演習 - データをクリーンアップして準備する
データセットを準備する前に、そのコンテンツと構造を理解する必要があります。 前のラボでは、主要な米国航空会社の定刻到着情報を含むデータセットをインポートしました。 そのデータには 26 個の列と数千もの行が含まれており、各行には 1 つのフライトが示され、フライトの出発地、目的地、予定の出発時刻などの情報が含まれていました。 また、データを Jupyter ノートブックに読み込み、シンプルな Python スクリプトを使用して、そこから Pandas DataFrame を作成しました。
DataFrame は 2 次元のラベル付きデータ構造です。 スプレッドシートまたはデータベース テーブル内の列と同じように、DataFrame の列にはさまざまな種類があります。 Pandas で最もよく使用されるオブジェクトです。 この演習では、DataFrame と、その内部のデータをより詳しく調べます。
前のセクションで作成した Azure ノートブックに戻ります。 ノートブックを閉じた場合は、Microsoft Azure Notebooks ポータルにもう一度サインインし、ノートブックを開き、[セル] ->[すべて実行] を使用して、開いたノートブック内のすべてのセルを再実行します。
FlightData ノートブック
前のラボでノートブックに追加したコードにより、flightdata.csv から DataFrame が作成され、そこで DataFrame.head が呼び出され、最初の 5 行が表示されます。 通常、データセットについて最初に知っておく必要があることの 1 つは、中に含まれている行数です。 数を取得するには、ノートブックの末尾にある空のセルに次のステートメントを入力して実行します。
df.shapeDataFrame に 11,231 個の行と 26 個の列が含まれていることを確認します。

行と列の数の取得
ここで、データセット内の 26 個の列を簡単に確認します。 これには、フライトが行われた日付 (YEAR、MONTH、DAY_OF_MONTH)、出発地と目的地 (ORIGIN と DEST)、予定の出発時刻と到着時刻 (CRS_DEP_TIME と CRS_ARR_TIME)、予定の到着時刻と実際の到着時刻の差 (分単位) (ARR_DELAY)、およびフライトが 15 分以上遅れたかどうか (ARR_DEL15) などの重要な情報が含まれています。
データセット内の列の完全な一覧を以下に示します。 時刻は 24 時間表示となっています。 たとえば、1130 は午前 11 時 30 分となり、1500 は午後 3 時 00 分となります。
列 説明 YEAR フライトが行われた年 QUARTER フライトが行われた四半期 (1 から 4) MONTH フライトが行われた月 (1 から 12) DAY_OF_MONTH フライトが行われた月の日 (1 から 31) DAY_OF_WEEK フライトが行われた曜日 (1 = 月、2 = 火など) UNIQUE_CARRIER 航空会社コード (DL など) TAIL_NUM 航空機のテール ナンバー FL_NUM 便名 ORIGIN_AIRPORT_ID 出発地の空港の ID ORIGIN 出発地の空港コード (ATL、DFW、SEA など) DEST_AIRPORT_ID 目的地の空港の ID DEST 目的地の空港コード (ATL、DFW、SEA など) CRS_DEP_TIME 予定の出発時刻 DEP_TIME 実際の出発時刻 DEP_DELAY 