Exchange 2019 に推奨されるアーキテクチャ
オンプレミスのお客様向けのExchange Serverの新しいリリースごとに、優先アーキテクチャを更新し、お客様に認識していただきたい変更について説明します。 Exchange Server 2013 年は、最新の Exchange の歴史の中で最初の優先アーキテクチャを提供し、その後、2016 年のリリースに伴う変更の絞り込みを提供することで、Exchange Server 2016 の更新に続きました。 Exchange Server 2019 のこの更新プログラムでは、以前の PA を反復処理して、新しいテクノロジと機能強化を活用します。
推奨されるアーキテクチャ
PA は、オンプレミス環境で Exchange Server 2019 に最適なデプロイ アーキテクチャであると考える場合の、Exchange Server エンジニアリング チームのベスト プラクティスの推奨事項です。
Exchange 2019 では、オンプレミスの展開にさまざまなアーキテクチャの選択肢が用意されていますが、ここで説明するアーキテクチャは最も精査されています。 他にもサポートされているデプロイ アーキテクチャがありますが、推奨される方法ではありません。
PA に従うと、顧客は同様のExchange Server展開を持つ組織のコミュニティのメンバーになります。 この戦略により、知識の共有が容易になり、予期しない状況に対するより迅速な対応が提供されます。 Microsoft 独自のサポート組織は、Exchange Server PA 展開の外観を認識しており、サポート ケースの解決に向けて作業する前に、顧客の高度なカスタム環境の学習と理解に長いサイクルを費やすことを防ぎます。
PA は、アーキテクチャで次のことが可能な要件など、いくつかのビジネス要件を念頭に置いて設計されています。
データセンター内の高可用性とデータセンター間のサイトの回復性の両方を含める
各データベースの複数のコピーをサポートし、迅速なアクティブ化を可能にします
メッセージング インフラストラクチャのコストを削減する
障害ドメインを最適化し、複雑さを軽減することで可用性を向上させる
PA の具体的な規範的な性質は、すべての顧客が単語の単語を展開できるわけではないことを意味します。 たとえば、すべての顧客が複数のデータ センターを持っているわけではありません。 一部のお客様は、異なるビジネス要件や、異なるデプロイ アーキテクチャを必要とする、準拠する必要がある内部ポリシーを持っている場合があります。 これらのカテゴリに分類され、Exchange をオンプレミスに展開する場合は、PA にできるだけ密接に従い、要件やポリシーによって強制的に異なる場所にのみ逸脱する利点があります。 または、Microsoft 365 または Office 365を常に考慮して、多数のサーバーを展開または管理する必要がなくなりました。
PA は、アーキテクチャを予測可能な復旧モデルに駆動するために必要な複雑さと冗長性を排除します。障害が発生すると、影響を受けるデータベースの別のコピーがアクティブになります。
PA では、次の 4 つのフォーカス領域について説明します。
Exchange Server 2019 では、Exchange Server 2016 優先アーキテクチャの 4 つのカテゴリのうち 3 つに変更はありません。 名前空間の設計、データセンターの設計、DAG の設計の領域は、大きな変更を受け取っていません。 Microsoft は、Exchange Server 2016 PA に密接に従ったお客様のデプロイに満足しており、これらの分野の推奨事項から逸脱する必要はありません。
Exchange Server 2019 PA における最も注目すべき変更点は、いくつかの新しくエキサイティングなテクノロジによるサーバー設計の領域に焦点を当てています。
名前空間の設計
Exchange Server 2016 の名前空間の計画と負荷分散の原則に関する記事で、ロス スミス IV では、Exchange 2016 で利用できるさまざまな構成の選択肢について説明しました。これらの概念は引き続き Exchange Server 2019 に適用されます。 名前空間の場合は、 バインドされた名前空間 (ユーザーが特定のデータセンターから操作するための優先設定を持つ) または 非バインド名前空間 (ユーザーが好みなしで任意のデータセンターに接続できるようにする) をデプロイします。
