インデックスの設計
SQL Server では、さまざまな種類のワークロードをサポートするためにいくつもの種類のインデックスが用意されています。 大まかに言うと、インデックスとは、ディスク上で 1 つのテーブルまたはビューに関連付けられている構造であると考えることができます。SQL Server がこれを使うと、テーブル全体をスキャンするよりも簡単に、インデックス キー (テーブルまたはビュー内部の一定数の列から成るもの) に関連付けられている行を見つけることができます。
クラスター化インデックス
DBA の採用面接でよくある質問の 1 つに、クラスター化インデックスと非クラスター化インデックスの違いを聞くというものがあります。インデックスは、データ記憶に関して SQL Server の基盤とも言うべきテクノロジだからです。 クラスター化インデックスは、基になるテーブルであり、キー値に基づいた並べ替えを済ませた状態で格納されます。 テーブルに行を格納する際の順序は 1 つなので、1 テーブルに作成できるクラスター化インデックスは 1 つだけです。 クラスター化インデックスのないテーブルを、ヒープと呼びます。ヒープは通常、ステージング テーブルとしてのみ使用します。 パフォーマンスを高めるうえで重要な設計原則の 1 つが、クラスター化インデックスのキーをできるだけ狭い範囲に抑えることです。 クラスター化インデックスのキー列を検討するときには、一意の列か、異なる値が多数入っている列を検討する必要があります。 ほかにクラスター化インデックス キーに適した特徴としては、逐次的にアクセスされるレコードや、テーブルから取得するデータを並べ替えるのに頻繁に使用するレコードのものがあります。 並べ替えに使用する列に基づくクラスター化インデックスがあると、必要な順番に並んだ状態でデータが格納されるので、クエリを実行するたびに並べ替えのコストが発生するのを防ぐことができます。
注意
ここで、テーブルが特定の順序で "格納されている" と言うのは、ディスク上の物理的順番ではなく、論理的な順序で並んでいることを指します。 インデックスにはページとページの間にポインターがあり、ポインターを使用して論理的な順序を作成できます。 SQL Server がインデックスを "順番に" スキャンするときは、ポインターに従ってページを順番に辿ります。 インデックスを作成した直後は、インデックスもディスク上の物理的順番で格納されている可能性が高いと思われます。しかし、データに変更を始め、インデックスに新しいページを追加する必要が出てくると、ポインターによって正しい論理的順番が与えられるため、新しいページはディスク上の物理的な順番に並ばなくなります。
[非クラスター化インデックス]
非クラスター化インデックスは、データ行とは別の構造です。 非クラスター化インデックスには、インデックスについて定めたキー値と、そのキー値が含まれるデータ行を参照するポインターが入っています。 非クラスター化インデックスのリーフ レベルに別の非キー列を追加すると、SQL Server の付加列機能を使ってカバーする列を増やすことができます。 非クラスター化インデックスは、1 つのテーブルに複数作成できます。
インデックスの追加や、既存の非クラスター化インデックスに対する列の追加が必要になる場面の例を以下に示します。

クエリ プランを見ると、インデックスのシークにより取得した各行について、クラスター化インデックス (テーブル自体) からさらにデータを取得する必要があることがわかります。 非クラスター化インデックスはありますが、そこには製品列しか含まれていません。 以下のように非クラスター化インデックスに対してクエリ内の他の列を追加すると、実行プランが Key Lookup を使わない形に変化します。

上で作成したインデックスは、カバー インデックスの例であり、キー列に加えて、クエリをカバーするためにさらに列を含め、テーブル自体にアクセスする必要がないようにしています。
