1 つの Azure リージョン内での SAP HANA の可用性
この記事では、1 つの Azure リージョン内での SAP HANA の複数の可用性シナリオについて説明します。 Azure には多くのリージョンがあり、世界中に分散しています。 Azure リージョンの一覧については、「Azure リージョン」をご覧ください。 1 つの Azure リージョン内の VM に SAP HANA をデプロイする場合は、Microsoft から単一の VM と HANA インスタンスのデプロイが提供されています。 可用性を高める場合は、FD=1 のフレキシブル スケール セット、可用性ゾーン、または可用性のために HANA システム レプリケーションを使用する可用性セットを使用して、2 つの HANA インスタンスと 2 つの VM をデプロイできます。
可用性ゾーンを提供する Azure リージョンは、複数のデータ センターで構成され、それぞれに独自の電源、冷却、ネットワーク インフラストラクチャがあります。 単一の Azure リージョン内で異なるゾーンを提供する目的は、使用可能な 2 つまたは 3 つの可用性ゾーンにアプリケーションをデプロイできるようにするためです。 アプリケーションのデプロイをゾーン間で分散することで、特定の Azure 可用性ゾーン インフラストラクチャに影響する電源またはネットワークの問題が発生しても、Azure リージョン内のアプリケーションの機能が完全に中断されることを防ぐことができます。 あるゾーンの VM が失われる可能性があるなど、容量が少なくなる場合もありますが、残りのゾーン内の VM は中断することなく動作し続けます。 異なるゾーンにまたがる別々の VM に 2 つの HANA インスタンスを設定する場合は、FD=1 のフレキシブル スケール セットまたは可用性ゾーンのデプロイ オプションを使用して VM をデプロイするオプションがあります。
リージョン内の可用性を高める場合は、可用性セットを使用して、2 つの HANA インスタンスと 2 つの VM をデプロイすることを推奨します。 Azure 可用性セットは、論理グループ作成機能であり、この機能によって、可用性セット内に構成された VM リソースは、Azure データセンター内にデプロイされるときに、確実に互いに障害分離されます。 Azure では、可用性セット内に配置された VM は、複数の物理サーバー、コンピューティング ラック、ストレージ ユニット、およびネットワーク スイッチ間で実行されます。 一部の Azure ドキュメントでは、この構成を異なる更新ドメインと障害ドメインへの配置と呼んでいます。 通常は、1 つの Azure データ センター内に配置されます。 アプリケーションがデプロイされているデータ センターが電源やネットワークの問題の影響を受けた場合、1 つの Azure リージョン内のすべての容量が影響を受けます。
Azure Availability Zones を構成するデータ センターの配置は、異なるゾーンにデプロイされたサービス間の許容できるネットワーク待機時間と、データ センター間の距離を比較検討して決定されます。 理想は、自然災害によって、1 つのリージョン内のすべての Availability Zones の電源、ネットワーク、インフラストラクチャが影響を受けないことです。 ただし、非常に大きな自然災害が発生した場合、Availability Zones は、1 つのリージョン内で必要とする可用性を必ずしも提供できない可能性があります。 2017 年 9 月 20 日にプエルトリコ島に上陸したハリケーン Maria を考えてみてください。 ハリケーンによって、幅 90 マイルの島でほぼ 100% の停電が発生しました。
