インフラストラクチャの永続レイヤーの設計
ヒント
このコンテンツは eBook の「コンテナー化された .NET アプリケーションの .NET マイクロサービス アーキテクチャ」からの抜粋です。.NET Docs で閲覧できるほか、PDF として無料ダウンロードすると、オンラインで閲覧できます。

データ永続化コンポーネントは、マイクロサービス (つまり、マイクロサービスのデータベース) の境界内でホストされているデータへのアクセスを提供します。 内容としては、リポジトリや作業単位クラス (カスタム Entity Framework (EF) DbContext など) などのコンポーネントの実際の実装が含まれています。 EF DbContext は、リポジトリおよび Unit of Work パターンの両方を実装します。
リポジトリ パターン
リポジトリ パターンは、システムのドメイン モデルの外部で永続化の問題を維持することを目的としたドメイン駆動設計パターンです。 1 つ以上の永続化抽象化 (インターフェイス) がドメイン モデルで定義されており、これらの抽象化には、アプリケーションの他の場所で定義されている永続化固有のアダプターの形式で実装があります。
リポジトリの実装は、データ ソースへのアクセスに必要なロジックをカプセル化するクラスです。 これにより、一般的なデータ アクセス機能が一元管理されて保守性が向上し、ドメイン モデルからデータベースにアクセスするためのインフラストラクチャやテクノロジが切り離されます。 Entity Framework などのオブジェクト リレーショナル マッパー (ORM) を使用する場合、LINQ と厳密な型指定により、実装する必要があるコードが簡素化されます。 これによりデータ アクセスの組み込みではなく、データ永続化ロジックに集中できるようになります。
リポジトリ パターンは、ドキュメントが整備されたデータ ソース操作方法です。 Martin Fowler は、著書『エンタープライズ アプリケーション アーキテクチャ パターン』の中でリポジトリのことを次のように述べています。
リポジトリは、ドメイン モデル レイヤーとデータ マッピングの間を媒介するタスクを実行し、メモリ内のドメイン オブジェクト セットに似たような動作をする。 クライアント オブジェクトは宣言によってクエリを構築し、リポジトリに送信して回答を得る。 概念上、リポジトリはデータベースに格納されている一連のオブジェクトとオブジェクト上で実行可能な操作をカプセル化し、永続レイヤーに近い方法を提供する。 また、リポジトリは、作業ドメインとデータの割り当て、すなわちマッピングとの依存関係を明確かつ一方向に切り離すという目的をサポートする。
集約ごとにリポジトリを定義する
各集約または集約ルートに1 つのリポジトリ クラスを作成する必要があります。 C# ジェネリックを利用して、維持する必要がある具象クラスの合計数を減らすことができる場合があります (この章の後半で説明します)。 ドメイン駆動設計 (DDD) パターンに基づくマイクロサービスでは、リポジトリはデータベースの更新に使用する唯一のチャネルです。 これは、リポジトリには集約ルートとの一対一の関係があるためで、これにより集約の不変性とトランザクションの一貫性が管理されます。 データベースのクエリは他のチャネルで実行することもできますが (CQRS アプローチに従って実行することも可能)、それは、クエリではデータベースの状態が変更されないためです。 ただし、トランザクション領域 (つまり、更新) は、常にリポジトリと集約ルートで制御する必要があります。
