チュートリアル:サーバーレス SQL プールを使用してデータ レイクを探索および分析する
このチュートリアルでは、探索的データ分析を実行する方法について説明します。 サーバーレス SQL プールを使用して、さまざまな Azure Open Datasets を組み合わせます。 次に、Azure Synapse Analytics の Synapse Studio で結果を視覚化します。
OPENROWSET(BULK...) 関数を使用すると、Azure Storage 内のファイルにアクセスできます。 [OPENROWSET](develop-openrowset.md) は、リモート データ ソース (ファイルなど) の内容を読み取って行のセットとして返します。
自動スキーマ推論
データは Parquet ファイル形式で格納されるため、自動スキーマ推論を使用できます。 ファイル内のすべての列のデータ型を一覧表示することなく、データに対するクエリを実行できます。 また、仮想列のメカニズムと filepath 関数を利用して、ファイルの特定のサブセットを除外することもできます。
注意
既定の照合順序は SQL_Latin1_General_CP1_CI_ASIf です。 既定以外の照合順序の場合は、大文字と小文字の区別を考慮してください。
列を指定するときに、大文字と小文字を区別する照合順序を使用したデータベースを作成する場合は、列の正しい名前を使用するようにしてください。
列名 tpepPickupDateTime は正しいですが、tpeppickupdatetime は既定以外の照合順序では機能しません。
このチュートリアルでは、 ニューヨーク市 (NYC) タクシーに関するデータセットを使用します。
- 乗車日時と降車日時
- 乗車地点と降車地点
- 移動距離
- 料金明細
- 料金の種類
- 支払いの種類
- 運転手から報告された乗客の人数
NYC のタクシー データについて理解するには、次のクエリを実行します。
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
同様に、次のクエリを使用して、休日のデータセットに対してクエリを実行できます。
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet',
FORMAT='PARQUET'
) AS [holidays]
次のクエリを使用して、気象データのデータセットに対してもクエリを実行できます。
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=*/month=*/*.parquet',
FORMAT='PARQUET'
) AS [weather]
個々の列の意味の詳細については、データ セットの説明を参照してください。