推奨される方法は、無制限のモデルを使用し、サイト回復性の高いデータセンター ペアのクライアント プロトコルごとに 1 つの Exchange 名前空間を展開することです (各データセンターは、独自の Active Directory サイトを表していると見なされます)。詳細については、以下を参照してください)。 以下に例を示します。
自動検出サービスの場合: autodiscover.contoso.com
HTTP クライアントの場合: mail.contoso.com
IMAP クライアントの場合: imap.contoso.com
SMTP クライアントの場合: smtp.contoso.com
各 Exchange 名前空間は、セッション アフィニティを使用しないレイヤー 7 構成の両方のデータセンター間で負荷分散され、その結果、トラフィックの 50% がデータセンター間でプロキシされます。 トラフィックは、ラウンド ロビン DNS、geo DNS、またはその他の同様のソリューションを使用して、サイト回復性ペア内のデータセンター全体に均等に分散されます。 私たちの観点から見ると、よりシンプルなソリューションは最も複雑で管理が容易であるため、ラウンド ロビン DNS を使用することをお勧めします。
お客様に注意する必要がある 1 つは、Exchange アーキテクチャに関連付けられているすべての DNS レコードに低い TTL (有効期間) 値を割り当てることです。 ラウンド ロビン DNS を使用しているときにデータセンターの完全な停止が発生した場合は、DNS レコードを迅速に更新する機能を維持する必要があります。 DNS クエリに対して IP アドレスが返されないように、オフライン データセンターから IP アドレスを削除する必要があります。 たとえば、DNS レコードの TTL 値が 24 時間長い場合、ダウンストリーム DNS キャッシュが適切に更新されるまでに最大で 1 日かかることがあります。 この手順を実行しないと、一部のクライアントが残りのデータセンターで引き続き使用可能な IP アドレスに適切に移行できない場合があります。 以前にオフラインのデータセンターが復旧され、サービスをもう一度ホストする準備ができたら、IP アドレスを DNS レコードに追加し直してください。
データ センター アフィニティは、Office Online Server ファームに必要であるため、レイヤー 7 を利用し、Cookie ベースの永続化を使用してセッション アフィニティを維持するロード バランサーを使用して、データセンターごとに名前空間がデプロイされます。
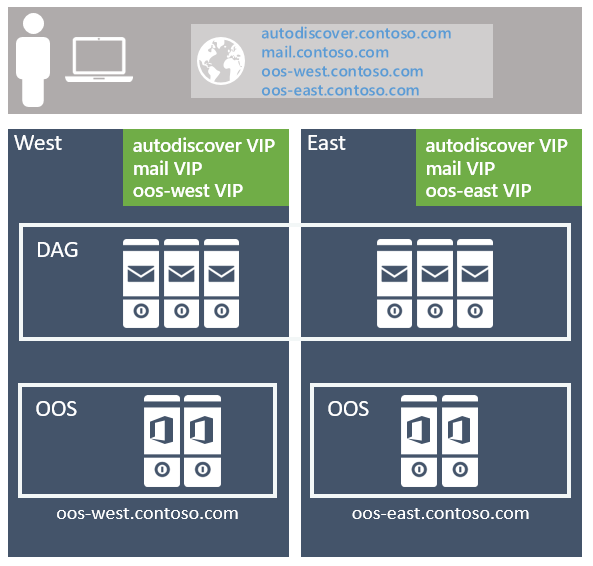
環境内にサイト回復性のデータセンター ペアが複数ある場合は、1 つのワールドワイド名前空間を使用するか、リージョン名前空間を使用して各特定のデータセンターへのトラフィックを制御するかを決定する必要があります。 決定は、ネットワーク トポロジと、非バインド モデルの使用に関連するコストによって異なります。たとえば、北米と南アフリカにデータセンターがある場合、これらのリージョン間のネットワーク リンクはコストがかかるだけでなく、待機時間が長くなる可能性があり、ユーザーの痛みや運用上の問題が発生する可能性があります。 その場合は、リージョンごとに個別の名前空間を持つバインドされたモデルをデプロイするのが理にかなっています。 ただし、地理的 DNS などのオプションを使用すると、コストのかかるネットワーク リンクがある場合でも、単一の統合名前空間をデプロイできます。geo-DNS を使用すると、ユーザーがクライアントの IP アドレスに基づいて最も近いデータセンターに誘導できます。
サイト回復性のあるデータセンター ペアの設計
高可用性 と サイト回復性を備えたアーキテクチャを実現するには、適切に接続されている 2 つ以上のデータセンターが必要です (理想的には、ラウンドトリップ ネットワーク待機時間が短く、それ以外の場合はレプリケーションとクライアント エクスペリエンスが悪影響を受ける必要があります)。 さらに、データセンターは、異なる運用通信事業者によって提供される冗長ネットワーク パスを介して接続する必要があります。