基本的に、リポジトリでは、データベースから取得されたデータをドメイン エンティティの形式でメモリ内に設定することができます。 メモリ内に設定されたエンティティは、トランザクションによって変更し、再度データベースに保存することができます。
前述したように、CQS/CQRS アーキテクチャ パターンを使用している場合、Dapper を使用した単純な SQL ステートメントによって実行されるドメイン モデルからの副クエリによって最初のクエリが実行されます。 この方法は、必要な任意のテーブルを照会および結合可能で、クエリが集約からのルールによって制限されないため、リポジトリよりはるかに柔軟です。 その場合、データはプレゼンテーション レイヤーまたはクライアント アプリに移動します。
ユーザーが変更を行うと、更新されるデータは、クライアント アプリまたはプレゼンテーション レイヤーからアプリケーションレイヤー (Web API サービスなど) に移動します。 コマンド ハンドラーでコマンドを受信したら、リポジトリを使用して、更新するデータをデータベースから取得します。 メモリ内で、コマンドを使用して渡されたデータを更新した後、トランザクションによりデータベース内のデータ (ドメイン エンティティ) を追加または更新します。
もう一度強調しますが、図 7-17 に示すように、集約ルートごとにリポジトリを 1 つのみ定義することが重要です。 集約内のすべてのオブジェクト間のトランザクションの一貫性を維持するという集約ルートの目標を達成するため、データベース内の各テーブルのリポジトリは作成しません。
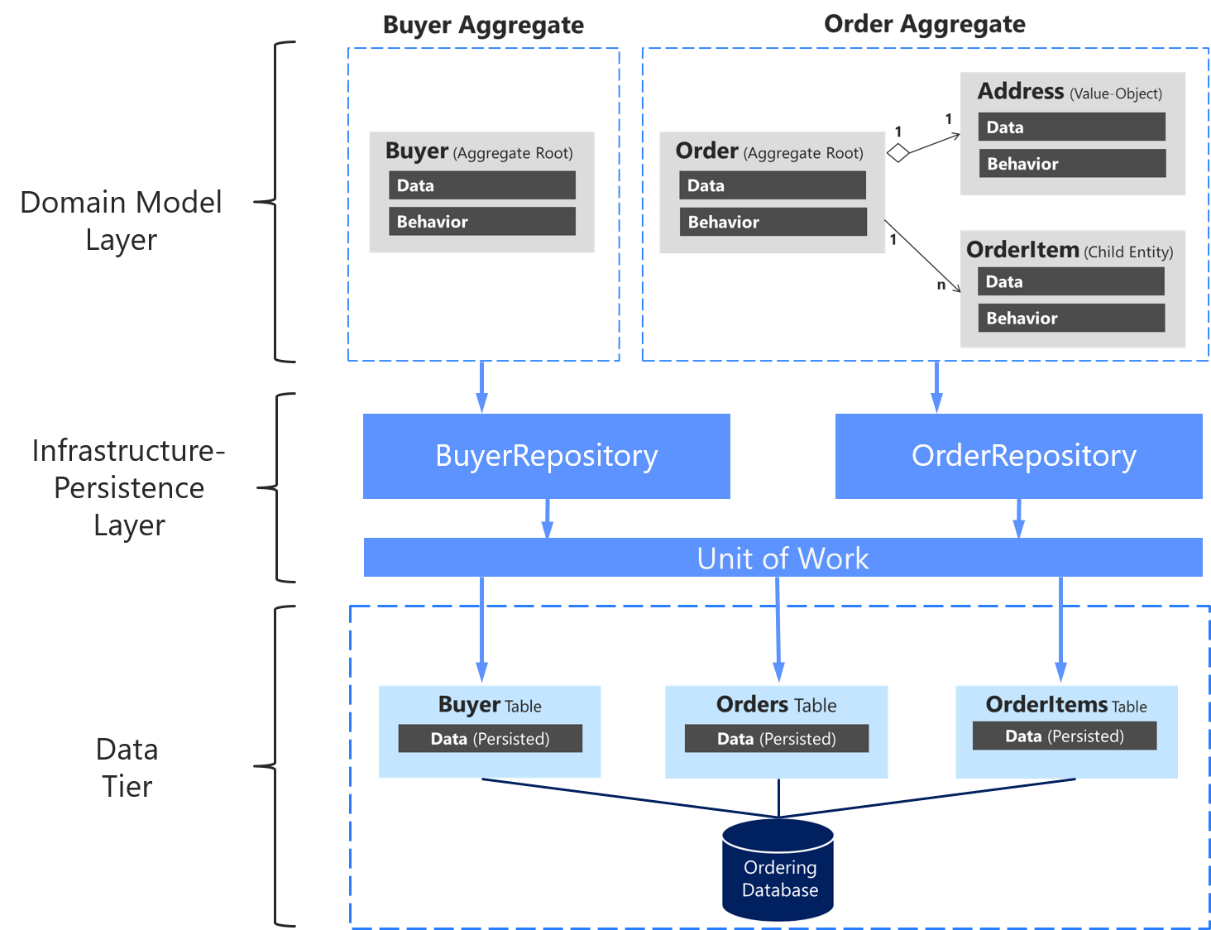
図 7-17。 リポジトリ、集約、およびデータベース テーブル間のリレーションシップ
上の図は、ドメインとインフラストラクチャのレイヤー間の関係を示しています。バイヤー集約は IBuyerRepository に依存し、Order Aggregate は IOrderRepository インターフェイスに依存し、これらのインターフェイスは UnitOfWork に依存する対応するリポジトリによってインフラストラクチャ レイヤーに実装され、データ層のテーブルにアクセスする場所にも実装されます。
リポジトリごとに 1 つの集約ルートを適用
リポジトリ設計を実装する際に、集約ルートのみにリポジトリを設定するというルールを適用することが重要な場合があります。 操作するエンティティの型を制約するジェネリック型または基本型のリポジトリを作成し、IAggregateRoot マーカー インターフェイスを設定することができます。
このように、インフラストラクチャ レイヤーで実装されている各リポジトリ クラスに独自のコントラクトまたはインターフェイスが実装されます (次のコードを参照)。
namespace Microsoft.eShopOnContainers.Services.Ordering.Infrastructure.Repositories
{
public class OrderRepository : IOrderRepository
{
// ...