時系列、季節性、および外れ値の分析
次のクエリを使用して、毎年のタクシー乗車数をまとめることができます。
SELECT
YEAR(tpepPickupDateTime) AS current_year,
COUNT(*) AS rides_per_year
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) >= '2009' AND nyc.filepath(1) <= '2019'
GROUP BY YEAR(tpepPickupDateTime)
ORDER BY 1 ASC
毎年のタクシー乗車数の結果を次のスニペットに示します。
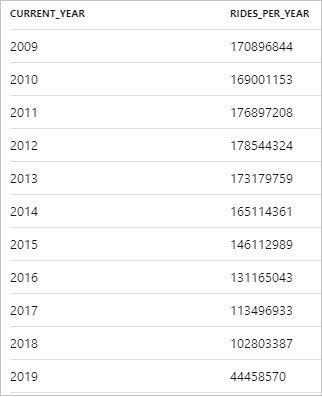
データは Synapse Studio でテーブル ビューからグラフ ビューに切り替えることによって視覚化できます。 さまざまな種類のグラフ ( [面] 、 [横棒] 、 [縦棒] 、 [折れ線] 、 [円] 、 [散布図] など) から選択できます。 この例で、 [Category column](カテゴリ列) を current_year に設定した [縦棒] グラフをプロットしてみましょう。
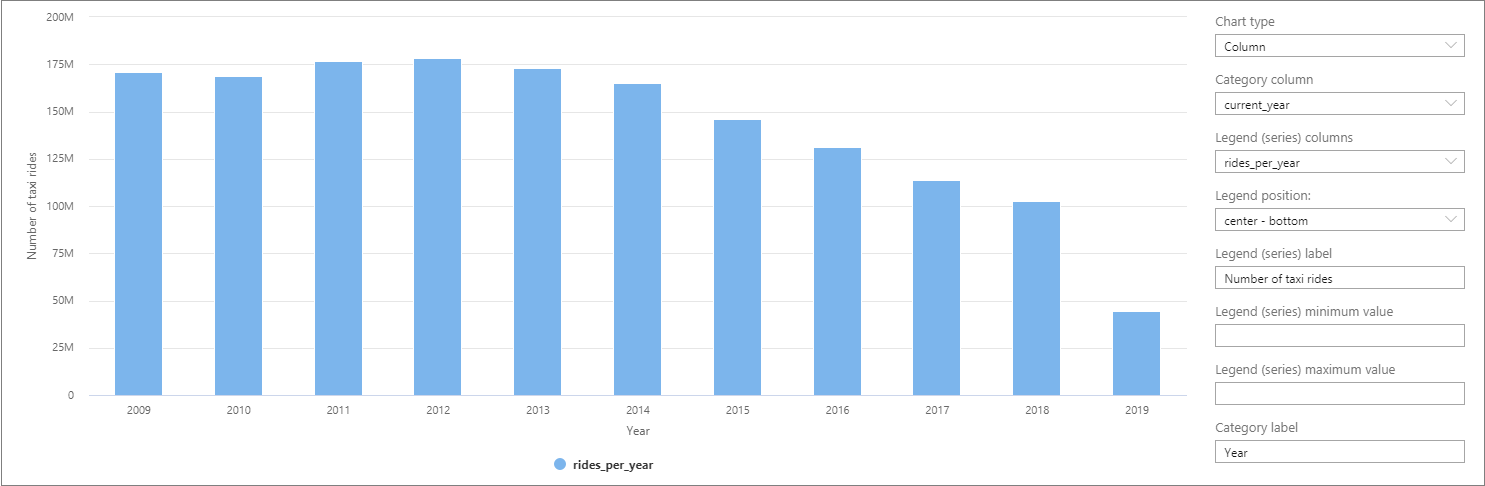
この視覚化から、乗車数が年々減少している傾向が見て取れます。 この減少はおそらく、近年のライドシェア企業の人気の高まりが原因であると思われます。
注意
このチュートリアルの執筆時点では、2019 年のデータは不完全です。 その結果、その年の乗車数が著しく低下しています。
単年度の分析に重点を置くこともできます。たとえば 2016 年に注目します。 次のクエリでは、その年の毎日の乗車数が返されます。
SELECT
CAST([tpepPickupDateTime] AS DATE) AS [current_day],
COUNT(*) as rides_per_day
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) = '2016'
GROUP BY CAST([tpepPickupDateTime] AS DATE)
ORDER BY 1 ASC
このクエリの結果を次のスニペットに示します。
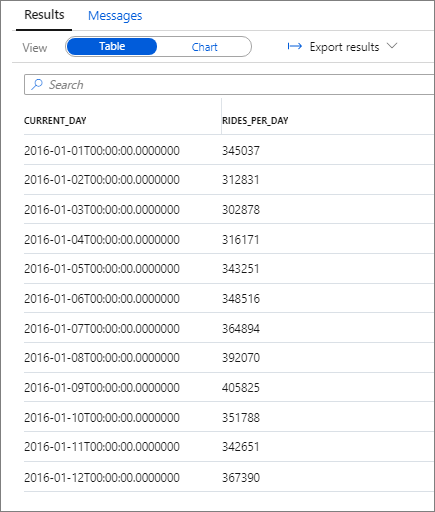
ここでも、[Category] (カテゴリ) 列を current_day に設定し、[Legend (series)] (凡例 (系列)) 列を rides_per_day に設定した [縦棒] グラフをプロットすることで、データを視覚化できます。
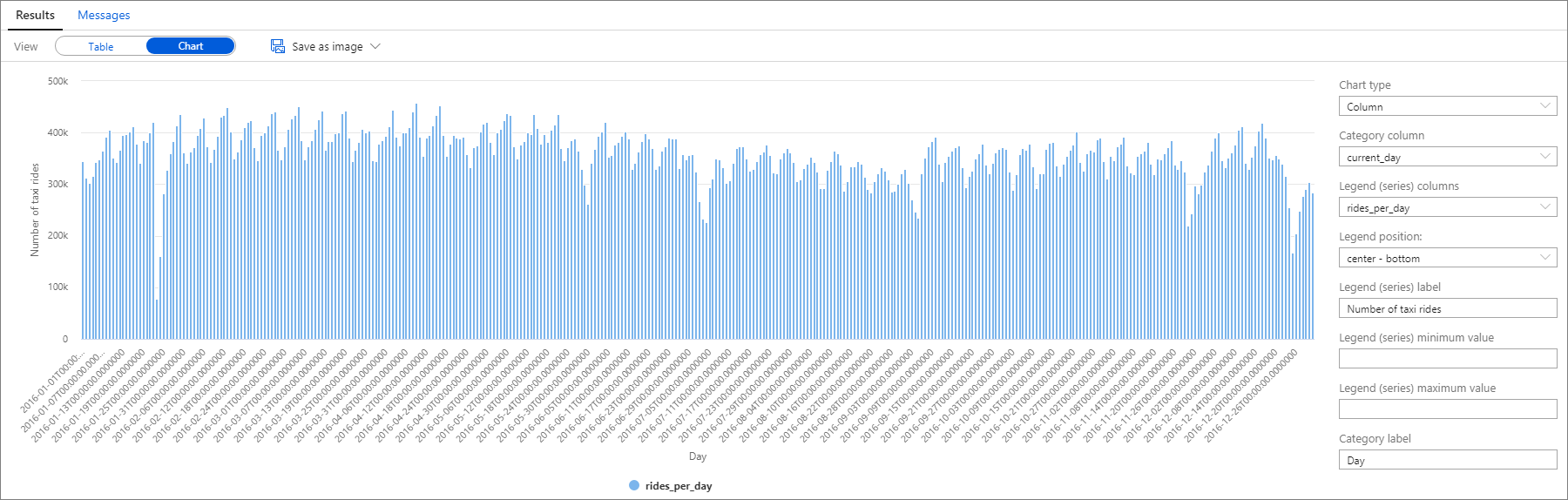