単一の VM のシナリオ
単一の VM のシナリオでは、SAP HANA インスタンス用に Azure VM を作成します。 Azure Premium Storage を使って、オペレーティング システム ディスクとすべてのデータ ディスクをホストします。 Azure の稼働時間 99.9% の SLA と他の Azure コンポーネントの SLA は、顧客の可用性 SLA を満たすのに十分です。 このシナリオでは、DBMS レイヤーを実行する VM 用に Azure 可用性セットを使用する必要はありません。 このシナリオでは、次の 2 つの異なる機能を使用します。
- Azure VM 自動再起動 (Azure サービス復旧と呼ぶこともあります)
- SAP HANA 自動再起動
Azure VM 自動再起動または "サービス復旧" は、次の 2 つのレベルで動作する Azure の機能です。
- Azure サーバー ホストが、サーバー ホストでホストされている VM の正常性を確認する。
- Azure ファブリック コントローラーが、サーバー ホストの正常性と可用性を監視する。
正常性チェック機能が、Azure サーバー ホストでホストされているすべての VM の正常性を監視します。 VM で異常が発生すると、VM の正常性をチェックする Azure ホスト エージェントが VM の再起動を開始できます。 ファブリック コントローラーは、ホスト ハードウェアの問題を示すことができる多数のさまざまなパラメーターをチェックして、ホストの正常性を確認します。 また、ネットワーク経由でホストのアクセシビリティも確認します。 ホストに問題があると、次のようなイベントが発生する可能性があります。
- ホストが異常を示した場合、ホストの再起動と、ホスト上で実行されている VM の再起動がトリガーされます。
- 再起動の成功後にホストが正常な状態ではない場合は、現在異常なノード上にもともとあった VM の正常なホスト サーバーへの再デプロイが開始されます。 この場合、元のホストは異常とマークされます。 クリアされるか交換されるまで、それ以上デプロイに使われることはありません。
- 再起動プロセス中に異常なホストに問題がある場合は、正常なホストでの VM の再起動がすぐにトリガーされます。
Azure によって提供されるホストと VM の監視により、ホストの問題が発生している Azure VM は正常な Azure ホストで自動的に再起動します。
重要
Azure サービスの復旧では、ゲスト OS がカーネル パニック状態にある Linux VM の再起動は行いません。 Linux のリリースで一般的に使用される既定の設定は、Linux カーネルがパニック状態にある場合、VMまたはサーバーを自動的に再起動しないことです。 既定の設定は、OS をカーネル パニック状態のままにして、カーネル デバッガーをアタッチして分析できるようにすることを期待しています。 Azure では、その動作を実行できるように、ゲスト OS がそのような状態にある場合は、VM の自動的な再起動を行いません。 前提は、そのような状態が発生することは非常にまれであるということです。 この既定の動作を上書きして、VM の再起動を有効にできます。 既定の動作を変更するには、/etc/sysctl.conf 内の 'kernel.panic' パラメーターを有効にします。 このパラメーターに対して設定する時間は秒単位です。 一般的な推奨値は、このパラメーターを通して再起動をトリガーする前に 20 秒から 30 秒間待機することです。 詳細については、sysctl.conf を参照してください。
