チュートリアル: 転移学習と ML.NET Image Classification API を利用した自動ビジュアル検査
転移学習、事前トレーニング済みの TensorFlow モデル、ML.NET Image Classification API を利用してカスタム ディープ ラーニング モデルをトレーニングし、コンクリートの表面の画像をひび割れあり/ひび割れなしに分類する方法について説明します。
このチュートリアルでは、次の作業を行う方法について説明します。
- 問題を把握する
- ML.NET Image Classification API について
- 事前トレーニング済みモデルについて
- 転移学習を利用し、カスタム TensorFlow 画像分類モデルをトレーニングする
- カスタム モデルによる画像の分類
必須コンポーネント
画像分類の転移学習の概要
このサンプルは、事前トレーニング済みディープ ラーニング TensorFlow モデルを利用して画像を分類する C# .NET Core コンソール アプリケーションです。 このサンプルのコードはサンプル ブラウザーにあります。
問題を把握する
画像分類はコンピューターのビジョンの問題です。 画像分類では、画像を入力として受け取り、指示されたクラスにそれを分類します。 画像分類モデルは、一般的にディープ ラーニングとニューラル ネットワークを使用してトレーニングされます。 詳細については、ディープ ラーニングと機械学習の違いに関するページを参照してください。
画像分類はたとえば次のシナリオで役立ちます。
- 顔認識
- 感情検出
- 医療診断
- 陸標検出
このチュートリアルでは、カスタム画像分類モデルをトレーニングし、橋床の映像を自動検査し、ひび割れしている構造物を特定します。
ML.NET Image Classification API
ML.NET からは、画像分類を実行するさまざまな方法が与えられます。 このチュートリアルでは、Image Classification API を使用する転移学習を応用します。 Image Classification API では TensorFlow.NET を利用します。これは TensorFlow C++ API 用に C# バインディングを提供する低レベル ライブラリです。
転移学習とは何か
転移学習では、ある問題を解決することで得られた知識が関連する別の問題に応用されます。
ディープ ラーニング モデルを最初からトレーニングするには、いくつかのパラメーター、大量のラベル付きトレーニング データ、膨大な量の計算リソース (数百時間の GPU) を設定する必要があります。 事前トレーニング済みモデルと転移学習を使用すると、トレーニング プロセスをショートカットできます。
トレーニング プロセス
Image Classification API のトレーニング プロセスは、事前トレーニング済み TensorFlow モデルを読み込むことから始まります。 トレーニング プロセスは次の 2 つのステップで構成されます。
- ボトルネック フェーズ
- トレーニング フェーズ
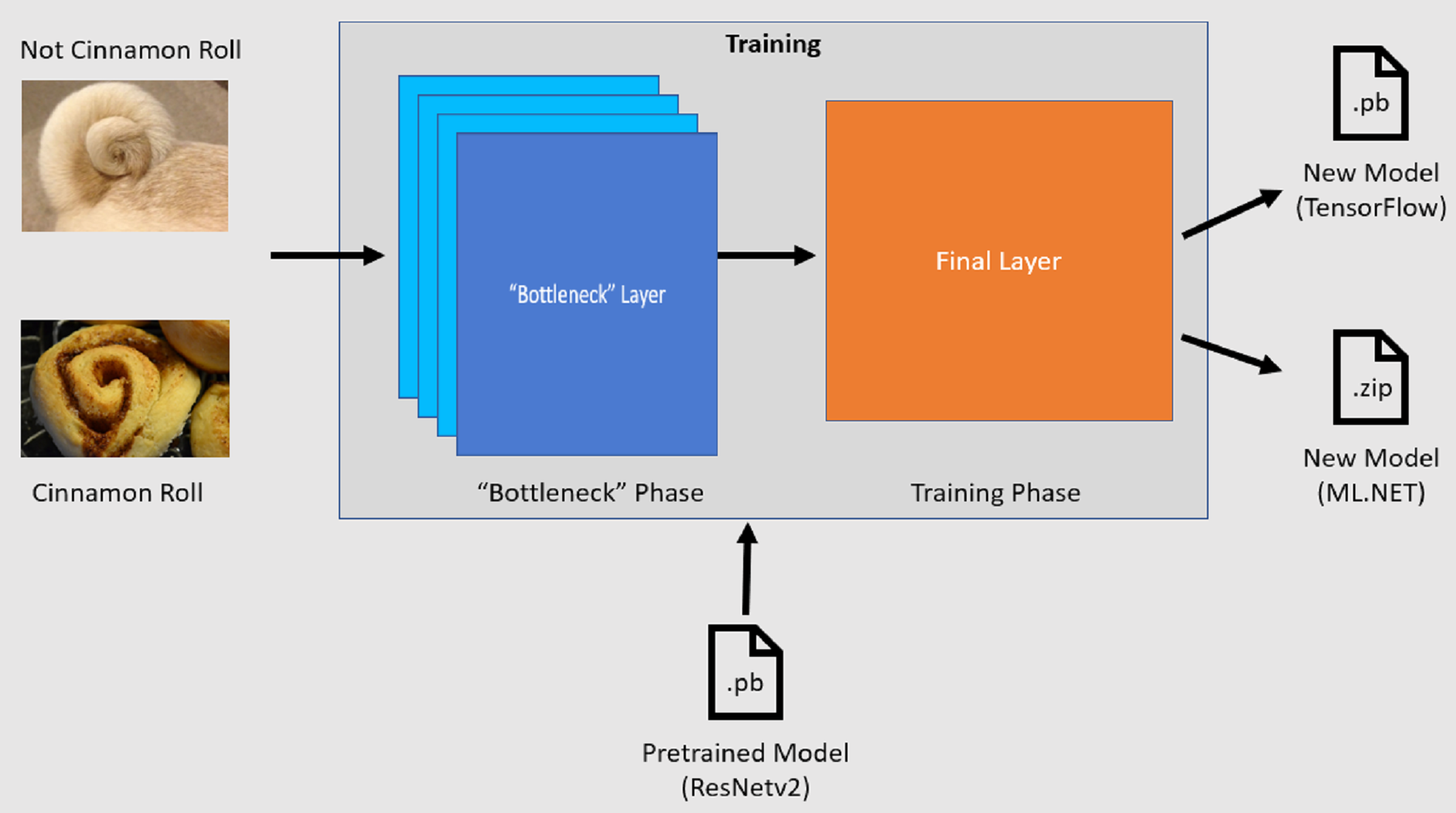
ボトルネック フェーズ
ボトルネック フェーズの間、事前トレーニング済みモデルの固定レイヤーに対して、一連のトレーニング画像が読み込まれ、ピクセル値が入力として使用されます。 固定レイヤーには、非公式にボトルネック レイヤーと呼ばれている最後から 2 番目のレイヤーまでに含まれる、ニューラル ネットワーク内のあらゆるレイヤーが含まれます。 このようなレイヤーは、その上でトレーニングが発生せず、操作がパススルーであるため、固定と呼ばれています。 モデルでさまざまなクラスを区別するのに役立つ低レベル パターンが計算されるのがこの固定レイヤーです。 レイヤーの数が多ければ多いほど、この手順は計算処理がそれだけ激しくなります。 幸いなことに、これは 1 回限りの計算であるため、結果をキャッシュし、後で異なるパラメーターを使用して実験するときに利用できます。
トレーニング フェーズ
ボトルネック フェーズからの出力値が計算されると、それが入力として利用され、モデルの最終的レイヤーが保持されます。 このプロセスは繰り返され、モデル パラメーターで指定された回数だけ実行されます。 実行のたびに、損失と精度が評価されます。 次に、損失を最小限に抑え、精度を最大限に高めることを目的としてモデルを改善するための適切な調整が行われます。 トレーニングが完了すると、2 つのモデル形式が出力されます。 そのうちの 1 つがモデルの .pb バージョンであり、もう 1 つがモデルの .zip ML.NET シリアル化バージョンです。 ML.NET でサポートされる環境で作業するとき、モデルの .zip バージョンを使用することが推奨されます。 ただし、ML.NET がサポートされない環境では、.pb バージョンを使用できます。
