Azure Data Explorer への Time Series Insights (TSI) Gen2 の移行
Note
Time Series Insights (TSI) サービスは、2025 年 3 月以降はサポートされなくなります。 できるだけ早く既存の TSI 環境を代替ソリューションに移行することを検討してください。 サポートの終了と移行の詳細については、こちらのドキュメントを参照してください。
概要
移行に関する推奨事項の概要。
| 機能 | Gen2 の状態 | 推奨される移行 |
|---|---|---|
| フラット化とエスケープを使用したハブからの JSON の取り込み | TSI の取り込み | ADX - OneClick 取り込み / ウィザード |
| コールド ストアを開く | 顧客のストレージ アカウント | ADLS で顧客が指定した外部テーブルへの継続的なデータ エクスポート。 |
| PBI コネクタ | プライベート プレビュー | ADX PBI コネクタを使用します。 TSQ を KQL に手動で書き換えます。 |
| Spark コネクタ | プライベート プレビュー。 テレメトリ データに対してクエリを実行します。 モデル データに対してクエリを実行します。 | ADX にデータを移行します。 テレメトリ データに ADX Spark コネクタを使用し、モデルを JSON にエクスポートして Spark に読み込みます。 KQL でクエリを書き換えます。 |
| 一括アップロード | プライベート プレビュー | ADX OneClick 取り込みと LightIngest を使用します。 必要に応じて、ADX 内でパーティション分割を設定します。 |
| タイム シリーズ モデル | JSON ファイルとしてエクスポートできます。 ADX にインポートして、KQL で結合することができます。 | |
| TSI エクスプローラー | ウォームとコールドの切り替え | ADX ダッシュボード |
| クエリの言語 | 時系列クエリ (TSQ) | KQL でクエリを書き換えます。 TSI の SDK ではなく Kusto のものを使用します。 |
テレメトリの移行
ストレージ アカウントの PT=Time フォルダーを使用して、環境内のすべてのテレメトリのコピーを取得します。 詳細については、「データ ストレージ」を参照してください。
移行手順 1 – テレメトリ データに関する統計情報を取得する
データ
- 環境の概要
- Data Access FQDN の最初の部分の環境 ID を記録します (たとえば、.env.crystal-dev.windows-int.net の d390b0b0-1445-4c0c-8365-68d6382c1c2a)
- [環境の概要] -> [ストレージ構成] -> [ストレージ アカウント]
- Storage Explorer を使用してフォルダーの統計情報を取得します
PT=Timeフォルダーのサイズと BLOB の数を記録します。 一括インポートのプライベート プレビューのお客様の場合は、PT=Importのサイズと BLOB の数も記録します。
移行手順 2 – テレメトリを ADX に移行する
ADX クラスターを作成する
ADX コスト見積りツールを使用して、データ サイズに基づいてクラスター サイズを定義します。
- Event Hubs (または IoT Hub) メトリックから、1 日に取り込まれたデータの量の割合を取得します。 TSI 環境に接続されたストレージ アカウントから、TSI によって使用される BLOB コンテナー内のデータの量を取得します。 この情報は、ご利用の環境に合った ADX クラスターの理想的なサイズを計算するために使用されます。