このようなシナリオで使用する 2 番目の機能では、再起動された VM で実行される HANA サービスが、VM の再起動後に自動的に開始されます。 HANA サービスの自動再起動は、さまざまな HANA サービスのウォッチドッグ サービス経由で設定できます。
この単一 VM のシナリオは、SAP HANA 構成にコールド フェールオーバー ノードを追加することで、改善できます。 SAP HANA のドキュメントでは、この設定はホスト自動フェールオーバーと呼ばれています。 この構成は、サーバー ハードウェアが制限され、一連の運用ホストに対するホスト自動フェールオーバー ノードとして 1 つのサーバー ノードを専用に使う、オンプレミス デプロイの場合に有効です。 ただし、Azure の基盤インフラストラクチャが VM の正常な再起動用に正常なターゲット サーバーを提供する場合には、Azure では、SAP HANA ホスト自動フェールオーバーのデプロイは有効ではありません。 Azure サービスの復旧では、HANA ホスト自動フェールオーバー用のスタンバイ ノードが用意される参照アーキテクチャは存在しません。
Azure での SAP HANA スケール アウト構成の特殊なケース
スタンバイ ノードまたは HANA システム レプリケーションに基づく高可用性アーキテクチャについては、次のドキュメントを参照してください。 SAP HANA スケールアウト構成でスタンバイ ノードまたは HANA システム レプリケーションの高可用性を使用しない場合は、Azure VM のサービス復旧機能と、VM が再び運用可能になった後の SAP HANA インスタンスの自動再起動に依存できます。
- RedHat Enterprise Linux
- SUSE Linux Enterprise Server
2 つの異なる VM の可用性シナリオ
特定のリージョン内での HANA システムの可用性を確保するには、2 つの VM をリージョンの可用性ゾーンにまたがって構成する、もしくはリージョン内で構成するオプションがあります。 この可用性の確保を実現するために、フレキシブル スケール セット、可用性ゾーン、または可用性セットのデプロイ オプションを使用して VM を構成できます。 Azure の基本設定は、次のようになります。
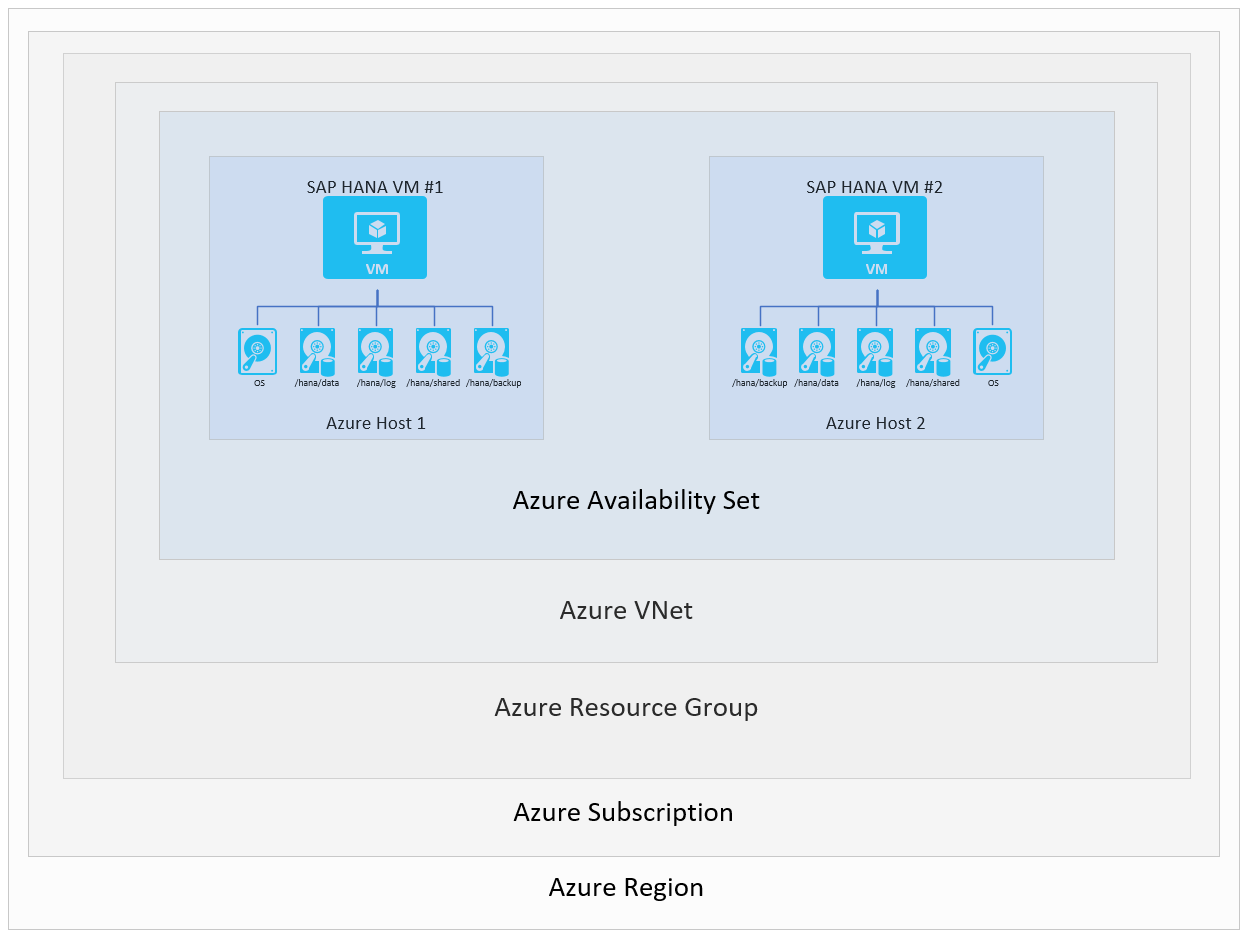
異なる SAP HANA の可用性シナリオを示すため、図のレイヤーのいくつかは省略されています。 図は、VM、ホスト、可用性セット、および Azure リージョンを表現しているレイヤーのみを示しています。 Azure Virtual Network インスタンス、リソース グループ、およびサブスクリプションは、このセクションで説明されるシナリオでは、役割を担いません。
第 2 の仮想マシンへのバックアップのレプリケート
最も基本的な設定の 1 つは、バックアップの使用です。 特に、1 つの VM から別の Azure VM へ配信されるトランザクション ログのバックアップを保持することができます。 Azure Storage タイプは、選択可能です。 この設定では、第 1 の VM で行われた第 2 の VM に対するスケジュール バックアップのコピーのスクリプト作成を行う必要があります。 第 2 の VM インスタンスを使用する必要がある場合は、必ず完全、増分/差分、およびトランザクション ログのバックアップを必要な時点に復元します。
