Apache Cassandra
Apache Cassandra は、完全分散型の構造化されたキー値ストレージ システムです。 Cassandra では、HBase と Amazon の一連のストレージ手法 (Dynamo と呼ばれます) の両方優れた部分が組み合わされています。3 Cassandra では、HBase のデータ モデルと、Dynamo の実装アーキテクチャが使用されています。 Cassandra については、次のビデオでも説明されています。
Cassandra のデータ モデル
Cassandra では、前のユニットで説明したように、HBase のデータ モデルが実装されていますが、用語は少し異なります。
Cassandra のテーブルは列ファミリと呼ばれます (Apache HBaseの 列ファミリと混同しないようにしてください。HBase の列ファミリは、テーブル内の関連付けられた列のグループです。図 7a を参照してください)。 レコード (つまり行) は、キーと値のペアとして扱われます。キーはレコードの識別特性となります。 値は、やはりキーと値のペア (複数のペアのセット) と見なされます。この場合、各キーは各列の名前であり、各値は列の値です (図 7b)。
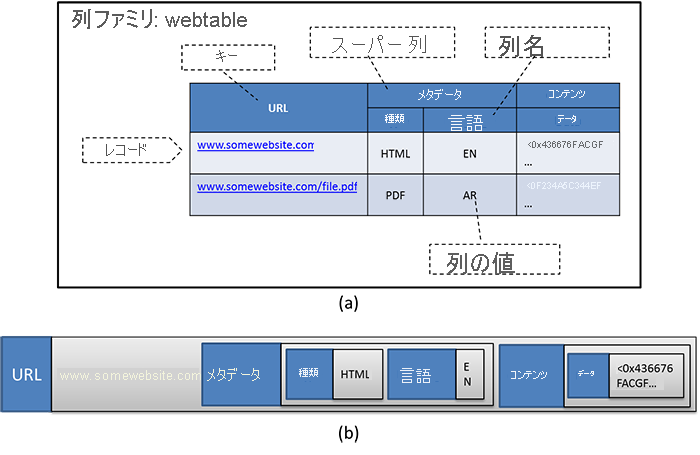
図 7: Cassandra のデータ モデル。 (a) Cassandra 内の Web テーブルの論理ビュー。 (b) テーブルの行 (入れ子になった "キーと値のペア" のシーケンスとして表されます)。
HBase と同様、Cassandra では、入れ子になった列 (スーパー列) も使用できます。 Cassandra のスーパー列は、入れ子になった "キーと値のペア" として実装されます。スーパー列名がキーで、値は、各列の名前と値に対応する "キーと値のペア" のシーケンスです。
Cassandra では、キーと値の各ペアの、キーまたは値の部分にデータを保存できます。 必要に応じて、列名やスーパー列名に値を保存することもできます。 Cassandra の一般的な操作としては、キーを使用して個々の行を保存/取得する操作や、行の一部を更新する操作があります。 そのため、Cassandra のデータ モデルは HBase に似ており、非常に柔軟性が高く、さまざまな種類のデータを保存することができます。 HBase と Cassandra のデータ モデルの大きな違いは、Cassandra では、HBase のようなバージョン管理が組み込みでサポートされていないという点です。
Cassandra では、HBase に似たデータ操作がサポートされていますが、いくつかの例外もあります。 Cassandra の一般的な操作は、Gets、Inserts、および Deletes で表されます。 操作は、1 行または一連の行 (範囲) に対して実行できます。 また、操作は、データベースの一連の列 (スライス) に対しても実行できます。
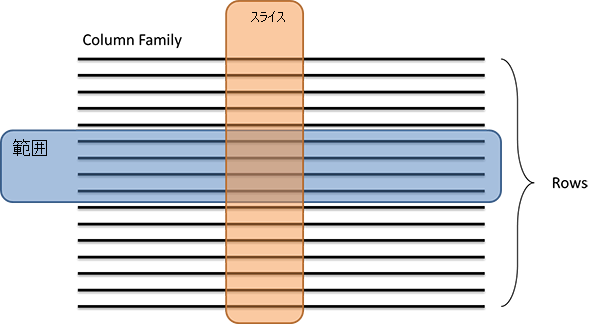
図 8:Cassandra の範囲とスライス
Cassandra のアーキテクチャ
分散データ ストアである Cassandra は、HBase と同様、複数のノードのクラスター上で動作するように設計されています。 ただし、HBase とは異なり、Cassandra では分散アーキテクチャが採用されています (つまり、プライマリ/セカンダリ アーキテクチャは存在せず、Cassandra 内のすべてのノードが同じロールになります)。これは、Cassandra が単一障害点 (SPOF) のない設計になっていることを意味します。 HBase は耐障害性を備えた設計となっていますが、永続的ストレージについては Hadoop の分散ファイル システム (HDFS) に依存しており、NameNode が SPOF となります。 Cassandra では、基盤となる分散ファイル システム (DFS) が必要ありません。Cassandra クラスター内のノードでは、各ノードのローカル ストレージが使用されます。 Cassandra のクラスター ノード間の調整は、ピアツーピア方式で処理されます。
Cassandra でのデータ分散