事前トレーニング済みモデルについて
このチュートリアルで使用される事前トレーニング済みモデルは、Residual Network (ResNet) v2 モデルの 101 レイヤー型です。 元のモデルは、画像を 1,000 個のカテゴリに分類する目的でトレーニングされています。 このモデルでは、サイズ 224 x 224 の画像を入力として受け取り、トレーニングしたクラス別にクラス確率を出力します。 このモデルの一部は、2 つのクラス間で予測する目的でカスタム画像を利用して新しいモデルをトレーニングするために使用されます。
コンソール アプリケーションを作成する
転移学習と Image Classification API の概要を理解できたところで、アプリケーションを構築しましょう。
"DeepLearning_ImageClassification_Binary" という名前の C# コンソール アプリケーションを作成します。 [次へ] をクリックします。
使用するフレームワークとして [.NET 6] を選択します。 [作成] ボタンをクリックします。
Microsoft.ML NuGet パッケージをインストールします。
注意
このサンプルでは、特に明記されていない限り、記載されている最新の安定バージョンの NuGet パッケージを使用します。
- ソリューション エクスプローラーで、プロジェクトを右クリックし、 [NuGet パッケージの管理] を選択します。
- [パッケージ ソース] として [nuget.org] を選択します。
- [参照] タブを選択します。
- [プレリリースを含める] チェックボックスをオンにします。
- Microsoft.ML を探します。
- [インストール] ボタンを選択します。
- [変更のプレビュー] ダイアログの [OK] を選択します。表示されているパッケージのライセンス条項に同意する場合は、 [ライセンスの同意] ダイアログの [同意する] を選択します。
- Microsoft.ML.Vision、SciSharp.TensorFlow.Redist バージョン 2.3.1、および Microsoft.ML.ImageAnalytics NuGet パッケージに対して、これらの手順を繰り返します。
データを準備して理解する
注意
このチュートリアルのデータセットの提供元: Maguire, Marc; Dorafshan, Sattar; and Thomas, Robert J., "SDNET2018:A concrete crack image dataset for machine learning applications" (2018). Browse all Datasets. Paper 48. https://digitalcommons.usu.edu/all_datasets/48
SDNET2018 は、ひび割れあり/ひび割れなしのコンクリート構造物 (橋床、壁、歩道) に関する注釈を含む画像データセットです。

データは 3 つのサブディレクトリで整理されています。
- D には橋床の画像が含まれています
- P には歩道の画像が含まれています
- W には壁の画像が含まれています
これらのサブディレクトリにはそれぞれ、追加のサブディレクトリが 2 つ含まれ、プレフィックスが付けられています。
- C はひび割れありの表面に使用されるプレフィックスです
- U はひび割れなしの表面に使用されるプレフィックスです
このチュートリアルでは、橋床の画像のみ使用します。
- データセットをダウンロードし、解凍します。
- データ セット ファイルを保存するために、プロジェクトに "assets" という名前のディレクトリを作成します。
- 先ほど解凍したディレクトリから assets ディレクトリに CD サブディレクトリと UD サブディレクトリをコピーします。
入力クラスと出力クラスを作成する
Program.cs ファイルを開き、ファイルの先頭にある既存の
usingステートメントを次で置き換えます。using System; using System.Collections.Generic; using System.Linq; using System.IO; using Microsoft.ML; using static Microsoft.ML.DataOperationsCatalog; using Microsoft.ML.Vision;Program.cs の
Programクラスの下でImageDataという名前のクラスを作成します。 このクラスは、最初に読み込んだデータを表わすために使用されます。class ImageData { public string ImagePath { get; set; } public string Label { get; set; } }ImageDataには次のプロパティが含まれます。ImagePathは、画像が保存されている完全修飾パスです。Labelは、画像が属するカテゴリです。 これが予測する値です。