- Azure Data Explorer のコスト見積もりツールを開き、見つかった情報を既存のフィールドに入力します。 [ワークロードの種類] を [ストレージ最適化] に設定し、アクティブにクエリされたデータの合計量を示す [ホット データ] を設定します。
- すべての情報を指定した後、Azure Data Explorer のコスト見積もりツールによって、クラスターの VM サイズとインスタンスの数が提案されます。 アクティブにクエリされたデータのサイズがホット キャッシュに収まるかどうかを分析します。 例に従い、提案されたインスタンスの数に VM サイズのキャッシュ サイズを乗算します。
- コスト見積もりツールの提案: 9x DS14 + 4 TB (キャッシュ)
- 提案されたホット キャッシュの合計: 36 TB = [9x (インスタンス) x 4 TB (ノードあたりのホット キャッシュ)]
- 考慮すべきその他の要因:
- 環境の拡大: ADX クラスターのサイズを計画する場合は、経時的なデータの増加を考慮してください。
- ハイドレーションとパーティション分割: ADX クラスターでインスタンスの数を定義する場合は、ハイドレーションとパーティション分割を高速化するために、追加のノード (2 から 3 倍) を検討してください。
- コンピューティングの選択の詳細については、「Azure Data Explorer クラスターに適したコンピューティング SKU を選択する」を参照してください。
クラスターおよびデータの取り込みを最適に監視するには、診断設定を有効にし、Log Analytics ワークスペースにデータを送信する必要があります。
Azure Data Explorer ブレードで、[監視] | [診断設定] に移動し、[診断設定を追加する] をクリックします
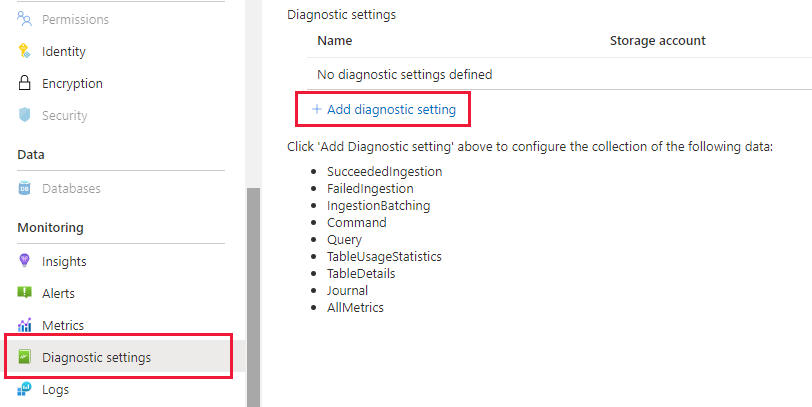
次のように入力します
- 診断設定の名前: この構成の表示名
- ログ: 少なくとも [SucceededIngestion]、[FailedIngestion]、[IngestionBatching] を選択します
- データを送信する Log Analytics ワークスペースを選択します (ない場合は、この手順の前にプロビジョニングする必要があります)
データのパーティション分割。
- ほとんどのデータ セットの場合は、既定の ADX パーティション分割で十分です。
- データのパーティション分割は、特定の限られたシナリオのセットで有益であり、それ以外の場合は適用しないでください。
- ほとんどのクエリでカーディナリティの高い文字列列 (時系列 ID など) をフィルター処理するビッグ データ セットのクエリ待機時間を改善します。
- 順序の異なったデータを取り込む場合 (たとえば、過去のイベントが配信元での生成の数日または数週間後に取り込まれる可能性がある場合など)。
- 詳細については、「ADX データ パーティション分割のポリシー」を参照してください。


データ取り込みの準備
「 https://dataexplorer.azure.com 」を参照してください。
[データ] タブに移動し、[BLOB コンテナーからの取り込み] を選択します

[クラスター] と [データベース] を選択し、TSI データ用に選択した名前で新しいテーブルを作成します
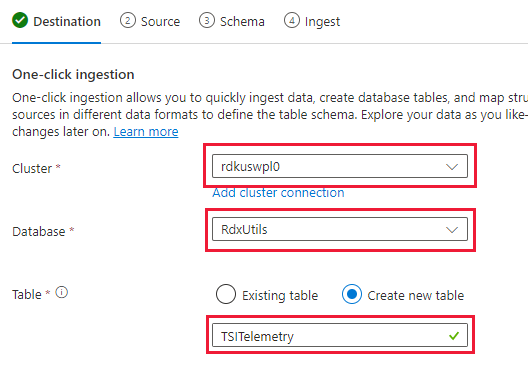
