業界データ API を抽出、変換、読み込み (ETL) エンジン (プレビュー) として使用する
重要
Microsoft Graph の /beta バージョンの API は変更される可能性があります。 実稼働アプリケーションでこれらの API を使用することは、サポートされていません。 v1.0 で API を使用できるかどうかを確認するには、Version セレクターを使用します。
業界データ API は、複数のソースのデータを 1 つの Azure Data Lake データ ストアに結合し、データを正規化し、送信フローでエクスポートする、Education 業界に重点を置いた ETL (Extract-Transform-Load) プラットフォームです。 API には、データの処理後の統計の取得に使用できるリソースが用意されており、監視とトラブルシューティングに役立ちます。
業界データ API は、OData サブネームスペース で定義されています microsoft.graph.industryData。
業界データ API と教育
業界データ API は、Microsoft 学校データ同期 (SDS) プラットフォームを活用して、学生情報システム (SIS) と学生管理システム (SMS) からMicrosoft Entra IDと Microsoft 365 を使用して組織、ユーザー、ユーザーの関連付け、グループをインポートし、同期するプロセスを自動化するのに役立ちます。 データを正規化した後、API は複数の送信プロビジョニング フローを通じてデータを利用して、ユーザー、クラス グループ、管理単位、およびセキュリティ グループを管理します。
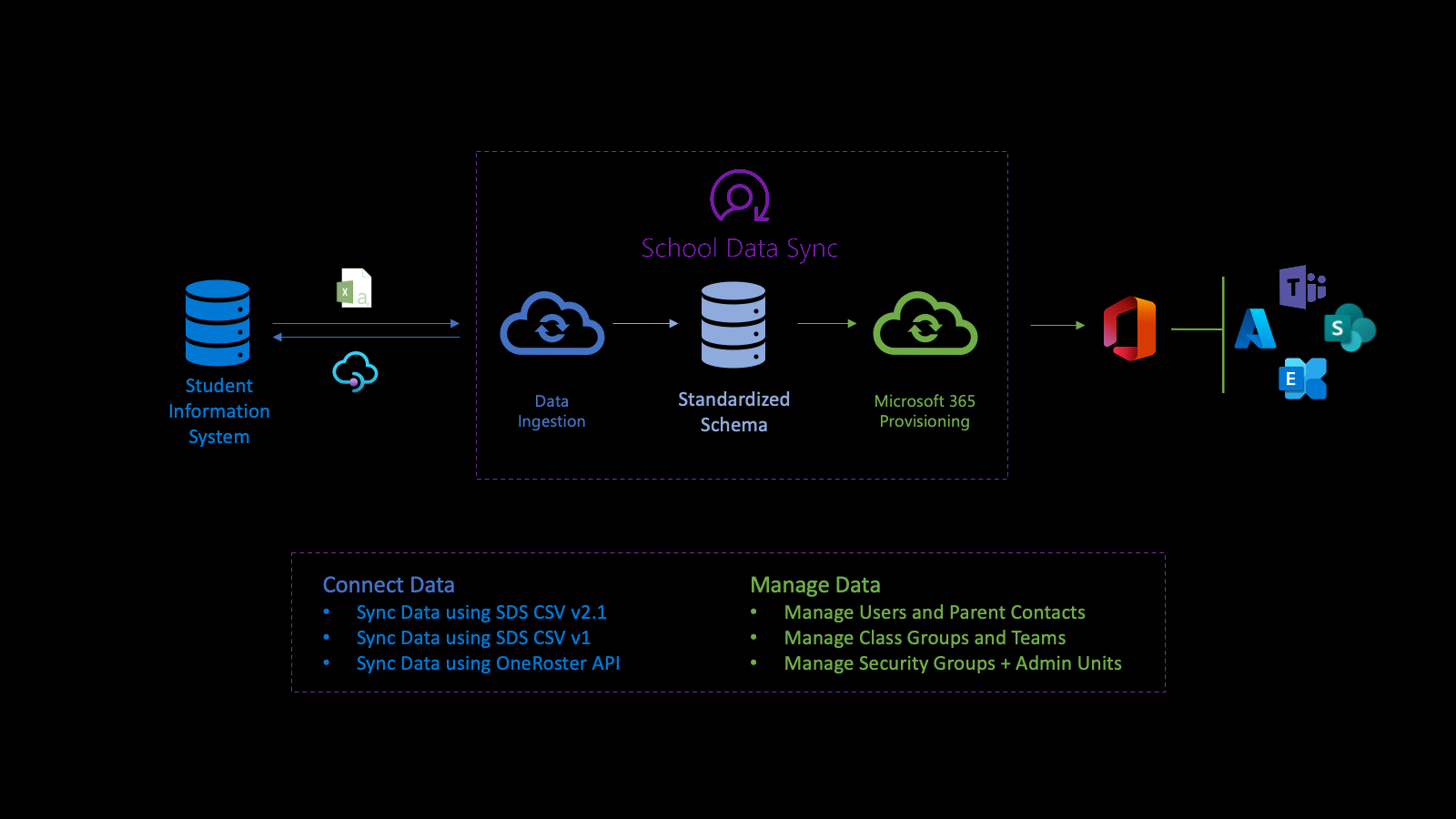
まず、教育機関のデータに接続します。 受信フローを定義するには、 sourceSystemDefinition、 dataConnector、 yearTimePeriodDefinition を作成します。 既定では、受信フローは 1 日に 2 回 ( 実行と呼ばれます) アクティブ化します。
実行が開始されると、受信フローの sourceSystemDefinition と dataConnector に接続し、基本的な検証を実行します。 基本的な検証では、 OneRoster API がソースの場合は接続が正しく、CSV がソースの場合はファイル名とヘッダーが正しいことを確認します。
次に、高度な検証に備えて、インポート用のデータが変換されます。 データ変換の一環として、構成された yearTimePeriodDefinition に基づいてデータが関連付けられます。
システムは、テナントのMicrosoft Entra IDの最新のコピーを Azure Data Lake に格納します。 Microsoft Entraのコピーは、sourceSystemDefinition と Microsoft Entra ユーザー オブジェクトの間のユーザー マッチングに役立ちます。 この段階では、一致リンクは Azure Data Lake にのみ書き込まれます。
次に、受信フローは高度な検証を実行してデータの正常性を判断します。 検証では、エラーと警告を特定して、適切なデータが入り込み、不適切なデータが出ないようにすることに重点を置いています。エラーは、レコードが検証に合格せず、それ以上の処理から削除されたことを示します。 警告は、レコードの省略可能なフィールドの値が渡されなかったことを示します。 値はレコードから削除されますが、さらに処理するためにレコードが含まれます。
エラーと警告は、データの正常性をより深く理解するのに役立ちます。
検証に合格したデータの場合、プロセスでは、次のように、構成された yearTimePeriodDefinition を使用して、縦方向ストレージの関連付けを決定します。
- データはテナントの Azure Data Lake に内部表現が格納されるため、業界データによって最初に表示されたタイミングを識別します。
- ユーザー organization、ロールの関連付け、グループの関連付けとリンクされたデータの場合、yearTimePeriodDefinition に基づいて、セッションでアクティブなデータとして識別されます。
- 今後の実行では、同じ受信フロー、 sourceSystemDefinition、 yearTimePeriodDefinition について、レコードがまだ表示されているかどうかを業界データで識別します。