Cassandra では、データの読み取りや書き込みに対するクライアントの要求を、クラスター内の任意のノードで処理できます。 Cassandra の列ファミリに行が挿入されると、それらの行はクラスター内の異なるノード間で自動的に分散されます。 ただし、行の分散に使用される手法は、HBase での行の分散方法とは大きく異なります。 Cassandra のデータは、コンシステント ハッシュ法という方法を使用して、行のキーのハッシュ値に基づいてノード間で分散されます。
コンシステント ハッシュ法
Cassandra では、各行のキーのハッシュ値を使用して、クラスター内のさまざまなノード間で行が自動的に分散されます。 既定では、Cassandra は、各行のキーに対してメッセージ ダイジェスト 5 (MD5) というハッシュ アルゴリズムを使用し、128 ビット長のハッシュが生成されます。 行がクラスターのどこに保存されるかは、キーのハッシュ値によって決まります。 Cassandra クラスター内のノード間で行を均等に分散するために、クラスター内の各ノードには一意のトークンが割り当てられます。 トークンは、各ノードに割り当てられるハッシュ値の範囲です。 既定では、ノード トークンの値の範囲は 0 ~ 2127 です。これが、クラスター内のノードの数で均等に分割されます。 クラスターのすべてのノードのコレクションは、集合的にトークン リングと呼ばれ、ノードが順番に配置されます。 トークン リング内のすべてのノードでは、トークン リング内の他のノードと、自身が担当するハッシュ値の範囲が認識されます。 次の図は、これを説明したものです。
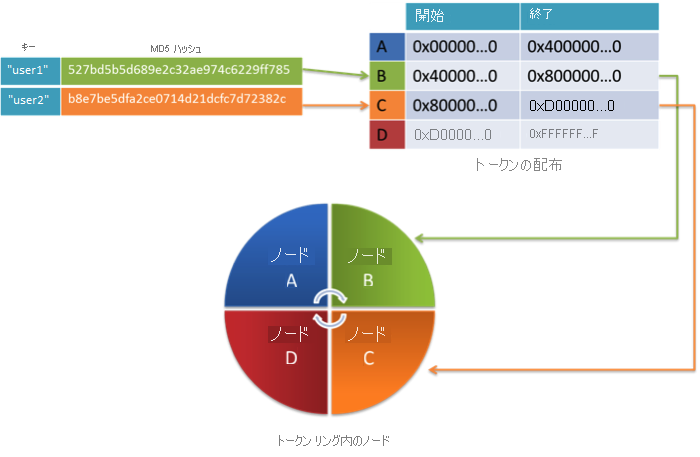
図 9:コンシステント ハッシュ法でハッシュ値の循環リングとして構成されたノード
この例では、キー user1 には、16 進値 5で始まる MD5 ハッシュ値があります。 トークン リング内のこの範囲に適合するノードは B です (これが、0x4 から 0x8 までのハッシュ値を受け入れます)。 したがって、キー user1 を持つ行はノード B に保存されます。同様に、user2 はハッシュ値が Bで始まるので、ノード C に保存されます。ノード C は、0x8 から 0xDのすべての値を処理します。
なお、重要な点として、Cassandra の管理者は、ノード間でトークン領域を手動でパーティション分割し、ハッシュ空間の特定の範囲を任意のノードに割り当てることができます。 このように、Cassandra のクラスターでは、コンシステント ハッシュ法によって自然な負荷分散メカニズムが提供されます。 次は、コンシステント ハッシュ法のスキームによって、Cassandra クラスターのレプリケーションとフォールト トレランスがどのように実現されのるかについて見ていきましょう。
レプリケーション
Cassandra のデータ分散ポリシーでは、クラスター内のノード間でデータが均等に分散されますが、いずれのノードでエラーが発生した場合は、そのノードに保存されている行が失われる可能性があります。 Cassandra では、ノード障害に対する冗長性を確保するために、行が複数のノードにレプリケートされます。これは、レプリケーション係数 (既定では 1) によって定義された方法で実行されます。 Cassandra では、レプリカの配置について、ラック認識型の戦略と、ラックを認識しない戦略の両方が提供されています。 最初のレプリカは常に、上記で説明したコンシステント ハッシュ法に基づいて配置されます。
たとえば、指定されたレプリケーション係数が $N$ であるとします。 最初のレプリカは常に、上記で説明したコンシステント ハッシュ法を使用して配置されます。 ラック認識型の戦略では、2 番目のレプリカは、常に別のデータセンターに配置される (Cassandra クラスターが複数のデータセンターにまたがっている場合) か、または最初のレプリカとは別のラックに配置されます。 残りのレプリカは、1 つ目と同じラックにあるノードに、トークン リング内でのノードの順序で配置されます。 ラックを認識しない戦略の場合は、レプリカは単純に、トークン リング内の次の $N - 1$ ノードに配置されます。
ノードは、いつでも Cassandra クラスターに追加できます。これは 2 つの方法のいずれかで処理されます。 1 つは、管理者が新しい受信ノードのトークンを手動で再割り当てする方法です。もう 1 つの方法は、データの最も多いノードを Cassandra によって自動的に検出し、そのトークンを半分に分割して、ハッシュ空間の半分を新しい受信ノードに割り当てる方法です。 新しいノードは要求をすぐに受け入れることができないので、まずリングのトポロジを学習し、自身も担当する可能性があるデータを受け入れます。 それが完了すると、完全なメンバーとしてリングに参加し、要求の受け入れを開始できるようになります。 その後、Cassandra によって、データがクラスター内のノード間で再シャッフルされます。