[Next: Source]\(次へ: ソース\) を選択します。
[ソース] タブで、次のように選択します。
- 履歴データ
- [コンテナーの選択]
- TSI データのサブスクリプションおよびストレージ アカウントを選びます
- TSI 環境に関連付けるコンテナーを選びます
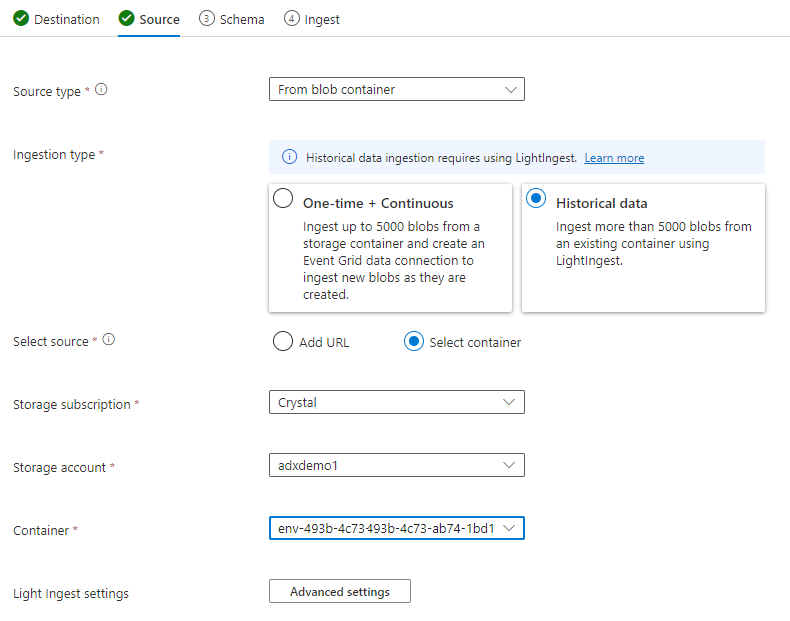
[詳細設定] を選択します
- 作成時刻パターン: '/'yyyyMMddHHmmssfff'_'
- BLOB 名パターン: *.parquet
- [取り込みが完了するまで待機しない] を選択します
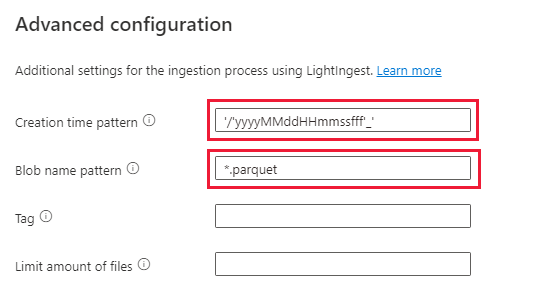
[ファイル フィルター] で、フォルダー パス
V=1/PT=Timeを追加します
[次へ: スキーマ] を選択します
Note
TSI では、Parquet ファイルの列を永続化するときに、一部のフラット化とエスケープが適用されます。 詳細については、フラット化とエスケープの規則および取り込み規則の更新に関するリンクを参照してください。






スキーマが不明または変化する場合
少なくともタイムスタンプおよび TSID 列を残して、クエリ頻度が低いすべての列を削除します。
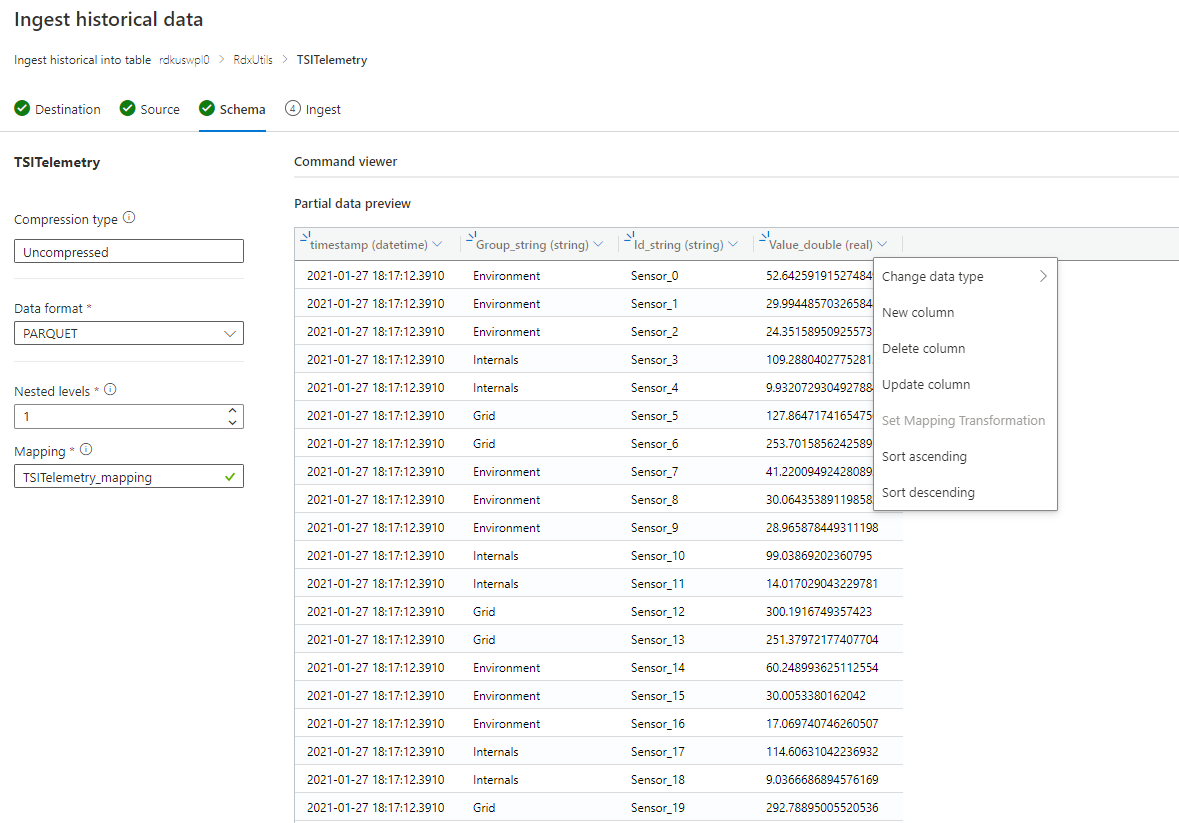
動的な型の新しい列を追加し、$ パスを使用してレコード全体にマップします。
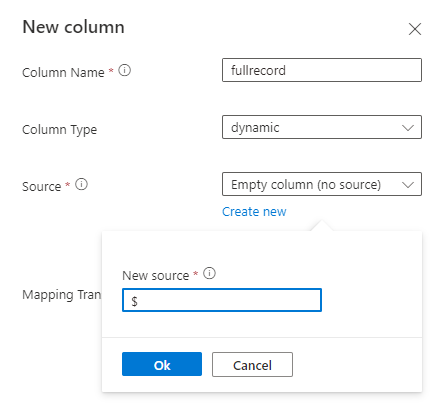
例:
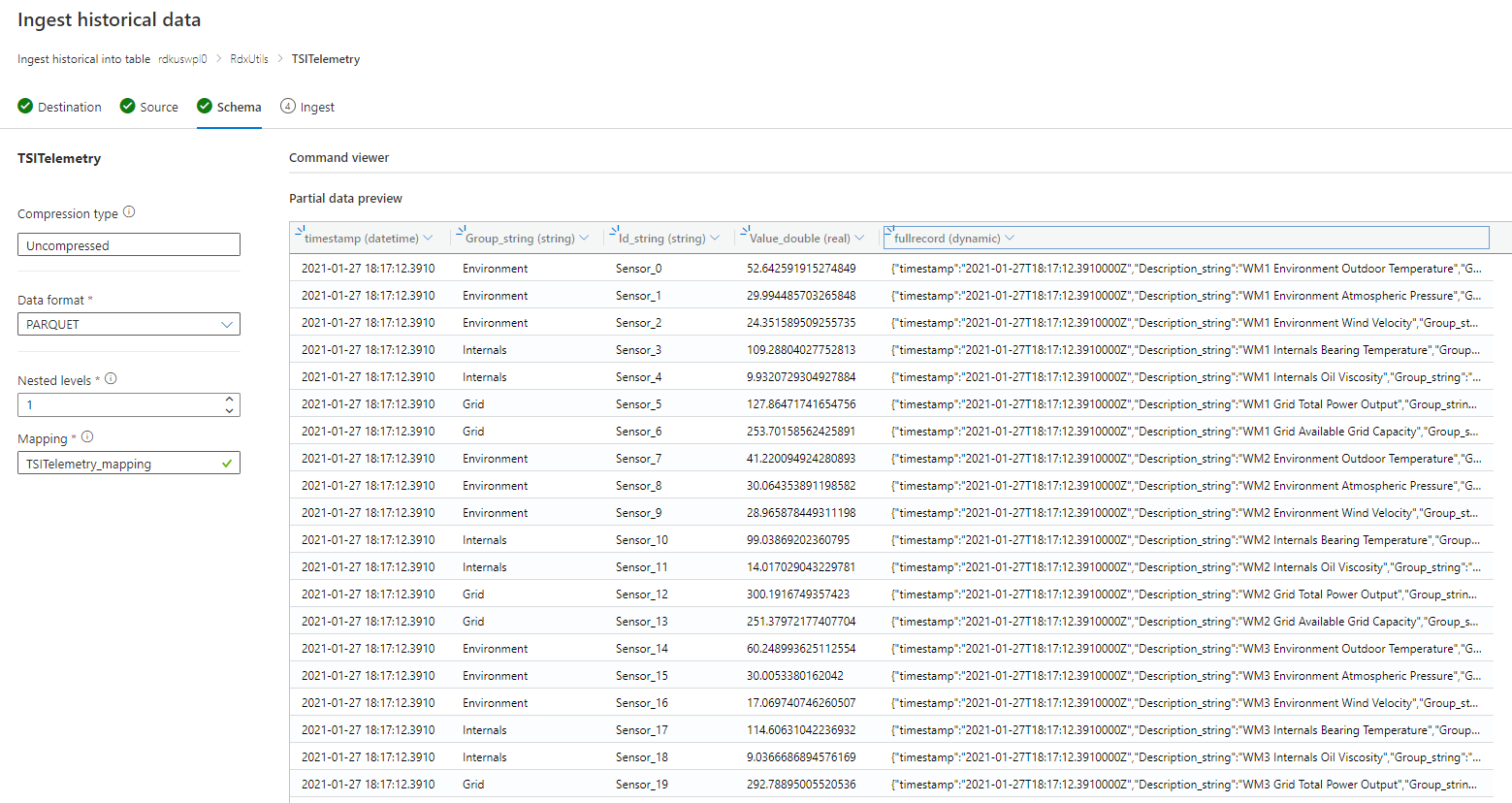
スキーマが既知または固定されている場合
- データが正しいことを確認します。 必要に応じて、任意の型を修正します。
- [次へ: 概要] を選択します



LightIngest コマンドをコピーし、次の手順で使用できるようにどこかに格納します。

データの取り込み
データを取り込む前に、LightIngest ツールをインストールする必要があります。 One-Click ツールから生成されるコマンドには SAS トークンが含まれています。 有効期限を制御できるように、新しいものを生成することをお勧めします。 ポータルで、TSI 環境の BLOB コンテナーに移動し、[共有アクセス トークン] を選択します

Note
大規模な取り込みを開始する前に、クラスターをスケールアップすることもお勧めします。 たとえば、8 つ以上のインスタンスがある D14 や D32 です。
次のように設定します
- 権限: 読み取りおよび一覧表示
- 有効期限: データの移行を完了するのに十分な期間に設定します
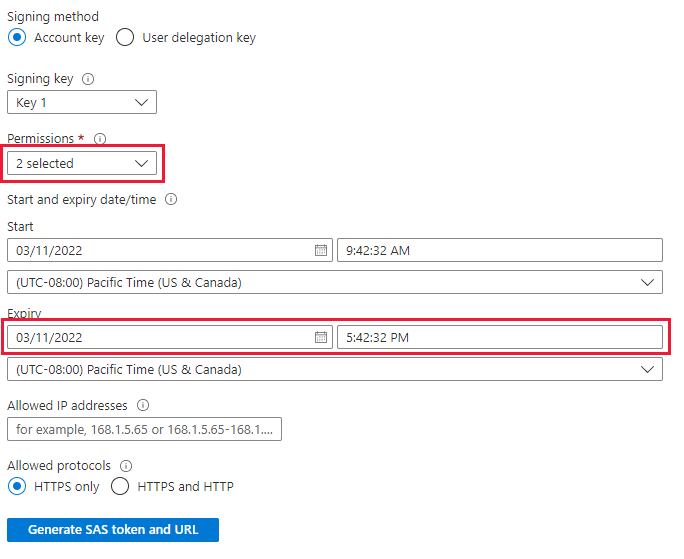
[SAS トークンおよび URL を生成] を選択し、[BLOB SAS URL] をコピーします

先ほどコピーした LightIngest コマンドに移動します。 コマンドの -source パラメーターをこの [SAS BLOB URL] に置き換えます
オプション 1: すべてのデータを取り込む。 より小規模な環境の場合は、1 つのコマンドを使用してすべてのデータを取り込むことができまう。
- コマンド プロンプトを開き、LightIngest ツールが展開されたディレクトリに移動します。 そこに、LightIngest コマンドを貼り付け、実行します。

オプション 2: 年または月別にデータを取り込む。 より大規模な環境の場合、またはより小規模なデータ セットでテストする場合は、さらに Lightingest コマンドをフィルター処理できます。