非クラスター化インデックスとクラスター化インデックスはどちらも一意に定義できます。つまり、キー値を重複させることはできません。 テーブルに PRIMARY KEY または UNIQUE の制約を作成すると、一意のインデックスが自動で作成されます。
このセクションで主に見ていくのは、SQL Server の B ツリー インデックスについてです。これは、行ストア インデックスとしても知られるものです。 B ツリーの一般的な構造は以下のとおりです。
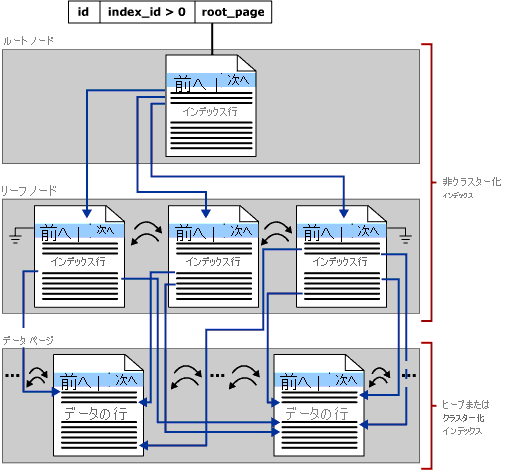
インデックス B ツリー内の各ページを、インデックス ノードと呼びます。また、B ツリーの最上位のノードを、ルート ノードと呼びます。 インデックスの最下層にあるノードは、リーフ ノードと呼びます。そのリーフ ノードが集まったものが、リーフ レベルです。
インデックス デザインは、芸術と科学の組み合わせです。 キーに列が数個しかない "狭い" インデックスの場合には、更新にかかる時間が短くなり、メンテナンスのオーバーヘッドも少なくなります。しかし、列の数がもっと多い "広い" インデックスほど多数のクエリには役に立たない可能性もあります。 アプリケーションのクエリによって選択される列に基づいて、いくつかのインデックス作成アプローチを試してみる必要があるでしょう。 クエリ オプティマイザーでは一般に、既存のインデックスのなかからクエリに応じて最善であると判定されたものが採用されます。しかし、そのインデックスが、作成できる最善のインデックスであるとは限りません。
データベースのインデックスを適切に作成するのは、複雑な作業です。 テーブルのインデックスを計画するときは、いくつかの基本原則に留意する必要があります。
- システムのワークロードを理解すること。 90% が読み取りアクティビティであるデータ ウェアハウス操作に使われるテーブルと比べて、主に挿入操作に使われるテーブルでは、余分なインデックスによるメリットは、はるかに小さくなります。
- 実行頻度の特に高いクエリを把握し、そのクエリを軸にインデックスを最適化すること。
- クエリに使用する列のデータ型を把握すること。 インデックスは、整数のデータ型や、一意の列または null でない列に使用するのが理想です。
- 非クラスター化インデックスは、述語や JOIN 句で頻繁に使用する列に作成すること。また、オーバーヘッドを避けるため、インデックスはできるだけ狭い範囲に抑えること。
- データのサイズやボリュームを把握すること。小さなテーブルのテーブル スキャンは比較的安価な操作であり、簡単 (ささい) であるという理由だけで、SQL Server がテーブル スキャンの実行を決定する場合があります。 大きなテーブルのテーブル スキャンには、コストがかかります。
SQL Server で用意されている選択肢としてはほかにも、フィルター処理済みインデックスの作成があります。 フィルター処理済みインデックスが特に適しているのは、大きなテーブルの、ほとんどの行が同じ値の列です。 実例としては、次に示すような、早期退職者や定年退職者も含めた全従業員のレコードが入った従業員テーブルが考えられます。
CREATE TABLE [HumanResources].[Employee](
[BusinessEntityID] [int] NOT NULL,
[NationalIDNumber] [nvarchar](15) NOT NULL,
[LoginID] [nvarchar](256) NOT NULL,
[OrganizationNode] [hierarchyid] NULL,
[OrganizationLevel] AS ([OrganizationNode].[GetLevel]()),
[JobTitle] [nvarchar](50) NOT NULL,
[BirthDate] [date] NOT NULL,