複数のデータセンターにまたがる Active Directory サイトのストレッチをサポートしていますが、PA では、各データセンターが独自の Active Directory サイトであることをお勧めします。 次の 2 つの理由があります。
Exchange ServerとExchange Serverのセーフティ ネットのシャドウ冗長性を介したトランスポート サイトの回復性は、DAG に複数の Active Directory サイトにメンバーが配置されている場合にのみ実現できます。
Active Directory では、サブネット間のラウンド トリップ待機時間が 10 ミリ秒を超える場合は、サブネットを異なる Active Directory サイトに配置する必要があることを示す ガイダンスが公開 されています。
サーバーの設計
PA では、すべてのサーバーが物理サーバーであり、ローカルに接続されたストレージを使用します。 物理ハードウェアは、仮想化されたハードウェアではなく、次の 2 つの理由でデプロイされます。
サーバーは、最悪の障害モード時にリソースの 80% を使用するようにスケーリングされます。
仮想化には若干のパフォーマンス低下が伴い、管理と複雑さのレイヤーが追加されます。特に、Exchange Serverは同じ機能をネイティブに提供するため、価値を追加しない追加の回復モードが導入されます。
コモディティ サーバー
コモディティ サーバー プラットフォームは PA で使用されます。 現在のコモディティ プラットフォームは次のとおりです。
最大 48 個の物理プロセッサ コアを備えた 2U のデュアル ソケット サーバー (Exchange 2016 の 24 コアからの増加)
最大 256 GB のメモリ (Exchange 2016 では 192 GB から増加)
バッテリを使用した書き込みキャッシュ コントローラー
サーバー シャーシ内の 12 つ以上のドライブ ベイ
従来の回転プラッタ ストレージ (HDD) とソリッド ステート ストレージ (SSD) を同じシャーシ内に混在させる機能。
スケール理論
2019 年Exchange Serverに許可されたプロセッサとメモリ容量を増やしたにもかかわらず、PG の推奨事項Exchange Serverは、スケールアップではなくスケールアウトする必要があることに注意することが重要です。 スケールアウトとスケールアップは、最大リソースを使用する高密度サーバーの数が少なく、多数のメールボックスが設定されるのではなく、サーバーあたりのリソースがわずかに少ない多数のサーバーをデプロイする方がはるかに多いことを意味します。 サーバー内に適切な数のメールボックスを配置することで、計画的または計画外の停止の影響を軽減し、他のシステムボトルネックを検出するリスクを軽減できます。
システム リソースが増加しても、Exchange 2016 の最大許可リソースと比較するときに、許可される最大リソースを使用して、Exchange Server 2019 で線形パフォーマンスが向上すると想定することはできません。 Exchange の新しい各バージョンでは、新しいプロセスと更新プログラムが提供され、現在のバージョンと以前のバージョンの比較が困難になります。 サーバーの設計を決定する際は、Microsoft のすべてのサイズ設定ガイダンスに従ってください。
ストレージ
メールボックスの数、メールボックスのサイズ、サーバーのリソースのスケーラビリティに応じて、追加のドライブ ベイがサーバーごとに直接接続される場合があります。
各サーバーには、オペレーティング システム、Exchange バイナリ、プロトコル/クライアント ログ、およびトランスポート データベース用の 1 つの RAID1 ディスク ペアが格納されます。
残りのストレージは JBOD (ディスクの束のみ) として構成されます。 一部のハードウェア ストレージ コントローラーでは、書き込みキャッシュを利用するために、各ディスクを単一ディスク RAID0 グループとして構成する必要がある場合があることに注意してください。 書き込みキャッシュが使用されることを保証するシステムの適切な構成を確認するには、ハードウェアの製造元に問い合わせてください。
Exchange Server 2019 PA の新機能は、前述の RAID1 ディスク ペアにまだ配置されていないすべてのストレージに 2 つのクラスのストレージを用意することをお勧めします。