年別: -prefix パラメーターを変更します
- 変更前:
-prefix:"V=1/PT=Time" - 変更後:
-prefix:"V=1/PT=Time/Y=<Year>" - 例:
-prefix:"V=1/PT=Time/Y=2021"
- 変更前:
月別: -prefix パラメーターを変更します
- 変更前:
-prefix:"V=1/PT=Time" - 変更後:
-prefix:"V=1/PT=Time/Y=<Year>/M=<month #>" - 例:
-prefix:"V=1/PT=Time/Y=2021/M=03"
- 変更前:



コマンドを変更したら、上記のように実行します。 取り込みが完了したら (以下の監視オプションを使用)、取り込む次の年と月のコマンドを変更します。
取り込みの監視
LightIngest コマンドには -dontWait フラグが含まれているので、コマンド自体は取り込みが完了するまで待機しません。 発生中に進行状況を監視する最善の方法は、ポータル内の [分析情報] タブを利用することです。 ポータル内の Azure Data Explorer クラスターのセクションを開き、[監視] | [分析情報] に移動します

以下の設定で [取り込み (プレビュー)] セクションを使用して、発生している取り込みを監視できます
- 時間の範囲: 過去 30 分
- [成功] と [テーブル別] を確認します
- エラーが発生した場合は、[失敗] と [テーブル別] を確認します
テーブルのメトリックが 0 になると、取り込みが完了するのがわかります。 詳細を表示する場合は、Log Analytics を使用できます。 Azure Data Explorer クラスター セクションで、[ログ] タブを選択します。

便利なクエリ
動的スキーマが使用される場合のスキーマについて理解します
| project p=treepath(fullrecord)
| mv-expand p
| summarize by tostring(p)
配列内の値へのアクセス
| where id_string == "a"
| summarize avg(todouble(fullrecord.['nestedArray_v_double'])) by bin(timestamp, 1s)
| render timechart
Azure Data Explorer への時系列モデル (TSM) の移行
モデルは、TSI Explorer UX または TSM Batch API を使用して、TSI 環境から JSON 形式でダウンロードできます。 その後、モデルを別のシステム (Azure Data Explorer など) にインポートできます。
TSI UX から TSM をダウンロードします。
VSCode または別のエディターを使用して、最初の 3 行を削除します。
VSCode または別のエディターを使用して、正規表現として
\},\n \{を検索して}{に置き換えます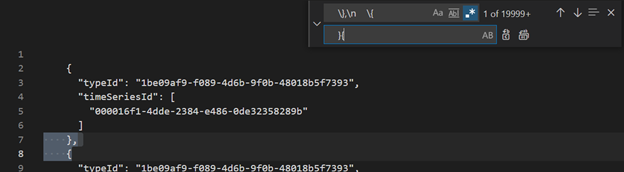
ファイルからアップロード機能を使用して、別のテーブルとして ADX に JSON として取り込みます。



時系列クエリ (TSQ) を KQL に変換する
GetEvents
{
"getEvents": {
"timeSeriesId": [
"assest1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"inlineVariables": {},