}
}
リポジトリの各インターフェイスには、ジェネリック IRepository インターフェイスが実装されます。
public interface IOrderRepository : IRepository<Order>
{
Order Add(Order order);
// ...
}
しかし、各リポジトリが単一の集計に関連付けられる規則を適用するコードを用意するには、ジェネリック型のリポジトリを実装することをお勧めします。 そうすることで、特定の集約を対象とするリポジトリを使用していることが明確になります。 これは、次のコードのように、そのジェネリックの IRepository 基底インターフェイスを実装することで簡単に行えます。
public interface IRepository<T> where T : IAggregateRoot
{
//....
}
アプリケーション ロジックのテストを容易にするリポジトリ パターン
リポジトリ パターンを利用すると、単体テストでアプリケーションを簡単にテストすることができます。 単体テストの対象はインフラストラクチャではなく、コードのみであるため、リポジトリの抽象化により目的を達成しやすくなります。
前のセクションで説明したように、リポジトリ インターフェイスをドメイン モデル レイヤーに定義および配置し、アプリケーション レイヤー (Web API マイクロサービスなど) が、実際のリポジトリ クラスを実装しているインフラストラクチャ レイヤーに直接依存しないようにすることをお勧めします。 これにより、Web API のコント ローラーで依存関係の挿入を使用して、データベースのデータではなく疑似データを返すモック リポジトリを実装できます。 このような分離アプローチでは、データベースへの接続を必要とせず、アプリケーションのロジックに集中する単体テストを作成し、実行することができます。
データベースに対して膨大なテストを実行することには、データベースへの接続が失敗する可能性があることに加え、さらに大きな 2 つの理由から問題があります。 その 1 つは、テスト量の多さにより時間がかかる可能性があることです。 次に、データベース レコードが変更され、テストの結果に影響を与える可能性があります。特に、テストが並列で実行されている場合は、一貫性が得られないことがあります。 単体テストは通常、並列で実行できます。統合テストは、実装によっては並列実行がサポートされていない場合があります。 データベースに対するテストは単体テストではなく、統合テストです。 多数の単体テストを高速で実行する必要がありますが、データベースに対する統合テストは大量に行う必要はありません。
単体テストの問題の分離という観点から、ロジックはメモリ内のドメイン エンティティで動作します。 ドメイン エンティティはリポジトリ クラスで提供されるものと想定します。 また、ロジックによって変更されたドメイン エンティティは、リポジトリ クラスに適切に保存されるものと想定します。 ここでの重要なポイントは、単体テストはドメイン モデルとそのドメイン ロジックに対して作成するということです。 集約ルートは DDD の主な整合性境界です。
eShopOnContainers に実装されたリポジトリは、その変更追跡を使用するリポジトリ パターンと Unit of Work パターンでの EF Core の DbContext 実装に依存するため、この機能を複製することはありません。
リポジトリ パターンと、従来のデータ アクセス クラス (DAL クラス) パターンの違い
一般的な DAL オブジェクトは、ストレージに対して、多くの場合、1 つのテーブルと行のレベルでデータ アクセスと永続化操作を直接実行します。 DAL クラスのセットを使用して実装される単純な CRUD 操作では、トランザクションがサポートされないことがよくあります (ただし、必ずしもそうであるとは限りません)。 ほとんどの DAL クラス アプローチでは抽象化を最小限に抑え、DAL オブジェクトを呼び出すアプリケーションまたはビジネス ロジック レイヤー (BLL) クラス間の緊密な結合を実現します。
リポジトリを使用する場合、永続化の実装の詳細はドメイン モデルからカプセル化されます。 抽象化を使用すると、デコレーターやプロキシなどのパターンを使用して動作を簡単に拡張できるようになります。 たとえば、キャッシュ、ログ、エラー処理などの横断的な問題にはすべて、データ アクセス コード自体でハードコーディングされるのではなく、これらのパターンを使用して適用できます。 また、ローカル開発から、共有ステージング環境や、運用環境まで、さまざまな環境で使用できる複数のリポジトリ アダプターをサポートすることも簡単です。
