データの取り込みと処理について説明する
データ分析とは、データを取得し、そこから有意義な情報と推論を見つけ出すことです。 これは、小売業者にとっては最適な種類の製品を選ぶことであったり、バイオテクノロジー企業にとっては最良のワクチン候補を選ぶことであったりと、多岐にわたります。
たとえば、会社でのデータ分析は、自社の組織で生成されるデータを取得し、それを使用して、組織の業績、および業績を維持するための対応を把握することに当たります。 データ分析を使用すると、組織の長所と短所を特定しやすくなり、ビジネス上の意思決定が適切に行われるようになります。
会社で使用されるデータは、多数のソースから取得できます。 くまなく調べる必要がある大量の履歴データがあり、最新のデータが常に届く可能性があります。 このデータは、顧客の購入、銀行取引、株価の動き、リアルタイムの気象データ、監視デバイス、さらにはカメラの結果である可能性があります。 データ分析ソリューションでは、このデータを結合し、事業運営に関する質問 (および回答) に使用できるデータ ウェアハウスを構築します。 データ ウェアハウスを構築するには、必要なデータをキャプチャし、適切な形式に "ラングリング" する必要があります。 その後、分析ツールと視覚化を使用して、情報を調べ、傾向とその原因を特定することができます。
注意
"ラングリング" は、生データを変換し、分析のためにより有用な形式にマッピングするプロセスです。 多くのソースからデータをキャプチャ、フィルター処理、クリーニング、結合、および集計するコードを記述することに関係する場合があります。