入力データと出力データのクラスを作成する
ImageDataクラスの下で、ModelInputという名前の新しいクラスに入力データのスキーマを定義します。class ModelInput { public byte[] Image { get; set; } public UInt32 LabelAsKey { get; set; } public string ImagePath { get; set; } public string Label { get; set; } }ModelInputには次のプロパティが含まれます。Imageは画像のbyte[]表現です。 モデルでは、トレーニングのために画像データがこの種類になることが求められます。LabelAsKeyはLabelの数値表現です。ImagePathは、画像が保存されている完全修飾パスです。Labelは、画像が属するカテゴリです。 これが予測する値です。
ImageとLabelAsKeyのみ、モデルのトレーニングと予測に使用されます。ImagePathプロパティとLabelプロパティは、元の画像ファイルの名前やカテゴリにアクセスするときに便利なため、維持されます。次に、
ModelInputクラスの下で、ModelOutputという名前の新しいクラスに出力データのスキーマを定義します。class ModelOutput { public string ImagePath { get; set; } public string Label { get; set; } public string PredictedLabel { get; set; } }ModelOutputには次のプロパティが含まれます。ImagePathは、画像が保存されている完全修飾パスです。Labelは、画像が属する元のカテゴリです。 これが予測する値です。PredictedLabelはモデルで予測された値です。
ModelInputと同様に、予測にはPredictedLabelのみが必要になります。モデルによる予測が含まれているためです。ImagePathプロパティとLabelプロパティは、元の画像ファイルの名前やカテゴリにアクセスするときに便利なため、保持されます。
ワークスペース ディレクトリを作成する
トレーニング データと検証データが頻繁に変更されない場合は、今後の実行のために、計算されたボトルネック値をキャッシュすることをお勧めします。
- プロジェクトで workspace という名前の新しいディレクトリを作成し、計算されたボトルネック値とモデルの
.pbバージョンを格納します。
パスを定義し、変数を初期化する
using ステートメントの下で、アセットの場所、計算されたボトルネック値、モデルの
.pbバージョンを定義します。var projectDirectory = Path.GetFullPath(Path.Combine(AppContext.BaseDirectory, "../../../")); var workspaceRelativePath = Path.Combine(projectDirectory, "workspace"); var assetsRelativePath = Path.Combine(projectDirectory, "assets");MLContext の新しいインスタンスを使用して
mlContext変数を初期化します。MLContext mlContext = new MLContext();MLContext クラスは、すべての ML.NET 操作の開始点で、mlContext を初期化することで、モデル作成ワークフローのオブジェクト間で共有できる新しい ML.NET 環境が作成されます。 これは Entity Framework における
DbContextと概念的には同じです。
データを読み込む
データ読み込みユーティリティ メソッドを作成する
イメージは 2 つのサブディレクトリに保存されます。 データを読み込む前に、ImageData オブジェクトの一覧に書式設定する必要があります。 それには、LoadImagesFromDirectory メソッドを作成します。
IEnumerable<ImageData> LoadImagesFromDirectory(string folder, bool useFolderNameAsLabel = true)
{
}
LoadImagesFromDirectory内で次のコードを追加し、サブディレクトリからすべてのファイル パスを取得します。var files = Directory.GetFiles(folder, "*", searchOption: SearchOption.AllDirectories);次に、