[MaritalStatus] [nchar](1) NOT NULL,
[Gender] [nchar](1) NOT NULL,
[HireDate] [date] NOT NULL,
[SalariedFlag] [bit] NOT NULL,
[VacationHours] [smallint] NOT NULL,
[SickLeaveHours] [smallint] NOT NULL,
[CurrentFlag] [bit] NOT NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL)
このテーブルに含まれる CurrentFlag という列は、現時点で従業員が在職中かどうかを示します。 この例で使っている bit データ型は値が 2 つだけであり、1 は在職していること、0 は在職していないことを示します。 CurrentFlag 列に WHERE CurrentFlag = 1 というフィルター処理済みインデックスを作成すると、在職中の従業員のクエリを効率的に実行できます。
また、ビューにインデックスを作成することもできます。ビューにインデックスを作成すると、ビューに集計やテーブル結合などのクエリ要素が含まれる場合に、パフォーマンスを大幅に向上させることができます。
列ストア インデックス
列ストアを使うと、大規模な集計ワークロードを実行するクエリのパフォーマンスが向上します。 この種類のインデックスは、もともとデータ ウェアハウスを対象としたものでしたが、その後大規模なテーブルに生じるパフォーマンス面の問題の解決に役立つとして、他の多くのワークロードにも使われるようになっています。 SQL Server 2014 からは、非クラスター化とクラスター化の 2 種類の列ストア インデックスが用意されています。 クラスター化列ストア インデックスが特殊な方法で格納されているテーブルそのものであり、非クラスター化列ストア インデックスがテーブルとは独立して格納されているという点は、B ツリー インデックスと同じです。 クラスター化列ストア インデックスには、特定のテーブル内の列がすべて入っています。 ただし、クラスター化列ストア インデックスには並べ替えが行われません。行ストア クラスター化インデックスとはこの点が異なります。
非クラスター化列ストア インデックスは、一般に 2 つのシナリオで使われます。1 つ目は、テーブルに列ストア インデックスでサポートされていないデータ型を含む列がある場合です。 列ストア インデックスでは、大部分のデータ型がサポートされていますが、XML、CLR、sql_variant、ntext、text、image はサポートされていません。 クラスター化列ストアは基になるテーブルそのものであって、そのテーブルの列がすべて含まれることになるため、非クラスター化が唯一の選択肢になります。 2 つめのシナリオは、フィルター処理済みインデックスです。このシナリオは、ハイブリッド トランザクション分析処理 (HTAP) と呼ばれるアーキテクチャで使用します。HTAP では、基になるテーブルにデータが読み込まれると同時に、テーブルについてレポートが実行されます。 この設計でインデックス (多くの場合、日付のフィールド) にフィルター処理を実行すると、挿入とレポートの両方に良好なパフォーマンスが実現します。
列ストア インデックスは、インデックスの各行を独立して格納するという独特な記憶メカニズムを採用しています。 それにより二重の利点が提供されます。 列ストア インデックスを使うクエリでは、クエリに必要な列のスキャンだけでよいので I/O の合計実行回数が減り、同じ列にあるデータは性質が似ている可能性が高いことから圧縮率を高くすることができます。