- レコードの有無に基づいて、レコードはアクティブに保持されるか、構成された yearTimePeriodDefinition のセッションでアクティブではなくなったとマークされます。 このプロセスは、日、月、年の間のデータの履歴と縦方向の性質を決定します。
各実行の最後に、データの正常性を判断するために industryDataRunStatistics を使用できます。
industryDataRunStatistics に関連するエラーと警告は、データ正常性の初期理解に役立つよう生成されます。 データの正常性を調査すると、業界データは、データ調査プロセスを開始するために検出されたエラーと警告に基づく情報を含むログ ファイルをダウンロードして、ソース システム内のデータを修正する機能を提供します。
データエラーや警告を調査して対処した後、データ正常性の現在の状態に慣れている場合は、データを使用してシナリオを有効にすることができます。 このデータを使用するシナリオを有効にすると、シナリオによって送信プロビジョニング フローが作成されます。
送信プロビジョニング フローを使用してデータを管理すると、ユーザーとクラスの管理が簡略化されます。 Microsoft Entra ユーザー オブジェクトへのリンクの書き込みに使用されるデータには、アクティブなユーザーと一致したユーザーのみが含まれます。 このリンクを使用すると、グループと Microsoft Teams クラスルームの SIS/SMS とそのセクション間の統合が容易になります。
詳細については、「School Data Sync、SDS の前提条件、および School Data Sync の概要の SDS コア概念」セクションを参照 してください。
登録、アクセス許可、および承認
業界データ API をサード パーティ製アプリと統合できます。 これを行う方法の詳細については、次の記事を参照してください。
- 認証と承認の基本。
- アプリケーションをMicrosoft ID プラットフォームに登録します。
- ユーザーの代わりにアクセス権を取得します。
- Microsoft Graph のアクセス許可リファレンス。
- Microsoft Graph 承認エラーを解決します。
一般的なユース ケース
| ユース ケース | REST リソース | 関連項目 |
|---|---|---|
| 区切られたデータ セットをインポートするアクティビティを作成する | inboundFileFlow | inboundFileFlow メソッド |
| 受信データのソースを定義する | sourceSystemDefinition | sourceSystemDefinition メソッド |
| Azure Data Lake にデータを投稿するコネクタを作成する (CSV の場合) | azureDataLakeConnector | azureDataLakeConnector メソッド |
データ ドメイン
dataDomain プロパティは、インポートされるデータの種類を定義し、格納する一般的なデータ モデル形式を決定します。 現在、サポートされている dataDomain は educationRosteringのみです。
参照定義
referenceDefinition は列挙値を表します。 サポートされている各業界ドメインは、定義の個別のコレクションを受け取ります。 referenceDefinition リソースは、構成と変換の両方でシステム全体で広く使用され、潜在的な値は特定の業界に固有です。 各 referenceDefinition では、 の {referenceType}-{code} 複合識別子を使用して、顧客テナント間で一貫性のあるエクスペリエンスを提供します。
参照値
referenceValue に基づく型は、referenceDefinition リソースをバインドするための簡略化された開発者エクスペリエンスを提供します。 各 referenceValue 型は 1 つの参照型にバインドされるため、開発者は参照定義の コード 部分のみを単純な文字列として指定でき、特定のプロパティが予期される referenceDefinition の種類に関する混乱を排除できます。
例
userMatchingSettings.sourceIdentifier プロパティは、referenceType にバインドする identifierTypeReferenceValue 型をRefIdentifierType受け取ります。
"sourceIdentifier": {
"code": "username"