Cassandra でレプリカを最新の状態に保つプロセスは、アンチエントロピと呼ばれます。 Cassandra のアンチエントロピは、Merkle ツリーを使用して達成されます。 Merkle ツリー1 (図 10) は、リーフが個々のキーの値のハッシュとなっているハッシュ ツリーです。 ツリーの上位にある親ノードは、それぞれの子のハッシュです。 Merkle ツリーの主な利点は、分岐全体をスキャンしなくても、ツリーの各分岐を個別にチェックできることです。 Cassandra では、列ファミリごとに Merkle ツリーを定期的に計算し、それをレプリカ メンバー間で交換してテーブル内の相違をすばやく計算することで、それらを相互に同期できるようになってます。 Cassandra の他の手法と比べると、アンチエントロピは多くの場合には実行されない高コストな操作です。 Cassandra には、読み取り中にレプリカに対して瞬時に修復を実行する手法もあります (読み取り修復と呼ばれます。これについては後で説明します)。

図 10:Merkle ツリー
Cassandra でのデータ操作
書き込み操作
書き込み操作が Cassandra ノードに送信されると、操作がそのノードのコミット ログ (ローカル ファイル システム上) に書き込まれます。 コミット ログは、クラッシュが発生した場合に書き込み操作を確実に復旧できるようにするためのジャーナルの一種です。 その後、書き込みは memtable に転送されます。memtable は、メモリに常駐するデータ構造 (キャッシュの一種) です。 memtable を使用すると、データをメモリ常駐型にすることができます。これにより、以降の操作ではメモリから直接値を読み取って、パフォーマンスを向上させることができます。 memtable のサイズが特定のしきい値に達すると、SSTable というファイル内のディスクにフラッシュされ、新しい memtable が作成されます。 フラッシュ操作は非ブロッキングなので、その Cassandra ノードに対する他の操作は、フラッシュが完了するまで続行を待機する必要はありません。
削除操作
削除操作は、削除する値に廃棄標識 (削除マーカー) を配置する更新操作として扱われます。つまり、データはすぐには Cassandra から削除されず、削除対象としてマークされます (これは、論理的な削除とも呼ばれます)。 ガベージ コレクションの猶予秒数の値に達するまで、値は削除されません。既定では、この値は 864,000 秒 (約 10 日) になります。 ガベージ コレクションのしきい値の有効期限が切れると、廃棄標識は期限切れとしてマークされます。
圧縮操作
Cassandra インスタンスの実行中には、(多くのフラッシュによって) 複数の SSTables が収集されている可能性があります。 圧縮と呼ばれる操作は、複数の SSTables からのデータをマージするために定期的に実行されます。 圧縮操作では、キーがマージされ、列がマージされ、期限切れの廃棄標識が削除された後、新しいインデックスが作成されます。
読み取り操作
Cassandra クラスターからデータを読み取る場合、クライアントはクラスター内の任意のノードに接続します。その後、クライアントによって指定された一貫性レベルに基づいて、クライアント内の複数のノードに読み取り要求が転送されます。 この読み取り操作は、必要な一貫性レベルが確保されるまでブロックされます。 ノードの一部が古い値で応答した場合は、最も新しい値がクライアントに返されます。 その後、Cassandra によって、読み取り修復操作が実行されます。 この操作は、前に説明した定期的なアンチエントロピ操作に加えて行われるものです。 読み取り修復操作によって、レプリカは最新の状態になります。 読み取り修復は、読み取り時に指定された一貫性レベル (次に説明します) に従って実行されます。
調整可能な一貫性
他の NoSQL データベース システムとは異なり、Cassandra には調整可能な一貫性モデルがあります。 Cassandra に読み取り操作や書き込み操作の要求を行うアプリケーションでは、その操作について Cassandra から提供される必要がある、一貫性レベルを指定できます。 つまり、各操作に必要な一貫性レベルを、アプリケーションが指定できるということです。 Cassandra では、次の表に示すように、最大 5 つの一貫性レベルがサポートされています。