列ストア インデックスは、データ ウェアハウスのファクト テーブルのように大量のデータをスキャンする分析クエリでは特に優れたパフォーマンスを発揮します。 SQL Server 2016 以降では、列ストア インデックスを別の B ツリー非クラスター化インデックスで拡張できます。これは、一部のクエリでシングルトン値の検索が行われる場合に役立ちます。
列ストア インデックスが有効なものとしてはほかにも、バッチ実行モードがあります。データベース エンジンが行を 1 つずつ処理していくのに対し、バッチ実行モードでは一定数の行 (通常は約 900 行) を一括で処理します。 クエリ エンジンでは、各レコードを個別に読み込んで処理していくのではなく、900 件のレコードから成るグループの計算をまとめて処理します。 この処理モデルを使うと、CPU 命令の数を劇的に減らすことができます。
SELECT SUM(Sales) FROM SalesAmount;
バッチ モードでは、従来の行処理より大幅に高いパフォーマンスを実現できます。 SQL Server 2019 では、行ストア データのバッチ モードも利用できます。 行ストアのバッチ モードでは、読み取りのパフォーマンスは列ストア インデックスほどではありませんが、分析クエリのパフォーマンスは最大で 5 倍に向上する可能性があります。
データ ウェアハウス ワークロードに対する列ストア インデックスのもう 1 つのメリットは、一括挿入操作の行数が 102,400 以上の場合の読み込みパスの最適化です。 102,400 行という数値は列ストアに直接読み込むための最小値であり、行の集合体 (行グループと呼びます) それぞれの行数の最大値は約 1,024,000 行です。 行グループの行数を増やして、グループの数を少なくする方が、SELECT クエリの効率が上がります。要求されたレコードを取得するためにスキャンが必要な行グループの数が少なくなるからです。 読み込みはメモリ内で発生し、その結果は直接インデックスに送られます。 もっと小規模なボリュームの場合には、データがデルタ ストアと呼ばれる B ツリー構造に書き込まれた後で、非同期的にインデックスに読み込まれます。
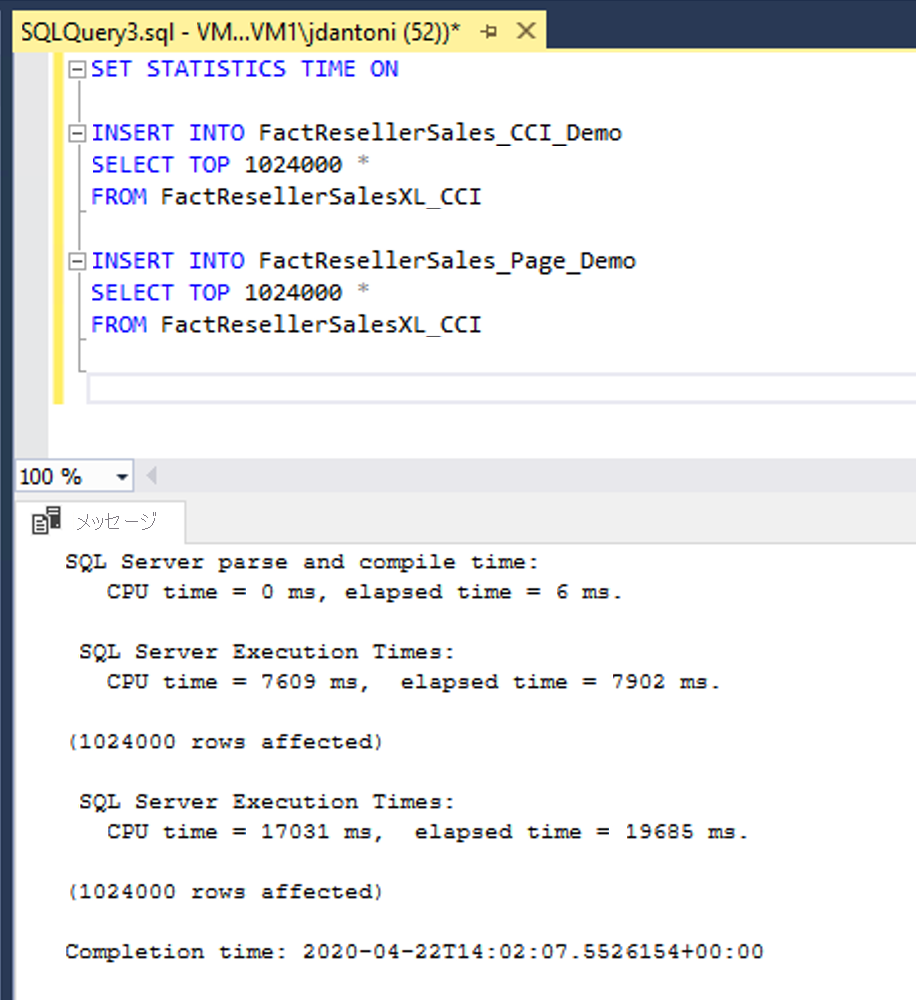
この例では、同じデータが 2 つのテーブル FactResellerSales_CCI_Demo と FactResellerSales_Page_Demo に読み込まれています。 FactResellerSales_CCI_Demo では、クラスター化列ストア インデックスが使われています。FactResellerSales_Page_Demo では、2 列でクラスター化 B ツリー インデックスが使われ、ページ圧縮が行われています。 ご覧のとおり、それぞれのテーブルが FactResellerSalesXL_CCI テーブルから 1,024,000 行を読み込んでいます。 SET STATISTICS TIME が ON のとき、SQL Server はクエリの実行にかかった時間を追跡します。 列ストア テーブルへのデータの読み込みに要した時間は、約 8 秒でした。これに対して、ページ圧縮を実施したテーブルへの読み込みには、20 秒近くかかっています。 この例では、列ストアに送られる行がすべて、単一の行グループに読み込まれています。
1 回の操作で列ストア インデックスに読み込まれるデータが 102,400 行未満の場合は、デルタ ストアと呼ばれる B ツリー構造に読み込まれます。 データベース エンジンでは、タプル ムーバーと呼ばれる非同期的なプロセスを使用し、このデータを列ストア インデックスに移動します。 デルタ ストアからのレコードの読み取りは、列ストアからの読み取りより効率が悪いため、デルタ ストアが開かれると、クエリのパフォーマンスに影響することがあります。 デルタ ストアを強制的に列ストア インデックスに追加して圧縮するため、COMPRESS_ALL_ROW_GROUPS オプションを使ってインデックスを再編成することもできます。