このユニットでは、データ分析において重要な 2 つのステージである、データの取り込みとデータ処理について学習します。 次の図は、これらのステージがどのように組み合わされているかを示しています。
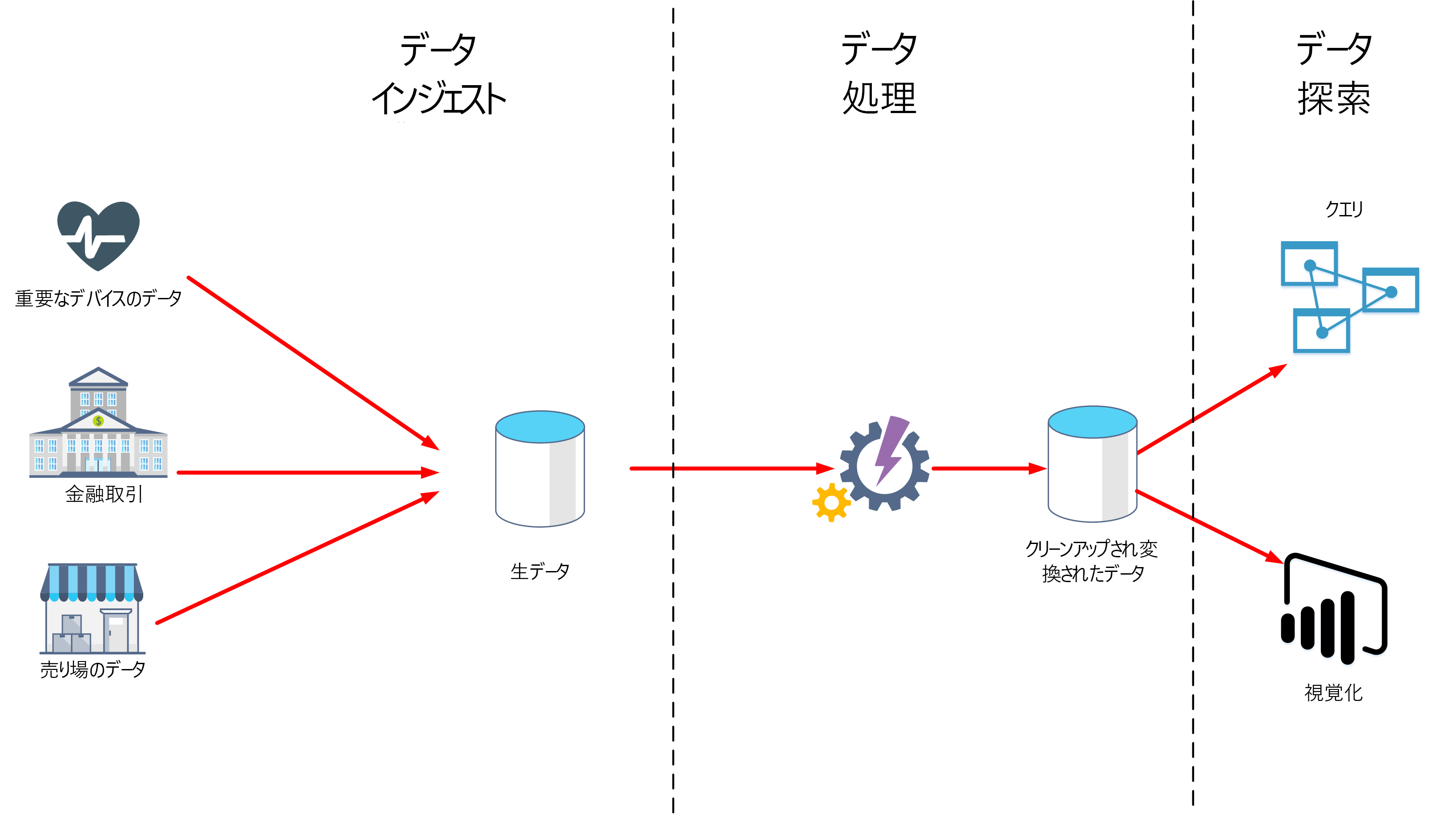
データの取り込みとは
データの取り込みは、データを取得してインポートし、すぐに使用したり、データベースに格納したりするプロセスです。 データは、連続したストリームとして到着する場合もあれば、ソースによってはバッチで届く場合もあります。 取り込みプロセスの目的は、このデータをキャプチャして格納することです。 この生データは、データベース管理システム、一連のファイル、あるいはその他の種類の高速で簡単にアクセスできるストレージなどのリポジトリに保持できます。
取り込みプロセスでは、フィルター処理も行われる場合があります。 たとえば、取り込みでは疑わしい、破損した、または重複したデータが拒否される場合があります。 疑わしいデータは、予期しないソースから届いたデータである可能性があります。 データの破損または重複は、デバイス エラー、送信エラー、あるいは改ざんなどが原因である可能性があります。
このステージで一部の変換を行い、データを標準形式に変換して後で処理することもできます。 たとえば、同じ日付と時刻の表現を使用するようにすべての日付と時刻のデータを再フォーマットし、同じ単位を使用するようにすべての測定データを変換することができます。 しかし、これらの変換は短時間で行う必要があります。 このステージでは、データに対して複雑な計算や集計を行わないようにしてください。
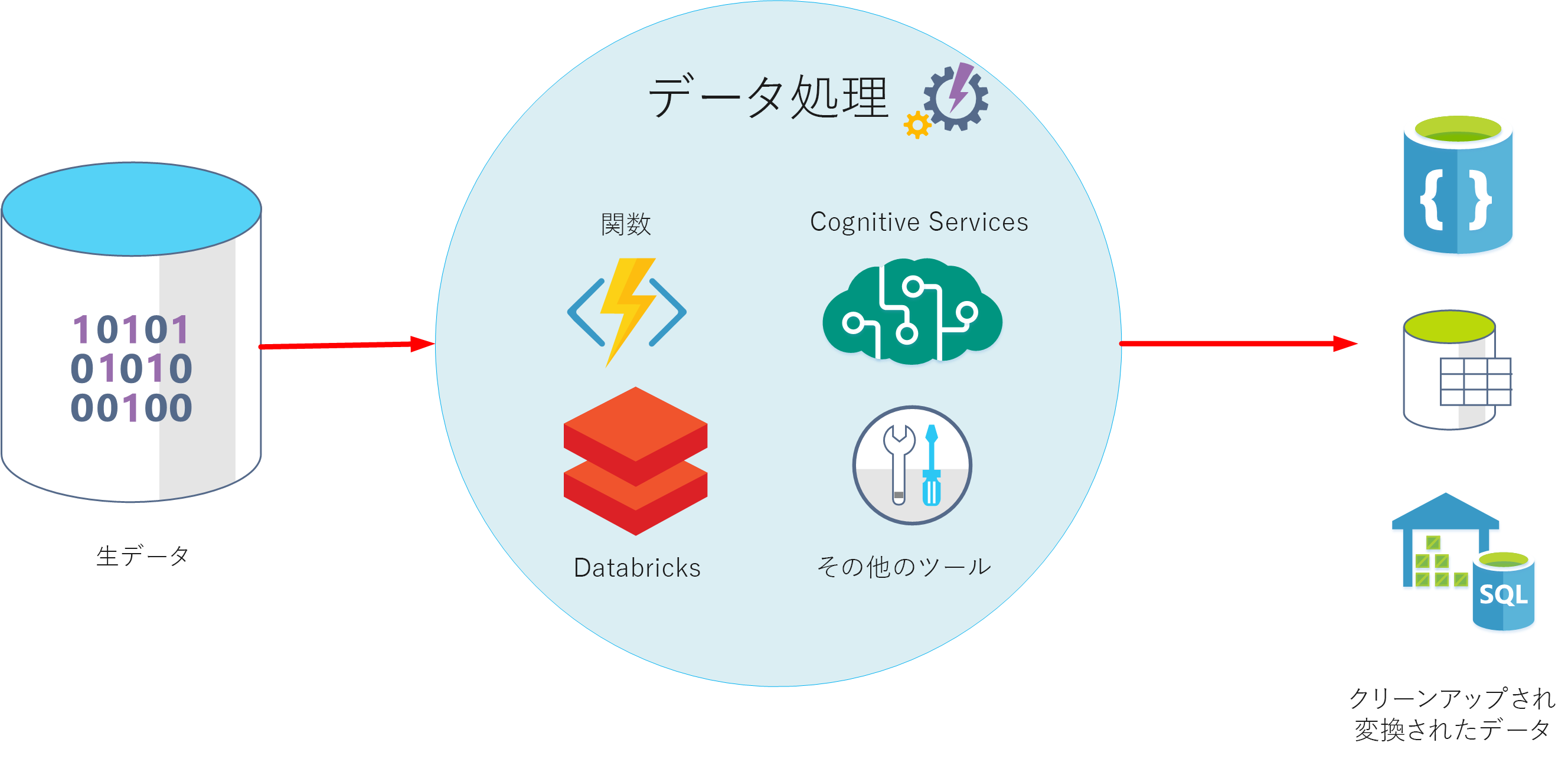