プロット グラフから、土曜日をピーク日とする週単位のパターンがあることが確認できます。 夏期は休暇のため、毎月のタクシー乗車数が減少します。 また、時期および理由の観点から明確なパターンがないのにタクシー乗車数が大幅に減少していることも見て取れます。
次に、乗車数の減少が休日と関連しているかどうかを確認してください。 NYC タクシー乗車数データセットを休日データセットと結合することで、相関関係があるかどうかを確認してください。
WITH taxi_rides AS (
SELECT
CAST([tpepPickupDateTime] AS DATE) AS [current_day],
COUNT(*) as rides_per_day
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) = '2016'
GROUP BY CAST([tpepPickupDateTime] AS DATE)
),
public_holidays AS (
SELECT
holidayname as holiday,
date
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet',
FORMAT='PARQUET'
) AS [holidays]
WHERE countryorregion = 'United States' AND YEAR(date) = 2016
),
joined_data AS (
SELECT
*
FROM taxi_rides t
LEFT OUTER JOIN public_holidays p on t.current_day = p.date
)
SELECT
*,
holiday_rides =
CASE
WHEN holiday is null THEN 0
WHEN holiday is not null THEN rides_per_day
END
FROM joined_data
ORDER BY current_day ASC
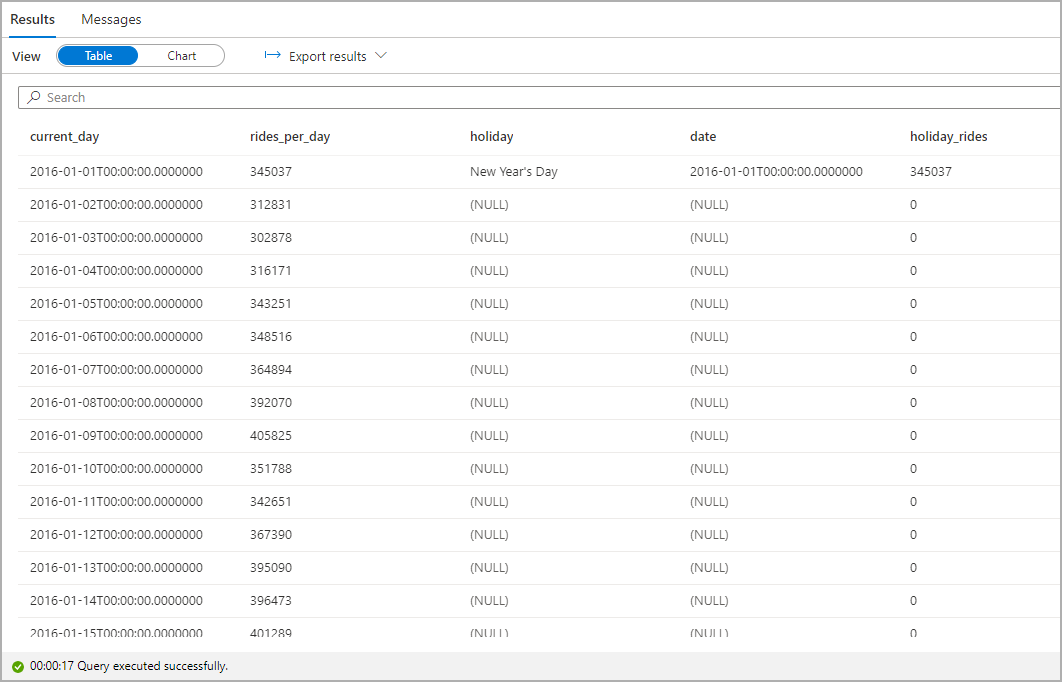
休日のタクシー乗車数を強調表示します。 そのために、カテゴリ列に current_day および凡例 (系列) 列として rides_per_day と holiday_rides を選択します。
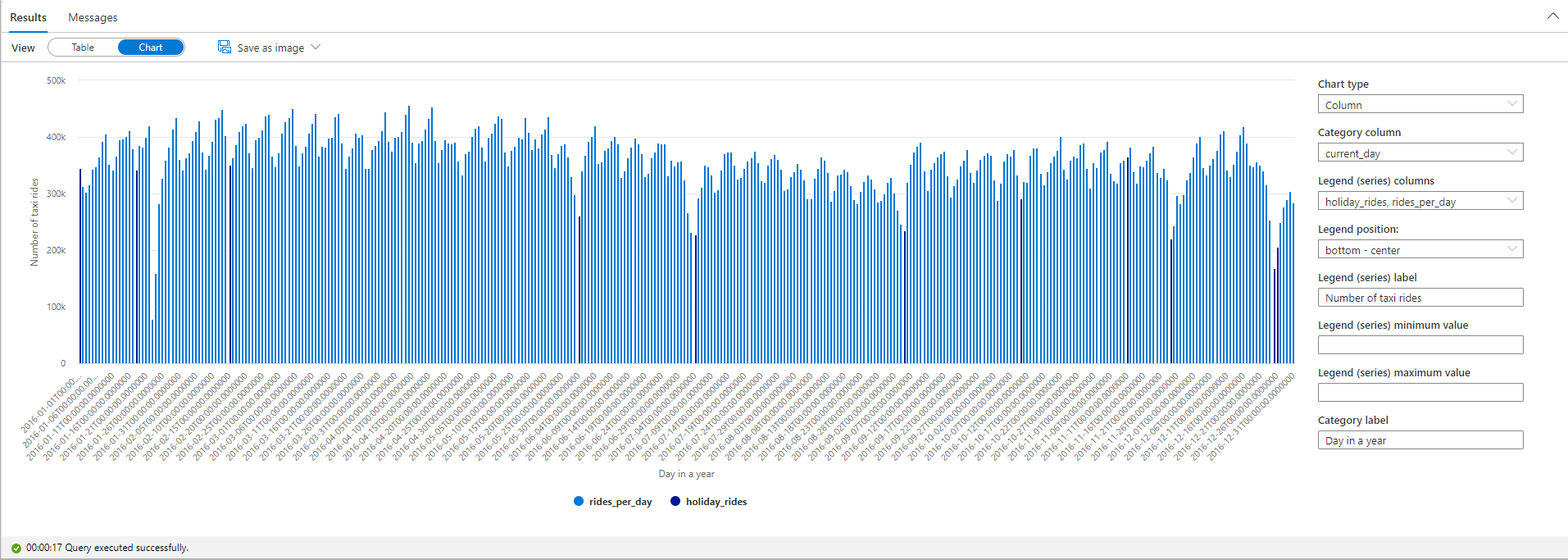
このプロット グラフから、休日はタクシー乗車数が少なくなることがわかります。 1 月 23 日の大幅な減少については、まだ説明がついていません。 では、気象データセットに対してクエリを実行して、その日のニューヨーク市の天気を確認してみましょう。
SELECT