出発遅延時間 (分) DEP_DEL15 0 = 出発遅延時間は 15 分未満、1 = 出発遅延時間は 15 分以上 CRS_ARR_TIME 予定の到着時刻 ARR_TIME 実際の到着時間 ARR_DELAY フライトの到着が遅れた時間 (分) ARR_DEL15 0 = 到着が遅れた時間は 15 分未満、1 = 到着が遅れた時間は 15 分以上 CANCELLED 0 = フライトがキャンセルされなかった、1 = フライトがキャンセルされた DIVERTED 0 = フライトが迂回させられなかった、1 = フライトが迂回させられた CRS_ELAPSED_TIME 予定のフライト時間 (分) ACTUAL_ELAPSED_TIME 実際のフライト時間 (分) DISTANCE 乗車距離 (マイル)
データセットには、1 年を通じてほぼ均等に分散された日付が含まれています。これは、ミネアポリスからのフライトが、1 月の場合より 7 月の方が吹雪による遅延が発生する可能性が低いため、重要です。 しかし、このデータセットは "クリーン" なものとはほど遠く、すぐに使用することはできません。 ここで、Pandas コードを記述してクリーンアップしてみましょう。
機械学習で使用するデータセットを準備する場合に最も重要な側面の 1 つは、結果に影響しないか、否定的な方向に偏らせる可能性がある、あるいは多重共線性が生成される可能性のある列をフィルター処理するときに、予測しようとしている結果に関連する "特徴" 列を選択することです。 もう 1 つの重要なタスクは、欠落値を排除することです。その場合、その値を含む行または列を削除するか、その値を意味のある値に置き換えます。 この演習では、余分な列を排除し、残りの列で欠落値を置き換えます。
データ サイエンティストが通常、データセット内で最初に探すものの 1 つは、欠落値です。 Pandas で欠落値を確認する簡単な方法があります。 たとえば、ノートブックの末尾にあるセルで次のコードを実行します。
df.isnull().values.any()出力が "True" であることを確認します。これは、データセット内のどこかに 1 つ以上の欠落値があることを示します。

欠落値の確認
次の手順では、欠落値の場所を探します。 そのためには、次のコードを実行します。
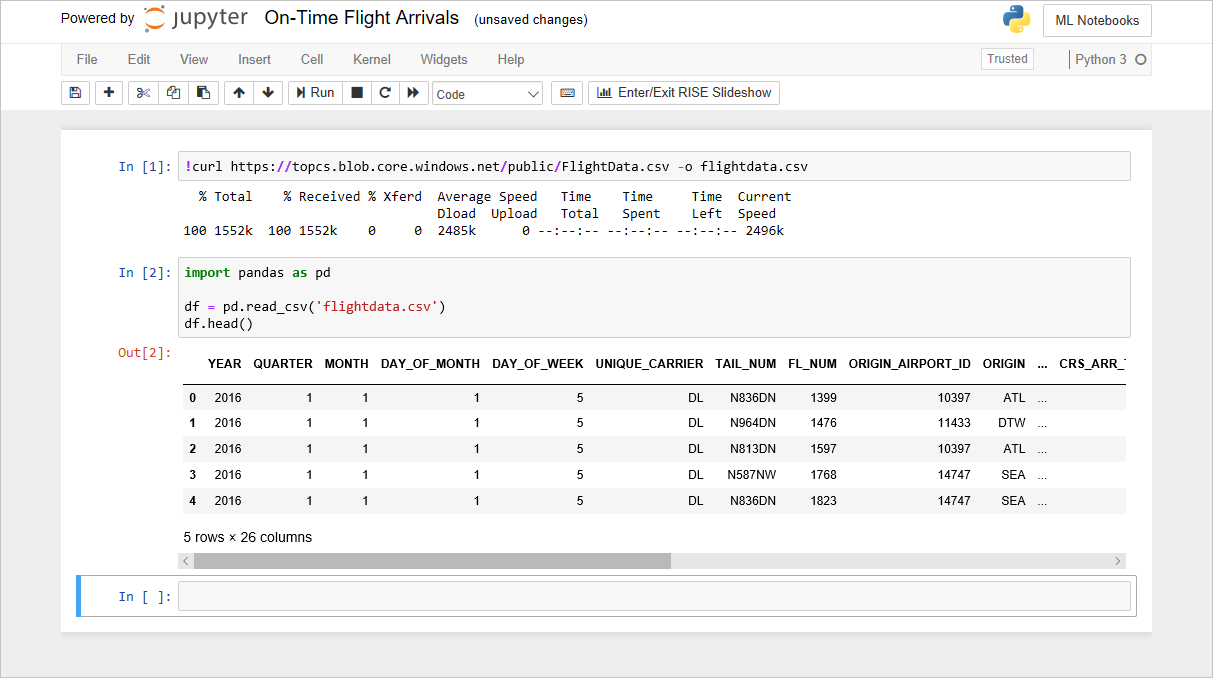
df.isnull().sum()各列の欠落値の数をリストする以下の出力が表示されていることを確認します。
各列の欠落値の数
不思議なことに、26 番目の列 ("Unnamed:25") には 11,231 個の欠落値が含まれており、これはデータセット内の行数と同じです。 インポートした CSV ファイルの各行の末尾にコンマが含まれているため、この列は誤って作成されました。 その列を排除するには、次のコードをノートブックに追加して実行します。
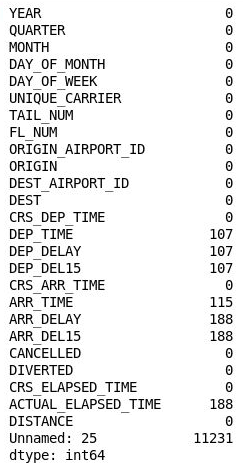
df = df.drop('Unnamed: 25', axis=1) df.isnull().sum()出力を検査し、列 26 が DataFrame から消えたことを確認します。
列 26 が削除された DataFrame
DataFrame にはまだ多くの欠落値が含まれていますが、その一部は役に立ちません。それらを含む列が、構築するモデルと関連がないためです。 そのモデルの目的は、予約を検討しているフライトが定刻に到着する可能性があるかどうかを予測することです。 フライトが遅れる可能性があることがわかっている場合、別のフライトを予約するように選択できます。