foreachステートメントを利用して各ファイルを反復処理します。foreach (var file in files) { }foreachステートメント内で、ファイルの拡張子がサポートされていることを確認します。 Image Classification API では、JPEG 形式と PNG 形式がサポートされています。if ((Path.GetExtension(file) != ".jpg") && (Path.GetExtension(file) != ".png")) continue;次に、ファイルのラベルを取得します。
useFolderNameAsLabelパラメーターがtrueに設定されている場合、ファイルが保存されている親ディレクトリがラベルとして使用されます。 それ以外の場合、ラベルは、ファイルのプレフィックスか名前自体にする必要があります。var label = Path.GetFileName(file); if (useFolderNameAsLabel) label = Directory.GetParent(file).Name; else { for (int index = 0; index < label.Length; index++) { if (!char.IsLetter(label[index])) { label = label.Substring(0, index); break; } } }最後に、
ModelInputの新しいインスタンスを作成します。yield return new ImageData() { ImagePath = file, Label = label };
データを準備する
LoadImagesFromDirectoryユーティリティ メソッドを呼び出し、mlContext変数の初期化後にトレーニングに使用される画像の一覧を取得します。IEnumerable<ImageData> images = LoadImagesFromDirectory(folder: assetsRelativePath, useFolderNameAsLabel: true);次に、
LoadFromEnumerableメソッドを利用してIDataViewに画像を読み込みます。IDataView imageData = mlContext.Data.LoadFromEnumerable(images);データはディレクトリから読み取られた順序で読み込まれます。 データのバランスを維持するために、
ShuffleRowsメソッドを利用してシャッフルします。IDataView shuffledData = mlContext.Data.ShuffleRows(imageData);機械学習モデルでは、数値形式で入力する必要があります。 そのため、トレーニングの前にデータでいくつかの処理を行う必要があります。
MapValueToKey変換とLoadRawImageBytes変換から構成されるEstimatorChainを作成します。MapValueToKey変換では、Label列のカテゴリ値を受け取り、それを数値KeyTypeに変換し、LabelAsKeyという名前の新しい列に保存します。LoadImagesでは、imageFolderパラメーターと共にImagePathから値を取得し、トレーニングのために画像を読み込みます。var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey( inputColumnName: "Label", outputColumnName: "LabelAsKey") .Append(mlContext.Transforms.LoadRawImageBytes( outputColumnName: "Image", imageFolder: assetsRelativePath, inputColumnName: "ImagePath"));データを
preprocessingPipelineEstimatorChainに適用するFitメソッドを使用し、事前処理済みのデータが含まれるIDataViewメソッドを返すTransformメソッドを続けます。IDataView preProcessedData = preprocessingPipeline .Fit(shuffledData) .Transform(shuffledData);モデルをトレーニングするには、トレーニング データセットと検証データセットを用意することが重要です。 モデルはトレーニング セットでトレーニングされます。 初見のデータの予測精度は、検証セットに対するパフォーマンスで計測されます。 そのパフォーマンスの結果に基づき、改善努力の中でモデルが学習したものに調整が加えられます。 検証セットは、元のデータセットを分割することで取得するか、この目的のために既に用意されていた別の情報源から取得します。 今回、事前処理済みのデータセットがトレーニング セット、検証セット、テスト セットに分割されています。