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where assetId_string == "assest1" and siteId_string == "siteId1" and dataid_string == "dataId1"
| take 10000
フィルターを使用した GetEvents
{
"getEvents": {
"timeSeriesId": [
"deviceId1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"filter": {
"tsx": "$event.sensors.sensor.String = 'status' AND $event.sensors.unit.String = 'ONLINE"
}
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where deviceId_string== "deviceId1" and siteId_string == "siteId1" and dataId_string == "dataId1"
| where ['sensors.sensor_string'] == "status" and ['sensors.unit_string'] == "ONLINE"
| take 10000
予測変数を使用した GetEvents
{
"getEvents": {
"timeSeriesId": [
"deviceId1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"inlineVariables": {},
"projectedVariables": [],
"projectedProperties": [
{
"name": "sensors.value",
"type": "String"
},
{
"name": "sensors.value",
"type": "bool"
},
{
"name": "sensors.value",
"type": "Double"
}
]
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where deviceId_string== "deviceId1" and siteId_string == "siteId1" and dataId_string == "dataId1"
| take 10000
| project timestamp, sensorStringValue= ['sensors.value_string'], sensorBoolValue= ['sensors.value_bool'], sensorDoublelValue= ['sensors.value_double']
AggregateSeries
{
"aggregateSeries": {
"timeSeriesId": [
"deviceId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:00.0000000Z",
"to": "2021-11-05T00:00:00.0000000Z"
},
"interval": "PT1M",
"inlineVariables": {
"sensor": {
"kind": "numeric",
"value": {
"tsx": "coalesce($event.sensors.value.Double, todouble($event.sensors.value.Long))"
},