したがって、次の手順では、予測モデルと関連のない列を排除するようにデータセットをフィルター処理します。 たとえば、航空機のテール ナンバーはフライトが定刻に到着するかどうかには、おそらくほとんど関連がなく、チケットを予約した時点で、フライトがキャンセルになるか、迂回させられるか、あるいは遅れるかを知る方法はありません。 逆に、予定の出発時刻は、定刻の到着に大きく関連する可能性があります。 ほとんどの航空会社で使用されるハブアンドスポーク方式により、朝のフライトは午後や夜間のフライトよりも定刻となる頻度が多くなる傾向にあります。 また、一部の主要な空港では、日中の航空機の旋回待機により、後のフライトが遅れる可能性が高くなります。
Pandas では、不要な列を除外する簡単な方法が提供されます。 ノートブックの末尾にある新しいセルで次のコードを実行します。
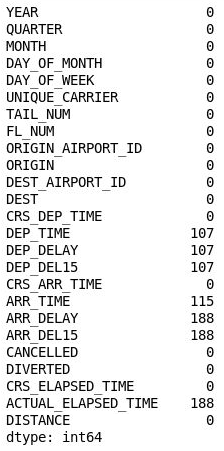
df = df[["MONTH", "DAY_OF_MONTH", "DAY_OF_WEEK", "ORIGIN", "DEST", "CRS_DEP_TIME", "ARR_DEL15"]] df.isnull().sum()出力には、DataFrame に現在、モデルに関連する列のみが含まれ、欠落値の数が大幅に減っていることが示されています。
フィルター処理された DataFrame
現在、欠落値を含む唯一の列は、ARR_DEL15 列であり、0 を使用して、定刻に到着したフライトを識別し、1 を使用して、定刻に到着しなかったフライトを識別します。 次のコードを使用して、欠落値を含む最初の 5 行を表示します。
df[df.isnull().values.any(axis=1)].head()Pandas では、
NaNを含む欠落値が示されます。これは、Not a Number の略です。 出力には、これらの行が実際は ARR_DEL15 列の欠落値であることが示されています。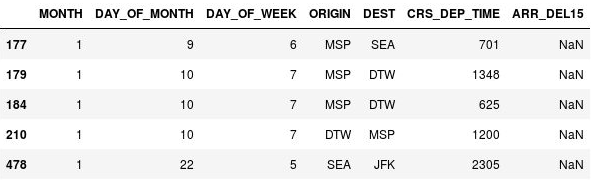
欠落値を含む行
これらの行が欠落している ARR_DEL15 値である理由は、それらがすべてキャンセルされたか迂回させられたフライトに対応しているためです。 DataFrame で dropna を呼び出して、これらの行を削除できます。 しかし、キャンセルされたか、別の空港に迂回させられたフライトは "遅延" と見なされる可能性があるため、fillna メソッドを使用して、欠落値を 1 に置き換えてみましょう。
次のコードを使用して、ARR_DEL15 列の欠落値を 1 に置き換え、行 177 から 184 までを表示します。
df = df.fillna({'ARR_DEL15': 1}) df.iloc[177:185]行 177、179、184 の
NaNが、フライトの到着が遅れたことを示す 1 に置き換えられたことを確認します。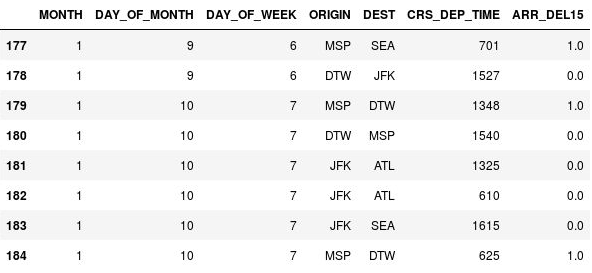
1 に置き換えられた NaN
欠落値が置き換えられ、列の一覧が、モデルに最も関連するものに絞り込まれたという意味で、データセットは "クリーン" な状態になりました。 しかし、まだ完了していません。 機械学習で使用するためにデータセットを準備するには、さらに行うことがあります。