Unit of Work の実装
Unit of Work は複数の挿入、更新、または削除操作を含む単一のトランザクションを指します。 つまり、特定のユーザー操作 (Web サイトへの登録など) に対して、すべての挿入、更新、および削除の操作が単一のトランザクションとして処理されることを意味します。 これは、複数のデータベース トランザクションを対話方法で処理するよりも効率的です。
これらの複数の永続化操作は、後でアプリケーション レイヤーのコードが命令を発行したときに、1 アクションで実行されます。 実際のデータベース記憶域にメモリ内の変更を適用する決定は、通常、作業単位パターンに基づいて行われます。 EF では、Unit of Work パターンは DbContext によって実装され、SaveChanges に呼び出しが行われると実行されます。
多くの場合、このパターンまたは記憶域に対する操作の適用方法により、アプリケーションのパフォーマンスを向上させ、不整合の可能性を低減することができます。 また、意図したすべての操作が単一のトランザクションの一部としてコミットされるので、データベース テーブル内でブロックされるトランザクションも少なくなります。 これは、データベースに対して多数の単独の操作を実行する場合と比べて効率的です。 そのため、小規模な個別のトランザクションを多数実行するのではなく、同じトランザクション内で複数の更新操作をグループ化することにより、選択した ORM でデータベースに対する実行を最適化できます。
Unit of Work パターンは、リポジトリ パターンを使用してもしなくても実装できます。
リポジトリは必須ではない
カスタム リポジトリは、前述の理由により便利であり、eShopOnContainers の順序付けマイクロサービスで採用されているアプローチですが、 DDD 設計の実装、または一般的な .NET 開発に不可欠なパターンではありません。
たとえば、このガイドに対するフィードバックを直接提供してくれた Jimmy Bogard は次のように述べています。
おそらく、これは私の最大のフィードバックになるでしょう。 私はリポジトリが好きではありません。その主な理由は、基本となる永続化メカニズムの重要な詳細が隠ぺいされていることです。 私がコマンドに MediatR を採用する理由もそこにあります。 永続レイヤーの機能をフルに活用し、集約ルートにドメイン動作のすべてをプッシュすることができます。 通常は、リポジトリでのシミュレーションを行いたくないので、実際のデータで統合テストを実行する必要があります。 CQRS を利用すれば、もうリポジトリは不要です。
リポジトリは便利な場合がありますが、集約パターンやリッチ ドメイン モデルの場合とは異なり、DDD では重要ではありません。 したがって、リポジトリ パターンは使用しても、しなくても、かまいません。
その他の技術情報
リポジトリ パターン
Edward Hieatt、Rob Mee。 リポジトリ パターン。
https://martinfowler.com/eaaCatalog/repository.htmlリポジトリ パターン
https://learn.microsoft.com/previous-versions/msp-n-p/ff649690(v=pandp.10)Eric Evans。 『Domain-Driven Design: Tackling Complexity in the Heart of Software』 (エリック・エヴァンスのドメイン駆動設計)。 (書籍: リポジトリ パターンに関する説明が含まれています)
https://www.amazon.com/Domain-Driven-Design-Tackling-Complexity-Software/dp/0321125215/
Unit of Work パターン
Martin Fowler。 Unit of Work パターン。
https://martinfowler.com/eaaCatalog/unitOfWork.htmlASP.NET MVC アプリケーションでの Repository および Unit of Work パターンの実装
https://learn.microsoft.com/aspnet/mvc/overview/older-versions/getting-started-with-ef-5-using-mvc-4/implementing-the-repository-and-unit-of-work-patterns-in-an-asp-net-mvc-application
.NET
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示