},
referenceDefinition は、value プロパティを使用して直接バインドされる場合もあります。
"sourceIdentifier": {
"value@odata.bind": "external/industryData/referenceDefinitions/RefIdentifierType-username"
},
役割グループ
データの変換は、多くの場合、organization内の個々のユーザーの役割によって形成されます。 これらのロールは参照定義として定義されます。 潜在的なロールの数を考えると、各ロールを個々にバインドすると、面倒なユーザー エクスペリエンスが発生します。 ロール グループ は、コードの RefRole コレクションです。
{
"@odata.type": "#microsoft.graph.industryDataRoleGroup",
"id": "37a9781b-db61-4a3c-a3c1-8cba92c9998e",
"displayName": "Staff",
"roles": [
{ "code": "adjunct" },
{ "code": "administrator" },
{ "code": "advisor" },
{ "code": "affiliate" },
{ "code": "aide" },
{ "code": "alumni" },
{ "code": "assistant" }
]
}
業界データ コネクタ
industryDataConnector は、sourceSystemDefinition と inboundFlow の間のブリッジとして機能します。 外部ソースからデータを取得し、受信データ フローにデータを提供する責任があります。
CSV データのアップロードと検証
CSV データの詳細については、次を参照してください。
CSV ファイルの要件を次に示します。
- ファイル名と列ヘッダーでは、大文字と小文字が区別されます。
- CSV ファイルは UTF-8 形式である必要があります。
- 受信データに改行を含めてはいけません。
SDS V2.1 CSV ファイルのサンプル セットを確認してダウンロードするには、 SDS GitHub リポジトリを参照してください。
重要
industryDataConnector は差分変更を受け入れないので、各アップロード セッションには完全なデータ セットが含まれている必要があります。 部分データまたは差分データのみを指定すると、欠落しているレコードが非アクティブ状態に遷移します。
アップロード セッションを要求する
azureDataLakeConnector は、セキュリティで保護されたコンテナーにアップロードされた CSV ファイルを使用します。 このコンテナーは 1 つの fileUploadSession のコンテキスト内に存在し、データ検証またはファイル アップロード セッションの有効期限が切れた後に自動的に破棄されます。
現在のファイルアップロード セッションは、CSV ファイルをアップロードするための SAS URL を返す getUploadSession を介して azureDataLakeConnector から取得されます。
アップロードされたファイルを検証する
アップロードされたデータ ファイルは、受信フローでデータを処理する前に検証する必要があります。 検証プロセスは、現在の fileUploadSession を終了し、必要なすべてのファイルが存在し、適切に書式設定されていることを確認します。 検証は、industryDataConnector: azureDataLakeConnector リソースの検証アクションを呼び出すことによって開始されます。
validate アクションでは、実行時間の長い fileValidateOperation が作成されます。 fileValidateOperation の URI は、応答のLocationヘッダーで提供されます。 この URI を使用して、実行時間の長い操作の状態と、検証中に作成されたすべてのエラーまたは警告を追跡できます。
次の手順
抽出、変換、読み込み (ETL) エンジンとして Microsoft Graph 業界のデータ API を使用します。 詳細情報
- 自分のシナリオに最も役立つリソースと方法を検討する。
- Graph エクスプローラーで API を試す。
関連コンテンツ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示