従来のストレージ クラス
このストレージ クラスには、データベース ファイルとトランザクション ログ ファイルExchange Server Exchange Serverが含まれています。 これらのディスクは、7.2 K RPM シリアル接続 SCSI (SAS) ディスクの大容量です。 SATA ディスクも利用できる一方で、SAS と同等の機能を使用して、IO の向上と年単位の障害率の低下を確認しています。
各ディスクの容量と IO が可能な限り効率的に使用されるように、ディスクごとに最大 4 つのデータベース コピーがデプロイされます。 通常の実行時コピー レイアウトでは、ディスクごとにアクティブなデータベース コピーが 1 つ以上存在しないようにします。
従来のストレージ ディスク プール内の少なくとも 1 つのディスクは、ホット スペアとして予約されています。 AutoReseed は有効になっており、ホット スペアをアクティブ化し、データベース コピーの再シードを開始することで、ディスク障害の後にデータベースの冗長性をすばやく復元します。
ソリッドステート ストレージ クラス
このストレージ クラスには、Exchange 2019 の新しい MetaCache Database (MCDB) ファイルが含まれています。 これらのソリッドステート ドライブは、従来の 2.5"/3.5" SAS 接続ドライブや M.2 PCIe 接続ドライブなど、さまざまなフォーム ファクターで提供される場合があります。
お客様は、約 5 ~ 10% の追加ストレージをソリッドステート ストレージとしてデプロイする必要があります。 たとえば、1 台のサーバーが従来のストレージに 28 TB のメールボックス データベース ファイルを保持することが予想された場合は、同じサーバーの追加ストレージとして、さらに 1.4 ~ 2.8 TB のソリッドステート ストレージも推奨されます。
従来のディスクとソリッド ステート ディスクは、可能な場合は 3:1 の比率でデプロイする必要があります。 サーバー内の 3 つの従来のディスクごとに、単一のソリッド ステート ディスクがデプロイされます。 これらのソリッド ステート ディスクは、関連付けられている 3 つの従来のディスク内のすべての DB の MCDB を保持します。 この推奨事項は、ソリッドステート ドライブの障害によってシステムに課される障害ドメインを制限します。 SSD が失敗すると、Exchange 2019 は、その MCDB 用の SSD を使用するすべてのデータベース コピーを、影響を受けるデータベースの正常な MCDB リソースを持つ別の DAG ノードにフェールオーバーします。 データベース フェールオーバーの数を制限すると、より多くのデータベースが少数のソリッド ステート ドライブを共有していた場合に、ユーザーに影響を与える可能性が低くなります。
ソリッドステート ドライブの障害が発生した場合、Exchange 高可用性サービスは、影響を受けるデータベースごとに正常な MCDB がまだ存在する異なる DAG ノードに、影響を受けるデータベースのマウントを試みます。 影響を受けるいずれかのデータベースに何らかの理由で正常な MCDB が存在しない場合、Exchange 高可用性サービスは、影響を受けるローカルデータベースのコピーを MCDB のパフォーマンス上の利点なしに実行したままにします。
たとえば、お客様が 20 台のドライブを保持できるシステムを展開する場合、次のようなレイアウトになる場合があります。
OS ミラー、Exchange バイナリ、トランスポート データベース用の 2 つの HDD
Exchange Database ストレージ用の 12 個の HDD
オートリート スペアとして 1 HDD
4 つの Exchange MCDB 用 SSD。累積データベース ストレージ容量の 5 ~ 10% を提供します。
必要に応じて、お客様は予備の SSD または 2 台目の AutoReseed ドライブの追加を選択できます。
この構成は、次の図を使用して視覚化できます。
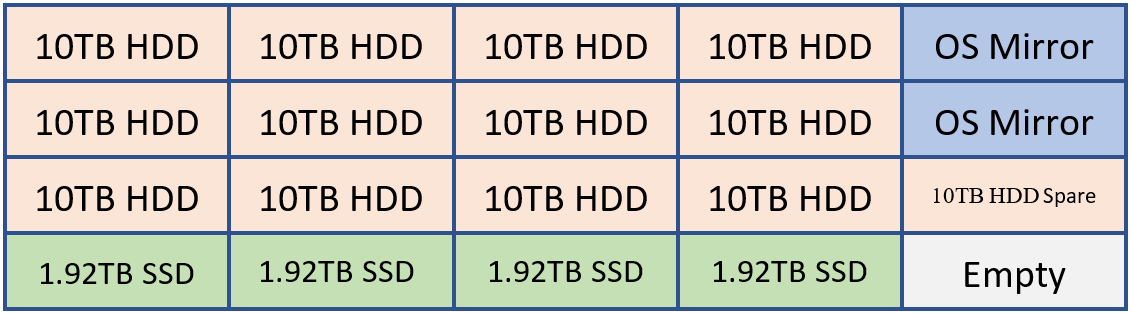