アーキテクチャは次のようになります。
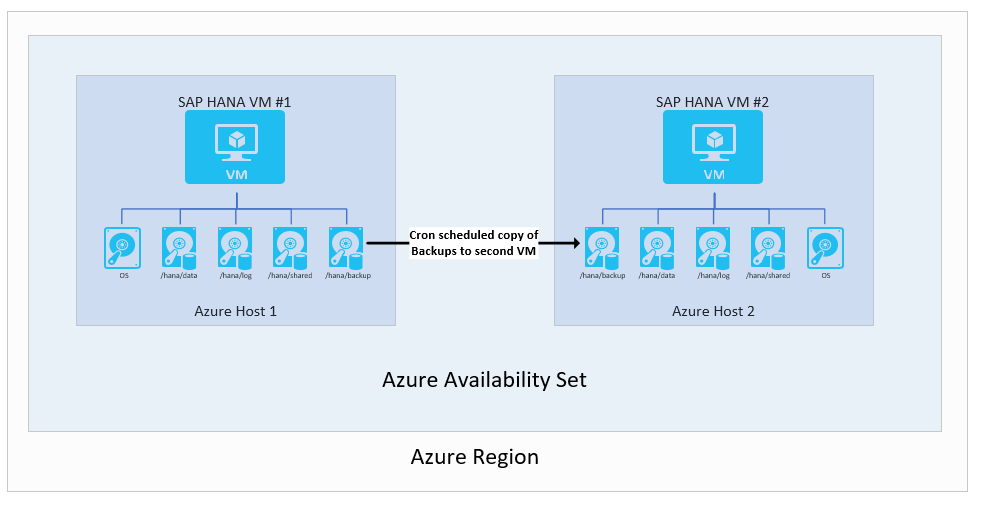
この設定は、優れた RPO (Recovery Point Objective) および RTO (Recovery Time Objective) 時間の実現には、あまり適していません。 特に RTO 時間は、コピーされたバックアップを使用して、データベース全体を完全に復元する必要があるため、困難が生じます。 ただし、このセットアップは、メイン インスタンスでの意図しないデータ削除からの復旧には役立ちます。 この設定では、特定時点への復元、データ抽出、メイン インスタンスへの削除されたデータのインポートが、いつでも可能です。 そのため、バックアップ コピーの手法を他の高可用性機能と組み合わせて使用すると、有効な場合があります。
バックアップをコピーするときは、SAP HANA インスタンスが実行されているメインの VM よりも、小さい VM を使用することもできます。 VM が小さいと、接続できる VHD の数は少なくなることに留意してください。 個別の VM タイプの制限については、「Azure の Linux 仮想マシンのサイズ」をご覧ください。
自動フェールオーバーを伴わない SAP HANA システム レプリケーション
このセクションで説明したシナリオでは、SAP HANA システム レプリケーションを使用します。 SAP ドキュメントについては、「System Replication」(システム レプリケーション) をご覧ください。 自動フェールオーバーを伴わないシナリオは、1 つの Azure リージョン内の構成にとって一般的ではありません。 自動フェールオーバーのない構成は、Pacemaker の設定は回避されても、監視とフェールオーバーを手動で実行することを要求します。 これには時間と労力がかかるため、ほとんどのお客様は、代わりに Azure サービスの復旧を頼りにします。 そのような構成が障害シナリオで役立つのは、一部の特別なケースだけです。 または、顧客が効率の向上を実現したいと考えているケースもあります。
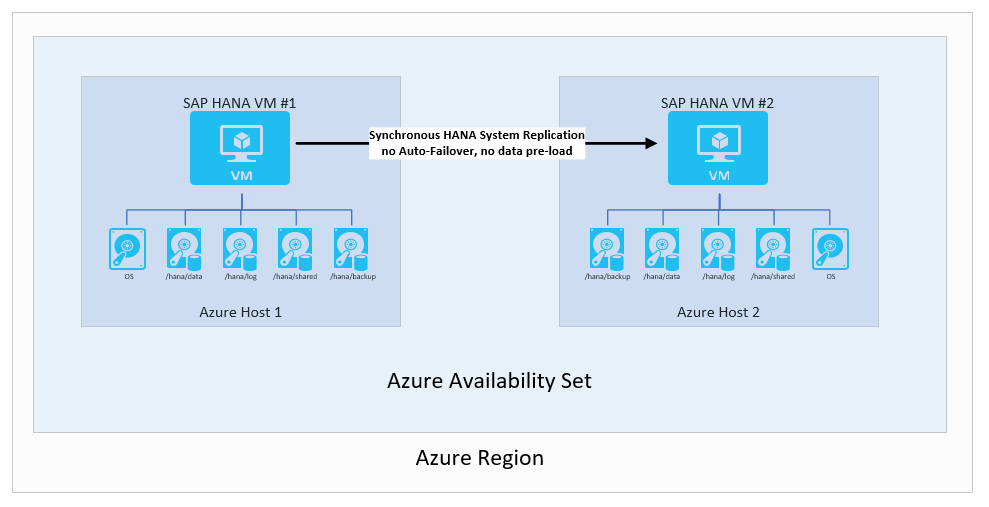
自動フェールオーバーとデータの事前読み込みを伴わない SAP HANA システム レプリケーション
このシナリオでは、同期的な方法でデータを移動して RPO の 0 を達成するために、SAP HANA システム レプリケーションを使用します。 一方で、RTO は十分に長いので、フェールオーバーや HANA インスタンス キャッシュへのデータの事前読み込みは必要ありません。 この場合は、以下の方法によって、構成の経済性を向上させることが可能です。
- 第 2 の VM で別の SAP HANA インスタンスを実行します。 第 2 の VM の SAP HANA インスタンスは、仮想マシンのメモリのほとんどを使用します。 第 2 の VM にフェールオーバーする場合は、第 2の VM にデータが完全に読み込まれている実行中の SAP HANA インスタンスをシャットダウンして、レプリケートされたデータが、第 2 の VM 内のターゲットの HANA インスタンスのキャッシュに読み込まれるようにする必要があります。