TrainTestData trainSplit = mlContext.Data.TrainTestSplit(data: preProcessedData, testFraction: 0.3); TrainTestData validationTestSplit = mlContext.Data.TrainTestSplit(trainSplit.TestSet);上のコード サンプルでは、2 回分割されます。 まず、事前処理済みのデータが分割され、70% がトレーニングに使用され、残りの 30% が検証に使用されます。 次に、30% の検証セットがさらに検証セットとテスト セットに分割され、90% が検証に使用され、10% がテストに使用されます。
このようなデータ分割の目的は試験を受けるようなものです。 試験勉強するとき、ノート、教科書、参考書で復習し、試験に出る概念をつかみます。 トレーニング セットがこれに相当します。 次に、模擬試験を受け、自分の知識を確認します。 ここで役立つのが検証セットです。 実際に試験を受ける前に概念をしっかり理解しているかを確認したくなることでしょう。 模擬試験の結果に基づき、間違った箇所や良く理解していなかった箇所をメモし、本番の試験に向けて復習する中、変えるべきところを組み込みます。 最後に、試験を受けます。 テスト セットがこれに相当します。 試験に出ている問題は今まで見たことがありません。トレーニングと検証から学習したことを活用し、手元の課題に自分の知識を応用します。
トレーニング データ、検証データ、テスト データそれぞれの値をパーティションに割り当てます。
IDataView trainSet = trainSplit.TrainSet; IDataView validationSet = validationTestSplit.TrainSet; IDataView testSet = validationTestSplit.TestSet;
トレーニング パイプラインを定義する
モデル トレーニングはいくつかのステップから構成されます。 まず、Image Classification API を利用し、モデルがトレーニングされます。 次に、PredictedLabel 列のエンコード済みラベルが MapKeyToValue 変換により元のカテゴリ値に戻されます。
ImageClassificationTrainer の必須パラメーターと省略可能なパラメーターのセットを格納するために、新しい変数を作成します。
var classifierOptions = new ImageClassificationTrainer.Options() { FeatureColumnName = "Image", LabelColumnName = "LabelAsKey", ValidationSet = validationSet, Arch = ImageClassificationTrainer.Architecture.ResnetV2101, MetricsCallback = (metrics) => Console.WriteLine(metrics), TestOnTrainSet = false, ReuseTrainSetBottleneckCachedValues = true, ReuseValidationSetBottleneckCachedValues = true };ImageClassificationTrainer では、いくつかの省略可能なパラメーターを取得します。
FeatureColumnNameはモデルの入力として使用される列です。LabelColumnNameは予測する値の列です。ValidationSetは検証データが含まれるIDataViewです。Archでは、使用する事前トレーニング済みモデル アーキテクチャが定義されます。 このチュートリアルでは、ResNetv2 モデルの 101 レイヤー型が使用されます。MetricsCallbackでは、トレーニング中に進捗状況を追跡記録する関数がバインドされます。TestOnTrainSetからは、検証セットがないとき、トレーニング セットに対してパフォーマンスを検証するようにモデルに指示が出ます。ReuseTrainSetBottleneckCachedValuesからは、後続の実行でボトルネック フェーズからキャッシュされた値を使用するかどうかがモデルに伝えられます。 ボトルネック フェーズは、初回実行時の計算処理が激しいワンタイム パススルー計算です。 トレーニング データが変わらないとき、エポック数やバッチ サイズを変えて実験する場合、キャッシュした値を利用すると、モデルのトレーニングに必要な時間が大幅に短縮されます。ReuseValidationSetBottleneckCachedValuesはReuseTrainSetBottleneckCachedValuesに似ていますが、これは検証データセット用になります。WorkspacePathでは、計算されたボトルネック値と.pbバージョンのモデルを格納するディレクトリを定義します。