上の例では、120 TB の Exchange データベース ストレージと 7.68 TB の MCDB ストレージがあり、従来のデータベース ストレージ領域の約 6.4% です。 この量の MCBD ストレージを使用すると、5 ~ 10% のガイダンス内で完全に調整されます。 10 TB ドライブはそれぞれ 4 つのデータベース コピーを保持し、各 MCDB ドライブは 12 MCDB を保持します。
一般的なストレージ設定
従来のディスクでもソリッドステートでも、Exchange データを格納するすべてのディスクは ReFS でフォーマットされ (整合性機能が無効になっています)、DAG は AutoReseed が ReFS でディスクをフォーマットするように構成されます。
Set-DatabaseAvailabilityGroup -Identity <DAGIdentity> -FileSystem ReFS
BitLocker は、各ディスクの暗号化に使用され、保存時のデータ暗号化を提供し、データの盗難やディスクの交換に関する懸念を軽減します。 詳細については、「 Exchange Server での BitLocker の有効化」を参照してください。
データベース可用性グループの設計
サイト回復性のある各データセンター ペア内には、1 つ以上の DAG があります。 2 つ以上のデータセンターに DAG をストレッチすることはお勧めしません。
DAG 構成
名前空間モデルと同様に、サイト回復性のあるデータセンター ペア内の各 DAG は非バインド モデルで動作し、アクティブなコピーは DAG 内のすべてのサーバーに均等に分散されます。 このモデル:
各 DAG メンバーのサービスの完全なスタック (クライアント接続、レプリケーション パイプライン、トランスポートなど) が、通常の操作中に検証されていることを確認します。
障害シナリオ中にできるだけ多くのサーバーに負荷を分散し、DAG 内の残りのメンバー間でリソースの使用量を段階的に増やすだけです。
各データセンターは対称であり、各データセンターに同じ数の DAG メンバーが含まれます。 つまり、各 DAG には偶数のサーバーがあり、クォーラムメンテナンスに監視サーバーが使用されます。
DAG は、Exchange 2019 の基本的な構成要素です。 DAG サイズに関しては、参加するメンバー ノードの数が多い DAG により、冗長性とリソースが増えます。 PA 内で目標は、メンバー ノードの数が多い DAG をデプロイすることです。通常は 8 メンバー DAG から始まり、要件を満たすために必要に応じてサーバーの数を増やします。 スケーラビリティによって既存のデータベース コピー レイアウトに関する懸念が生じる場合にのみ、新しい DAG を作成する必要があります。
DAG ネットワーク設計
PA は、クライアント接続とデータ レプリケーションの両方に、チーム化されていない 1 つのネットワーク インターフェイスを使用します。 単一のネットワーク インターフェイスが必要なのは、最終的には、障害に関係なく標準復旧モデルを実現することです。サーバー障害が発生した場合でも、ネットワーク障害が発生した場合でも、結果は同じです。DAG 内の別のサーバーでデータベース コピーがアクティブ化されます。 このアーキテクチャの変更により、ネットワーク スタックが簡素化され、ハートビートクロストークを手動で排除する必要がなくなります。
ミラーリング監視サーバーの配置
監視サーバーの配置により、アーキテクチャでデータセンターの自動フェールオーバー機能を提供できるかどうか、またはサイト障害が発生した場合にサービスを有効にするために手動によるライセンス認証が必要かどうかが決まります。
DAG が展開されているサイト回復性のあるデータセンター ペアに影響を与えるネットワーク 障害から分離されたネットワーク インフラストラクチャを持つ 3 番目の場所が組織にある場合は、その 3 番目の場所に DAG の監視サーバーを展開することをお勧めします。 この構成により、DAG は、障害が発生したデータセンターに関係なく、データセンター レベルの障害イベントに応答して、データベースを他のデータセンターに自動的にフェールオーバーできます。