使用するデータセットの CRS_DEP_TIME 列は、予定の出発時刻を表します。 この列の数値の細分性 (500 個を超える一意の値が含まれている) は、機械学習モデルの精度に悪影響を及ぼす可能性があります。 これは、ビン分割あるいは量子化という手法を使用して解決できます。 この列の各数値を 100 で除算し、最も近い整数に切り捨てるとどうなりますか。 たとえば、1030 は 10 になり、1925 は 19 になります。この列に最大 24 の不連続値が残ることになります。 直感的には理にかなっています。フライトの出発時刻が午前 10 時 30 分であるか、午前 10 時 40 分であるかは、おそらくあまり重要ではないからです。出発時刻が午前 10 時 30 分であるか、午後 5 時 30 分であるかは非常に重要です。
さらに、データセットの ORIGIN と DEST の列には、カテゴリ別の機械学習値を表す空港コードが含まれています。 これらの列は、"ダミー" 変数とも呼ばれる、インジケーター変数を含む個々の列に変換する必要があります。 つまり、5 つの空港コードを含む ORIGIN 列を、5 つの列に変換する必要があります。これらの列は空港ごとに 1 つずつあり、各列には、その列で表されている空港からフライトが出発したかどうかを示す 1 と 0 が含まれます。 DEST 列も同様の方法で処理する必要があります。
この演習では、CRS_DEP_TIME 列の出発時刻をビン分割し、Pandas の get_dummies メソッドを使用して、ORIGIN と DEST の列からインジケーター列を作成します。
DataFrame の最初の 5 行を表示するには、次のコマンドを使用します。
df.head()CRS_DEP_TIME 列に、24 時間表示の 0 から 2359 の値が含まれていることを確認します。
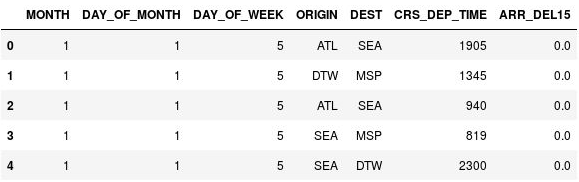
出発時刻がビン分割されていない DataFrame
出発時刻をビン分割するには、次のステートメントを使用します。
import math for index, row in df.iterrows(): df.loc[index, 'CRS_DEP_TIME'] = math.floor(row['CRS_DEP_TIME'] / 100) df.head()CRS_DEP_TIME 列の数値が現在、0 から 23 の範囲になっていることを確認します。
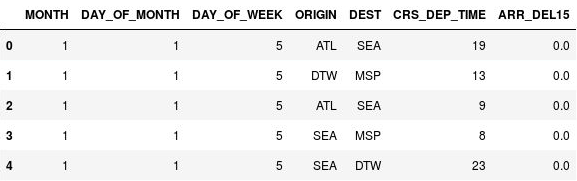
出発時刻がビン分割された DataFrame
次は以下のステートメントを使用して、ORIGIN と DEST の列自体を削除するときに、ORIGIN と DEST の列からインジケーター列を生成します。
df = pd.get_dummies(df, columns=['ORIGIN', 'DEST']) df.head()結果の DataFrame を調べ、ORIGIN と DEST の列が、元の列にある空港コードに対応する列に置き換えられたことを確認します。 新しい列には 1 と 0 があります。これは、特定のフライトが対応する空港から出発したか、目的地がその空港だったかを示します。
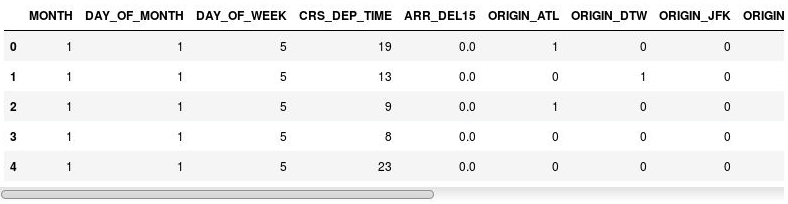
インジケーター列を含む DataFrame
[ファイル] ->[Save and Checkpoint] (保存とチェックポイント) コマンドを使用して、ノートブックを保存します。
データセットは開始時とは大きく異なって見えますが、これで機械学習で使用するために最適化されました。