mapLabelEstimatorと ImageClassificationTrainer の両方から構成されるEstimatorChainトレーニング パイプラインを定義します。var trainingPipeline = mlContext.MulticlassClassification.Trainers.ImageClassification(classifierOptions) .Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));Fitメソッドを利用してモデルをトレーニングします。ITransformer trainedModel = trainingPipeline.Fit(trainSet);
モデルを使用する
モデルをトレーニングできたところで、モデルを利用して画像を分類しましょう。
コンソールに予測情報を表示する、OutputPrediction という名前の新しいユーティリティ メソッドを作成します。
private static void OutputPrediction(ModelOutput prediction)
{
string imageName = Path.GetFileName(prediction.ImagePath);
Console.WriteLine($"Image: {imageName} | Actual Value: {prediction.Label} | Predicted Value: {prediction.PredictedLabel}");
}
1 枚の画像を分類する
ClassifySingleImageという名前の新しいメソッドを作成します。このメソッドは画像を 1 回予測し、出力します。void ClassifySingleImage(MLContext mlContext, IDataView data, ITransformer trainedModel) { }ClassifySingleImageメソッド内にPredictionEngineを作成します。PredictionEngineは、データの 1 つのインスタンスを渡してから、その予測を実行できる便利な API です。PredictionEngine<ModelInput, ModelOutput> predictionEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(trainedModel);1 つの
ModelInputインスタンスにアクセスするには、 メソッドを利用してdataIDataViewをCreateEnumerableIEnumerableに変換し、最初の観察を取得します。ModelInput image = mlContext.Data.CreateEnumerable<ModelInput>(data,reuseRowObject:true).First();Predictメソッドを使用し、画像を分類します。ModelOutput prediction = predictionEngine.Predict(image);OutputPredictionメソッドでコンソールに予測を出力します。Console.WriteLine("Classifying single image"); OutputPrediction(prediction);Fitメソッドの呼び出しの下で、画像のテスト セットを利用してClassifySingleImageを呼び出します。ClassifySingleImage(mlContext, testSet, trainedModel);
複数の画像を分類する
ClassifySingleImageメソッドの下にClassifyImagesという名前の新しいメソッドを追加します。このメソッドは画像を複数回予測し、出力します。void ClassifyImages(MLContext mlContext, IDataView data, ITransformer trainedModel) { }Transformメソッドを利用し、予測を含むIDataViewを作成します。ClassifyImagesメソッド内に次のコードを追加します。IDataView predictionData = trainedModel.Transform(data);予測を反復処理するには、 メソッドを利用して
predictionDataIDataViewをCreateEnumerableIEnumerableに変換し、最初の 10 件の観察を取得します。IEnumerable<ModelOutput> predictions = mlContext.Data.CreateEnumerable<ModelOutput>(predictionData, reuseRowObject: true).Take(10);予測を反復処理し、元のラベルと予測後のラベルを出力します。
