apply(apply_cases, packages=FALSE)
次のステップ
- 既定のライブラリを確認します: Apache Spark バージョンのサポート
- Synapse Studio ポータルの外部からパッケージを管理します: Az コマンドと REST API を使用したパッケージ管理