| 一貫性レベル | 読み取りの場合の意味 | 書き込みの場合の意味 |
|---|---|---|
| ZERO | 読み取りではサポートされていません。 | 書き込み操作は、確認なしで直ちに返されます。 |
| ANY | 読み取りではサポートされていません。代わりに ONE を使用してください。 | 少なくとも 1 つのノードによって書き込み操作がコミットされます。この場合、ヒント (後で説明します) は書き込みとしてカウントされます。 |
| ONE | クエリに応答する最初のノードに保持されているレコードを直ちに返します。 読み取り要求が実行された後、レプリカに一貫性がない場合は、読み取り修復を実行します。 | クライアントに戻る前に、少なくとも 1 つのノードのコミット ログと memtable に値が書き込まれていることを確認します。 |
| QUORUM | すべてのノードを照会します。 大部分のレプリカ $(\frac{replication\ factor}{2} + 1)$ が応答した後、タイムスタンプが最新である値をクライアントに返します。 その後、必要に応じて、残りのすべてのレプリカのバックグラウンドで読み取り修復を実行します。 応答は、読み取り修復が完了した後にのみ送信されます。 | 少なくとも過半数のレプリカ $(\frac{replication\ factor}{2} + 1)$ によって書き込みが受信されたことを確認します。 |
| ALL | すべてのノードを照会します。 すべてのノードが応答するのを待って、最新のタイムスタンプを持つレコードをクライアントに返します。 その後、必要に応じて、バックグラウンドで読み取り修復を実行します。 応答は、読み取り修復が完了した後にのみ送信されます。 いずれかのノードが応答に失敗した場合、読み取り操作は失敗します。 | クライアントに戻る前に、レプリケーション係数によって指定された数のノードが書き込みを受信したことを確認します。 書き込み操作に応答しないレプリカが 1 つでもある場合、操作は失敗します。 |
Cassandra でのエラー検出
見越しエラー検出
クラスター内のノードを追跡するための一元的なプライマリがない場合、Cassandra では特別なゴシップ プロトコルを使用して、トークン リング内のすべてのノード間での通信が行われます。 Cassandra では、エラーは見越しエラー検出 (AFD)2 アルゴリズムを使用して、確率として表現されます。これは次のようにまとめることができます。
Cassandra トークン リング内の各ノードは、約 1 秒ごとに、リング内の別のランダム メンバーに問い合わせをし、その状態を照会します。 この通信は、TCP ハンドシェイクと同様のハンドシェイク プロトコルを使用して行われます。 ノードに接続できない場合は、障害の疑いが生じます。 その場合、障害監視システムは、ノードが障害を起こしたことについての確信度を、継続的に出力します。これは、ネットワーク環境の変動について説明できるようにするという意味で、望ましい措置です。 たとえば、1 つの接続で問題が検出されたというだけで、ノード全体が停止しているとは限りません。 そのため、ハートビート メカニズムの Dead と Alive のような単純なバイナリ評価ではなく、疑いの指標を使ったほうが、解釈に基づいて、より流動的かつ先見的に障害の可能性を示すことができます。
ヒンテッド ハンドオフ
何らかの障害によって到達できなくなった場所にデータを書き込む必要がある場合のために、Cassandra では、ヒンテッド ハンドオフと呼ばれる戦略が実装されています。 書き込み要求を最初に受信したノードが、(書き込みの実行先である) ターゲット ノードがダウンしていることを検出したとします。 その場合、そのノードはヒントを作成します。これは、その書き込み操作のリマインダーです。 非公式の例えですが、ヒントは、不在中のユーザーへのメッセージを受け取る代理人に相当します。 ヒントが代理人だとすれば、次のような意思を示していることになります。"私はノード X に対する書き込み情報を保有しています。私はこの書き込み操作を預かり、ノード X がオンラインに戻ったら、この書き込み要求をノード X に送信します。" この仕組みによって、Cassandra は書き込みを受け付けることができます。 書き込みの一貫性モデルが ANY である場合、ヒンテッド ハンドオフは成功した書き込みとしてカウントされます。