"aggregation": {
"tsx": "avg($value)"
}
}
},
"projectedVariables": [
"sensor"
]
}
events
| where timestamp >= datetime(2021-11-01T00:00:00.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.0000000Z)
| where deviceId_string == "deviceId1"
| summarize avgSensorValue= avg(coalesce(['sensors.value_double'], todouble(['sensors.value_long']))) by bin(IntervalTs = timestamp, 1m)
| project IntervalTs, avgSensorValue
フィルターを使用した AggregateSeries
{
"aggregateSeries": {
"timeSeriesId": [
"deviceId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:00.0000000Z",
"to": "2021-11-05T00:00:00.0000000Z"
},
"filter": {
"tsx": "$event.sensors.sensor.String = 'heater' AND $event.sensors.location.String = 'floor1room12'"
},
"interval": "PT1M",
"inlineVariables": {
"sensor": {
"kind": "numeric",
"value": {
"tsx": "coalesce($event.sensors.value.Double, todouble($event.sensors.value.Long))"
},
"aggregation": {
"tsx": "avg($value)"
}
}
},
"projectedVariables": [
"sensor"
]
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:00.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.0000000Z)
| where deviceId_string == "deviceId1"
| where ['sensors.sensor_string'] == "heater" and ['sensors.location_string'] == "floor1room12"
| summarize avgSensorValue= avg(coalesce(['sensors.value_double'], todouble(['sensors.value_long']))) by bin(IntervalTs = timestamp, 1m)
| project IntervalTs, avgSensorValue
TSI Power BI コネクタから ADX Power BI コネクタへの移行
この移行に関連する手動の手順は次のとおりです
- Power BI クエリを TSQ に変換します
- TSQ を KQL Power BI クエリに変換してから TSQ に変換します。TSI UX エクスプローラーからコピーされた Power BI クエリは以下のようになります
生データ (GetEvents API) の場合