組織に 3 番目の場所がない場合は、サーバー監視を Azure に配置することを検討してください。または、サイト回復性のあるデータセンター ペア内のいずれかのデータセンターにミラーリング監視サーバーを配置します。 サイト回復性のあるデータセンター ペア内に複数の DAG がある場合は、すべての DAG の監視サーバーを同じデータセンター (通常は、ほとんどのユーザーが物理的に配置されているデータセンター) に配置します。 また、各 DAG のプライマリ Active Manager (PAM) も同じデータセンターに配置されていることを確認します。
Exchange Server 2019 以前のすべてのバージョンでは、Windows Server 2016 フェールオーバー クラスターで最初に導入されたクラウド監視機能の使用はサポートされていません。
データの回復性
データの回復性は、複数のデータベース コピーをデプロイすることによって実現されます。 PA では、データベース コピーがサイト回復性のあるデータセンター ペア全体に分散されるため、メールボックス データがソフトウェア、ハードウェア、さらにはデータセンターの障害から保護されます。
各データベースには 4 つのコピーがあり、各データセンターには 2 つのコピーがあります。つまり、少なくとも PA には 4 つのサーバーが必要です。 これら 4 つのコピーのうち、3 つは高可用性として構成されています。 4 番目のコピー (アクティブ化の基本設定番号が最も大きいコピー) は、遅延データベース コピーとして構成されます。 サーバーの設計により、データベースの各コピーは他のコピーから分離されるため、「 DAG: "A" を超えて」で説明されているように、障害ドメインが減り、ソリューションの全体的な可用性が向上します。
遅延データベース コピーの目的は、システム全体で致命的な論理破損が発生するまれな場合の復旧メカニズムを提供することです。 これは、個々のメールボックスの回復やメールボックスアイテムの回復を目的としたものではありません。
遅延データベース コピーは、7 日間の ReplayLagTime で構成されます。 さらに、Lag Manager の再生は、遅延のないコピーが失われたために可用性が損なわれた場合に、遅延コピーに対して動的ログ ファイルの再生を提供することもできます。
この方法でラグされたデータベース コピーを使用することで、遅延データベース コピーは保証されたポイントインタイム バックアップではないことを理解することが重要です。 遅延したデータベース コピーには、ディスク障害が原因で遅延コピーを含むディスクが失われる期間、ラグされたコピーが HA コピーになる (自動再生が原因)、ラグされたデータベース コピーが再生キューを再構築している期間が原因で、通常は約 90% の可用性しきい値が設定されます。
誤った (または悪意のある) アイテムの削除から保護するために、 単一アイテムの回復 または インプレース ホールド テクノロジが使用され、[ 削除済みアイテムの保持] ウィンドウは、定義された項目レベルの回復 SLA を満たす値または超える値に設定されます。
これらのテクノロジがすべて実行されるため、従来のバックアップは不要です。その結果、PA は Exchange Native Data Protection を使用します。
Office Online Server設計
少なくとも、Exchange 2019 サーバーをホストする各データセンターに、少なくとも 2 つの OOS ノードを含むOffice Online Server (OOS) ファームを展開する必要があります。 各Office Online Serverには、少なくとも 8 つのプロセッサ コア、32 GB のメモリ、およびログ ファイル専用の少なくとも 40 GB の領域が必要です。 Exchange 2019 メールボックス サーバーは、データセンター内のローカル OOS ファームに依存するように構成して、ファイル コンテンツをユーザーにレンダリングするために、サーバー間で可能な限り短い待機時間と可能な限り高い帯域幅を確保する必要があります。
概要
Exchange Server 2019 年は、以前のバージョンの Exchange で導入された投資を引き続き改善し、Microsoft 365 およびOffice 365で使用するために最初に発明された追加のテクノロジを導入しています。
優先アーキテクチャに合わせることにより、これらの変更を活用し、可能な限り最適なオンプレミス ユーザー エクスペリエンスを提供します。 信頼性が高く、予測可能で回復力の高い Exchange 展開を行うという伝統を続けます。