Console.WriteLine("Classifying multiple images"); foreach (var prediction in predictions) { OutputPrediction(prediction); }最後に、
ClassifySingleImage()メソッドの下で、画像のテスト セットを利用してClassifyImagesを呼び出します。ClassifyImages(mlContext, testSet, trainedModel);
アプリケーションの実行
コンソール アプリを実行します。 出力は下の出力のようになるはずです。 警告メッセージまたは処理中のメッセージが表示される場合がありますが、わかりやすくするため、これらのメッセージは結果から削除してあります。 簡潔にするため、出力は要約されています。
ボトルネック フェーズ
画像は byte[] として読み込まれており、表示する画像名がないため、画像名には値が出力されません。
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 279
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 280
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 1
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 2
トレーニング フェーズ
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 21, Accuracy: 0.6797619
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 22, Accuracy: 0.7642857
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 23, Accuracy: 0.7916667
画像分類の出力
Classifying single image
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Classifying multiple images
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-163.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-210.jpg | Actual Value: UD | Predicted Value: UD
7001-220.jpg 画像の検査後、実際のところ、ひび割れがないことがわかりました。

おめでとうございます! これで画像を分類するディープ ラーニング モデルが正しく作成されました。
画像を改善する
モデルの結果に不満が残る場合、次の手法を試し、パフォーマンスを向上してみることができます。
- データを増やす:モデルが学習するサンプルの数が多ければ多いほど、パフォーマンスがそれだけ上がります。 SDNET2018 データセットを全部ダウンロードし、それを利用してトレーニングします。
- データを拡張する:データに変化を与える一般的な手法は、画像にさまざまな変換 (回転、裏返し、移動、トリミング) を適用してデータを強化することです。 これでモデルが学習するサンプルに変化が与えられます。
- トレーニング時間を増やす:トレーニング時間が長ければ長いほど、モデルがそれだけ微調整されます。 エポックの数を増やすことで、モデルのパフォーマンスが上がることもあります。
- パイパーパラメーターで実験する:このチュートリアルで使用されているパラメーターに加え、他のパラメーターを微調整するとパフォーマンスが上がることがあります。 各エポック後のモデル更新の規模を決定する学習率を変更すると、パフォーマンスが上がることがあります。
- 別のモデル アーキテクチャを使用する:目で見たときのデータによっては、その特徴を最も効果的に学習できるモデルが異なることがあります。 モデルのパフォーマンスに不満が残る場合、アーキテクチャの変更をお試しください。
次の手順
このチュートリアルでは、転移学習、事前トレーニング済みの画像分類 TensorFlow モデル、ML.NET Image Classification API を利用してカスタム ディープ ラーニング モデルを構築し、コンクリートの表面の画像をひび割れあり/ひび割れなしに分類する方法について学習しました。
さらに詳しく学習するには、次のチュートリアルに進んでください。
.NET
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示