- 第 2 の VM 上でより小さい VM サイズを使用できます。 フェールオーバーが発生した場合、手動フェールオーバーの前に追加の手順を行います。 この手順では、VM サイズをソース VM のサイズに変更します。
シナリオは次のようになります。
Note
HANA システム レプリケーション ターゲットでデータの事前読み込みを使用しない場合でも、少なくとも 64 GB のメモリが必要です。 64 GB に加えて、ターゲット インスタンスのメモリに行ストア データを保持するための十分なメモリも必要です。
自動フェールオーバーがなく、データの事前読み込みを伴う SAP HANA システム レプリケーション
このシナリオでは、第 2 の VM の HANA インスタンスにレプリケートされるデータが事前に読み込まれます。 これにより、データの事前読み込みがない場合の 2 つの利点が失われます。 この場合、第 2 の VM で別の SAP HANA システムを実行することはできません。 また、小さい VM サイズを使うこともできません。 そのため、顧客がこのシナリオを実装することは、ほとんどありません。
自動フェールオーバーを伴う SAP HANA システム レプリケーション
1 つの Azure リージョン内の標準的かつ最も一般的な可用性の構成では、HA パッケージで Linux を実行する 2 つの Azure VM でフェールオーバー クラスターが定義されています。 HA Linux クラスターは、fencing deviceSLES または RHEL を例とした SLES または RHEL を使用するPacemaker フレームワークに基づいています。
SAP HANA の観点から、使用されるレプリケーション モードは同期され、自動フェールオーバーが構成されます。 第 2 の VM では、SAP HANA インスタンスはホット スタンバイ ノードとして機能します。 スタンバイ ノードは、プライマリ SAP HANA インスタンスから変更レコードの同期ストリームを受け取ります。 HANA プライマリ ノードでアプリケーションによってトランザクションがコミットされると、プライマリ HANA ノードは、セカンダリ SAP HANA ノードがコミット レコードを受信したことを確認するまで、アプリケーションへのコミットの確認を待機します。 SAP HANA では 2 つの同期レプリケーション モードを提供しています。 これら 2 つの同期レプリケーション モード間の違いに関する詳細および説明については、SAP の記事「Replication modes for SAP HANA System Replication」(SAP HANA システム レプリケーションのレプリケーション モード) をご覧ください。
全体的な構成は次のようになります。

RPO = 0 と短い RTO を実現できるため、このソリューションを選択できます。 SAP HANA クライアントが仮想 IP アドレスを使って HANA システム レプリケーション構成に接続するように、SAP HANA クライアント接続を構成します。 このような構成では、セカンダリ ノードへのフェールオーバーが発生した場合にアプリケーションを再構成する必要がなくなります。 このシナリオでは、プライマリおよびセカンダリ VM の Azure VM SKU を同じにする必要があります。
次のステップ
Azure でのこれらの構成の設定手順については、以下をご覧ください。
複数の Azure リージョン間での SAP HANA の可用性の詳細については、以下をご覧ください。