{"storeType":"ColdStore","isSearchSpanRelative":false,"clientDataType":"RDX_20200713_Q","environmentFqdn":"6988946f-2b5c-4f84-9921-530501fbab45.env.timeseries.azure.com", "queries":[{"getEvents":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"take":250000}}]}
- TSQ に変換するには、上記のペイロードから JSON をビルドします。 GetEvents API のドキュメントには、理解を深めるための例も含まれています。 クエリ - 実行 - REST API (Azure Time Series Insights) | Microsoft Docs
- 変換された TSQ は以下のようになります。 これは "queries" 内の JSON ペイロードです
{
"getEvents": {
"timeSeriesId": [
"Arctic Ocean",
"null"
],
"searchSpan": {
"from": "2019-10-31T23:59:39.590Z",
"to": "2019-11-01T05:22:18.926Z"
},
"take": 250000
}
}
集約データ (Aggregate Series API) の場合
- 単一インライン変数の場合、TSI UX エクスプローラーからの PowerBI クエリは以下のようになります。
{"storeType":"ColdStore","isSearchSpanRelative":false,"clientDataType":"RDX_20200713_Q","environmentFqdn":"6988946f-2b5c-4f84-9921-530501fbab45.env.timeseries.azure.com", "queries":[{"aggregateSeries":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"interval":"PT1M", "inlineVariables":{"EventCount":{"kind":"aggregate","aggregation":{"tsx":"count()"}}},"projectedVariables":["EventCount"]}}]}
- TSQ に変換するには、上記のペイロードから JSON をビルドします。 AggregateSeries API のドキュメントには、理解を深めるための例も含まれています。 クエリ - 実行 - REST API (Azure Time Series Insights) | Microsoft Docs
- 変換された TSQ は以下のようになります。 これは "queries" 内の JSON ペイロードです
{
"aggregateSeries": {
"timeSeriesId": [
"Arctic Ocean",
"null"
],
"searchSpan": {
"from": "2019-10-31T23:59:39.590Z",
"to": "2019-11-01T05:22:18.926Z"
},
"interval": "PT1M",
"inlineVariables": {
"EventCount": {
"kind": "aggregate",
"aggregation": {
"tsx": "count()"