データ処理とは
データ処理ステージは、データが取り込まれ、収集された後に発生します。 データ処理では、未加工の形式でデータを受け取り、クリーニングし、より意味のある形式 (テーブル、グラフ、ドキュメントなど) に変換します。 結果として、データのデータベースが生成されます。これを使用して、クエリを実行し、視覚化して、コンピューターによって解釈され、組織全体の従業員が使用する必要な形式やコンテキストを作成できます。
注意
データ クリーニングは、異常の除去、および取り込みステージ中に実行するには時間がかかりすぎるフィルターと変換の適用などのさまざまなアクションを含む一般化された用語です。
データ処理の目的は、生データを 1 つまたは複数のビジネス モデルに変換することです。 ビジネス モデルでは、意味のあるビジネス エンティティの観点からデータを記述します。また、項目を一緒に集計し、情報をまとめる場合もあります。 データ処理ステージでは、データから予測またはその他の分析モデルを生成することもできます。 データ処理は複雑な場合があり、自動化されたスクリプトや、Azure Databricks、Azure Functions、Azure Cognitive Services などのツールを使用して、データを調べて再フォーマットしたり、モデルを生成したりすることがあります。 データ アナリストは機械学習を使用することができます。これは、これらのモデルに基づいて将来の傾向を判断するのに役立ちます。
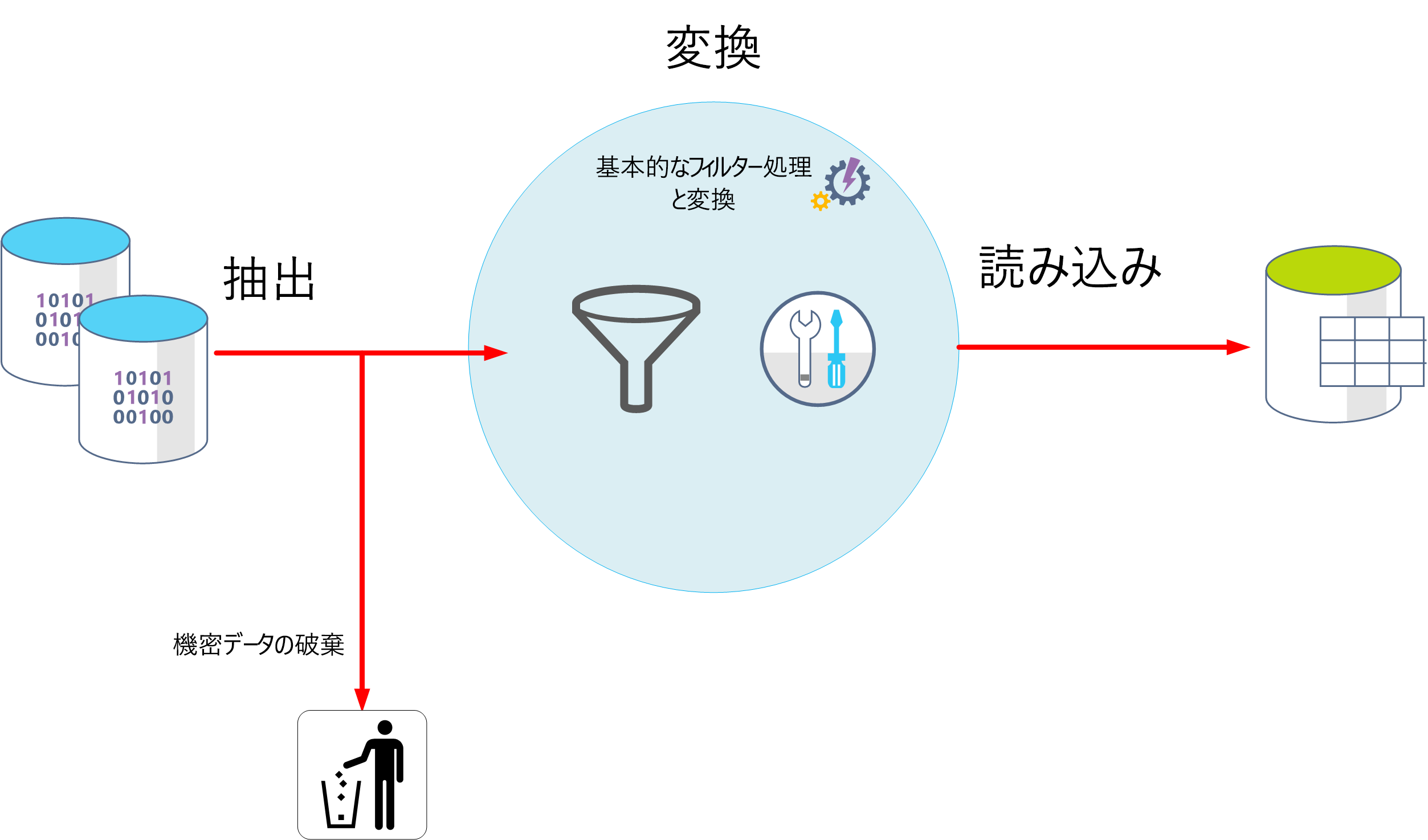
ELT および ETL とは