Cassandra の ACID プロパティ
他のデータベース システムとは異なり、Cassandra の ACID プロパティは、操作ごとに完全に構成可能です。 Cassandra の ACID プロパティは次のとおりです。
原子性:行のすべての列に対して列ファミリの原子性が保証されます (ただし、書き込みが少なくとも 1 つのコミット ログで保持されている必要があります)。
一貫性:読み取りと書き込みの一貫性モデルに ALL または QUORUM を使用した場合、一貫性は高いと見なすことができますが、代わりに可用性が低下します (読み取りと書き込みが失敗する可能性があります)。 より弱い一貫性モデル (ZERO、ANY、ONE など) を使用した場合、パフォーマンスは向上します (クライアントの応答時間が短縮されます) が、一貫性が低下します。
より正式な表現で示すなら、Cassandra の一貫性は次の式で表わすことができます。
- $W$ は書き込みレプリカの数です。
- $R$ は読み取りレプリカの数です。
- $N$ はレプリケーション係数です。
- $W + R > N$ であれば、そのシステムでは厳密な一貫性が確保されます。
この数式が意味しているのは、読み取り操作と書き込み操作を組み合わせた場合、操作の一貫性を保つには、特定の行のすべてのレプリカにアクセスする必要があるということです。 たとえば、$W = 1$ (一貫性レベルは ONE) かつ $R = N$ (一貫性レベルは ALL) の状態を考えてみてください。 この場合、システムは厳密な一貫性を維持していると見なされます。 同様に、$W = N$ かつ $R = 1$ の場合も、システムの一貫性は厳密に保たれます。 QUORUM について、Q を $\frac{N}{2} + 1$ と定義した場合、$W = R = Q$ (つまり、読み取りと書き込みの両方が QUORUM モードで実行される) であれば、システムは一貫性があると見なされます。
独立性:バージョン 1.1 以降、Cassandra では、特定の行に対してのみ、書き込み操作の分離が保証されます。
永続性:ALL、ONE、および QUORUM モデルでは、書き込みの永続性が保証されます (コミット ログに書き込まれます)。 ZERO モデルと ANY モデルでは、書き込みがいずれかのノードのコミット ログに書き込まれたという保証がないため、書き込みには永続性がない可能性があります。
Cassandra のユース ケース
Cassandra は、調整可能な一貫性、高可用性、スケーラビリティなど、便利な機能を備えたユニークなデータ ストレージ システムです。 Cassandra は、多数のサーバーを使用してデプロイする場合に適しています。そうすることで、ユーザーはこれらの機能を最大限に活用できます。
また、Cassandra は書き込みパフォーマンスにおいても非常に優れています。これは、そのアーキテクチャや、調整可能な一貫性モデルなどによって実現されている性能です。 Cassandra は、主にソーシャル ネットワーク分野のアプリケーション向けに開発されたものです。書き込みの頻度が高く、読み取り操作の予測が困難な環境に適しています。
Cassandra のもう 1 つの便利な特長は、複数のデータセンター間でのレプリケーションをすぐにサポートできるということです。 フォールト トレランス メカニズムは、(HBase や Hadoop と比較して) 非常に動的であり、長い待機時間を誤ってエラーと見なすこともありません。 スキーマフリーのデータ モデルなので、変更が頻繁に発生する可能性のあるアプリケーションにも適しています。
参考資料
- Merkle, R. (1988 年)。 従来の暗号化機能に基づくデジタル署名 CRYPTO の議事録 (369 ~ 378 ページ)。 Springer-Verlag
- Hayashibara, Naohiro, et al. (2004 年)。 φ 見越し障害検出機能 高信頼性分散システム、高信頼性分散システムに関する IEEE 国際シンポジウム (第 23 回) の議事録
- DeCandia, Giuseppe、他 (2007 年)。 Dynamo: Amazon の高可用性キー値ストア ACM SIGOPS オペレーティング システム レビュー。 Vol. 41. No. 6 ACM