AVG(windspeed) AS avg_windspeed,
MIN(windspeed) AS min_windspeed,
MAX(windspeed) AS max_windspeed,
AVG(temperature) AS avg_temperature,
MIN(temperature) AS min_temperature,
MAX(temperature) AS max_temperature,
AVG(sealvlpressure) AS avg_sealvlpressure,
MIN(sealvlpressure) AS min_sealvlpressure,
MAX(sealvlpressure) AS max_sealvlpressure,
AVG(precipdepth) AS avg_precipdepth,
MIN(precipdepth) AS min_precipdepth,
MAX(precipdepth) AS max_precipdepth,
AVG(snowdepth) AS avg_snowdepth,
MIN(snowdepth) AS min_snowdepth,
MAX(snowdepth) AS max_snowdepth
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=*/month=*/*.parquet',
FORMAT='PARQUET'
) AS [weather]
WHERE countryorregion = 'US' AND CAST([datetime] AS DATE) = '2016-01-23' AND stationname = 'JOHN F KENNEDY INTERNATIONAL AIRPORT'

このクエリの結果から、タクシー乗車数の減少は次のことが原因であることが示されます。
- 当日、ニューヨーク市に吹雪が発生して大雪だった (約 30 cm)。
- 寒かった (気温が摂氏 0 度を下回った)。
- 強風だった (約 10 m/秒)。
このチュートリアルでは、データアナリストが探索的データ分析をすばやく実行する方法について説明しました。 サーバーレス SQL プールを使用してさまざまなデータセットを組み合わせ、Azure Synapse Studio を使用して結果を視覚化できます。
次のステップ
サーバーレス SQL プールを Power BI Desktop に接続してレポートを作成する方法については、サーバーレス SQL プールの Power BI Desktop への接続とレポートの作成に関する記事をご覧ください。
サーバーレス SQL プールで外部テーブルを使用する方法については、「Synapse SQL で外部テーブルを使用する」をご覧ください。