データ処理メカニズムでは、取り込まれたデータを取得し、このデータを処理および変換してモデルを生成してから、変換されたデータとモデルを保存する 2 つのアプローチを取ることができます。 これらの方法は、ETL および ELT と呼ばれています。
ETL は、"抽出、変換、読み込み" の略です。 生データは、保存される前に取得および変換されます。 抽出、変換、読み込みの各手順は、操作の継続的なパイプラインとして実行できます。 これは、項目間の依存関係がほとんどない、シンプルなモデルのみを必要とするシステムに適しています。 たとえば、この種のプロセスは、基本的なデータ クリーニング タスク、データの重複除去、および個々のフィールドの内容の再フォーマットに使用されることがよくあります。
別のアプローチとして、ELT があります。 ELT は、"抽出、読み込み、変換" の省略形です。 このプロセスは、データが変換される前に格納されるという点で ETL とは異なります。 データ処理エンジンでは、変換されたデータとモデルをストレージに書き戻す前に、ストレージからデータを取得して処理する反復的なアプローチを取ることができます。 ELT は、データベース内の複数の項目に依存する複雑なモデルを構築する場合により適しており、多くの場合、定期的なバッチ処理が使用されます。
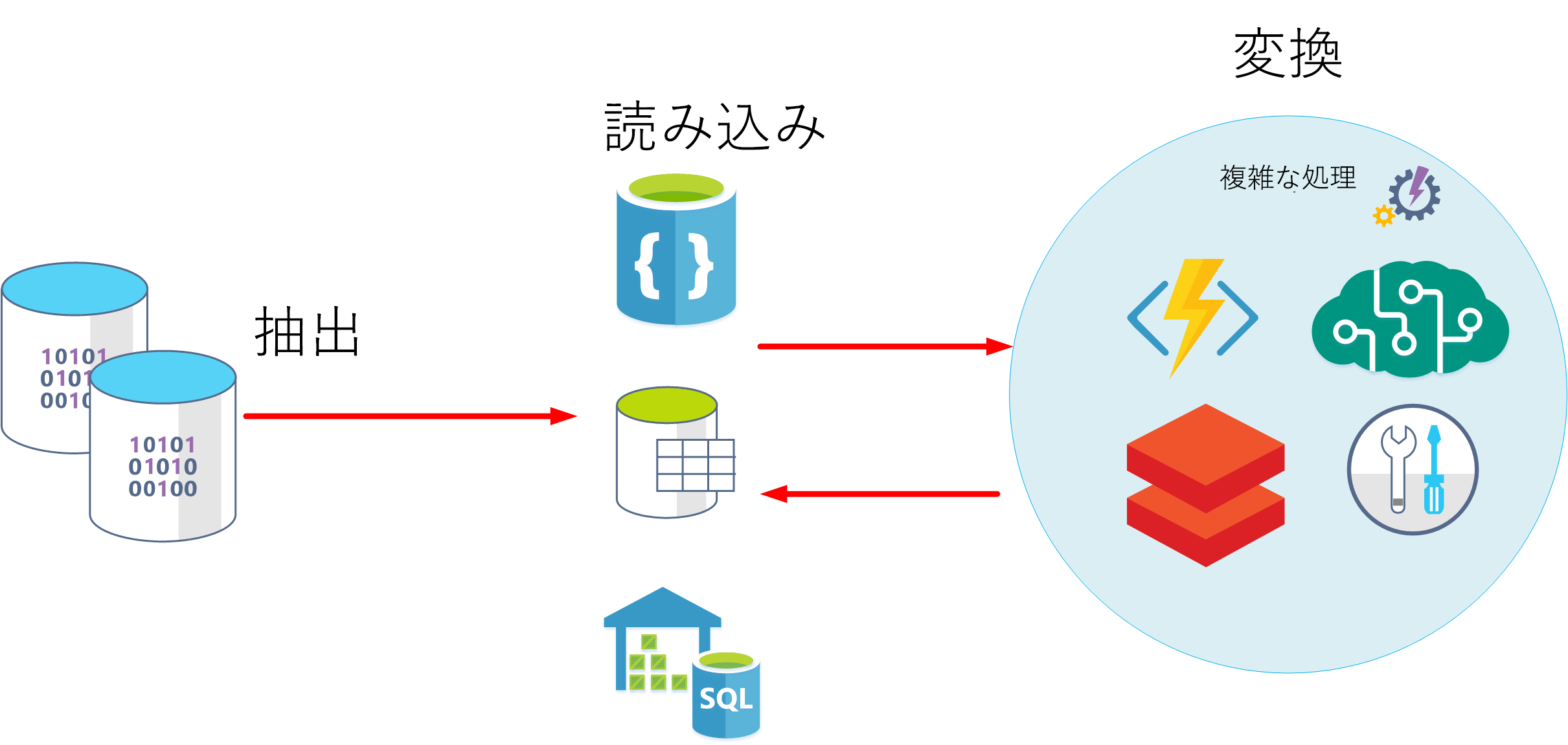
ELT は、使用可能な広範な処理能力を利用できるため、クラウドに適したスケーラブルなアプローチです。 ETL のよりストリーム指向のアプローチでは、スループットにより重点が置かれます。 しかし、ETL では、データを格納する前にフィルター処理を行うことができます。 このように、ETL は、分析データ モデルに到達する前に機微なデータを除去することで、データのプライバシーとコンプライアンスを維持するのに役立ちます。
Azure には、ELT および ETL アプローチを実装するために使用できるオプションがいくつか用意されています。 たとえば、Azure SQL Database にデータを格納する場合は、SQL Server Integration Services を使用できます。 Integration Services を使用すれば、XML データ ファイル、フラット ファイル、リレーショナル データ ソースなど、さまざまなソースのデータを抽出および変換してから、1 つまたは複数のターゲットにデータを読み込むことができます。
これは、ほとんどの場合での ETL と ELT の利点を示す簡単な表です。

より一般化された別のアプローチは、Azure Data Factory を使用することです。 Azure Data Factory は、データの移動を調整し、大規模なデータの変換を行うためのデータ主導型のワークフローを作成できるクラウドベースのデータ統合サービスです。 Azure Data Factory を使えば、各種のデータ ストアからデータを取り込むことができるデータ主導型の (パイプラインと呼ばれる) ワークフローを作成し、スケジューリングできます。 データ フローを使用するか、Azure Databricks や Azure SQL Database などのコンピューティング サービスを使用して、視覚的にデータを変換する複雑な ETL プロセスを構築できます。