}
}
},
"projectedVariables": [
"EventCount",
]
}
}
- 複数のインライン変数の場合は、以下の例に示すように、json を "inlineVariables" に追加します。 複数のインライン変数に対する Power BI クエリは次のようになります。
{"storeType":"ColdStore","isSearchSpanRelative":false,"clientDataType":"RDX_20200713_Q","environmentFqdn":"6988946f-2b5c-4f84-9921-530501fbab45.env.timeseries.azure.com","queries":[{"aggregateSeries":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"interval":"PT1M", "inlineVariables":{"EventCount":{"kind":"aggregate","aggregation":{"tsx":"count()"}}},"projectedVariables":["EventCount"]}}, {"aggregateSeries":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"interval":"PT1M", "inlineVariables":{"Magnitude":{"kind":"numeric","value":{"tsx":"$event['mag'].Double"},"aggregation":{"tsx":"max($value)"}}},"projectedVariables":["Magnitude"]}}]}
{
"aggregateSeries": {
"timeSeriesId": [
"Arctic Ocean",
"null"
],
"searchSpan": {
"from": "2019-10-31T23:59:39.590Z",
"to": "2019-11-01T05:22:18.926Z"
},
"interval": "PT1M",
"inlineVariables": {
"EventCount": {
"kind": "aggregate",
"aggregation": {
"tsx": "count()"
}
},
"Magnitude": {
"kind": "numeric",
"value": {
"tsx": "$event['mag'].Double"
},
"aggregation": {
"tsx": "max($value)"
}
}
},
"projectedVariables": [
"EventCount",
"Magnitude",
]
}
}
- 最新のデータに対してクエリを実行する場合 ("isSearchSpanRelative": true) は、以下に示すように searchSpan を手動で計算します
- Power BI ペイロードの "from" と "to" の差を確認します。 その差を "D" と呼びましょう。ここで、"D" は "from" - "to" です
- 現在のタイムスタンプ ("T") を取得し、最初の手順で取得した差を減算します。 これが、searchSpan の新しい "from" (F) となります。ここで、"F" は "T" - "D" です
- これで、手順 2 で取得した新しい "from" は "F" で、新しい "to" は "T" (現在のタイムスタンプ) となります